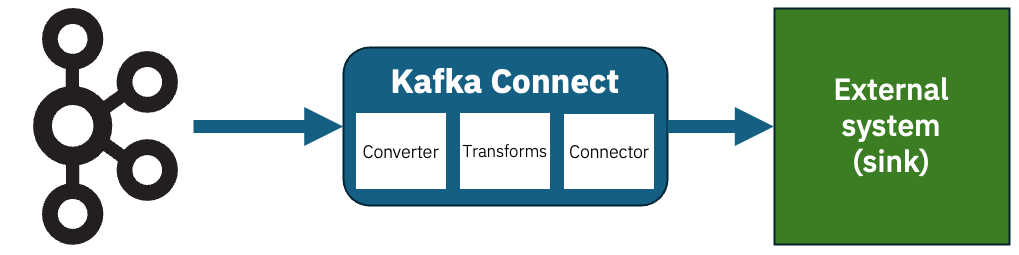
I’m often asked this. The specific question varies, but it’s typically some variation of asking how quickly a single CPU of Flink processes events from a Kafka topic.
Why “per CPU”? Maybe because enterprise software is typically charged per CPU? Maybe because I tend to talk to people who run everything in Kubernetes, who think of running software in terms of requests / limits? Not sure, but the question tends to be framed from the perspective of asking how much processing they can expect to get from a CPU.
I try to avoid doing the engineer thing of answering “it depends“… but… it really does depend!

That is the motivation behind this post: to give me something I can point at as an illustration of the degree to which Flink’s performance varies (and a taste of the range of interrelated factors that influence it).