![]() I’ve tried to explain IBM Watson to a lot of people this year. A common theme in questions I’ve had has been comparing it to search engines like Google.
I’ve tried to explain IBM Watson to a lot of people this year. A common theme in questions I’ve had has been comparing it to search engines like Google.
Sometimes people ask why one is “better” than another. Sometimes they just ask how they are different.
It’s not surprising. A natural response to learning about something new is to put it into context of things that we already know.
In addition, we describe Watson as a question answering technology and over the last few years many people have perhaps become a bit conditioned to thinking that if they have a question then they can Google for it.
There are many differences between search engines and Watson, both in what they can do, and in how they try to do it.
Here is one example.
Consider this question:
Which loyal companion made his first appearance in the year that the object he shares a name with was discovered?
The answer is Pluto. The cartoon character dog Pluto first appeared in a 1930 Disney film called “The Chain Gang”, which was the same year that Clyde Tombaugh is formally credited with having discovered the planet Pluto.
But… if you put that question into Google, Pluto doesn’t come up. [1]
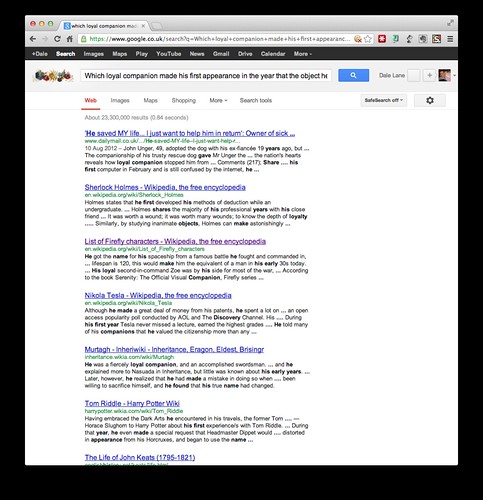
A search engine isn’t trying to answer the question, it’s looking for documents that contain keywords from the query. But there aren’t distinctive keywords in the question that are unique enough to make a document about a Disney cartoon character jump to the top.
A search engine isn’t trying to understand the question.
It’s not looking at “loyal companion” and recognising that this can mean many things, such as dogs.
It’s not trying to identify what types of things can be discovered, such as a place or a planet, and favouring answers that are something of one of those types.
It’s not able to perform decomposition on the question to recognise that it’s made up of two separate sub-queries (one about the cartoon dog, one about the planet) which can be attempted separately.
Instead, a search engine is forced to depend upon finding a single document that contains the entire query. This has to be a connection that someone else has previously made and written about in a single page. It’s not able to make a new connection – answering each bit independently and comparing answers from different sources to look for matches.
Given this question, Watson will be doing all of these things and more, bringing hundreds of different algorithms and strategies to bear on the question.
Here’s another question.
This is one that I heard David Ferrucci, who led the original Research team, use.
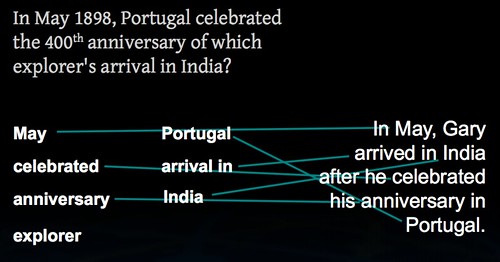
In May 1898, Portugal celebrated the 400th anniversary of which explorer’s arrival in India?
On the one hand, relying upon keywords means that a passage like this looks like it could be a match:
“…In May, Gary arrived in India after he celebrated his anniversary in Portugal…”
Keyword-wise, this is a great match (it contains “May”, “celebrated”, “explorer”, “Portugal”, “arrival”, and “India”) which suggests that this is a piece of evidence that the explorer who discovered India was called Gary.
On the other hand, a search engine that relies upon keywords without a deeper level of understanding or interpretation would miss something like this:
“…On the 27th May 1498, Vasco de Gama landed on Kappad Beach…”
It needs some sort of temporal reasoning to recognise that 1898 is the 400th anniversary of 1498. It needs some sort of spatial reasoning to understand that Kappad Beach is the name of a place in India.
Recognising that this is a piece of evidence that correctly identifies “Vasco de Gama” takes a deeper level of understanding than just picking out keywords.
Why this matters
This level of understanding (both of the question that is being asked, and of the documents that it will look for answers in) is one of the differences between how Watson and search engines.
For simple trivia, such as looking up facts and figures, the approach used by search engines are a good fit.
But for complex questions, Watson’s capabilities are unique and will enable us to answer detailed, expert questions that a keyword-driven approach would struggle with.
.
[1] – I’ve been using this example question in a few talks I’ve given this year, so now if you google variations of that question, you can come across slides of mine that people have put online or some comments that people made about it. This blog post probably wont help either. But before I first wrote those slides, I did try Googling that question and no Disney characters at all showed up in the first ten pages of results that I went through. I just need to come up with a new example question for next year… 🙂
Tags: watson