In this post, I want to talk about what happens when you use Avro to deserialize messages on a Kafka topic, why it actually needs two schemas, and what those schemas need to be.
I should start by pointing out that if you’re using a schema registry, you probably don’t need to worry about any of this. In fact, a TLDR for this whole post could be “You should be using a good schema registry and SerDes client“.
But, there are times where this may be difficult to do, so knowing how to set a deserializer up correctly is helpful. (Even if you’re doing the right thing and using a Schema Registry, it is still interesting to poke at some of the details and know what is happening.)
The key thing to understand is that to deserialize binary-encoded Avro data, you need a copy of the schema that was used to serialize the data in the first place [1].
This gets interesting after your topic has been around for a while, and you have messages using a mixture of schema versions on the topic. Maybe over the lifetime of your app, you’ve needed to add new fields to your messages a couple of times.
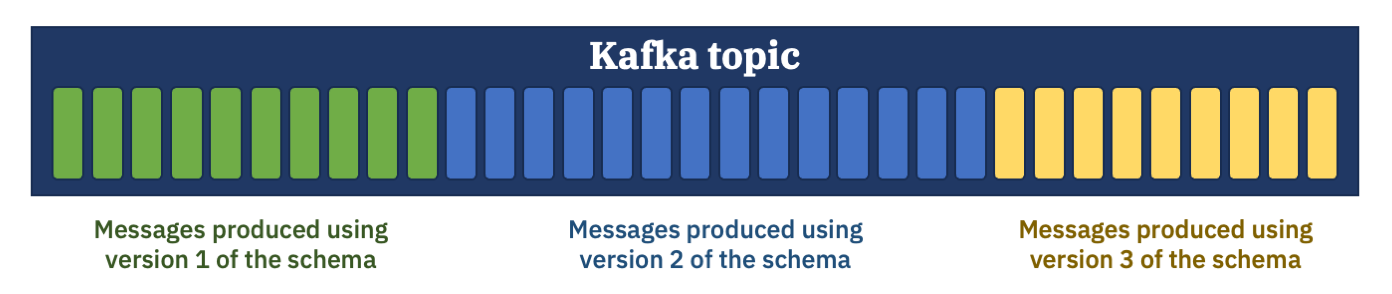
If you want a consumer application to be able to consume all of the messages on this topic, what does that mean?