IBM TechCon is an annual online technical event for engineers, creators, and integration specialists.
One of our sessions for this year was an introduction to Monitoring your Event Driven Architecture:
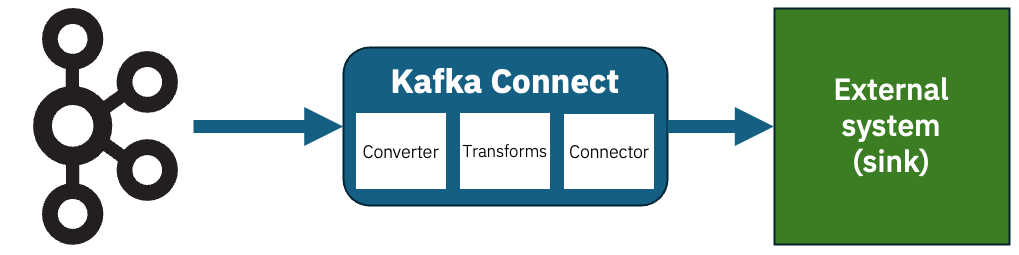
This session will give you an insight into the life of an Event Automation administrator, responsible for a busy event-driven system where teams have been creating a variety of Kafka topics, integrations, stream processing apps, connectors, and much more. We’ll highlight the importance of metrics and monitoring for event driven architectures and introduce you to the tools that are available to help.
We’ll do this by showing you an event-driven environment where things have gotten out of hand. In our fictional scenario, users are being impacted by things like poorly configured topics, poorly written applications, poorly managed connectors, poorly configured stream processors…
In this session, we’ll walk you through to bring control to the chaos. We’ll step through how to get an insight into what is happening, find out where the problems are, and put controls in place to mitigate their impact.
session recording on video.ibm.com
It was an introduction for beginners, that you could sum up as a 40-minute plea for people to monitor their Kafka clusters and applications! Essentially, we set up a handful of naive and broken applications, and walked through how metrics and monitoring show you where the problems are hiding.
Watch it to be persuaded that metrics are important.
Or to watch how Matt had to jump in and help me when an Apple Magic Mouse decide it didn’t like scrolling any more, and I needed to get to things at the bottom of web pages!
Or just to marvel at how glamourous our offices are. 😉