In this post, I want to share a couple of very quick and simple examples for how to use LISTAGG and ARRAY_AGG in Flink SQL.
This started as an answer I gave to a colleague asking about how to output collections of events from Flink SQL. I’ve removed the details and used this post to share a more general version of my answer, so I can point others to it in future.
Windowed aggregations
One of the great things in Flink is that it makes it easy to do time-based aggregations on a stream of events.
Using this is one of the first things that I see people try when they start playing with Flink. The third tutorial we give to new Event Processing users is to take a stream of order events and count the number of orders per hour.
In Flink SQL, that looks like:
SELECT
COUNT (*) AS `number of orders`,
window_start,
window_end,
window_time
FROM
TABLE (
TUMBLE (
TABLE orders,
DESCRIPTOR (ordertime),
INTERVAL '1' HOUR
)
)
GROUP BY
window_start,
window_end,
window_time
In our low-code UI, it looks like this:
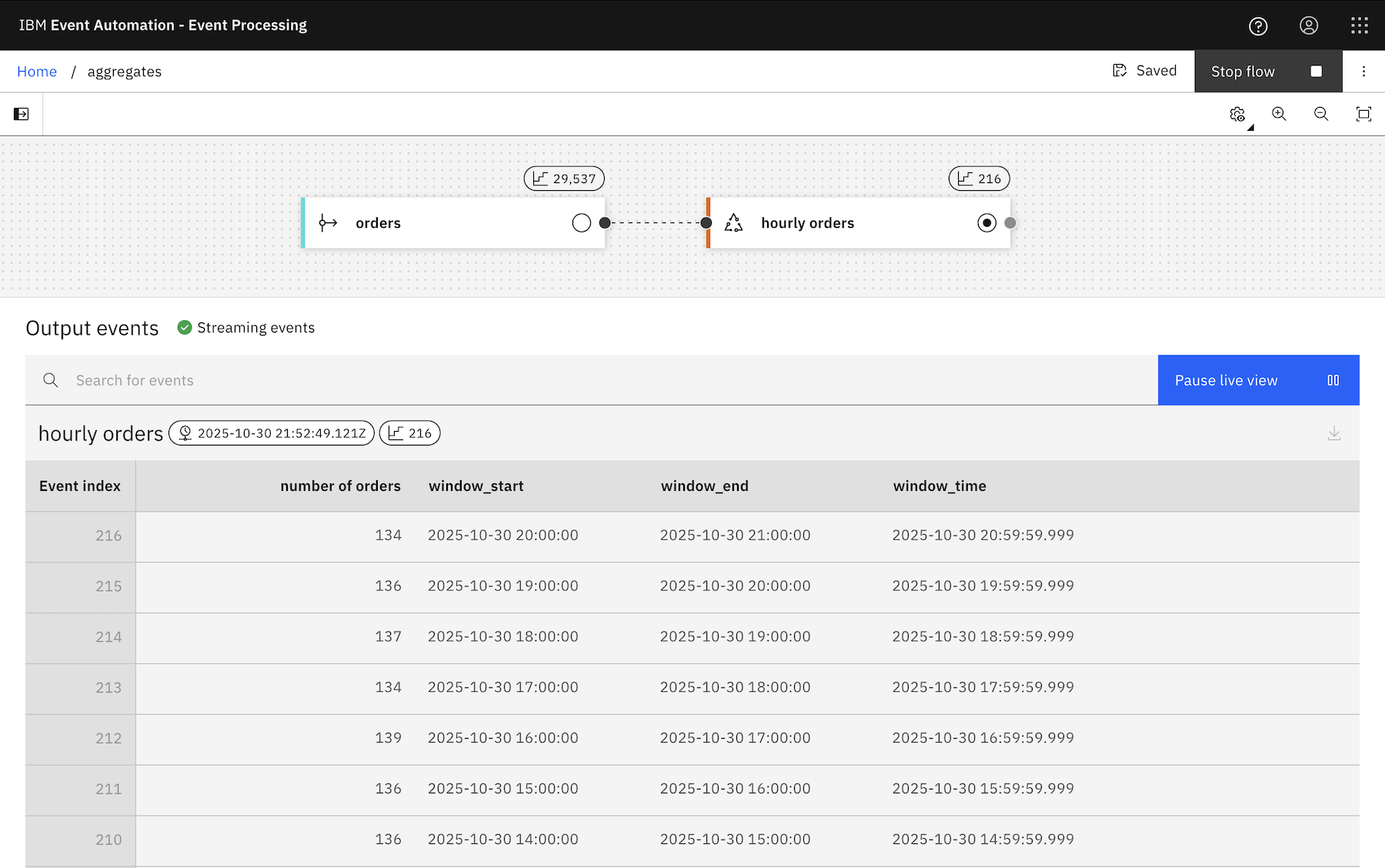
However you do it, the result is a flow that emits a result at the end of every hour, with a count of how many order events were observed during the last hour.
But what if you don’t just want a count of the orders?
What if you want the collection of the actual order events emitted at the end of every hour?
To dream up a scenario using this stream of order events:
At the end of each hour, emit a list of all products ordered during the last hour, so the warehouse pickers can prepare those items for delivery.
This is where some of the other aggregate functions in Flink SQL can help.
LISTAGG
If you just want a single property (e.g. the name / description of the product that was ordered) from all of the events that you collect within each hourly window, then LISTAGG can help.
For example:
SELECT
LISTAGG (description) AS `products to pick`,
window_start,
window_end,
window_time
FROM
TABLE (
TUMBLE (
TABLE orders,
DESCRIPTOR (ordertime),
INTERVAL '1' HOUR
)
)
GROUP BY
window_start,
window_end,
window_time
That gives you a concatenated string, with a comma-separated list of all of the product descriptions from each of the events within each hour.
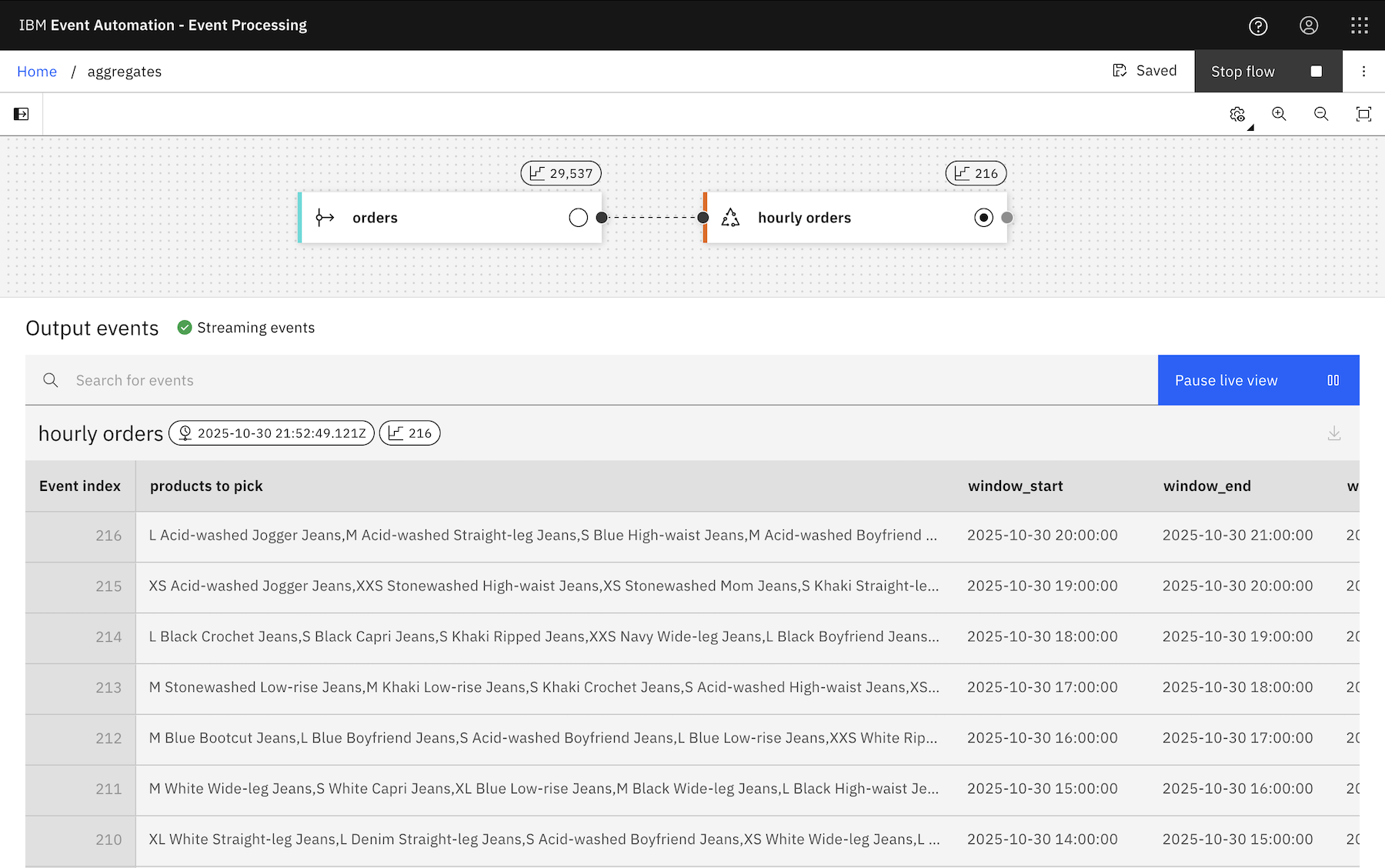
You can use a different separator, but it’s a comma by default.
ARRAY_AGG
If you want to output an object, with some or even all of the properties (e.g. the name and quantity of the products that was ordered) from all of the events that you collect within each hourly window, then ARRAY_AGG can help.
For example:
SELECT
ARRAY_AGG (
CAST (
ROW (description, quantity)
AS
ROW <description STRING, quantity INT>
)
) AS `products to pick`,
window_start,
window_end,
window_time
FROM
TABLE (
TUMBLE (
TABLE orders,
DESCRIPTOR (ordertime),
INTERVAL '1' HOUR
)
)
GROUP BY
window_start,
window_end,
window_time
The CAST isn’t necessary, but it lets you give names to the properties instead of the default names you get such as EXPR$0, so downstream processing is easier.
In each hour, an event is emitted that contains an array of objects, made up of properties from the events in that hour.
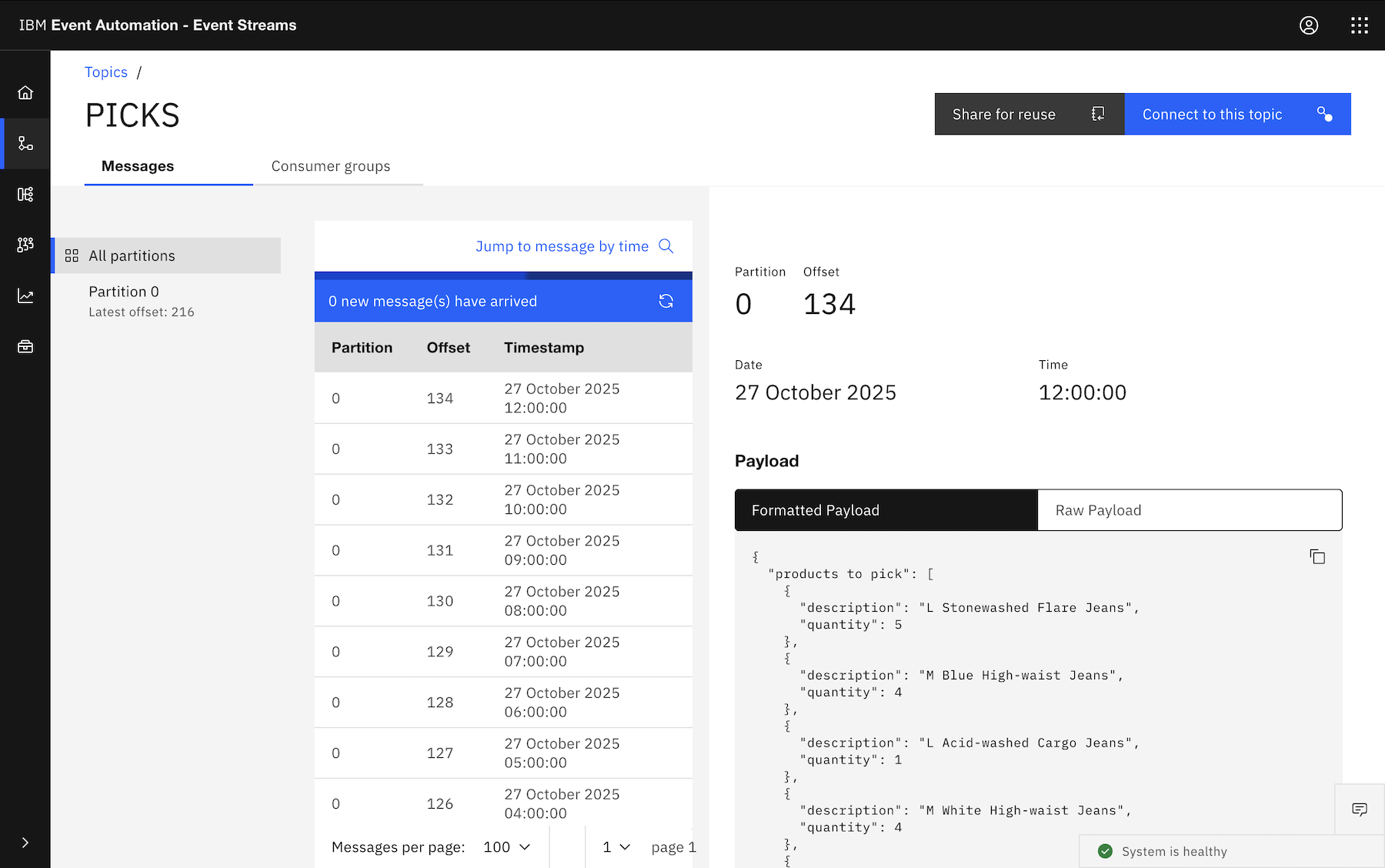
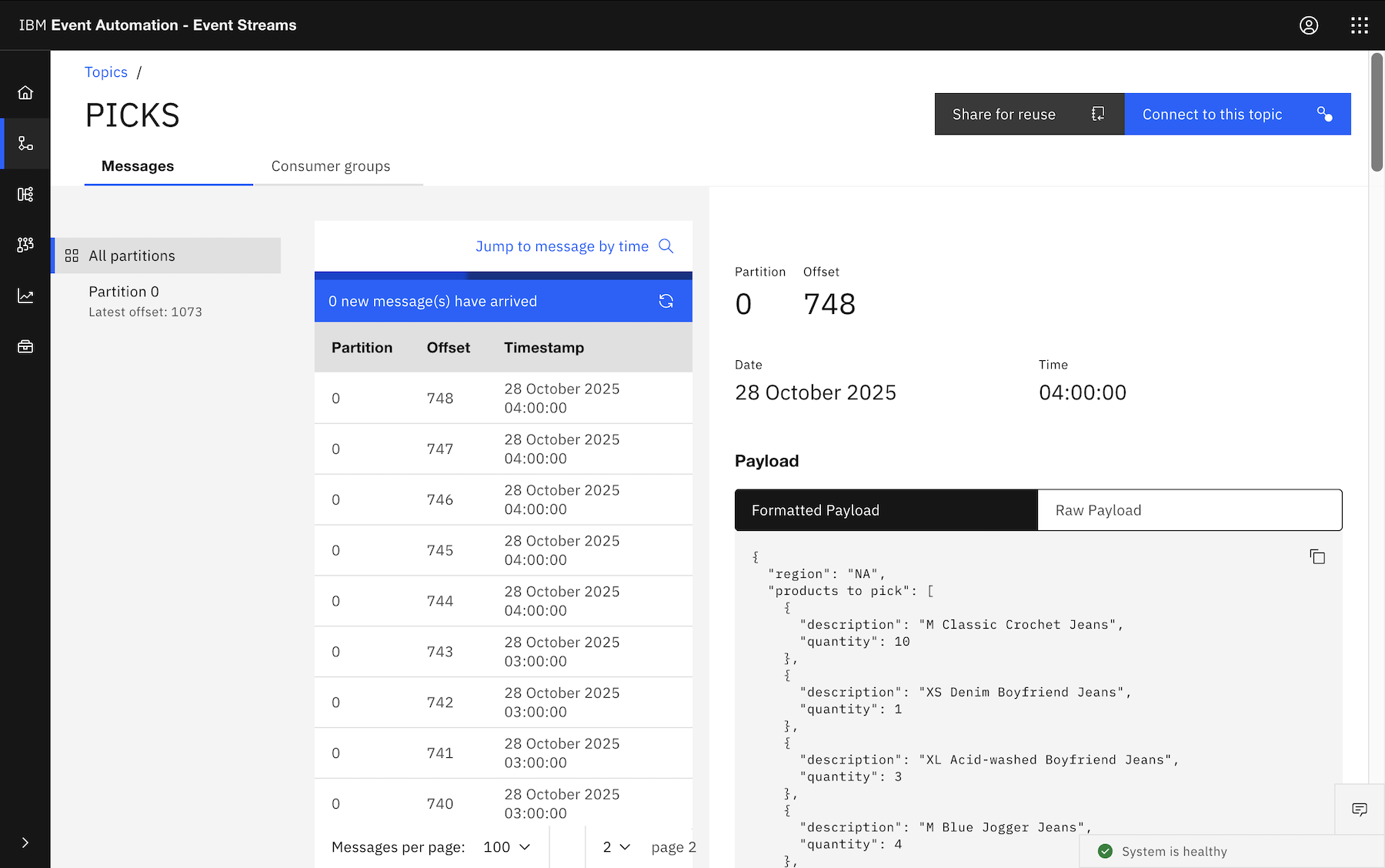
And naturally you could add additional GROUP BY, for example, if you wanted a separate pick list event for each region:
SELECT
region,
ARRAY_AGG (
CAST (
ROW (description, quantity)
AS
ROW <description STRING, quantity INT>
)
) AS `products to pick`,
window_start,
window_end,
window_time
FROM
TABLE (
TUMBLE (
TABLE orders,
DESCRIPTOR (ordertime),
INTERVAL '1' HOUR
)
)
GROUP BY
window_start,
window_end,
window_time,
region
This outputs five events at the end of every hour, one with a list of each of the orders for the NA, SA, EMEA, APAC, ANZ regions.
Try it yourself
I’ve used the “Loosehanger” orders data generator in these examples, so if you want to try it for yourself, you can find it at
github.com/IBM/kafka-connect-loosehangerjeans-source.
If you want to try it in Event Processing, the instructions for setting up the tutorial environment can be found at
ibm.github.io/event-automation/tutorials.