In this post, I’ll demonstrate how Event Processing can use parameters from an external source (such as a rules engine) in event processing flows.
A simple flow to demonstrate the idea
To illustrate the idea, I created a simple demo event processing flow. The flow takes a stream of order events, filters it to keep only orders for high value items, and then modifies the description property in some of the events:
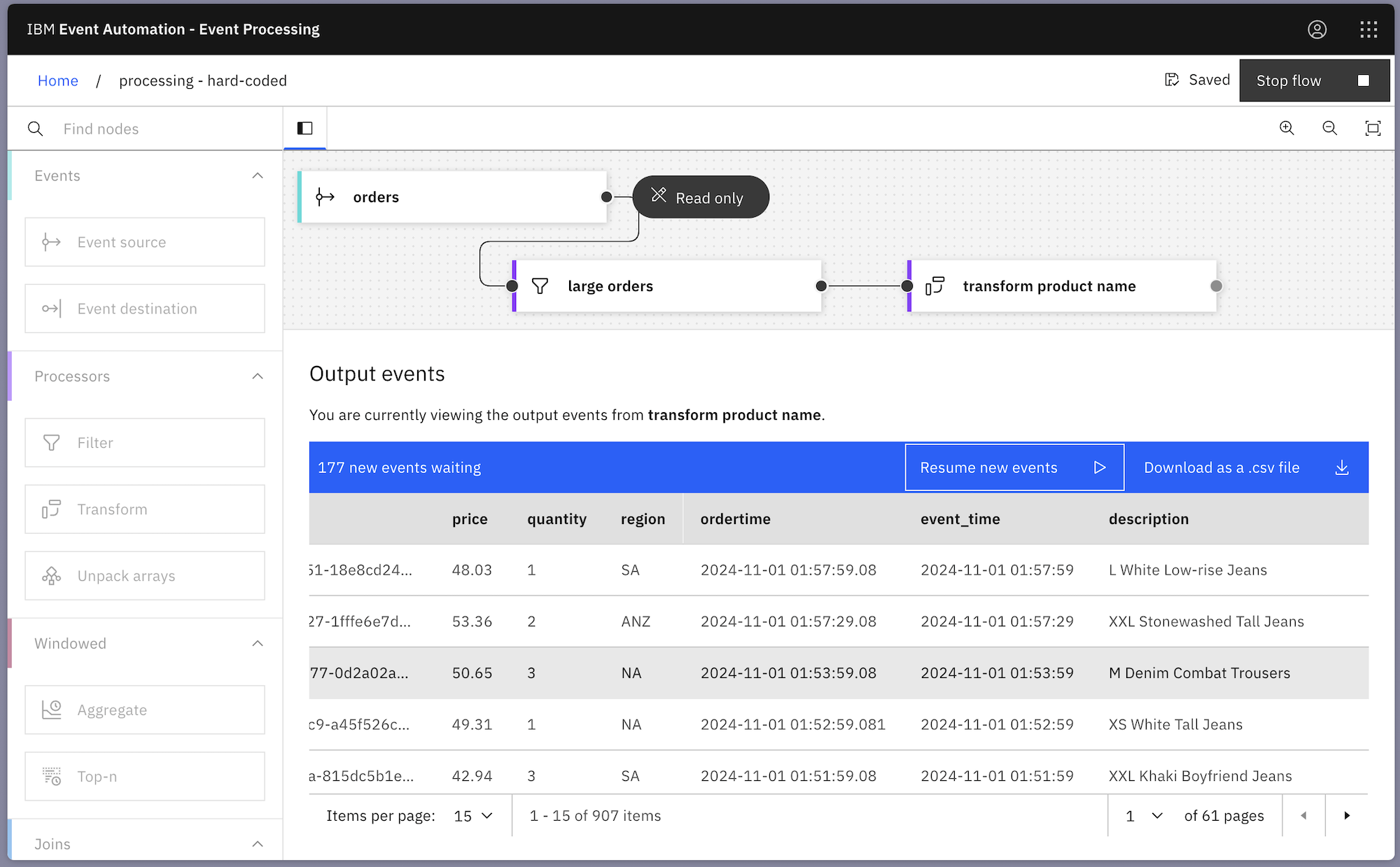
The filter node is comparing the price with “40”, so only order events for items with a value above $40 are kept.
The transform node is modifying the description property of order events – any description that contains the string “Cargo Jeans” is replaced with “Combat Trousers”.
![]()
Hard-coded parameters
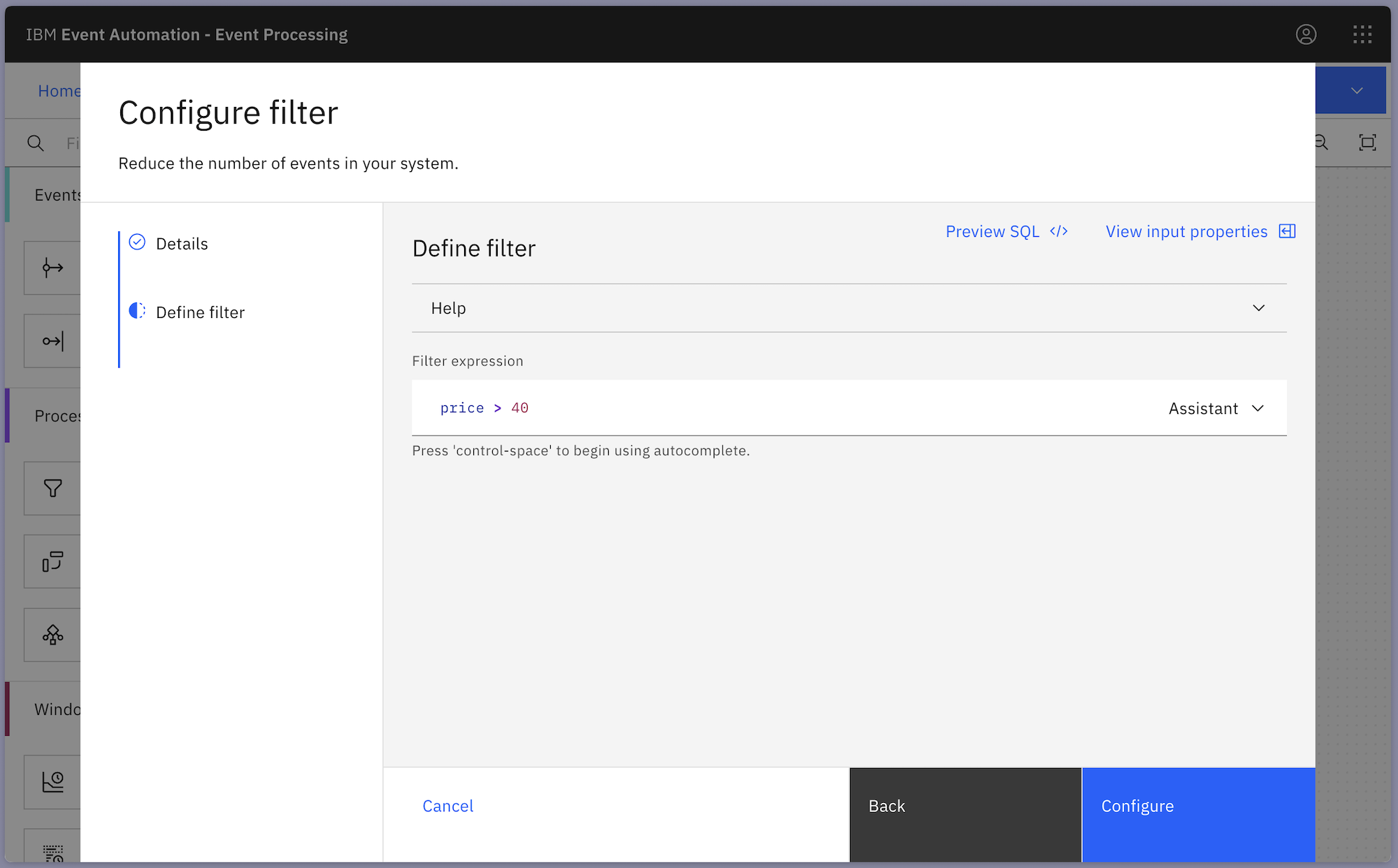
What if you wanted to modify the threshold for the filter, to change that $40 minimum value for an order to be considered “large”?
Or what if you wanted to modify the transformation, so that different strings would be used in the regular expression replacement?
With the values hard-coded in the flow as shown above, you would need to:
- create a savepoint for the job
- stop the job
- modify the parameters in the job
- resume the job from the savepoint
This is a workable approach, although it does require a little downtime and some administrative effort.
The aim for this post is to highlight an alternative approach.
Externalized parameters
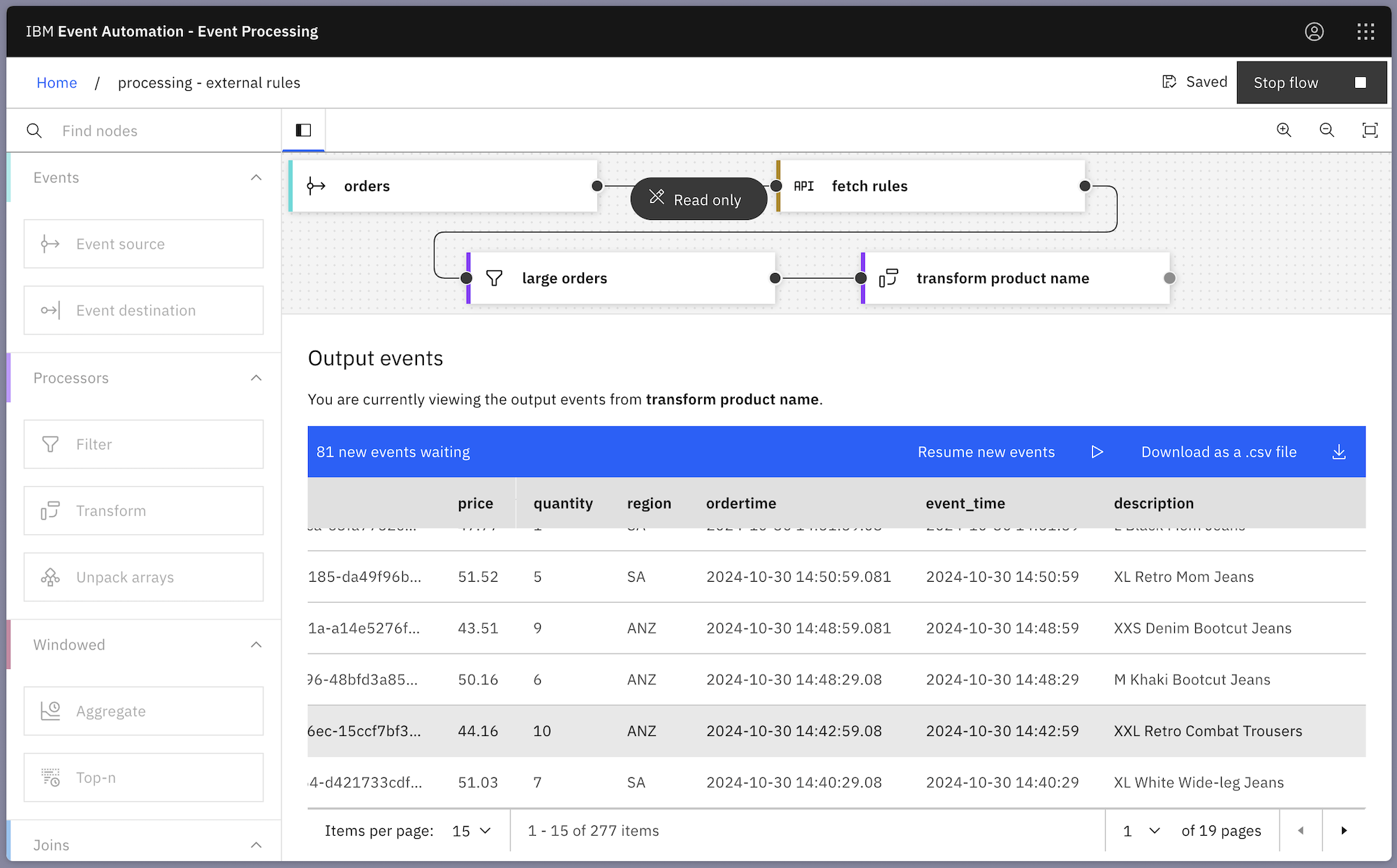
An alternative approach is to maintain those parameters outside of the flow. If these parameters are made available through a REST API, then they can be retrieved while the job is still running, modifying the behaviour of the flow without requiring any downtime.
The same flow as above would look like this – with the new node added to retrieve the parameters from a source of business rules.
For example, imagine an API that returned a payload like:
{
"thresholds" : {
"large_order": 40.00
},
"transforms" : {
"product_name": {
"before" : "Cargo Jeans",
"after" : "Combat Trousers"
}
}
}
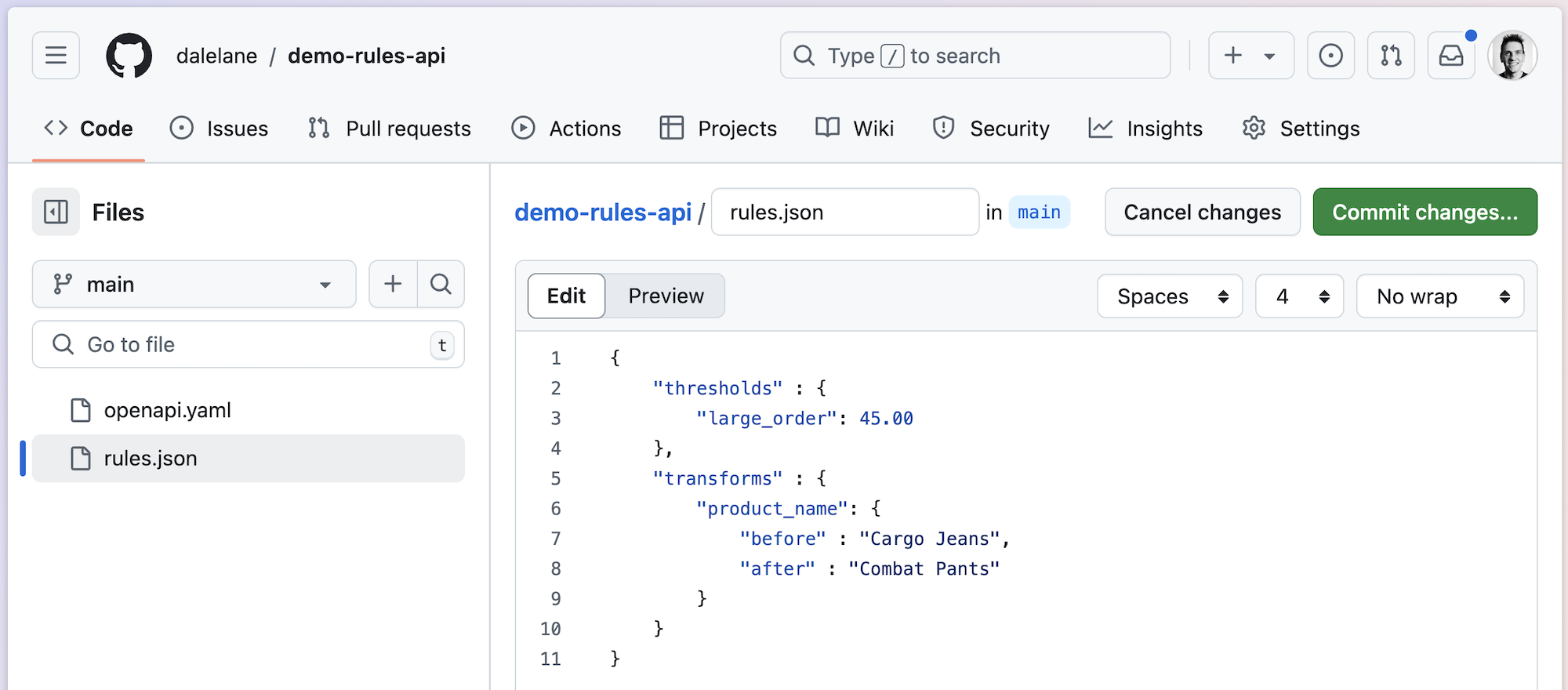
To illustrate this without introducing any additional components, I created a JSON file in github to act as an API:
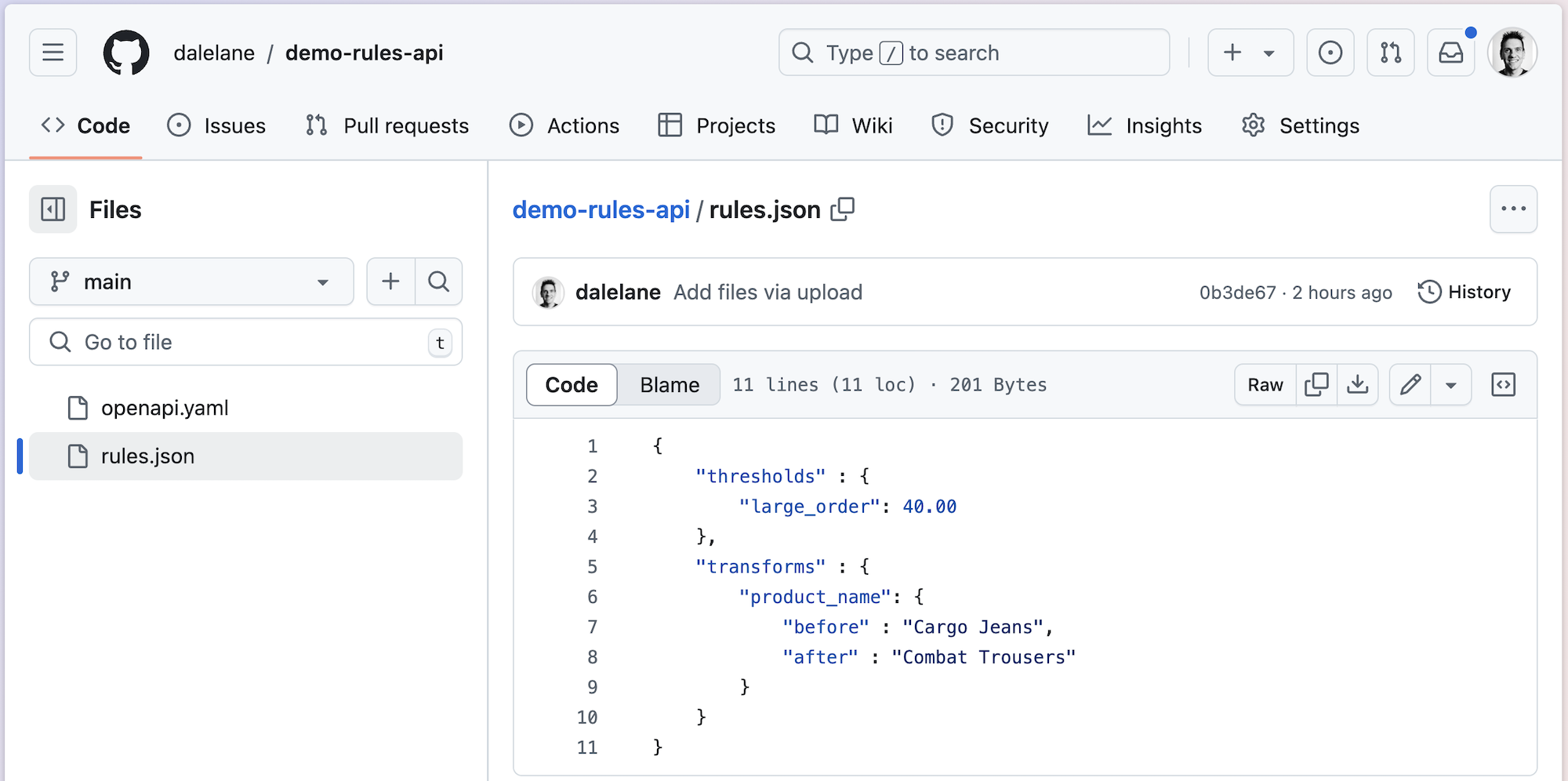
This means that HTTP calls to raw.githubusercontent.com/…/rules.json will return that JSON payload.
Adding an API Enrichment node using the OpenAPI document for this static API let me bring the values from the API payload into the flow.
I gave the values more readable names for use in the flow, as you can see in the bottom of this screenshot:
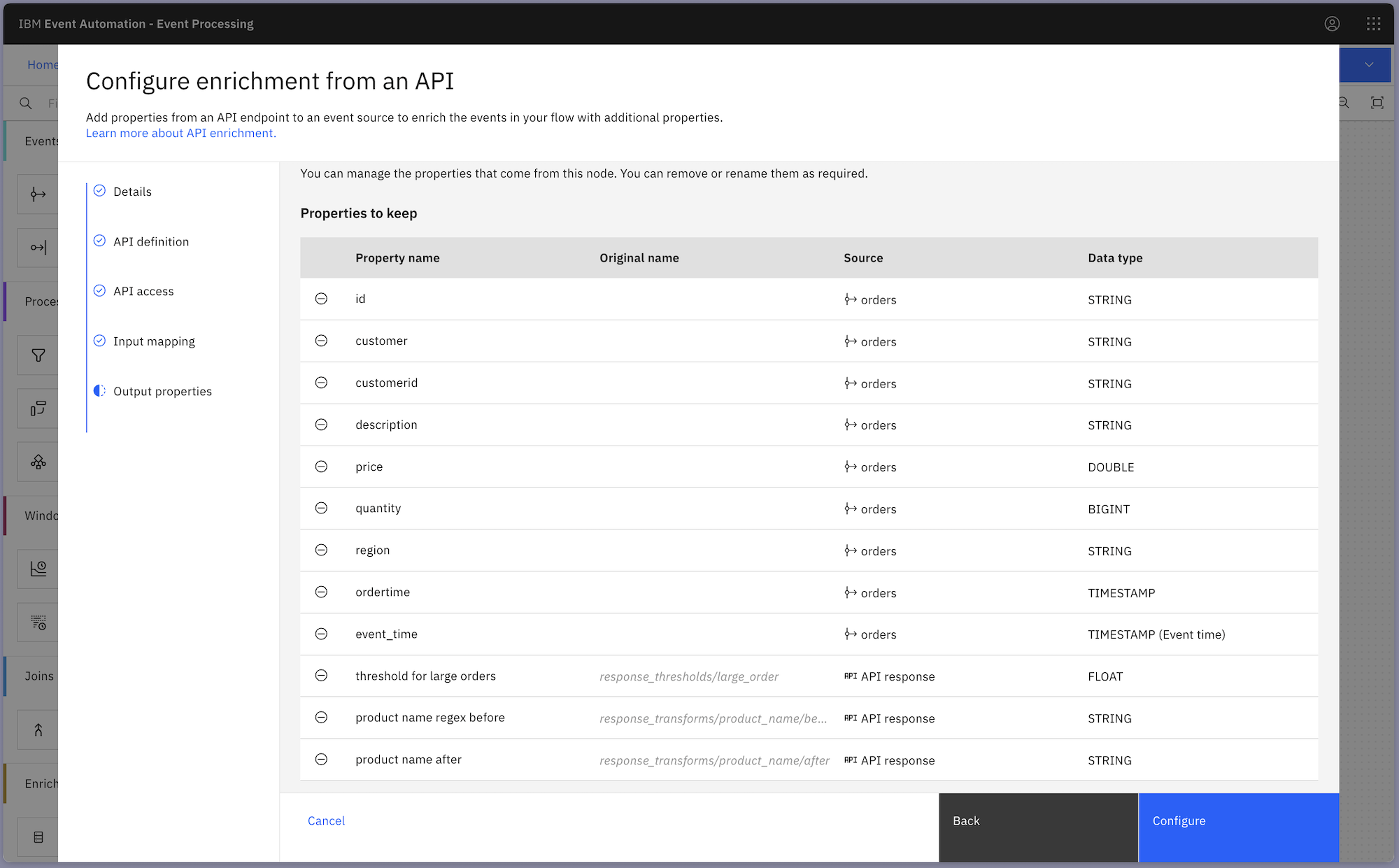
In the rest of the nodes, the hard-coded values can be replaced with references to the parameters fetched by the API.
This means the filter node now looks like this:
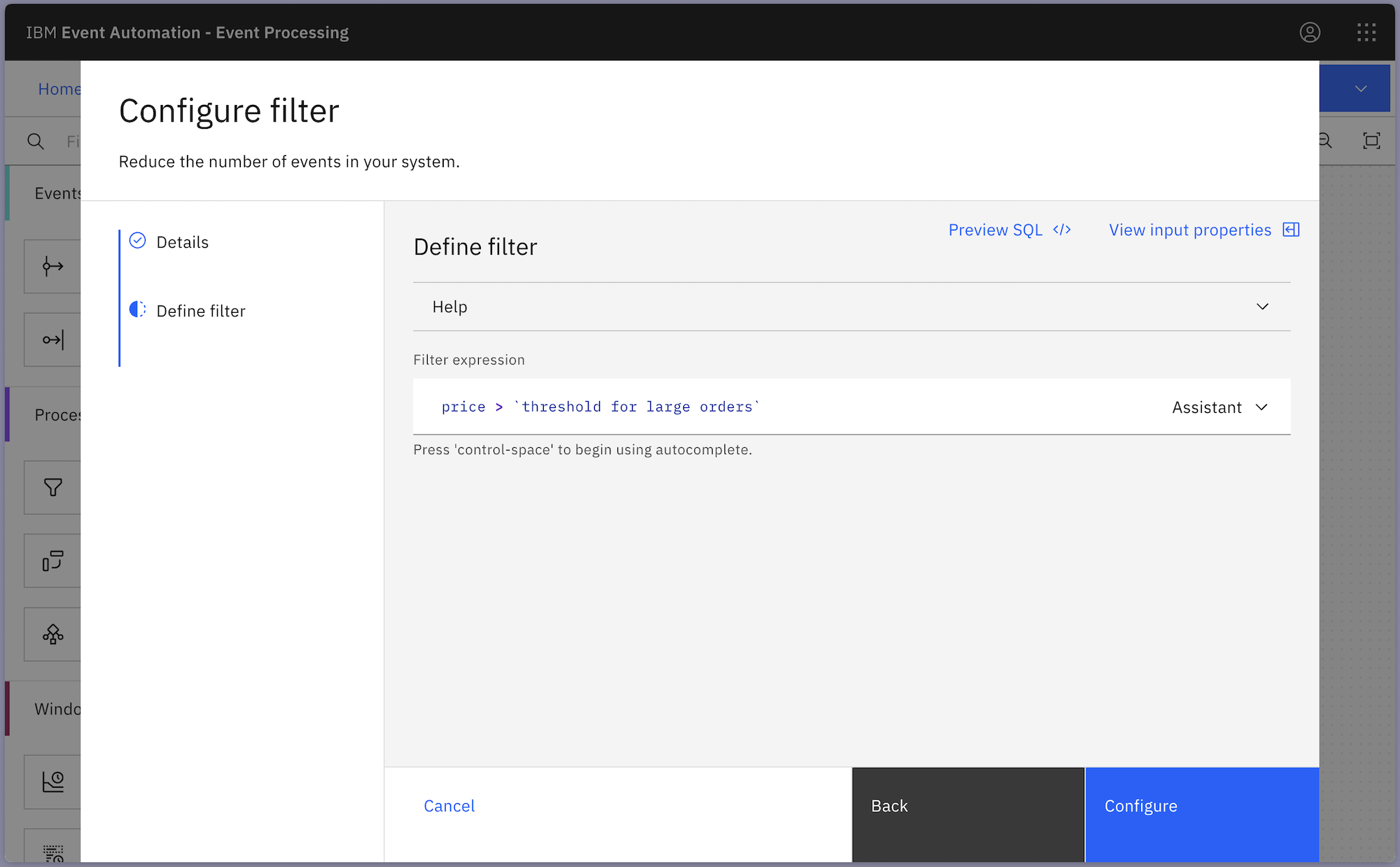
And the transform node now looks like this:
![]()
Responding to rule changes
To illustrate what happens to the job when there are changes to the parameters in the rules engine, I modified the JSON file in github: changing the threshold used by the filter node to identify large orders, and changing the replacement string used by the transform node.
The outcome is that the results from the job reflect the new parameters (only orders that match the new filter are included, and the transformation uses the new replacement string).
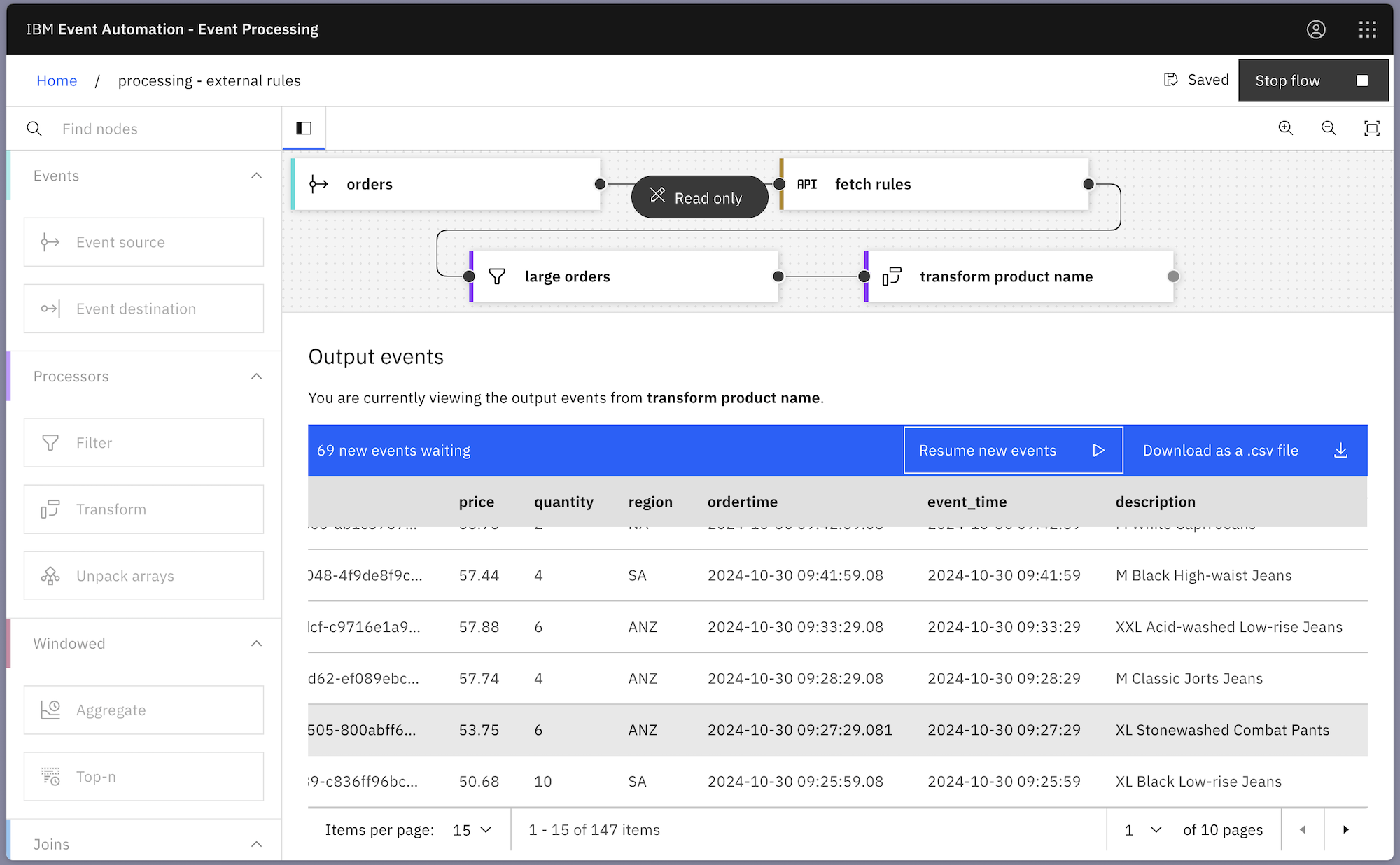
Caching for improved efficiency
This approach does work, however the result is that the API is invoked as a part of processing each and every order event.
This isn’t very efficient:
- if there is a high throughput of order events, this will introduce a significant overhead to the REST API with a large number of repeated calls
- it increases the latency of the order processing, as the processing of every event now includes the time taken to make an HTTP call
Caching the response from the API calls is a good way to mitigate these challenges.
For example, reducing the load so that API calls are made only every 30 minutes would look like:
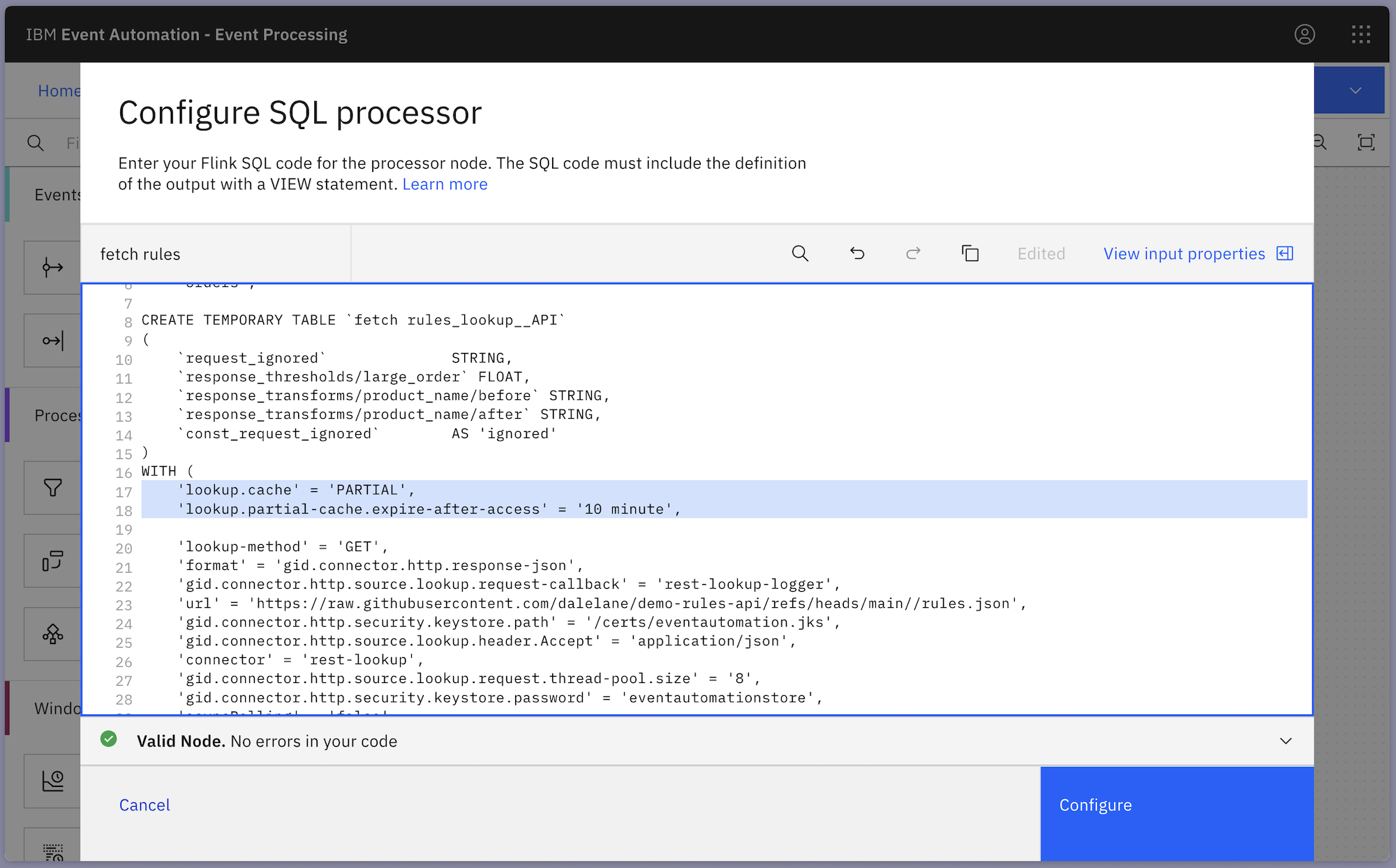
'lookup.cache' = 'PARTIAL', 'lookup.partial-cache.expire-after-access' = '30 minute',
The longer the cache period, the more this reduces the overhead on the API and the latency impact on the processing – however it increases the time before the rules changes are reflected in the event processing.
Reducing the cache period means that rules changes take effect more quickly, however increases the load on the API server and the event processing latency.
Finding a good balance between these will depend on the priorities for your use case.
To add this config to the API enrichment node, you can switch to the SQL view in the node and add the new lines to the properties of the table representing the API:
Role of rules engines in event processing
This was just a quick and trivial demo to illustrate what can be done very simply. If you’re interested in a deeper dive into this general idea, we gave a talk on the roles of Rules Engines in event stream processing at this year’s Kafka Summit.
A recording of the talk is available on Confluent’s website.
Tags: flink