How to run a tiny local Kafka cluster using IBM Event Streams images
For local development on Kafka projects, I always run the public open source builds of ZooKeeper and Kafka as Java processes directly on my laptop (similar to steps described in the Apache Kafka Quickstart).
But for a project this week, I needed to verify something with the distribution of Kafka that comes with IBM Event Streams.
I used a simple Docker Compose setup for this. I’ll use this post to share how I did it.
Quick primer if you’re not a gamer or don’t know what I’m talking about!
The Xbox platform comes with a social aspect: details about games you play and the achievements you earn playing them, are shared with your friends on the Xbox LIVE service. That is the source of data I’m using here.
Create an API key for your Xbox LIVE account, and run the Connector with it, and it will start producing two streams of events to your Kafka cluster:
Screenshot from Event Streams, but as a Kafka Connect connector, you could use any flavour of Kafka, including Apache Kafka.
ACHIEVEMENTS
Events when one of your friends earns an achievement.
PRESENCE
Events when your friends start playing a game, or go online/offline.
Details about the attributes of each of these events can be found in the Connector README, but here are a few screenshots to give you an idea.
This post was written for MachineLearningForKids.co.uk/stories: a series of stories I wrote to describe student experiences of artificial intelligence and machine learning, that I’ve seen from time I spend volunteering in schools and code clubs.
Machine learning models don’t just give an answer, they also typically return a score showing how confident the system is that it has correctly recognized the input.
Knowing how to use this confidence score is an important part of using machine learning.
An example of how a student used this in their project is shown in this video. Their Scratch script says that if the machine learning model has less than 50% confidence that it has correctly recognized a command, it replies “I’m sorry I don’t understand” (instead of taking an action).
The project was trained to understand commands to turn on a lamp or a fan. When they asked it to “Make me a cheese sandwich”, their assistant didn’t try to turn the lamp or fan on, it said “I don’t understand”
This command was unlike any of the example commands that had been used to train the model, causing the machine learning model to have a very low level of confidence that it had recognised the command. This was represented with a very low confidence score.
The challenge for the students making this project was knowing what confidence score threshold to use. Instead of telling them a good value to use, I let them try out different values and decide for themselves. By playing and experimenting with it, they get a feel for the impact that this threshold has on their project.
In this post, I want to share a new Scratch extension that I made this week, explain what it does, and suggest a few ideas for the sorts of ways that it could be used.
Overview
The extension makes some of the data from the Spotify Audio Features API available as blocks in Scratch.
It means you can get numeric values representing different characteristics of songs, directly into a Scratch project.
This video is a great description of the aspiration of the team, and the vision of the sort of work we want to do with our customers. (Plus you get a few glimpses of our office in York Road where I worked this year).
This post was written for MachineLearningForKids.co.uk/stories: a series of stories I wrote to describe student experiences of artificial intelligence and machine learning, that I’ve seen from time I spend volunteering in schools and code clubs.
Digital assistants, such as Amazon’s Alexa or Google’s Home, is a great basis for student projects, because it is a use case that the students are familiar with.
A project I’ve run many times is to help students create their own virtual assistant in Scratch, by training a machine learning model to recognise commands like “turn on a lamp”. They do this by collecting examples of how they would phrase those commands.
This is an example of what this can look like:
By the time I do this project, my classes will normally have learned that they need to test their machine learning model with examples they didn’t use for training.
Students like trying to break things – they enjoy looking for edge cases that will trip up the machine learning model. In this case, it can be unusual ways of phrasing commands that their model won’t recognise.
I remember one student came up with ‘activate the spinny thing!’ as a way of asking to turn on a fan, which I thought was inspired.
But when the model gets something wrong, what should they do about that?
Students will normally suggest by themselves that a good thing to do is to collect examples of what their machine learning model gets wrong, and add those to one of their training buckets.
That means every time it makes a mistake, they can add that to their training, and train a new model – and their model will get better at recognizing commands like that in future.
They typically think of this for themselves, because with a little understanding about how machine learning technology behaves, this is a natural and obvious thing to do.
A quick tip for how to give a developer access to the IBM Event Streams UI only for the Kafka topics used by their application, and not everything else.
Imagine I’m a Kafka cluster admin. I’m running a cluster with a variety of topics on it.
Only viewing their own topics
One of my developers is responsible for the flight tracking app, and wants to use the Event Streams UI. But I don’t want them to be able to access the other sensitive topics for other applications.
I can create them their own login for the UI, that only lets them see their own topics.
This post was written for MachineLearningForKids.co.uk/stories: a series of stories I wrote to describe student experiences of artificial intelligence and machine learning, that I’ve seen from time I spend volunteering in schools and code clubs.
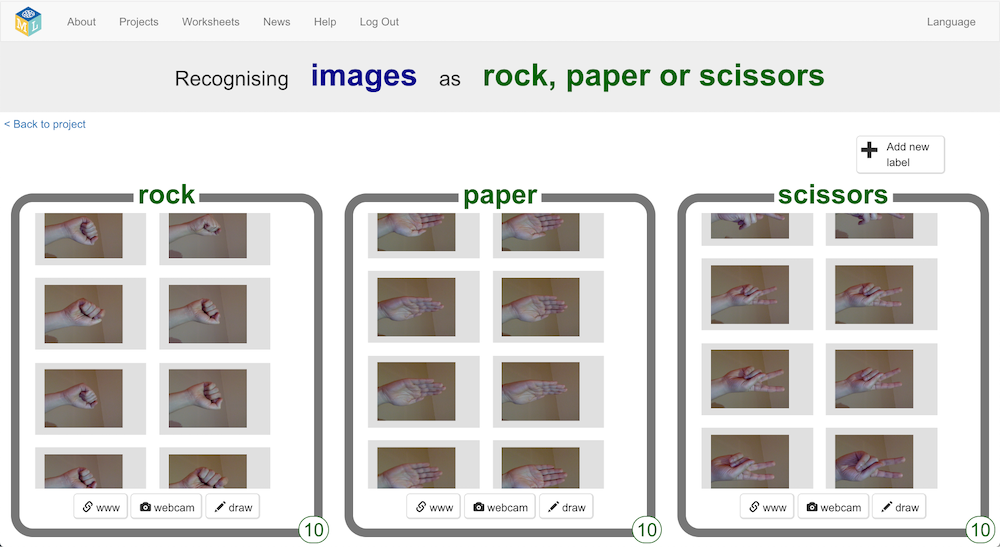
Students can make a Scratch project to play Rock, Paper, Scissors. They use their webcam to collect example photos of their hands making the shapes of ‘rock’ (fist), ‘paper’ (flat hand), and ‘scissors’ (two fingers). Then they use those photos to train a machine learning model to recognise their hand shapes.
I often have at least one enthusiastic (or impatient!) student keen to create their machine learning model as quickly as possible. They’ll hold their hand fairly still in front of the webcam, and keep hitting the camera button. The result is that they’ll take a large number of very similar photos.