Operators bring a lot of benefits as a way of managing complex software systems in a Kubernetes cluster. In this post, I want to illustrate one in particular: the way that custom resources (and declarative approaches to managing systems in general) enable easy integration with source control and a CI/CD pipeline.

I’ll be using IBM Event Streams as my example here, but the same principles will be true for many Kubernetes Operators, in particular, the open-source Strimzi Kafka Operator that Event Streams is based on.
I’ve got a few screen recordings showing exactly how to set up a demo of this, which I’ve embedded at the start of each section. The screenshots underneath all link to a specific timestamp of the relevant video.
The developer example
Imagine you’re a developer. You’re working on a Java application.
The details of the app aren’t important for the purposes of this demo, but I forked and tweaked the awesome kafka-java-vertx-starter app as a basis for showing what’s possible, as it’s a simple Kafka Java app with a nice UI.
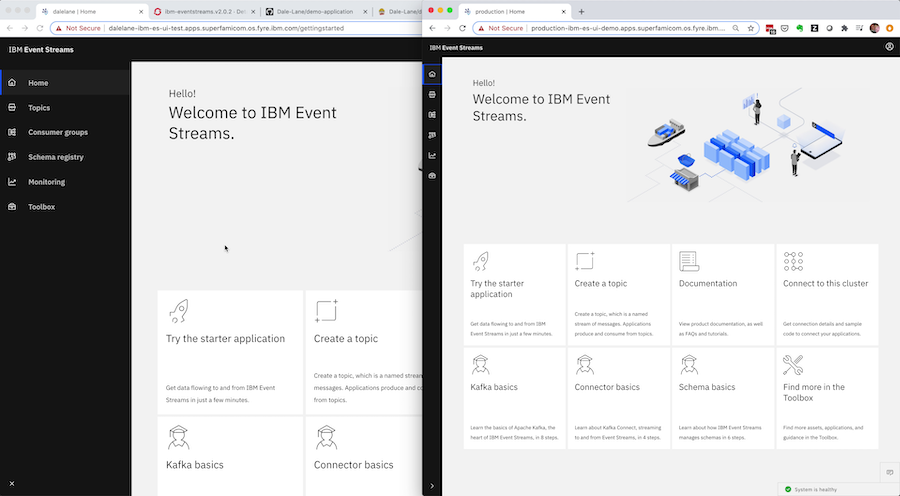
There are two instances of Event Streams here – two Kafka clusters.
- A development instance – that you’re free to play with, make changes to and test things on
- A production instance – that is locked down, with all changes made in a controlled automated way
Now you need a new Kafka topic for your application.
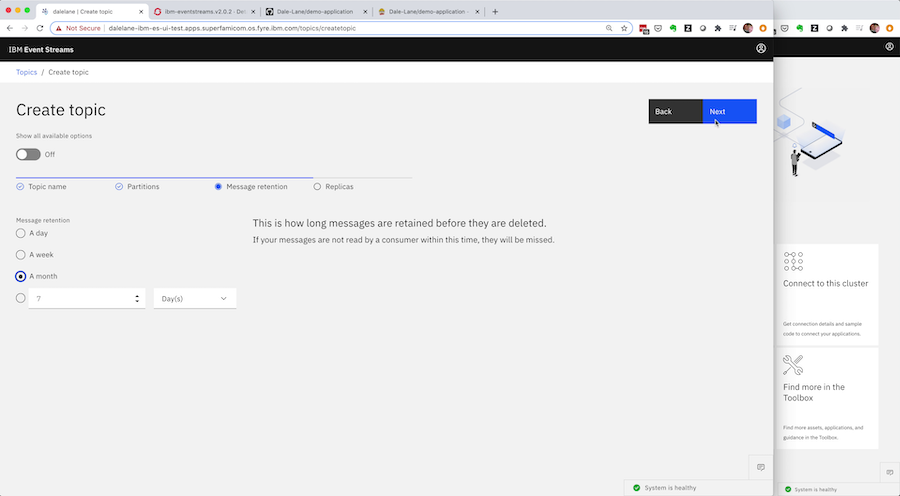
You can use the Event Streams user interface for the development instance for this – giving you a friendly guided wizard to help you work out the right config for your topic.
You can test your app against it, and tweak the config if you need to.
Once you’re happy with it, it’s time to commit this.
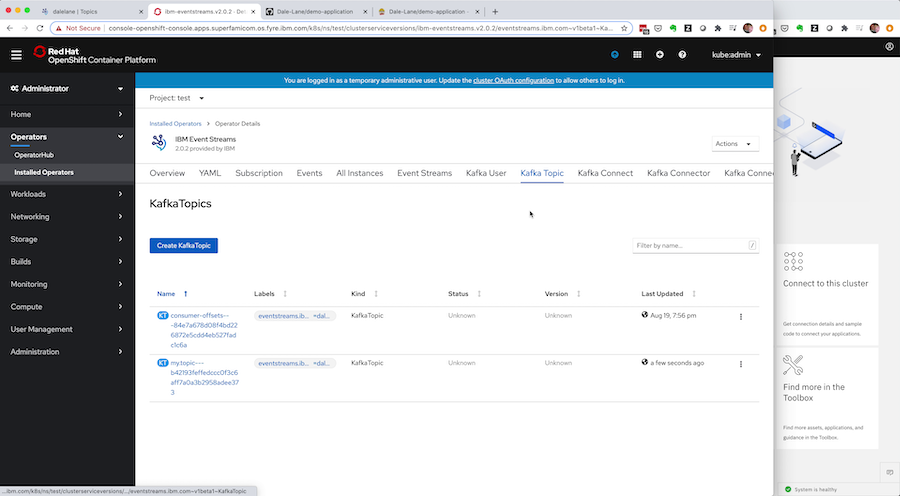
Everything in Event Streams is represented under the covers as custom resources, which means you can get the custom resource for your new topic from the development instance.
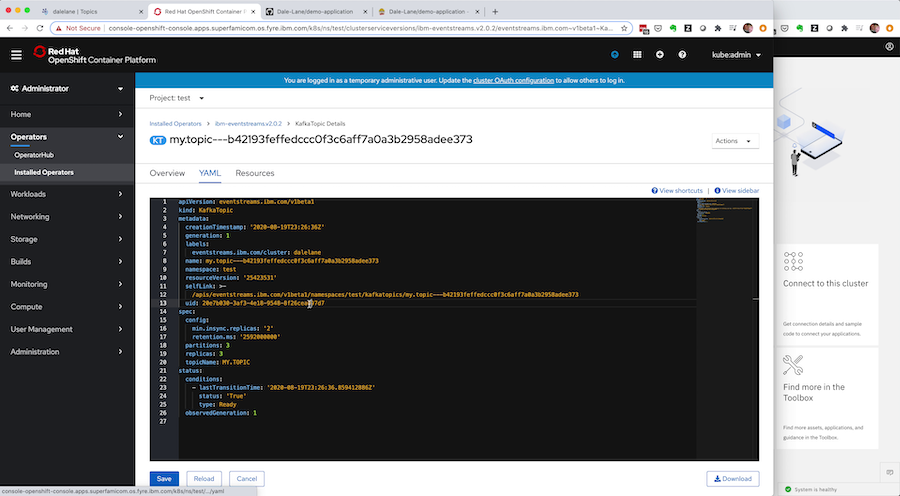
Everything you chose in the UI – all the final options and config you settled on through interactively clicking through the UI wizard – is captured here by the Event Streams Operator.
Kubernetes can give this to you in YAML or JSON form, but let’s go with YAML for now.
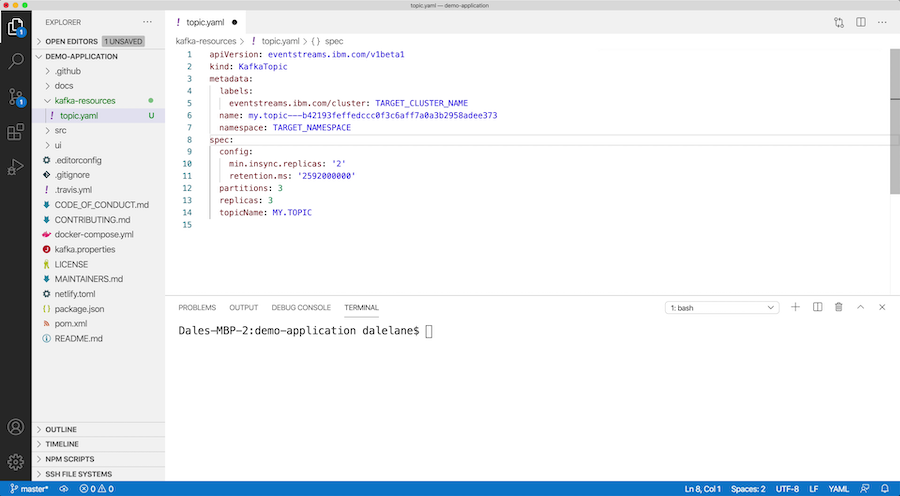
You’ll do a tiny bit of editing: stripping it down to the spec by removing the status. You can make the spec more generic and flexible by replacing the Event Streams instance name and deployment namespace with environment variables.
What you’re left with is a human-readable plain text file that describes the new topic you need for your application. This can live alongside the rest of the source code for your application, letting you manage them together.
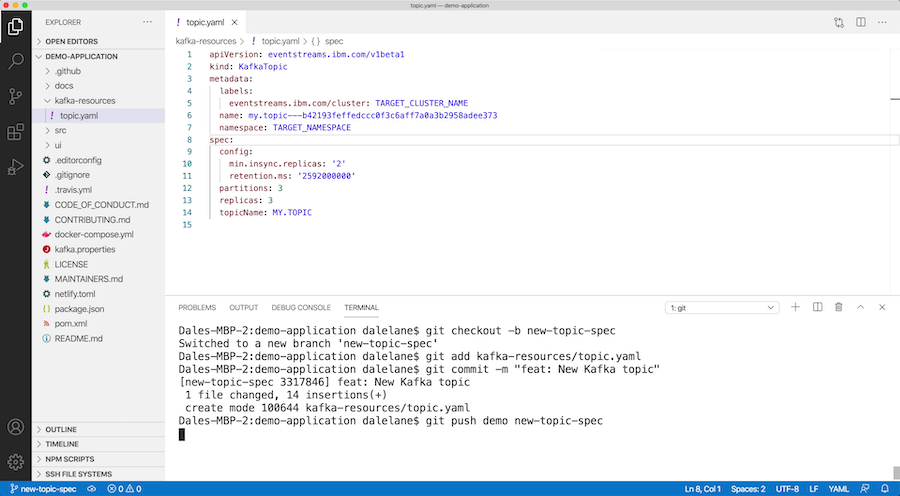
You can put this in a pull-request so your colleagues can review that the spec looks reasonable for promoting to the production cluster instance.
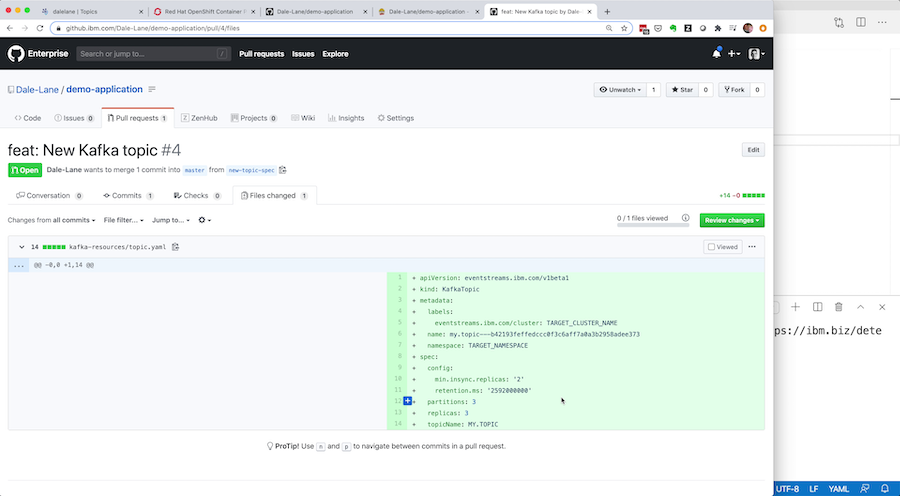
(You could put the topic spec in the same pull-request as whatever code changes you made to your application that needed the new topic – so the reviewer can see why you need the new topic in the context of your application, but let’s just keep the pull-request simple with the single file for now).

Once your pull-request is reviewed and approved, you can merge your branch into master.
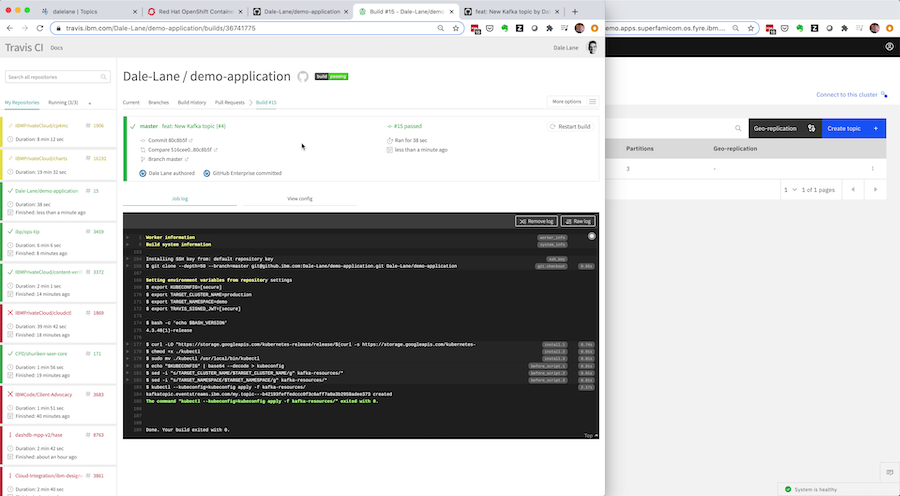
At that point, a Travis job will be started – taking your new custom resource spec requesting a new Kafka topic, and automatically applying it to the production Event Streams cluster instance.
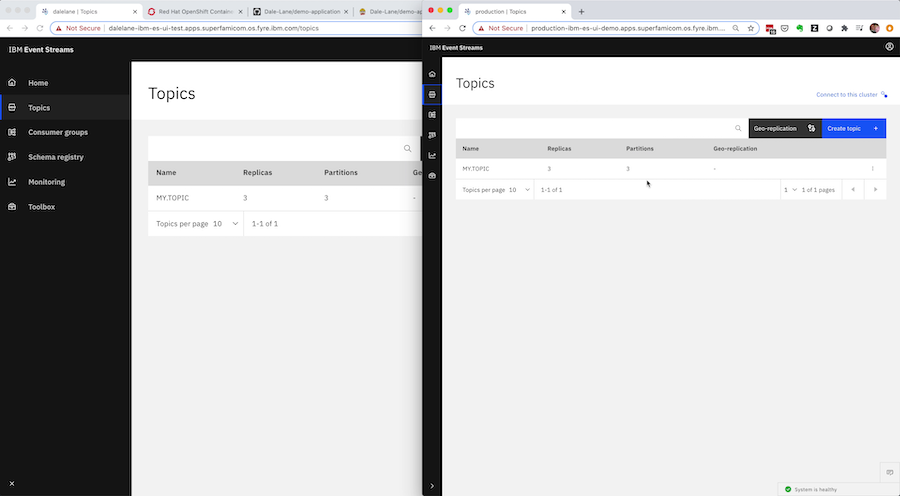
This means the Event Streams Operator managing the production cluster will automatically create your new topic, matching the attributes and config that you had working in the development environment.
To help make this clear, let’s do that again. But this time, you need a new set of Kafka credentials for your application.
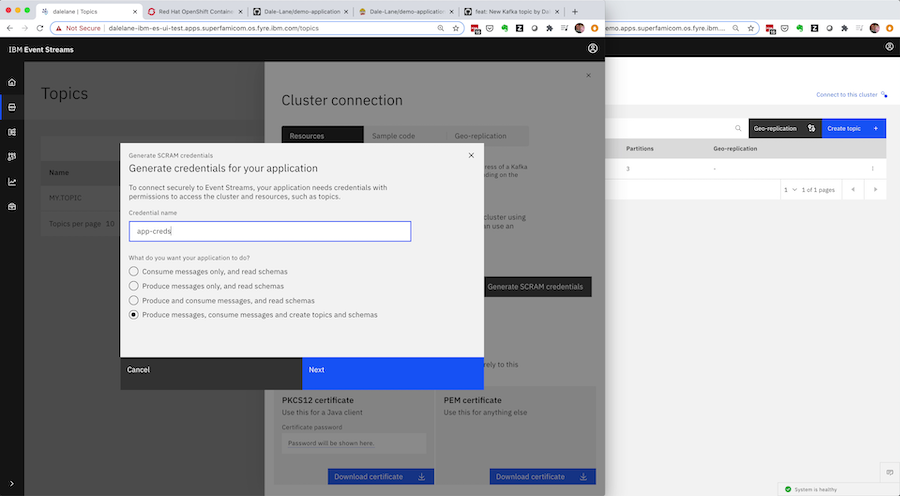
As before, you do this using your development cluster, using the wizard in the Event Streams UI to interactively define credentials with the correct permissions for your application.
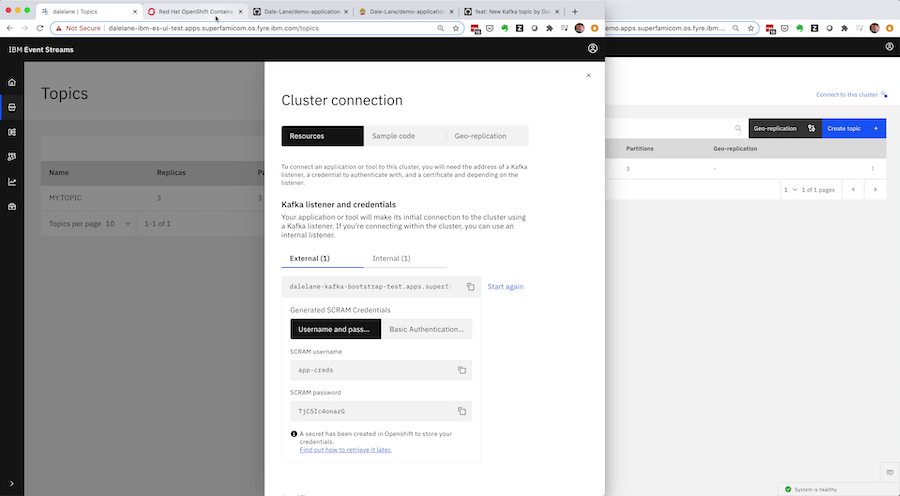
The Event Streams Operator will capture all of this in the custom resource representing the credentials, so once you’re happy that everything is working, you can retrieve the spec from Kubernetes.
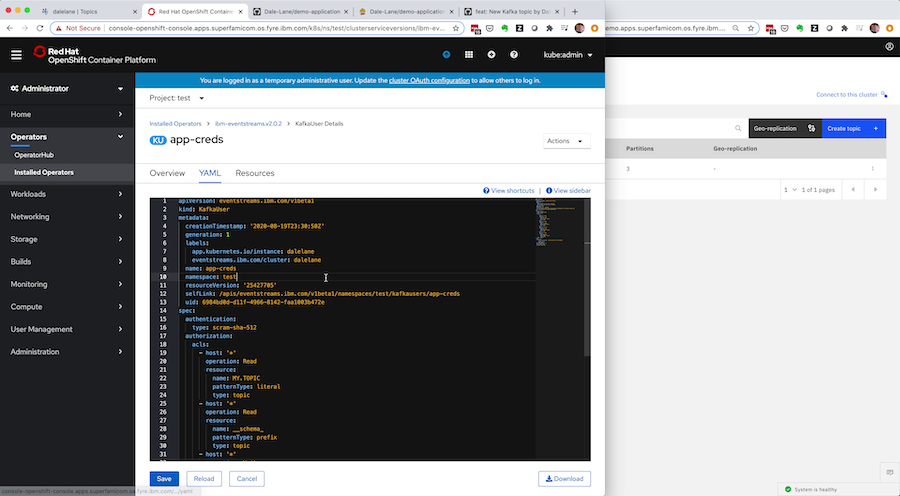
Again, you need to do a tiny bit of editing – removing the dynamic status sections to get just the specification, and replacing the cluster and namespace names with environment variables to make it easier to apply to other clusters.
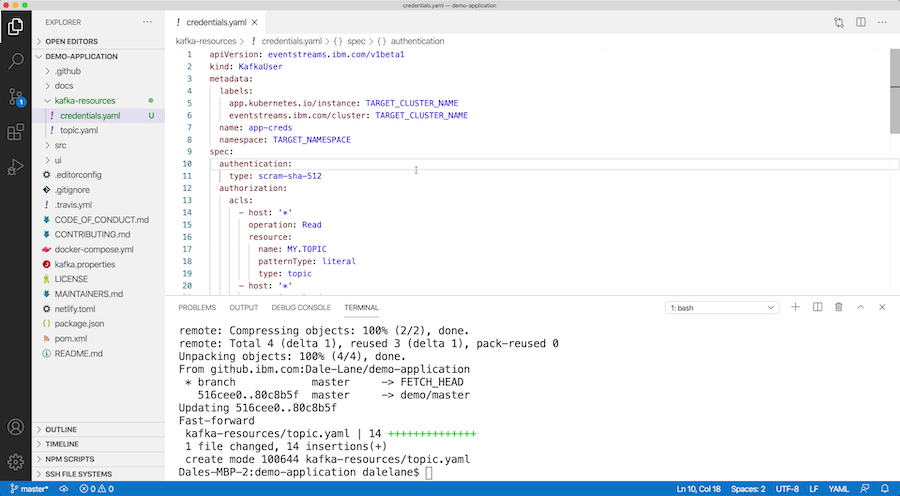
As before, you’re left with a human-readable plain text file that describes what your application needs. This sort of YAML specification might be a bit tricky for a novice user to write from scratch but the admin UI did that for you as a result of clicking through the wizard.
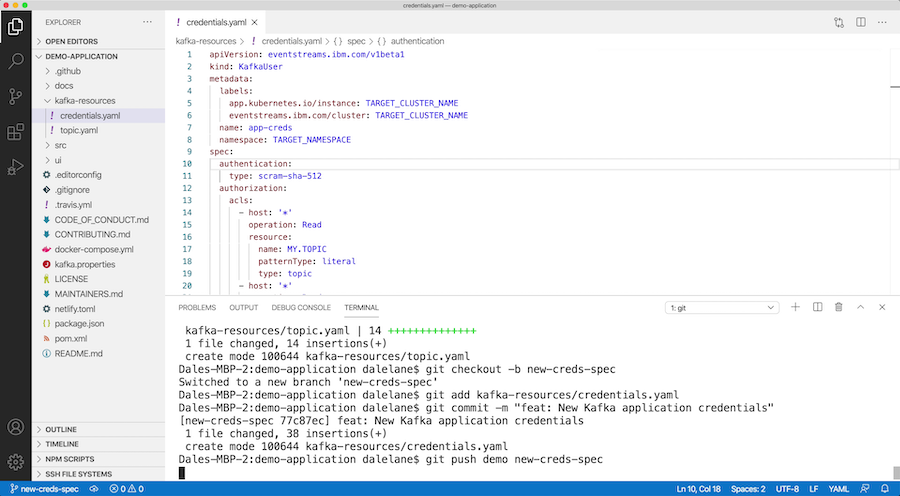
Putting the resulting specification in a pull-request makes it easy for a reviewer to read and follow what is being asked for.

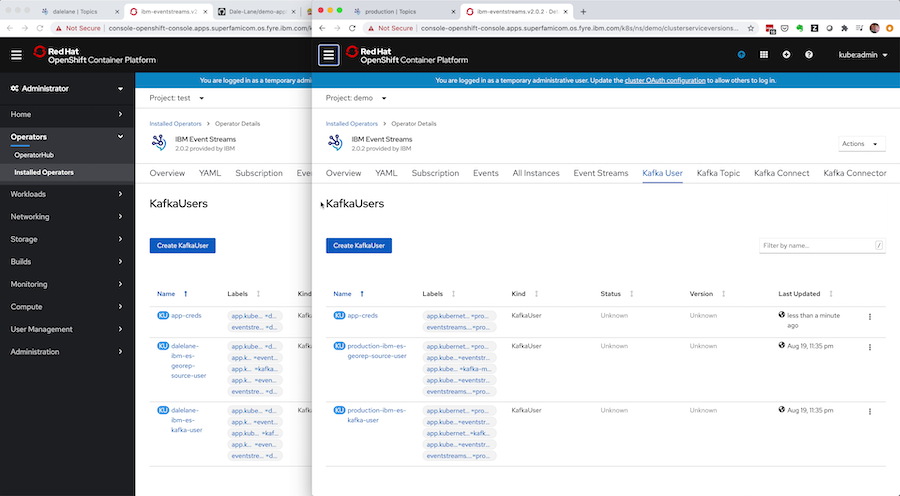
Once this pull-request is approved and merged, Travis runs again, applying the latest change to the production cluster, so the new approved set of credentials are automatically provisioned on the production Event Streams cluster by the Event Streams Operator, with permissions matching what was verified in the development environment.
The admin/ops example
This sort of workflow isn’t just useful for developers. Cluster administrators can use the same approach for managing the deployment of the whole Kafka cluster.
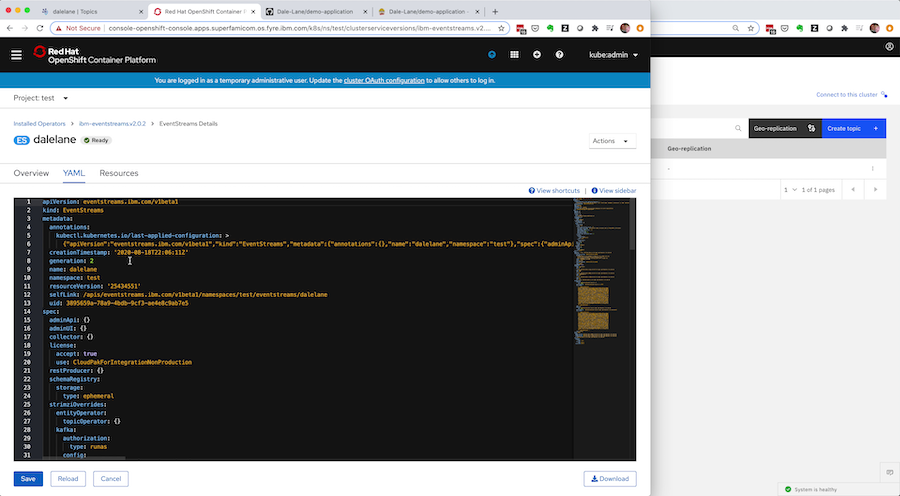
As with everything else in Event Streams, the specification for the Kafka cluster is defined in a Kubernetes custom resource, that you can retrieve in JSON or YAML form.
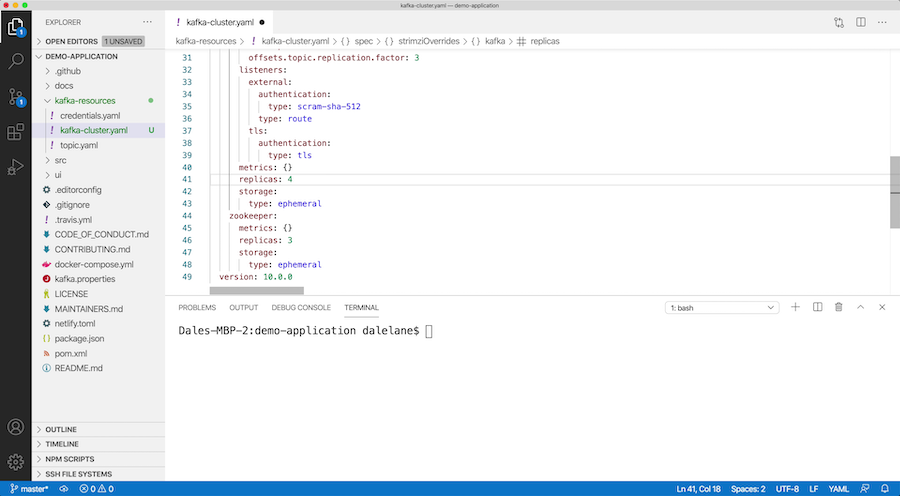
For this example, let’s say you want to make a couple of changes. You want to scale up your Kafka cluster from three brokers to four, so you update the replicas attribute.
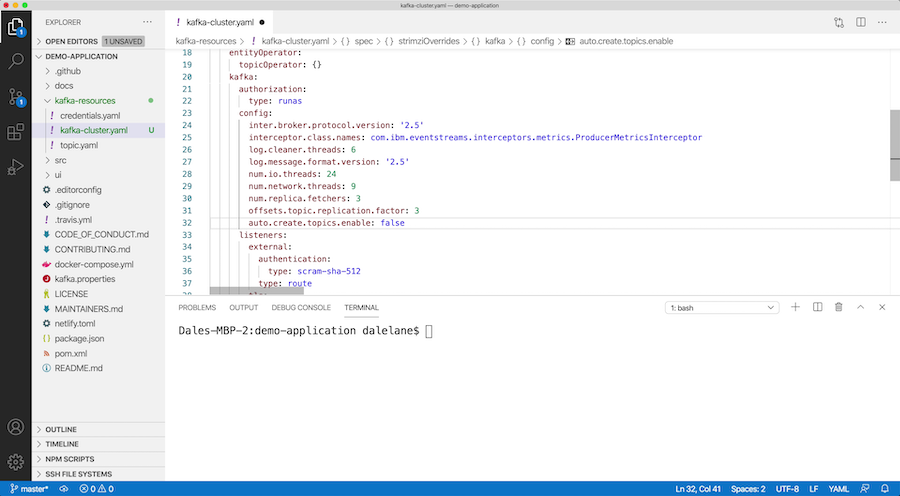
And you want to lock down the broker to prevent topics from being automatically created, so you add that to the Kafka cluster config.
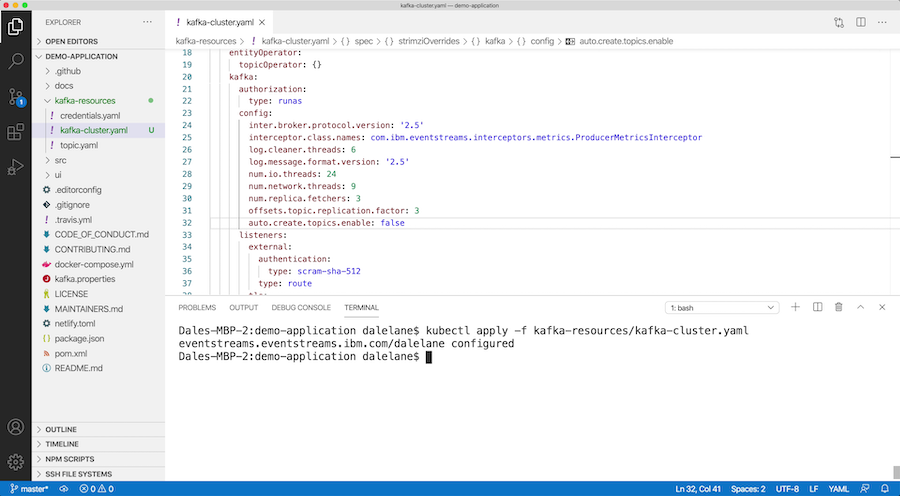
You start by applying this to the development cluster, to make sure that you’re happy with the change.
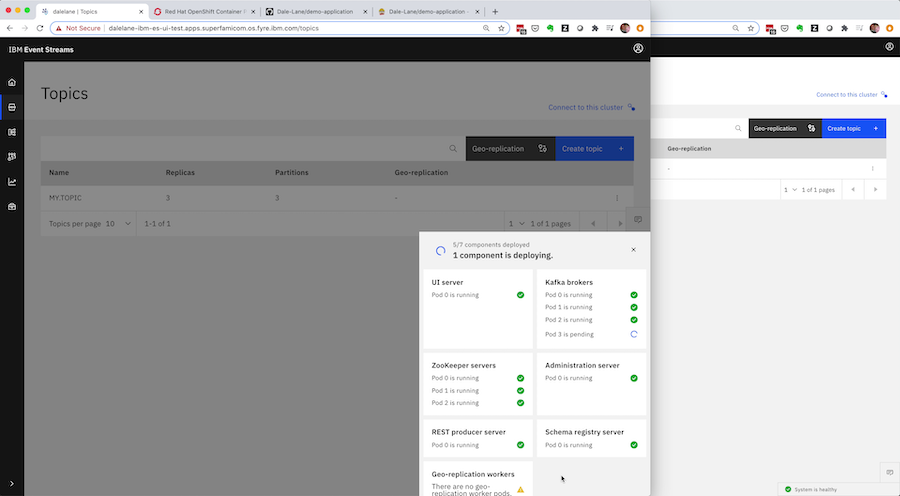
This takes a little while, so if you’re following the video, you might want to fast-forward through this bit!
It’s just watching-and-waiting – there isn’t anything for the administrator to do as the Event Streams Operator takes care of orchestrating the careful roll of the cluster to apply the changes you’ve requested, without any disruption or downtime.
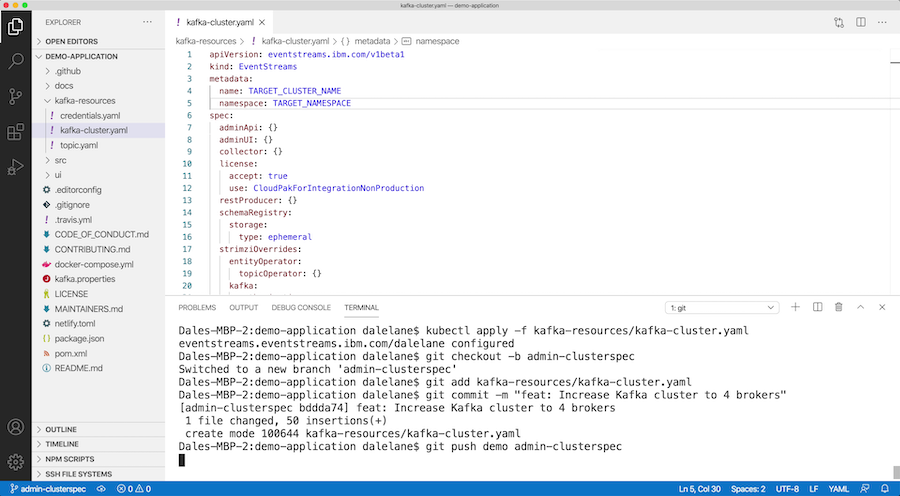
Just like the Kafka topic and client credentials, once you’re happy you can put the YAML specification for the cluster into a GitHub pull-request for review and approval.
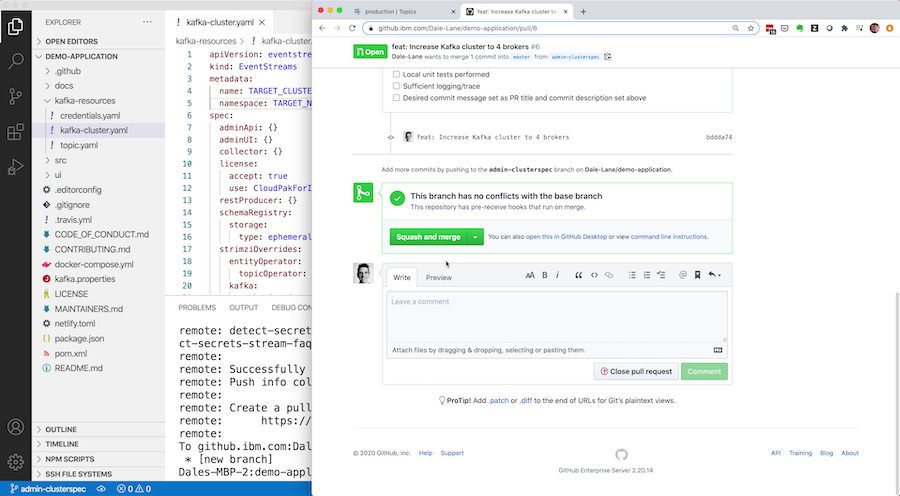
As you can see from this, this means you’re not restricted to creating new things in these changes.
You can use pull-requests to modify the spec for existing things – changing the config for a topic, modifying the permissions for client credentials, and so on.
Every time you want to make a change, that’s another edit to a YAML file in another pull request. And GitHub will keep a full history of all of these changes.
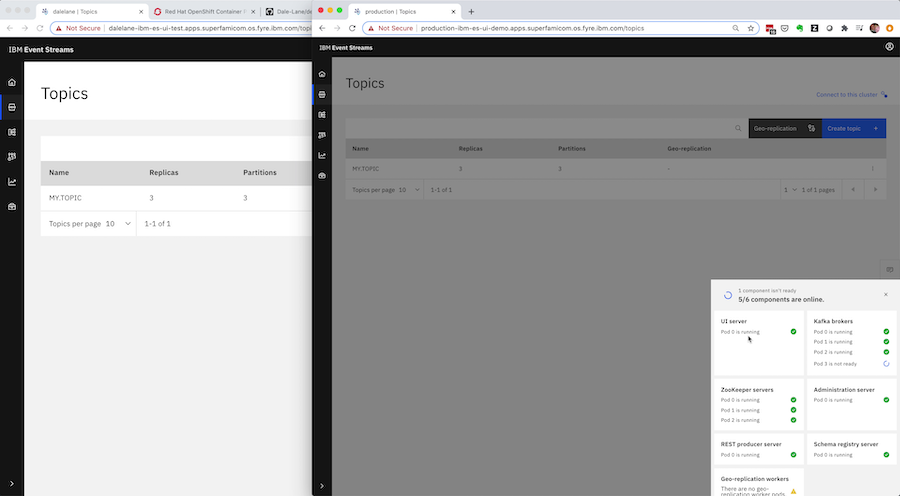
Once the pull-request is merged, Travis will apply the updated spec to the production cluster, and the Event Streams Operator will start rolling that change out to the production instance – updating the Kafka cluster config and scaling up the cluster with an additional broker.
Where all of this is happening
As you can see, it’s easy to retrieve the specifications for all aspects of your Kafka cluster from Event Streams. And because they’re just plain text, they’re easy to store and track in source control systems like GitHub.
The only bit I haven’t shown is how these specifications are being magically being applied to the production cluster.
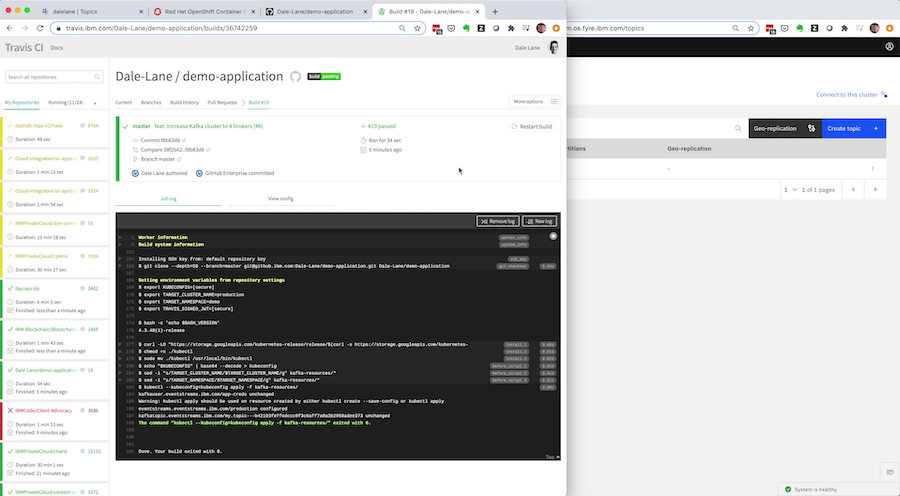
As I mentioned, I used Travis for this, but there are loads of ways to trigger jobs from GitHub so this by no means the only way I could’ve done it.

I needed to give Travis the details for my production Event Streams instance, so I did this using a few environment variables:
KUBECONFIG– with the credentials and address of my production Kubernetes clusterTARGET_CLUSTER_NAME– with the name of my Event Streams instanceTARGET_NAMESPACE– with the name of the Kubernetes namespace where it is running
To get a convenient value for KUBECONFIG, I collapsed all of this down into a single simple string by base64-encoding the contents of my kubectl config.
kubectl config view | base64
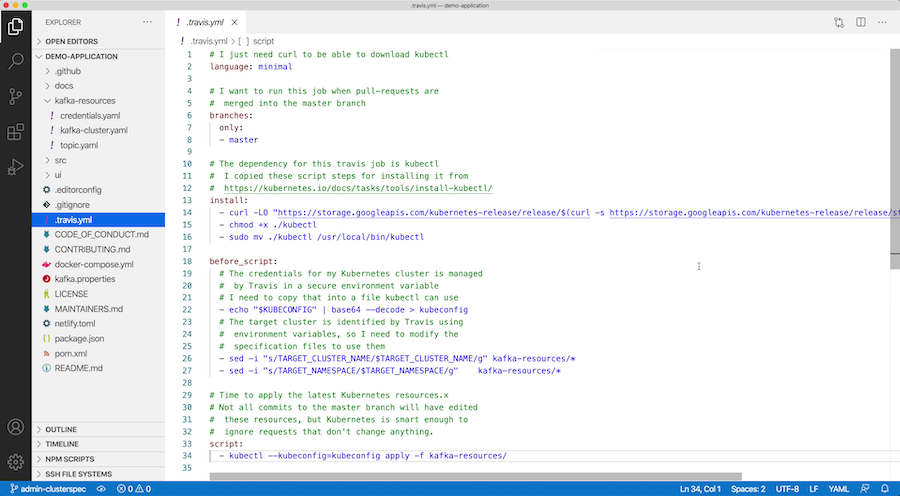
Here is the Travis job I’m using. I’ve added comments to each section so that you can follow what it’s doing:
- download kubectl
- configure it with my
KUBECONFIG - edit the YAML specs to substitute in the target Event Streams instance details
- apply the YAML specs to the production cluster
Putting all of the Kubernetes specs in the same folder means the Travis job doesn’t need updating every time a new spec is added.
# I just need curl to be able to download kubectl language: minimal # I want to run this job when pull-requests are # merged into the master branch branches: only: - master # The dependency for this travis job is kubectl # I copied these script steps for installing it from # https://kubernetes.io/docs/tasks/tools/install-kubectl/ install: - curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl" - chmod +x ./kubectl - sudo mv ./kubectl /usr/local/bin/kubectl before_script: # The credentials for my Kubernetes cluster is managed # by Travis in a secure environment variable # I need to copy that into a file kubectl can use - echo "$KUBECONFIG" | base64 --decode > kubeconfig # The target cluster is identified by Travis using # environment variables, so I need to modify the # specification files to use them - sed -i "s/TARGET_CLUSTER_NAME/$TARGET_CLUSTER_NAME/g" kafka-resources/* - sed -i "s/TARGET_NAMESPACE/$TARGET_NAMESPACE/g" kafka-resources/* # Time to apply the latest Kubernetes resources. # Not all commits to the master branch will have edited # these resources, but Kubernetes is smart enough to # ignore requests that don't change anything. script: - kubectl --kubeconfig=kubeconfig apply -f kafka-resources/
What have we done?
This has all been a long-winded way to demonstrate this:
Developers get a guided experience in an admin UI, helping them to interactively define what they need in a development cluster.
Once they’re happy with it, they retrieve the resulting specifications and put them in GitHub for review.
Once the changes are approved, Travis applies them to the production cluster.
Why is this useful?
This has many benefits, but this post is already longer than I planned, so I won’t go into them here. If you do a web search for “configuration as code” you can find a variety of compelling arguments for why this approach can be great. You get the workflow benefits of an automated rollout of tested and reviewed changes to your production system, a version history for all config changes you make (captured together with and in the context of the related application logic changes), and much more.
What else could I have done?
Loads!
For example, I could’ve used another GitHub branch to support a staging/test Event Streams instance in between development and production. For pull-requests into a develop branch, Travis could apply those changes to a test Event Streams instance. And then only apply the specs to the production Event Streams instance when the changes are promoted to the master branch.
The Travis job I used will create new things and modify existing things, but I could have extended the Travis job to support deleting things as well:
- Adding a folder called
deleted-kafka-resourcesto the application repo - Adding
kubectl delete -f deleted-kafka-resources/to my Travis script
This would allow developers to delete things in a similar way.
For example, a pull-request that moves the topic.yaml file from the kafka-resources folder to the deleted-kafka-resources folder would automatically delete the Kafka topic on the production Event Streams instance once it’s merged.
I’ve described testing as a manual step against the development or test Event Streams instance, but automated testing of configuration changes could be brought into Travis, too.
If you have integration tests for your Kafka application, then these could be run in a Travis job for your pull-request:
- Applying the updated custom-resource specifications to a test Event Streams cluster instance
- Running the integration tests against that modified Event Streams instance
The results from these tests could be made an automated check for the pull-request, giving the reviewer an extra bit of confirmation that the proposed configuration changes have been verified.
And lots more.
As I said at the start, a lot of what I’ve covered here will be true for many Operators, and you could do a very similar demo to what I’ve done here using the open source Strimzi Kafka Operator that Event Streams is based on.
The important point is that the declarative approach to managing complex systems that is enabled by Kubernetes Operators makes it easy to integrate with a broader CI/CD strategy.
Tags: apachekafka, eventstreams, ibmeventstreams, kafka, kubernetes