In this post, I’ll show how to bring posts from open social media networks (Bluesky and Mastodon) into Kafka using Kafka Connect source connectors.
My goal is to be able to populate a Kafka topic with status updates posted to social media.
Rather than to try and do this with the full firehose of all status updates, this is done with status updates that match a search term or hashtag.
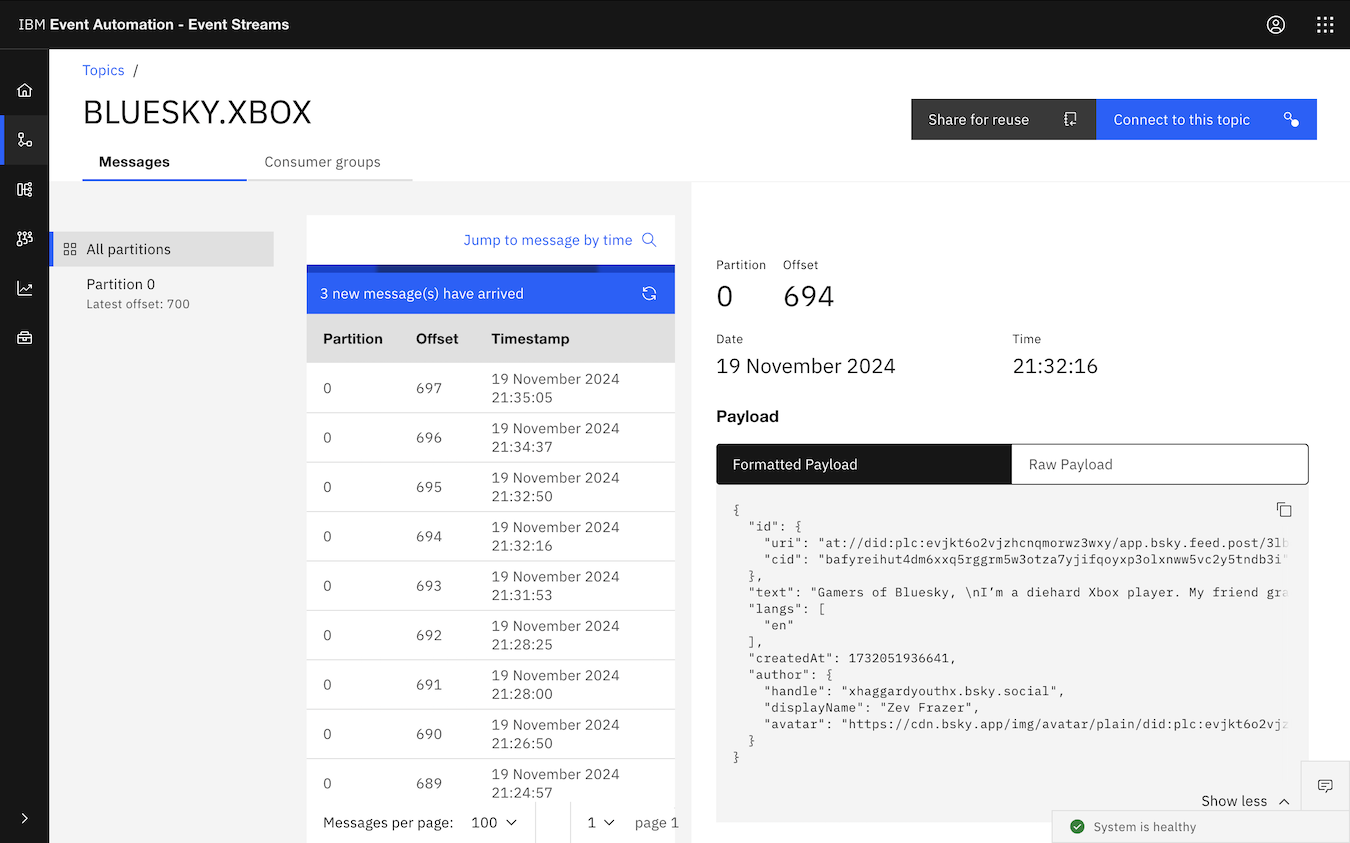
For example, the screenshot above is a Kafka topic with posts from Bluesky that mention the term “xbox”.
Getting the connectors
You can download the jars from my github:
Bluesky : github.com/dalelane/kafka-connect-bluesky-source
Mastodon : github.com/dalelane/kafka-connect-mastodon-source
If you’re running Kafka Connect manually, you need to put these jars in your plugin.path location.
If you’re using Strimzi or IBM Event Streams to build your Kafka Connect workers automatically, you’d point at the jars like:
kind: KafkaConnect
...
spec:
build:
plugins:
# Social media posts from Bluesky
- name: bluesky
artifacts:
- type: jar
url: 'https://github.com/dalelane/kafka-connect-bluesky-source/releases/download/0.0.1/kafka-connect-bluesky-source-0.0.1-jar-with-dependencies.jar'
# Social media posts from Mastodon
- name: mastodon
artifacts:
- type: jar
url: 'https://github.com/dalelane/kafka-connect-mastodon-source/releases/download/0.0.3/kafka-connect-mastodon-source-0.0.3-jar-with-dependencies.jar'
...
You can see an example of this in the context of a whole Kafka Connect spec in my demo repository.
Configuring the connectors
Each of the connector repositories has a README that describes the config options, but essentially you just need to give them:
- credentials for accessing the social media service
- identify which topic you want the status updates to be delivered to
- specify a search term to identify which posts to stream into Kafka
Bluesky
If you’re running a stand-alone Connect instance, the properties file will look something like this:
# name this anything you want name=bluesky-connector # identify the Bluesky connector connector.class=uk.co.dalelane.kafkaconnect.bluesky.source.BlueskySourceConnector # your Bluesky username bluesky.identity=yourusername.bsky.social # an app password - create one at https://bsky.app/settings/app-passwords bluesky.password=aaaa-bbbb-cccc-dddd # the search term to use bluesky.searchterm=thanksgiving # the topic to deliver the Bluesky status updates to bluesky.topic=BLUESKY.THANKSGIVING
If you’re using a distributed Connect cluster, the equivalent REST API request will be:
{
"name": "bluesky-connector",
"config": {
"connector.class": "uk.co.dalelane.kafkaconnect.bluesky.source.BlueskySourceConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"bluesky.identity": "yourusername.bsky.social",
"bluesky.password": "aaaa-bbbb-cccc-dddd",
"bluesky.searchterm": "thanksgiving",
"bluesky.topic": "BLUESKY.THANKSGIVING",
"tasks.max": 1
}
}
If you’re using Strimzi or IBM Event Streams, you can see examples of how to do this in my bluesky-connectors.yaml spec.
Mastodon
If you’re running a stand-alone Connect instance, the properties file will look something like this:
# name this anything you want name=mastodon-connector # identify the Mastodon connector connector.class=uk.co.dalelane.kafkaconnect.mastodon.source.MastodonSourceConnector # a Mastodon token with at least read:search and read:statuses scopes mastodon.accesstoken=REPLACE-THIS-WITH-YOUR-ACCESS-TOKEN # which federated instance of Mastodon to use mastodon.instance=mastodon.org.uk # hashtag to stream to Kafka mastodon.searchterm=thanksgiving # the topic to deliver the Mastodon status updates to mastodon.topic=MASTODON.THANKSGIVING
If you’re using a distributed Connect cluster, the equivalent REST API request will be:
{
"name": "mastodon-connector",
"config": {
"connector.class": "uk.co.dalelane.kafkaconnect.mastodon.source.MastodonSourceConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"mastodon.accesstoken": "REPLACE-THIS-WITH-YOUR-ACCESS-TOKEN",
"mastodon.instance": "mastodon.org.uk",
"mastodon.searchterm": "thanksgiving",
"mastodon.topic": "MASTODON.THANKSGIVING",
"tasks.max": 1
}
}
If you’re using Strimzi or IBM Event Streams, you can see examples of how to do this in my mastodon-connectors.yaml spec.
Output format
The Connectors emit structured records, which means you can use them with your choice of converter – for example, Avro or JSON. (Or even XML if you’re feeling like making your life more challenging.)
As you can see in the example specs above, I’ve been using them to produce JSON events.
Example output
To start with, I’m only outputting a subset of the API responses from Bluesky and Mastodon. I’ve included the properties that I thought would be useful. (I’m very open to suggestions or requests to add additional properties if there is something else you need.)
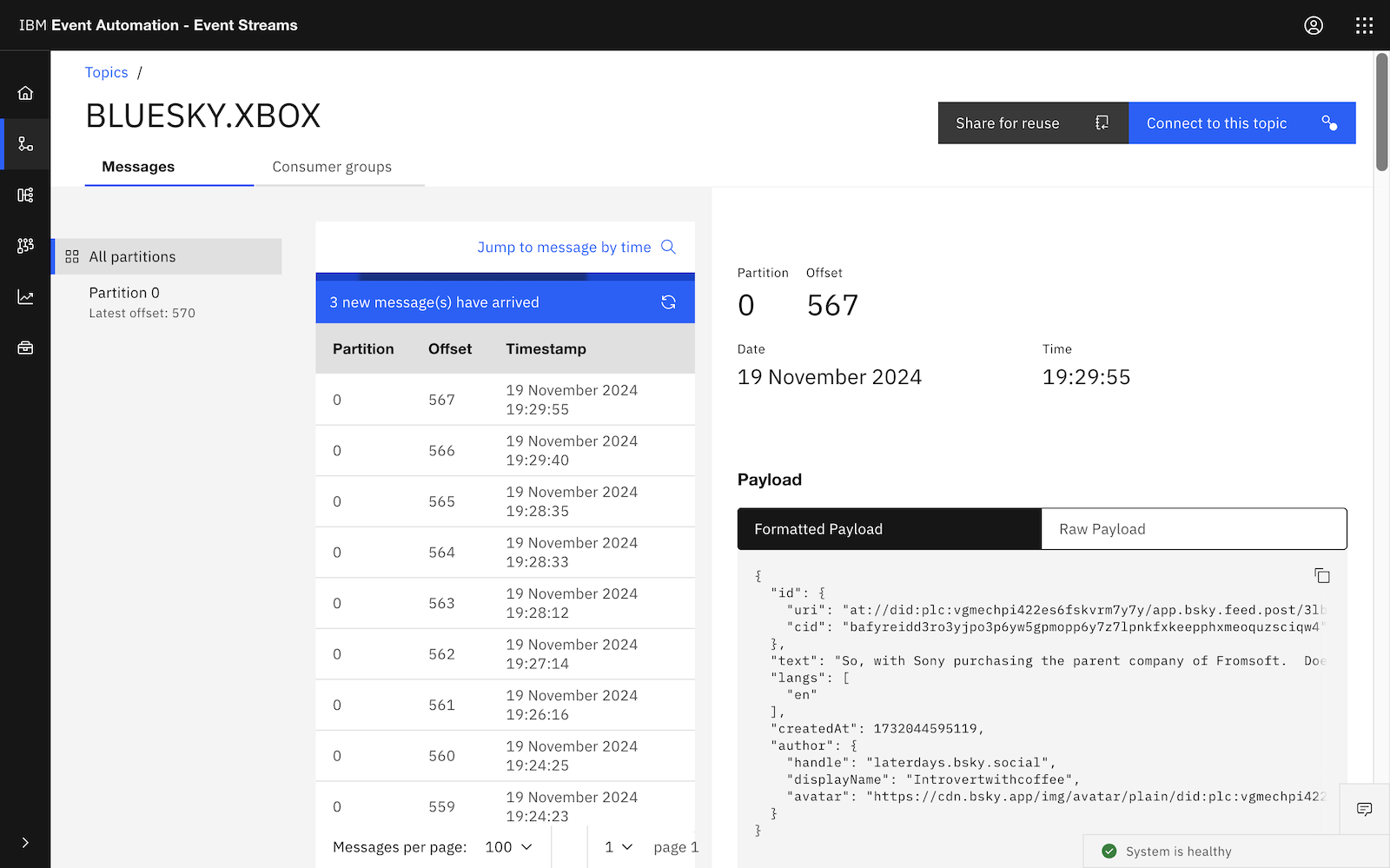
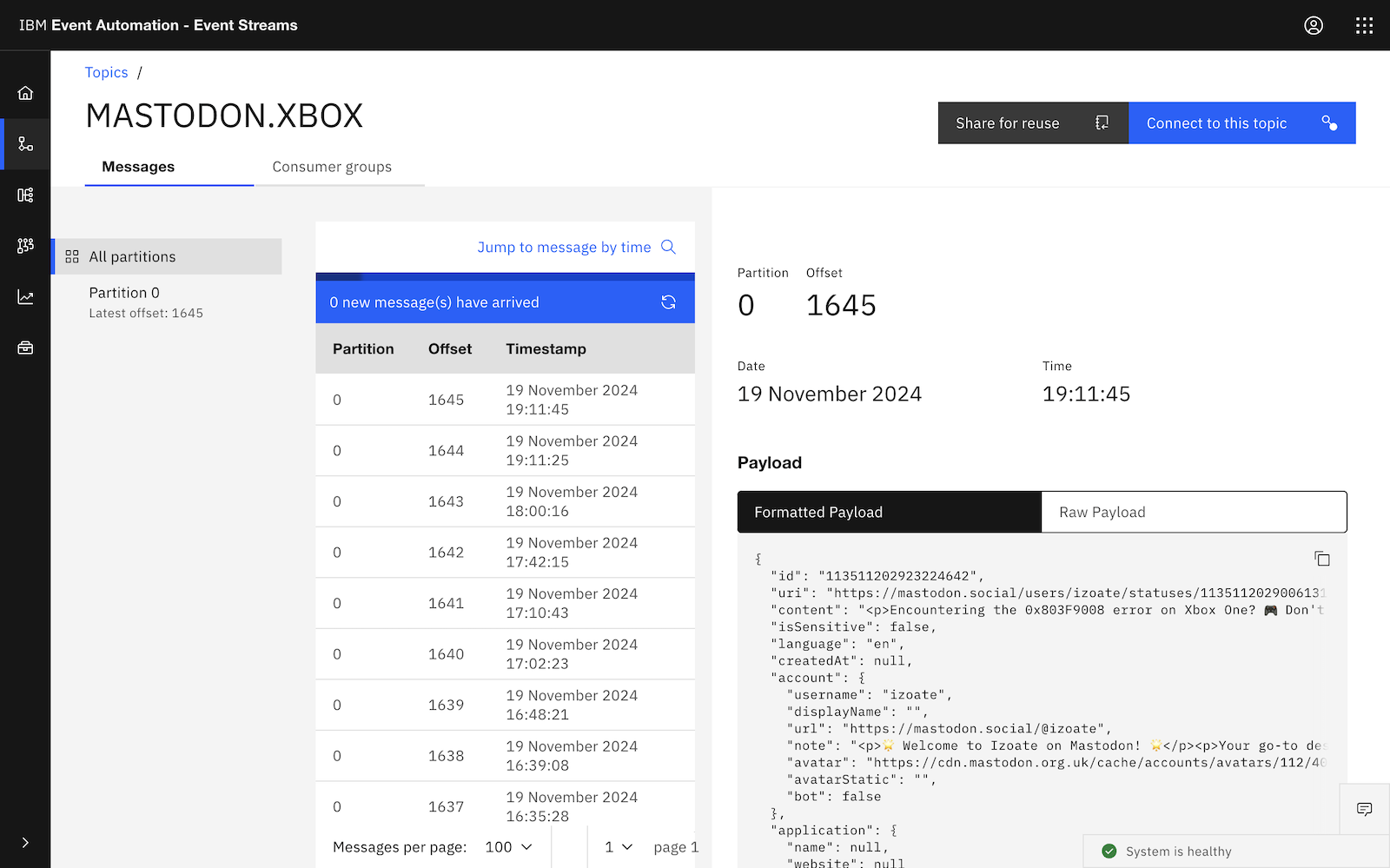
The result is that you get Kafka topics with a constant stream of events with posts from social media.
In the IBM Event Streams UI, this can look something like this:
Processing the events
To finish off, let’s have a quick play using Apache Flink.
For example, I can count how many posts each social media site received per hour for a couple of search terms (“xbox” and “netflix” – which I chose because between The Game Awards and the coverage of the recent boxing match, they are both being talked about this week).
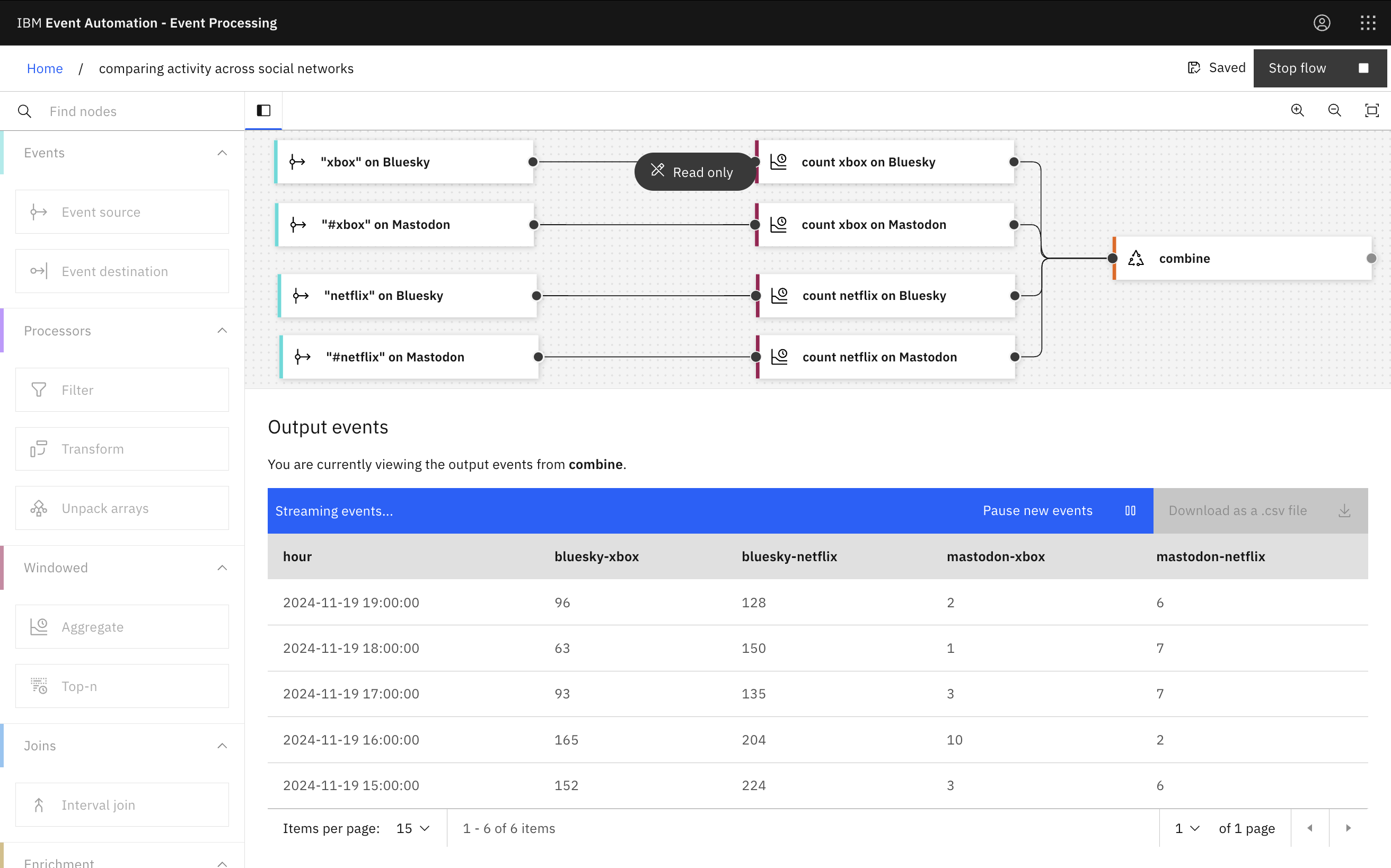
As you can see, I used IBM Event Processing to quickly prototype this Flink job. If you want to see the Flink SQL that was generated under the covers, I put an exported copy (minus a few of the specific properties for my Kafka cluster) in a public gist.
(To be clear, this is in no way a fair or robust analysis of Bluesky activity vs Mastodon. For example, on Bluesky the connector is doing a text search for any updates that mention the word “xbox” or “netflix”. Mastodon doesn’t have a free text search, and the API only lets you fetch posts with an explicit hashtag. Lots of people won’t think to use #xbox or #netflix in their posts, so even this difference alone makes a comparison like this unbalanced.)
For another example of processing social media updates from a Kafka topic, you can see my earlier post on Analysing social media sentiment.
Tags: apachekafka, flink, ibmeventstreams, kafka