In this post, I want to share two examples of how you can use pattern recognition in Apache Flink to turn a noisy stream of output into something useful and actionable.
Imagine that you have a Kafka topic with a stream of events that you sometimes need to respond to.
You can think of this conceptually as being a stream of values that could be plotted against time.
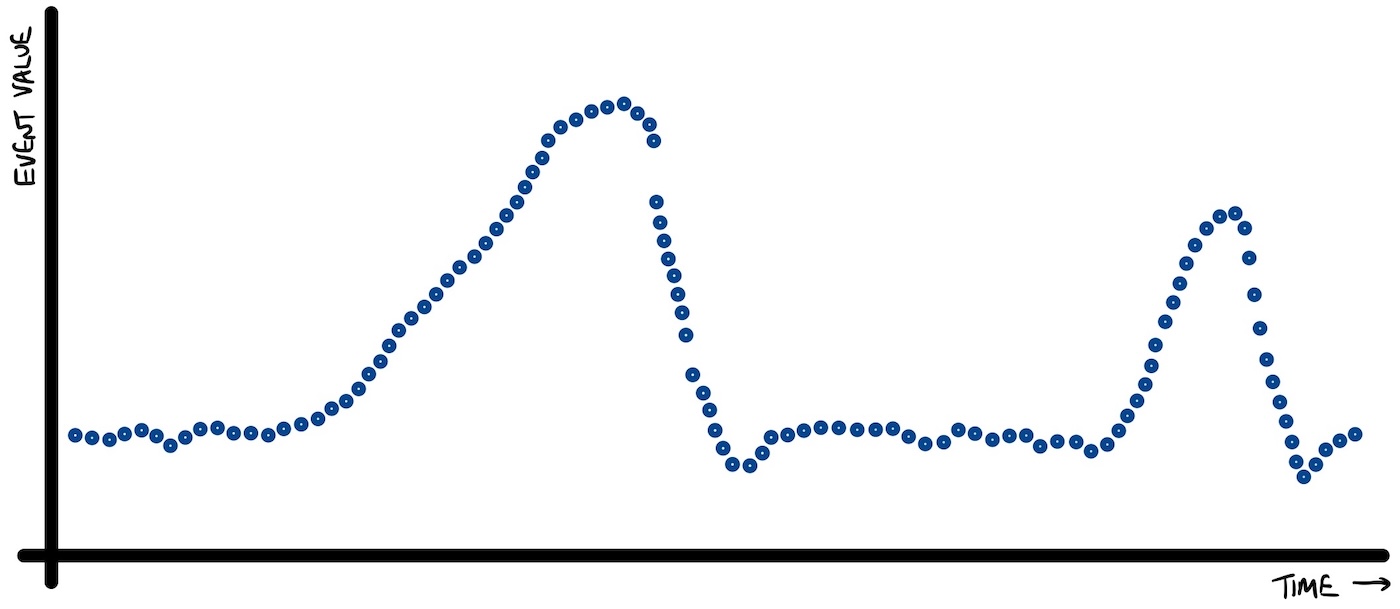
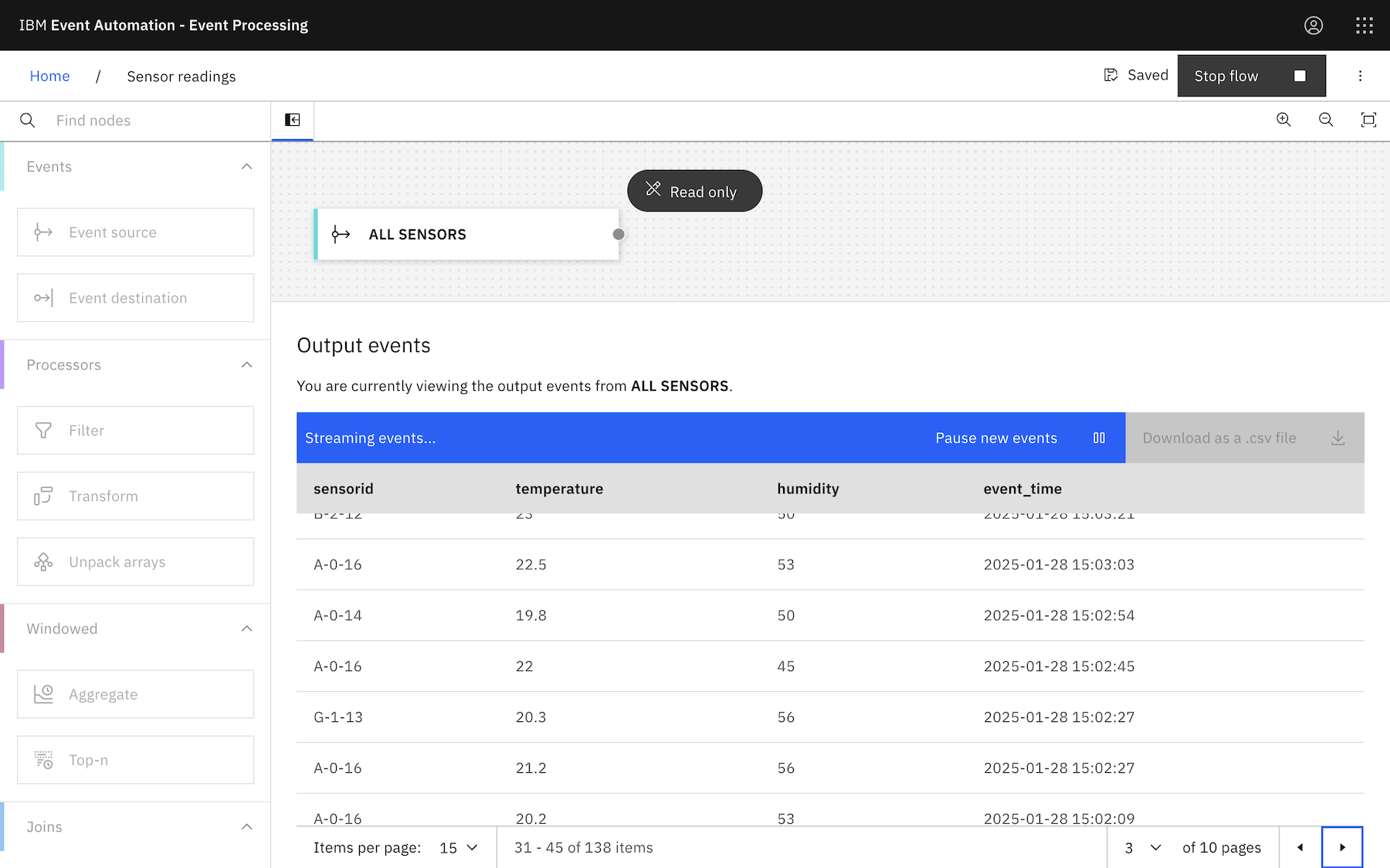
To make this less abstract, we can use the events from the sensor readings topic that the “Loosehanger” data generator produces to. Those events are a stream of temperature and humidity readings.
Imagine that these events represent something that you might need to respond to when the event for a sensor exceeds some given threshold.
You can think of it visually like this:
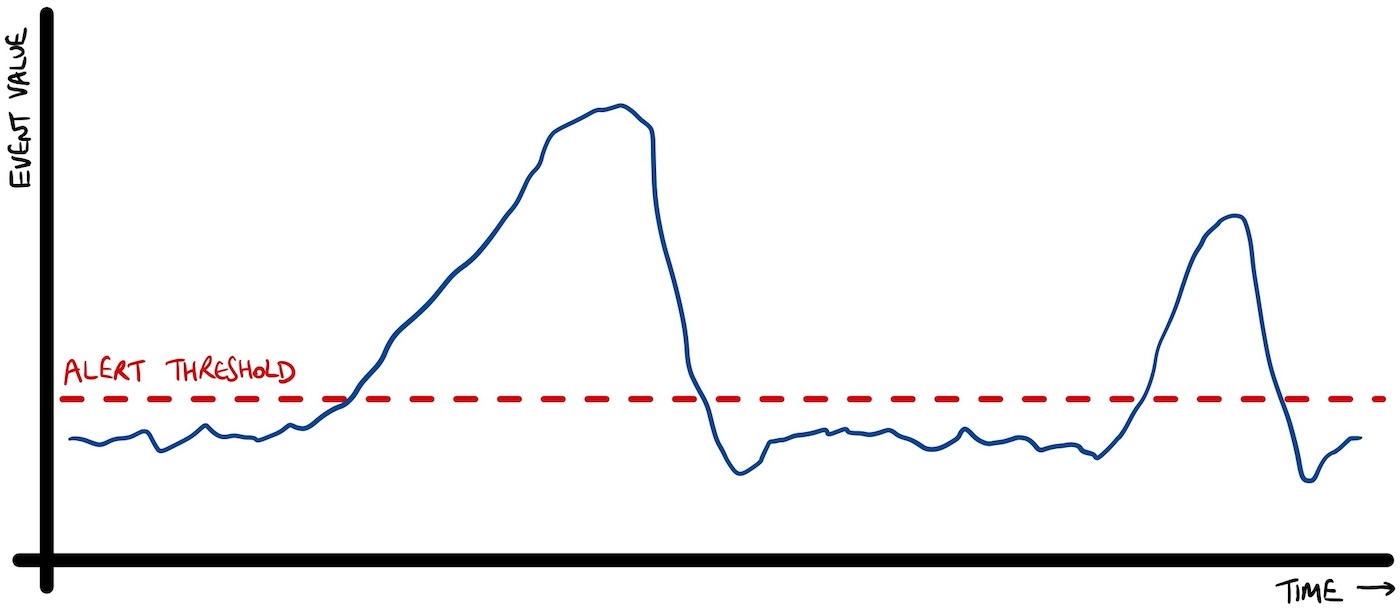
When the events contain values that are over the threshold, this is something that you care about. This is something you need to respond to.
You might just think of that as a filtering use case.
For the “Loosehanger” sensor readings, that could be filtering on sensor readings with temperature or humidity readings that exceed a threshold.
In Flink SQL, that would be something like this:
SELECT
*
FROM
`ALL SENSORS`
WHERE
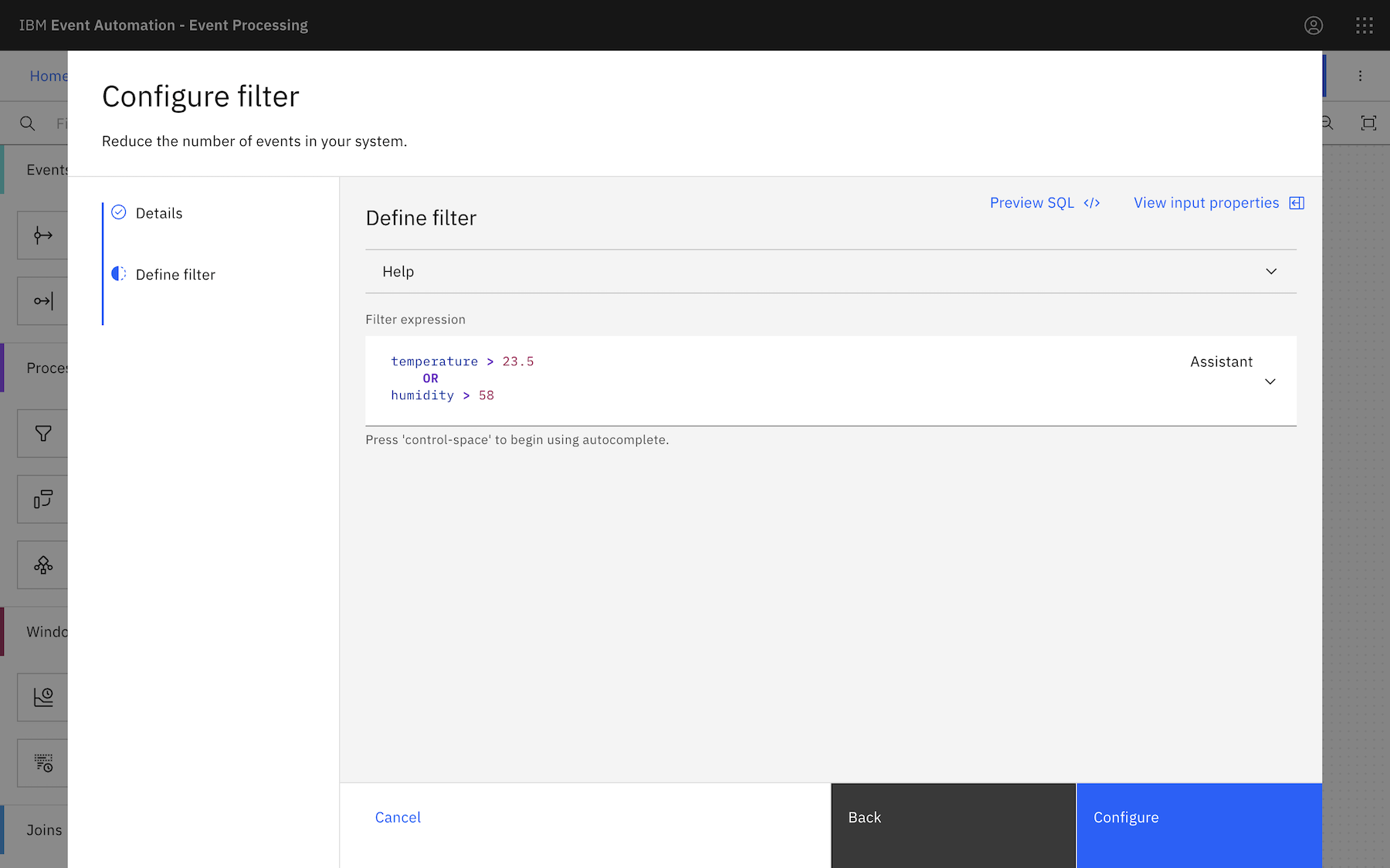
temperature > 23.5
OR
humidity > 58;
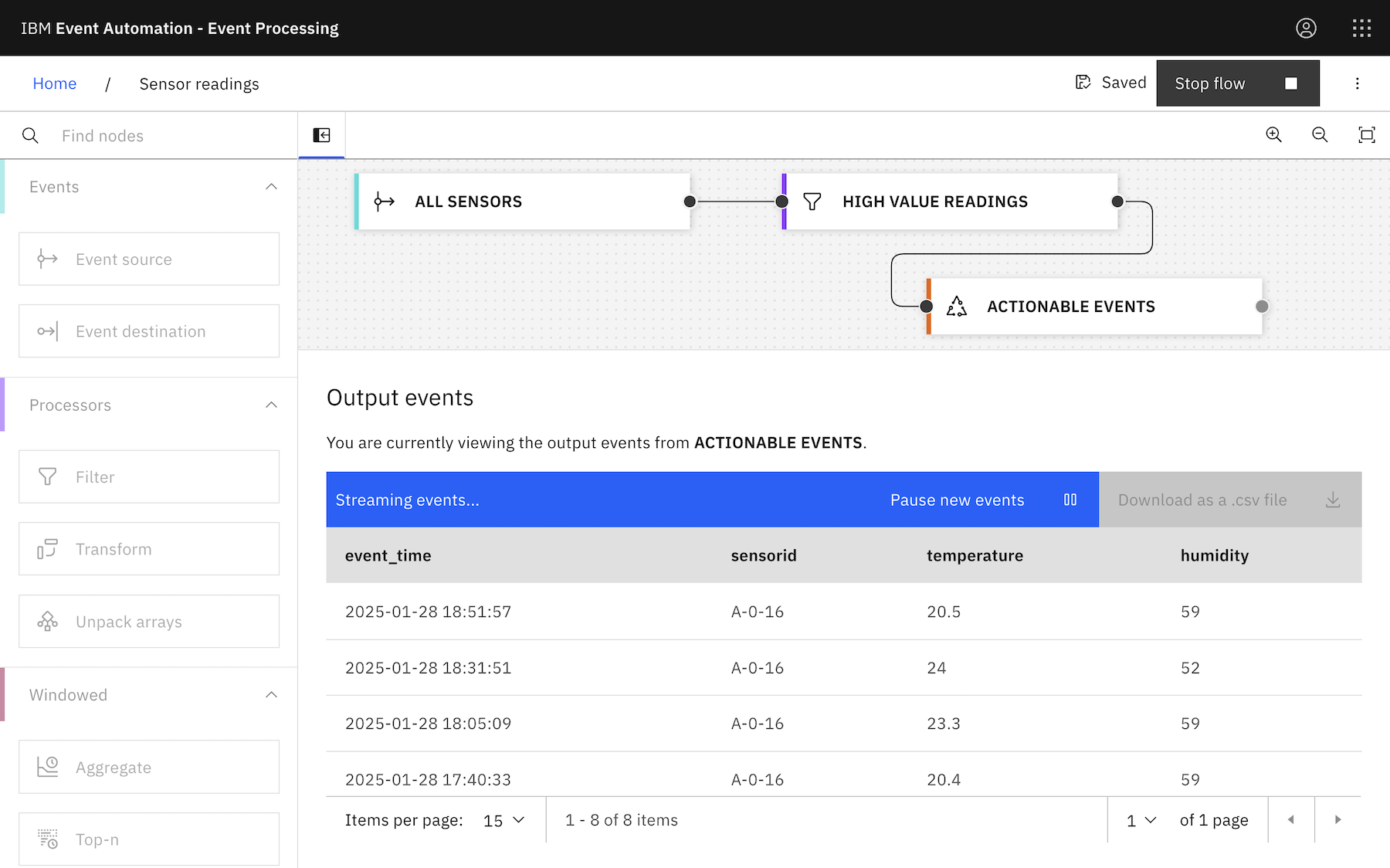
If you use the Event Processing UI to create that, it would look like this:
A Flink job like this will output all events with values that indicate something needs attention.
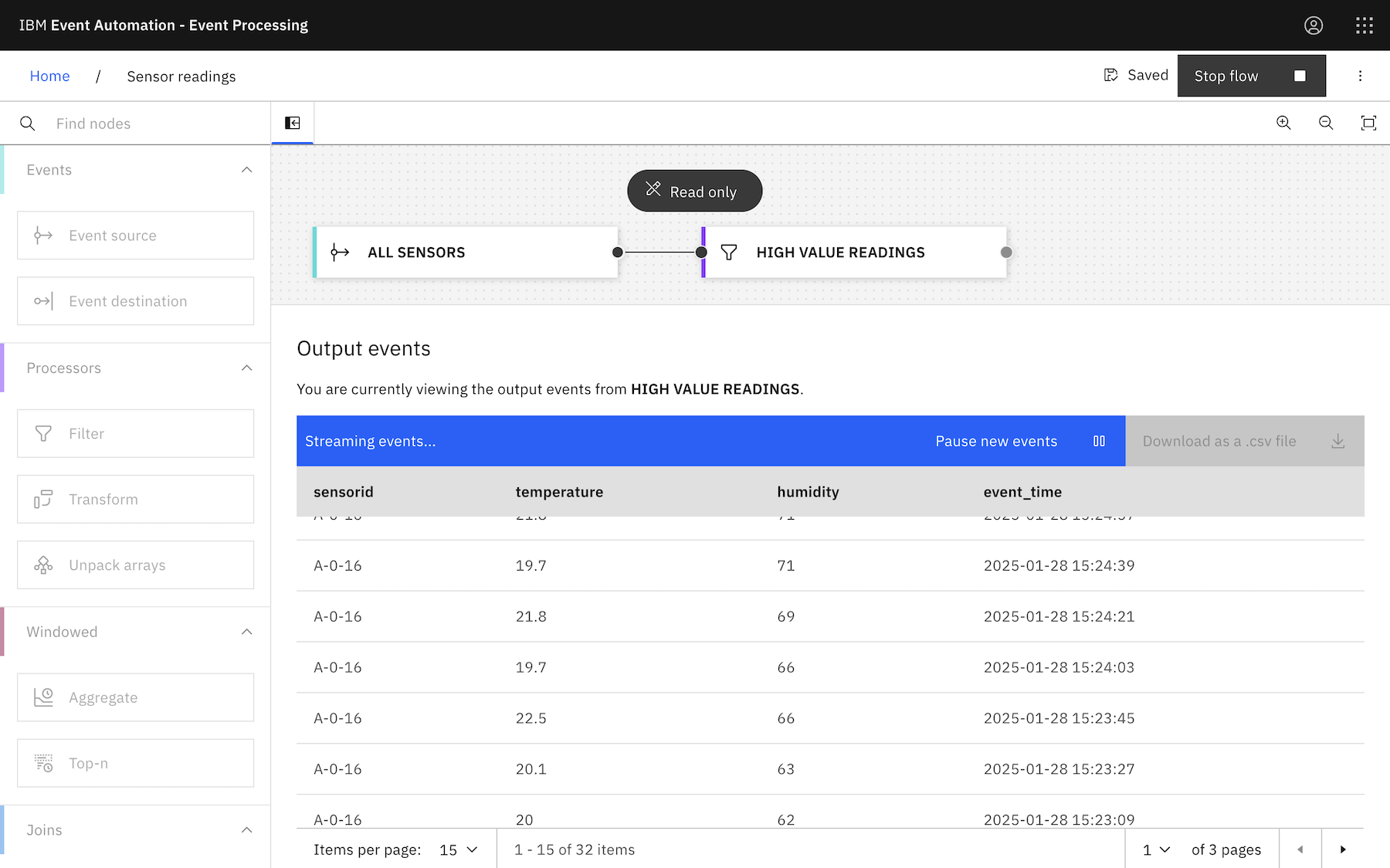
The result of a processing flow like this is likely a large and “noisy” burst of output throughout the time while something needs attention.
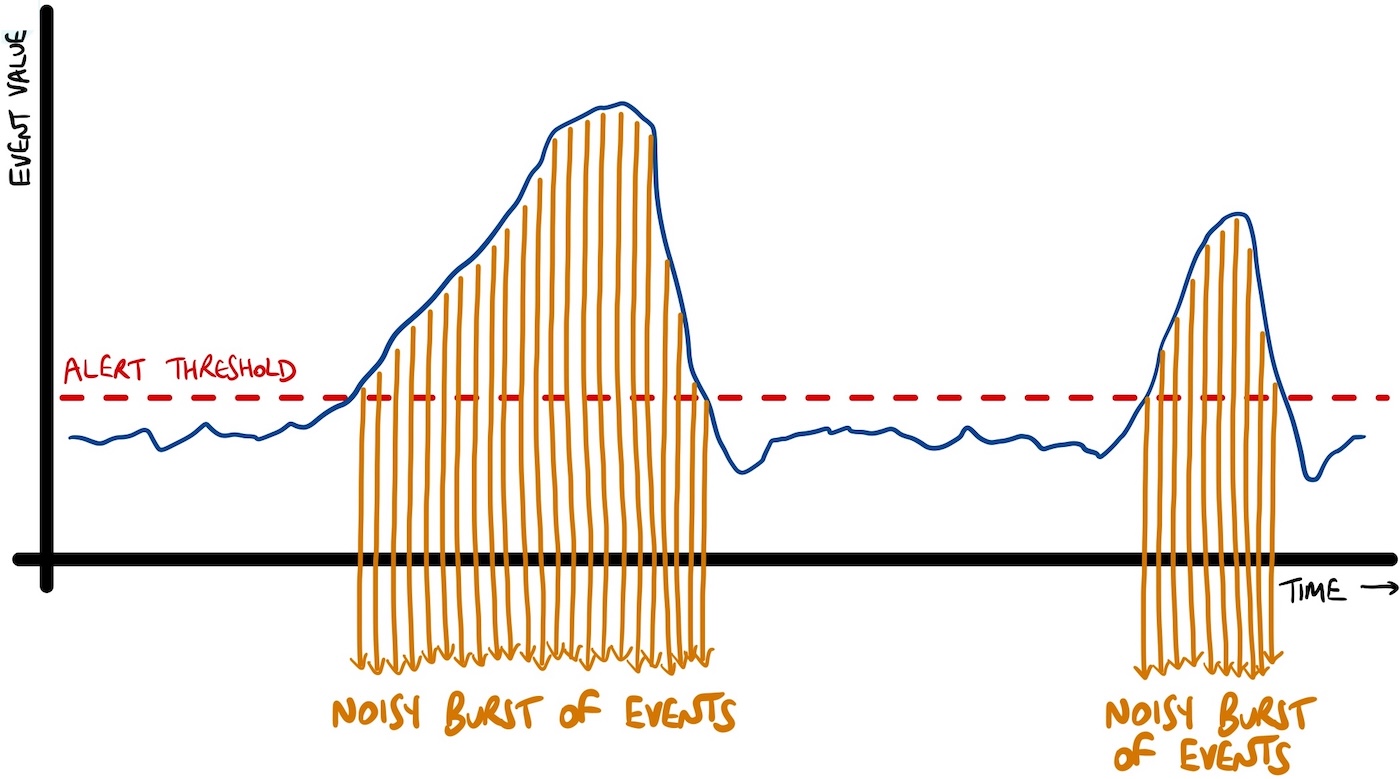
Is that helpful output?
After the first event, are the next hundred events you get still useful?
Probably not.
You probably want output that looks more like this:
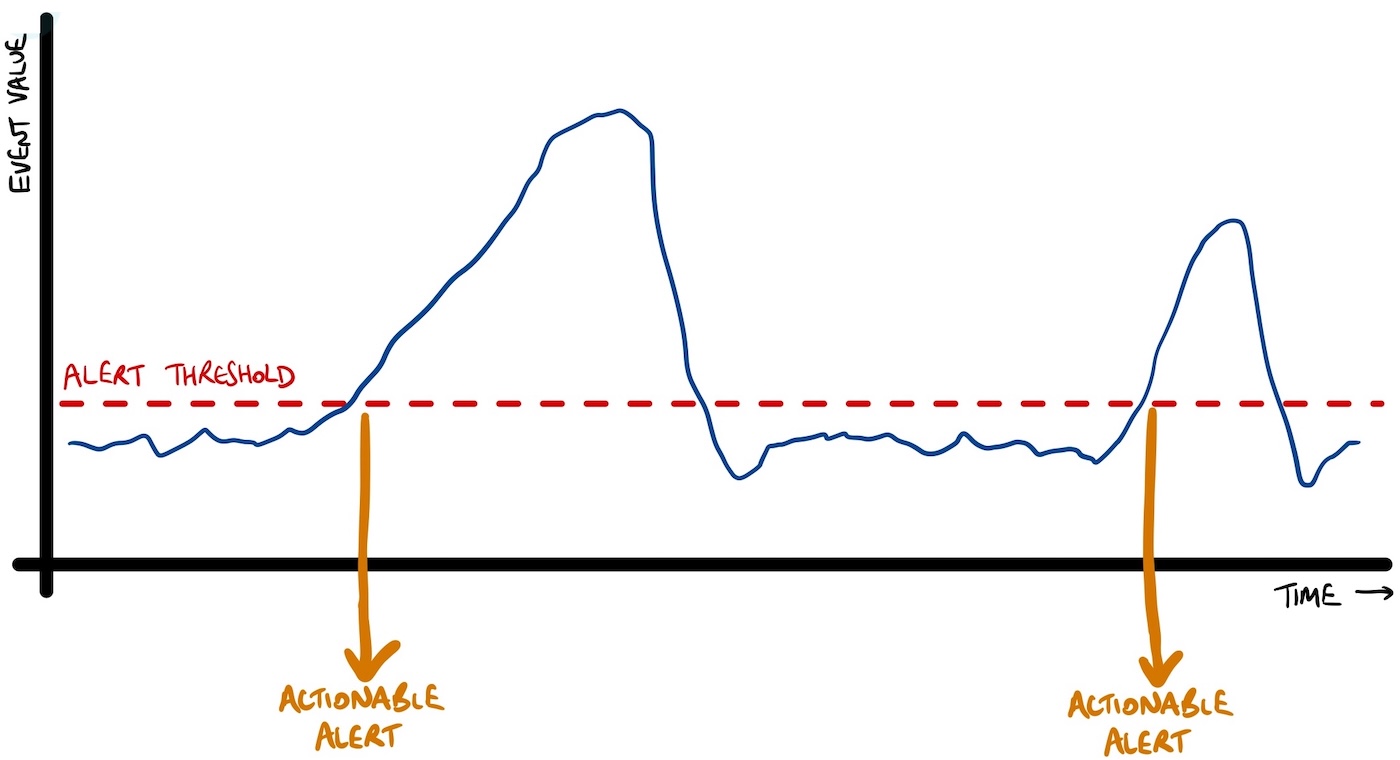
You want to know when the events indicate that something has happened that needs your attention. While you’re responding to that, you don’t want to be disturbed with more notifications until the next time it happens.
There are several different ways you can implement this. Here are two easy ways to approach it.
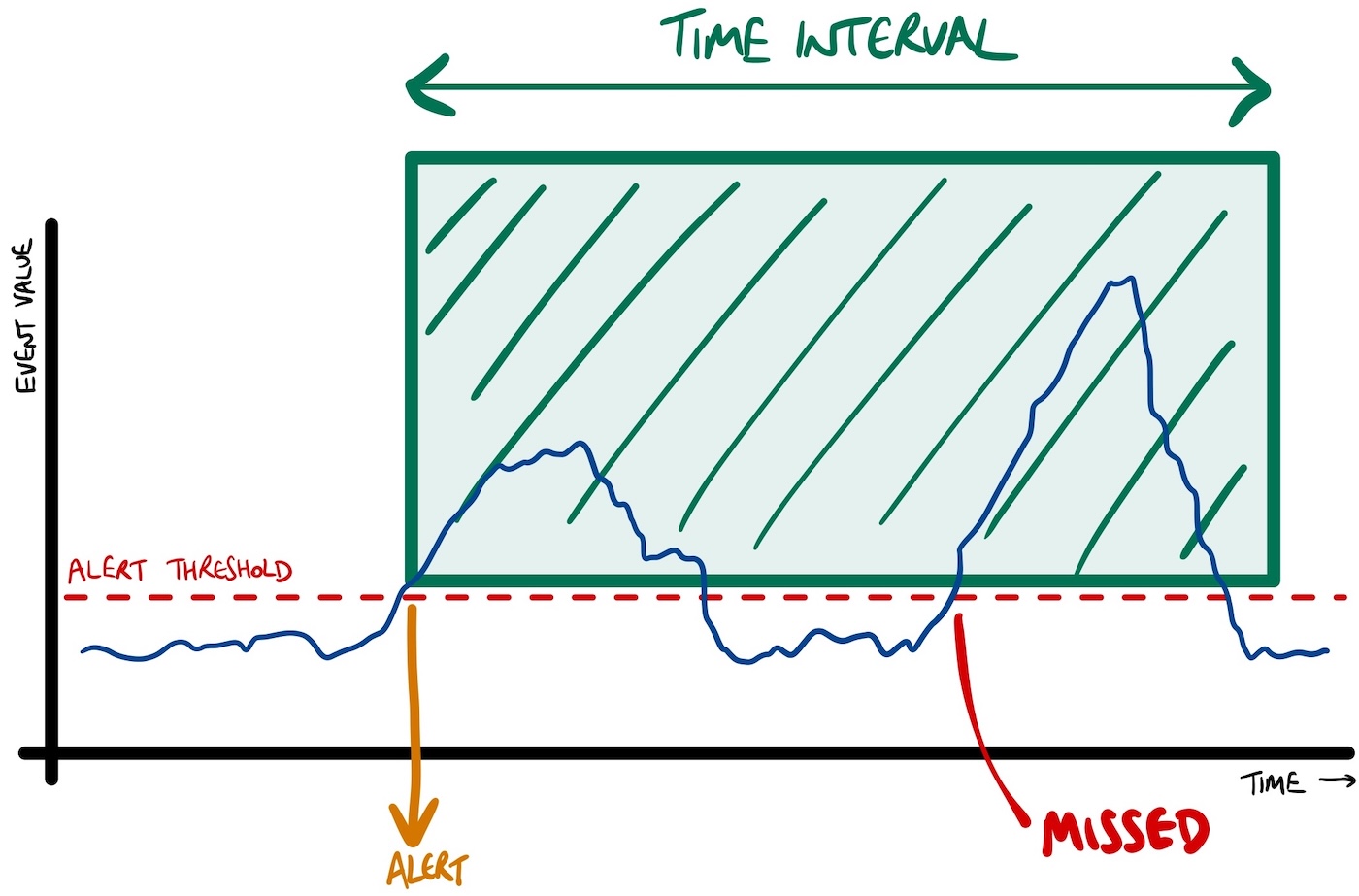
approach 1 : time-based
After emitting an actionable alert, you could ignore any subsequent events (that contain values over the threshold) for a fixed time interval.
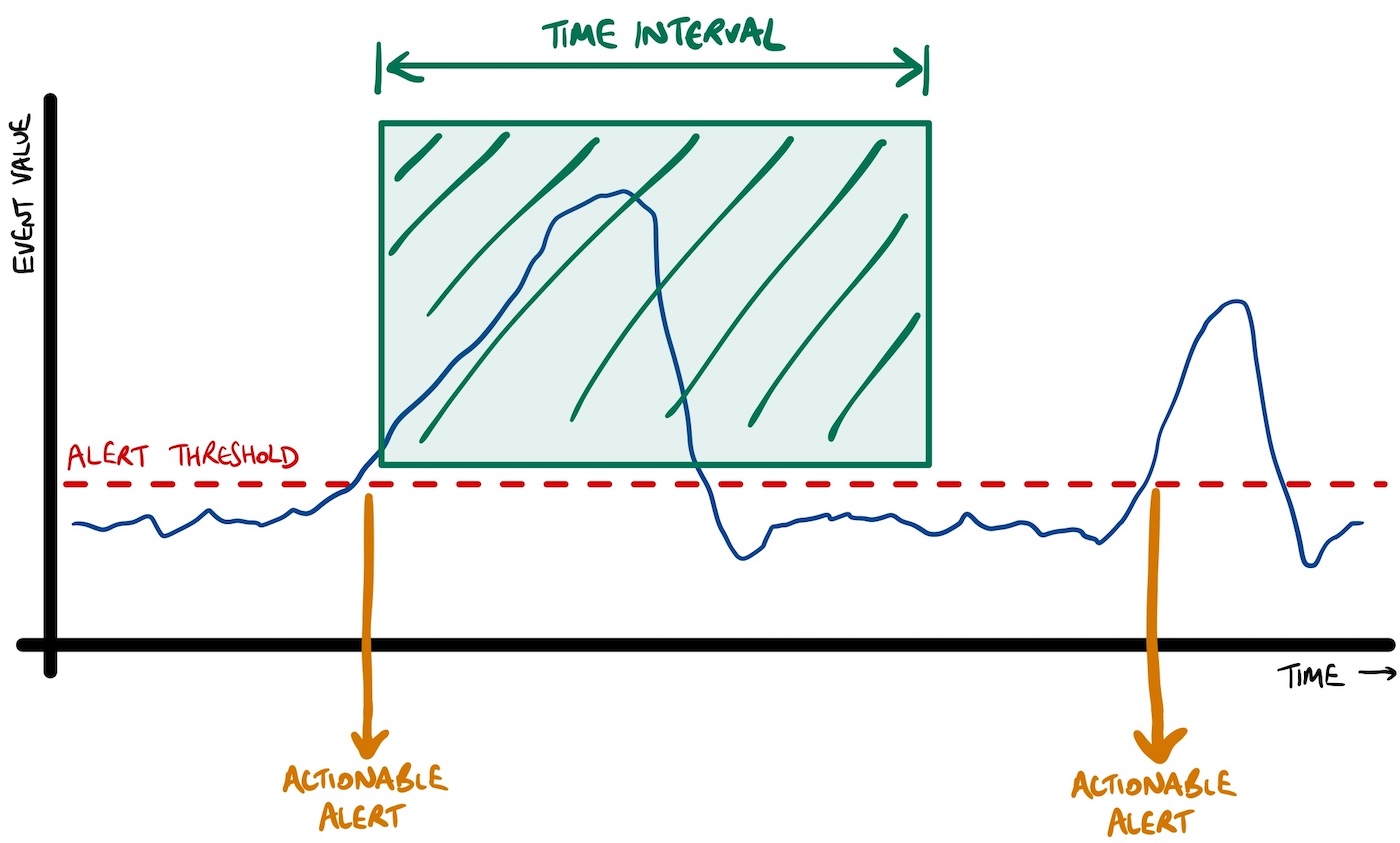
After an actionable alert, you can assume that the issue will be given attention. You can assume someone will look at it and fix it. This means there is no need to trigger additional alerts for a short time afterwards.
For example, doing this with the “Loosehanger” sensor events using a time interval of 10 minutes:
CREATE TEMPORARY VIEW MATCHREC AS
SELECT
*
FROM
`HIGH VALUE READINGS`
MATCH_RECOGNIZE (
PARTITION BY
sensorid
ORDER BY
event_time
MEASURES
LAST(AFTER_TIME_INTERVAL.event_time) AS event_time,
LAST(AFTER_TIME_INTERVAL.temperature) AS temperature,
LAST(AFTER_TIME_INTERVAL.humidity) AS humidity
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST AFTER_TIME_INTERVAL
PATTERN (
LAST_ALERT DURING_TIME_INTERVAL* AFTER_TIME_INTERVAL
)
DEFINE
DURING_TIME_INTERVAL AS
event_time <= TIMESTAMPADD(MINUTE, 10, LAST_ALERT.event_time),
AFTER_TIME_INTERVAL AS
event_time > TIMESTAMPADD(MINUTE, 10, LAST_ALERT.event_time)
);
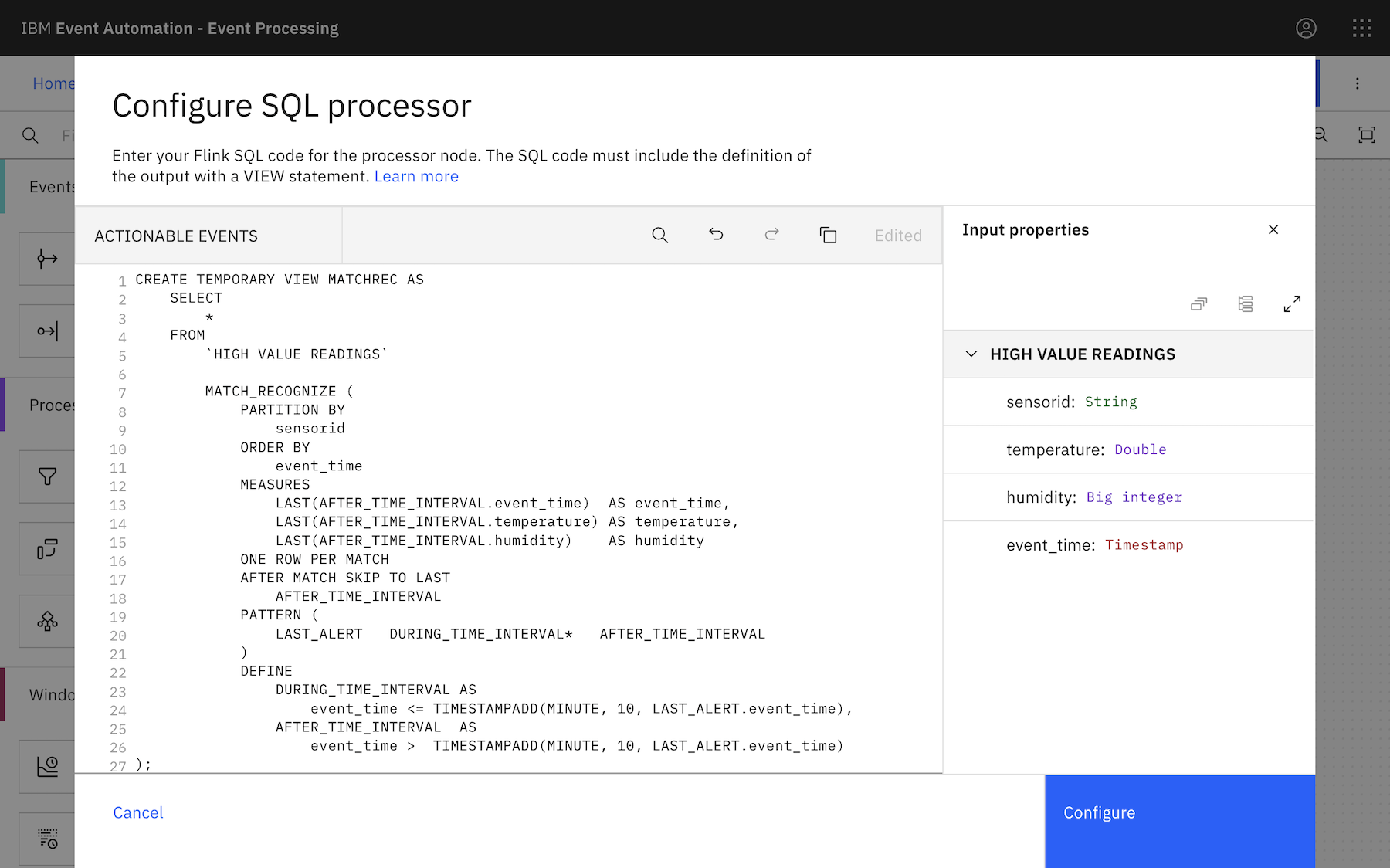
This is a pattern that you want Flink to recognize:
- the last alert that was emitted (for a given sensor id)
- followed by zero-or-more events from the same sensor – (which have timestamps within 10 minutes of the alert)
- followed by an event from the same sensor – (which has a timestamp that is more than 10 minutes after the alert)
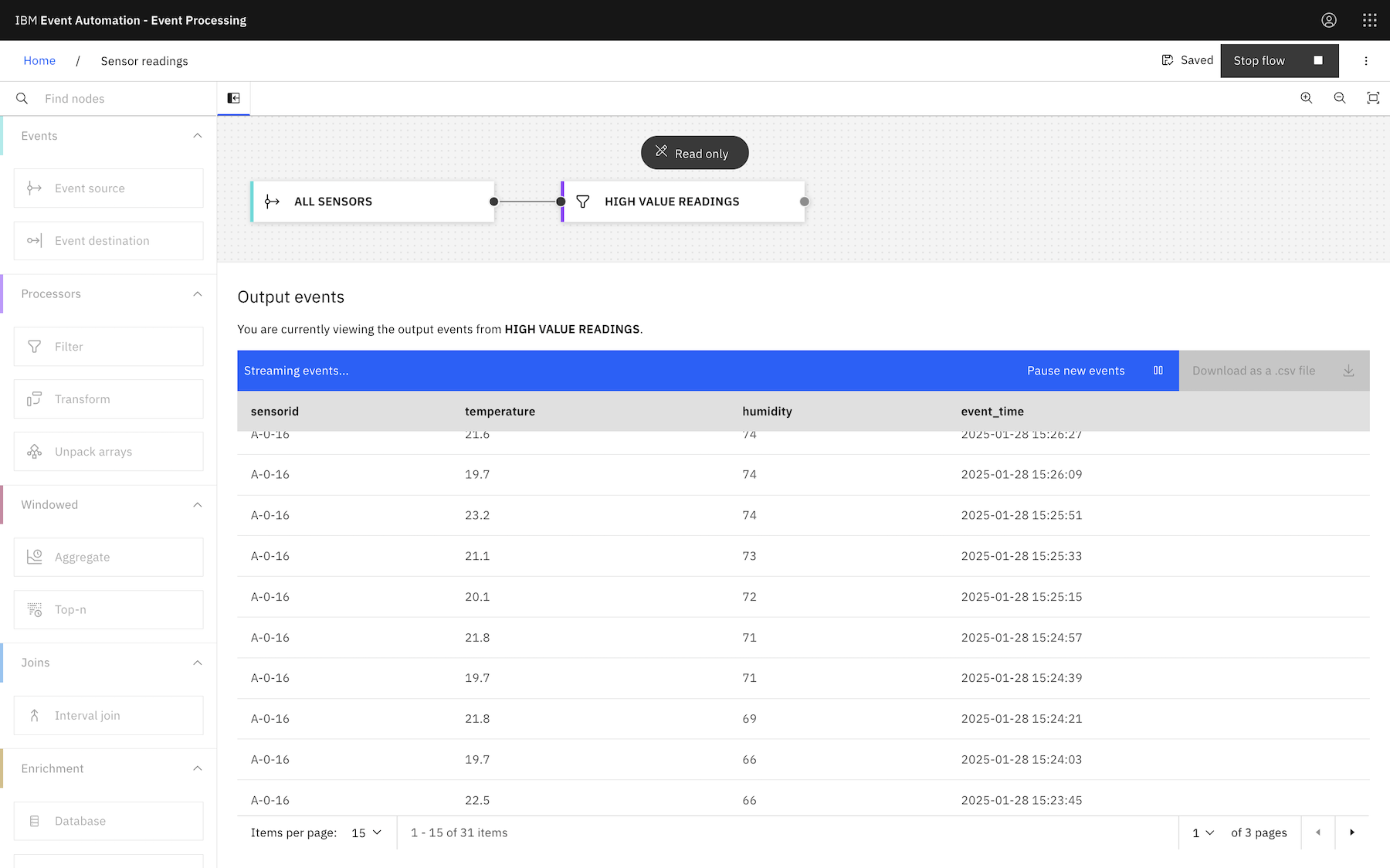
This results in a much cleaner output that will be easier to consume:
option 2 : threshold-based
After emitting an actionable alert, you can ignore any subsequent events until the next time the value goes below the threshold again.
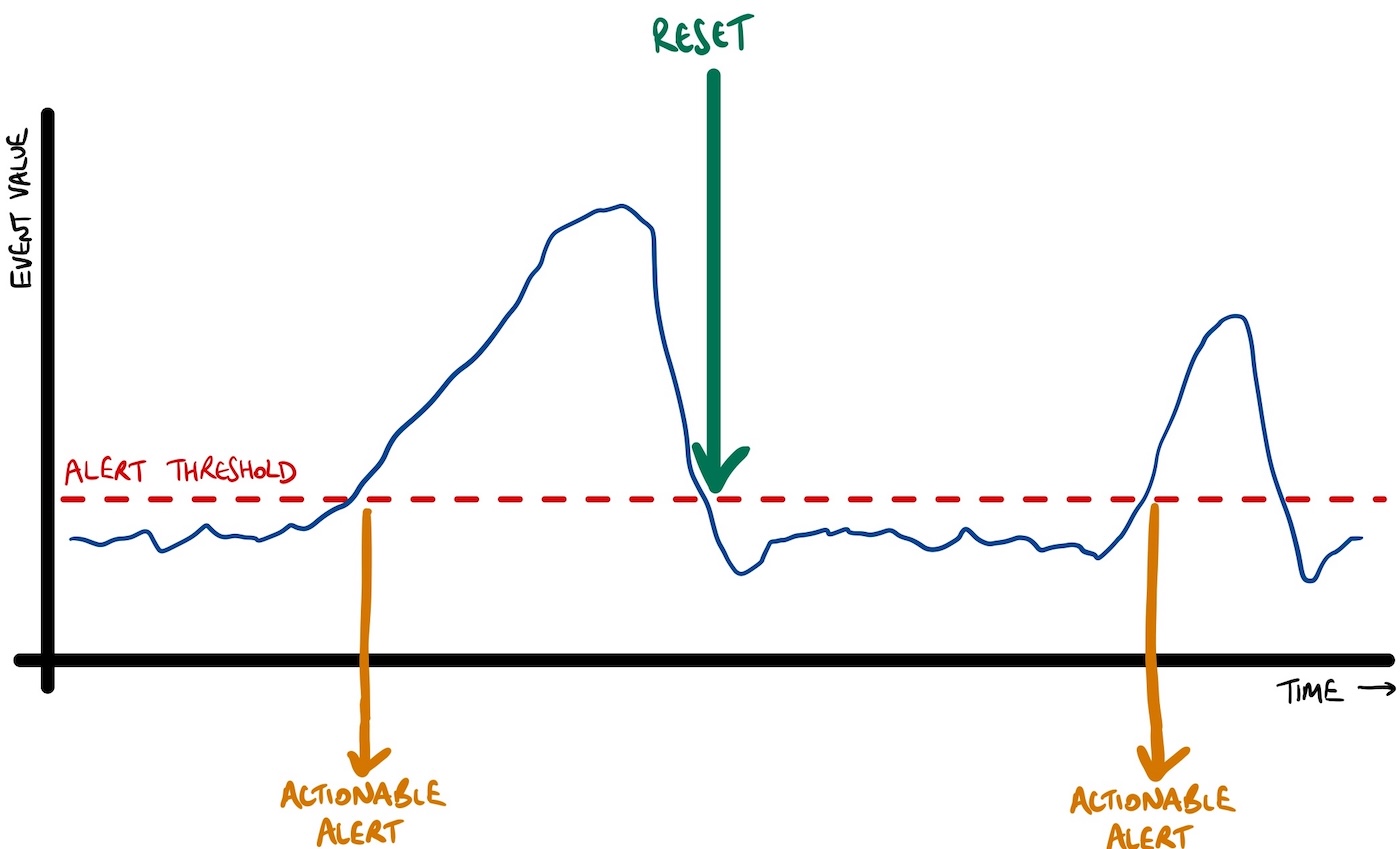
After the first actionable alert, you can assume that if the value returns under the threshold again, this means the issue has now been resolved.
For example, I would infer that the issue in the screenshot below was resolved at 15:30:21 :
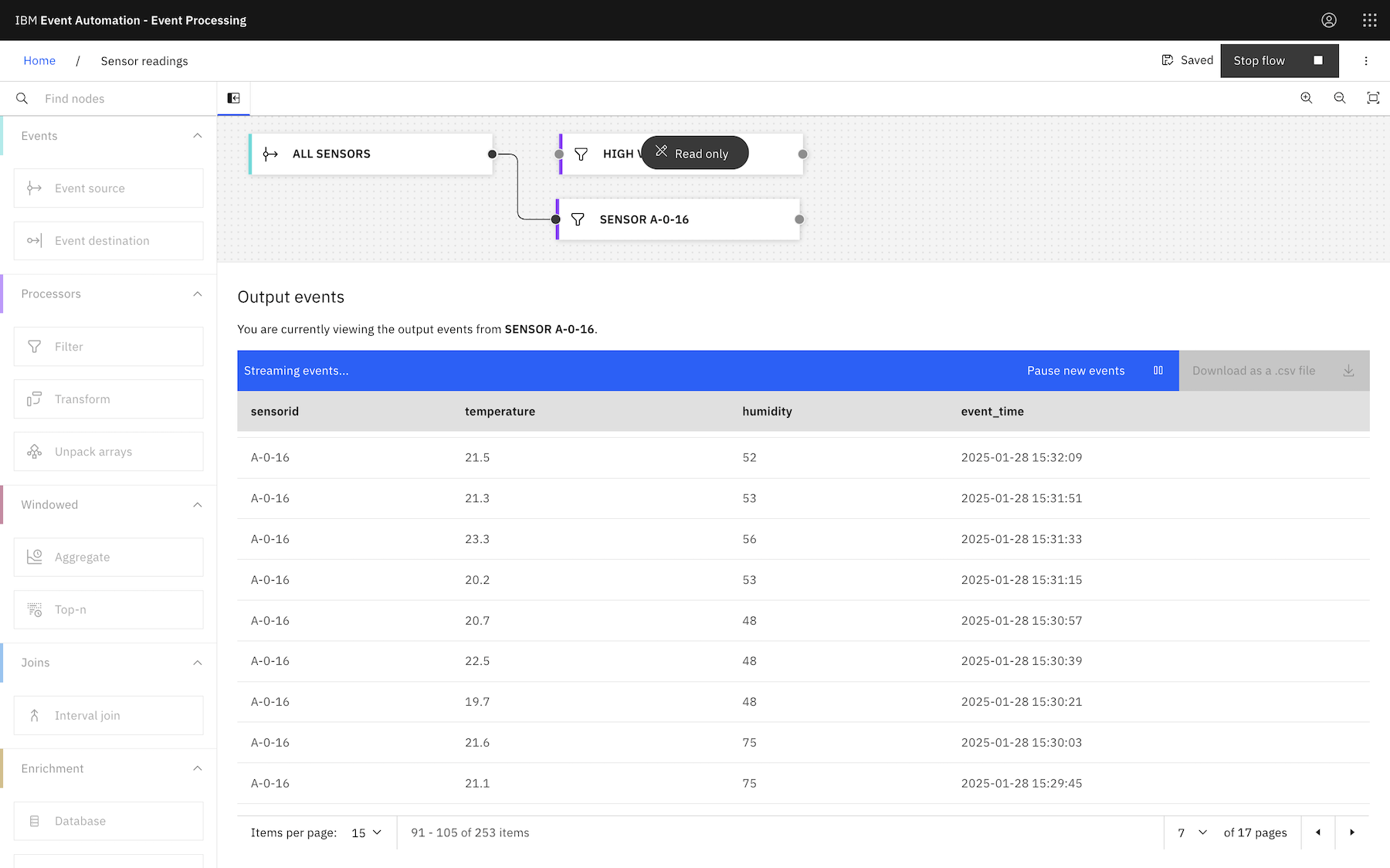
If it increases again after 15:30:21, you want another notification.
For example, doing this with the “Loosehanger” sensor events:
CREATE TEMPORARY VIEW MATCHREC AS
SELECT
*
FROM
`ALL SENSORS`
MATCH_RECOGNIZE (
PARTITION BY
sensorid
ORDER BY
event_time
MEASURES
event_time AS event_time,
temperature AS temperature,
humidity AS humidity
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (
BELOW_THRESHOLD ABOVE_THRESHOLD
)
DEFINE
BELOW_THRESHOLD AS temperature <= 23.5 AND humidity <= 58,
ABOVE_THRESHOLD AS temperature > 23.5 OR humidity > 58
);
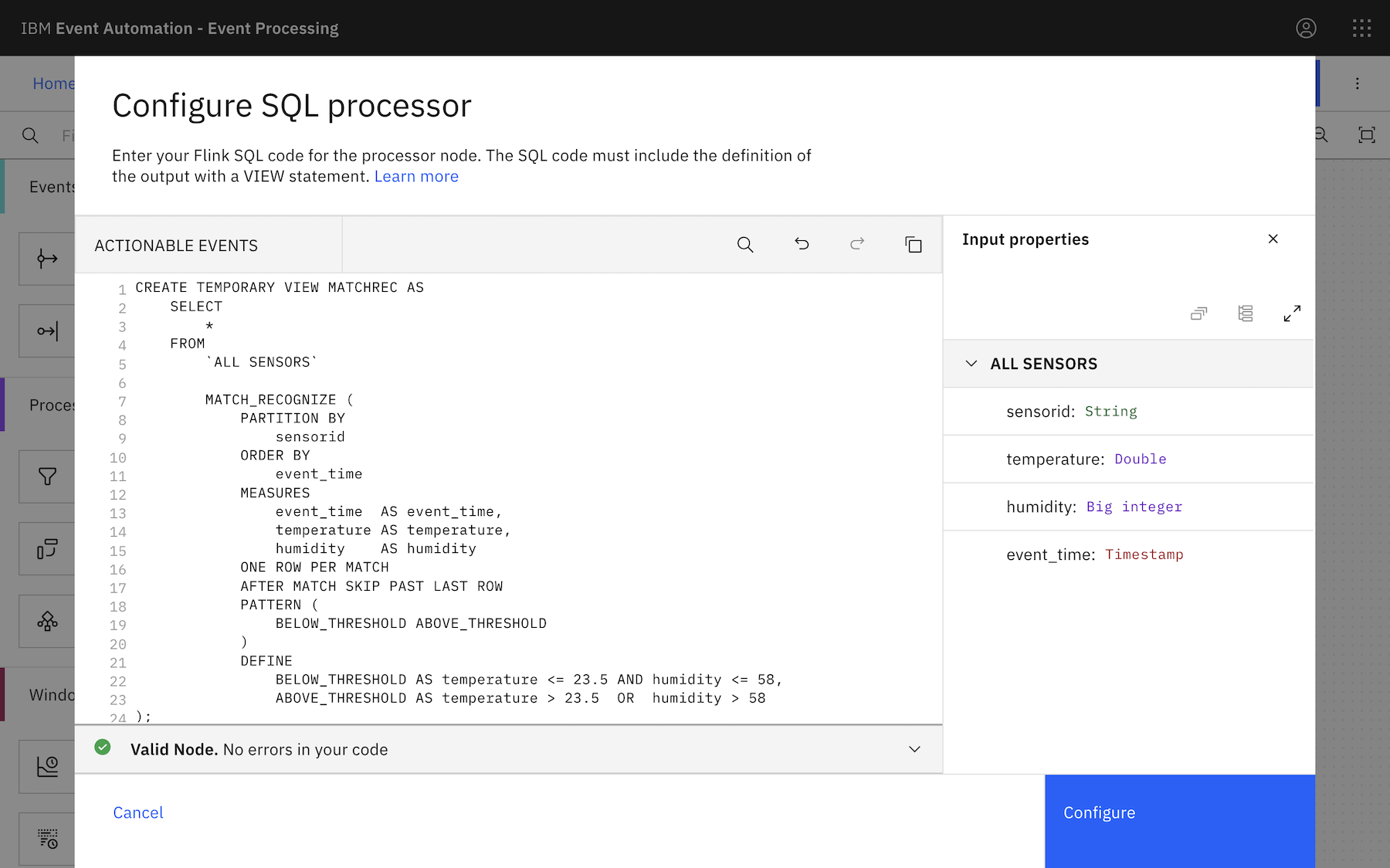
This is a pattern that you want Flink to recognize: the value (for a given sensor id) has exceeded a threshold (where the last event for the same sensor id was previously below the threshold).
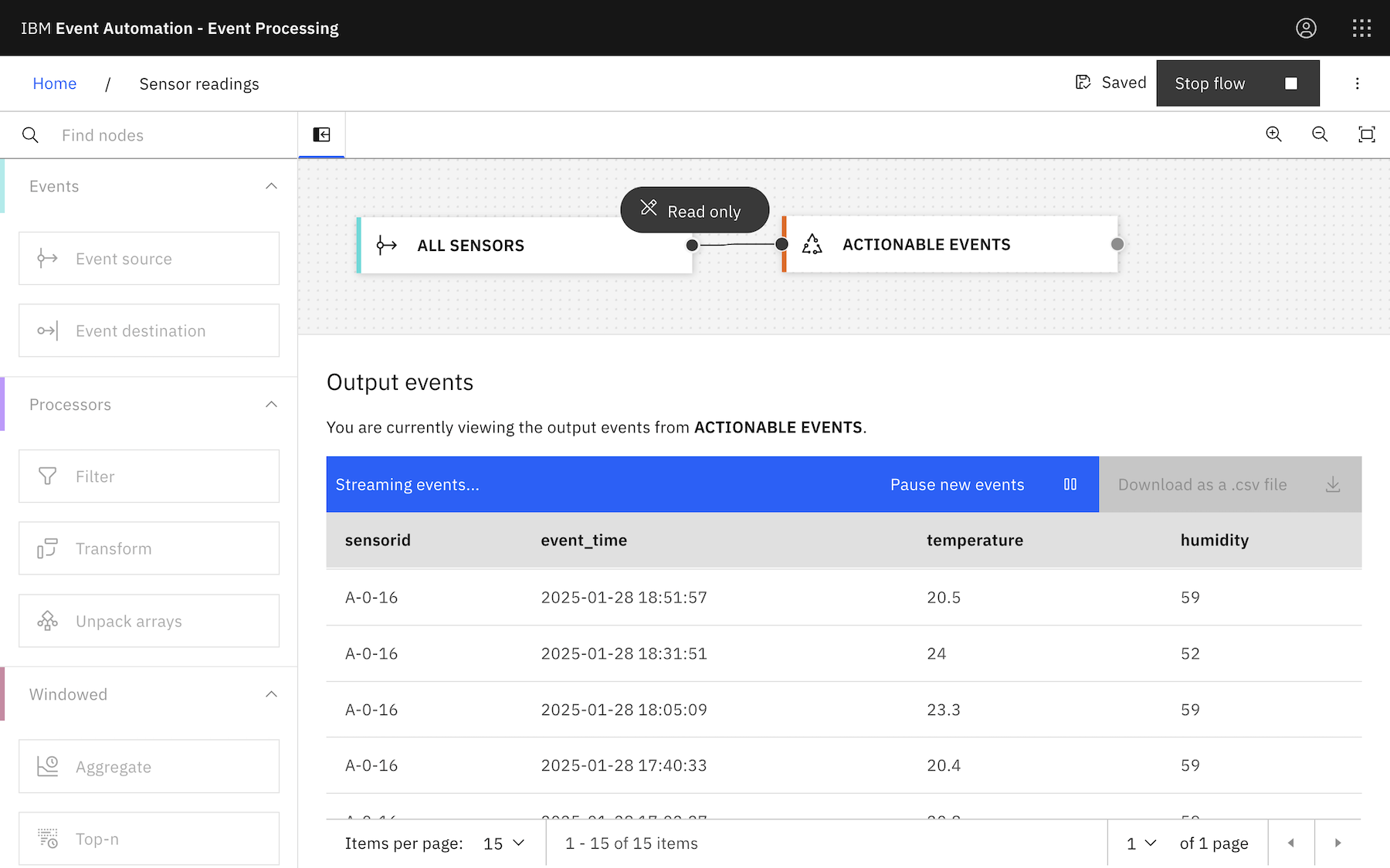
Choosing an approach
The best approach for your use case will depend on the nature of the events you are processing, and the way that you are responding to them.
For example, is it reasonable to assume that if the value drops below the threshold, this means that the issue has been resolved? If the values in your stream of events are very spiky during a period that needs attention then the threshold approach may be less effective.
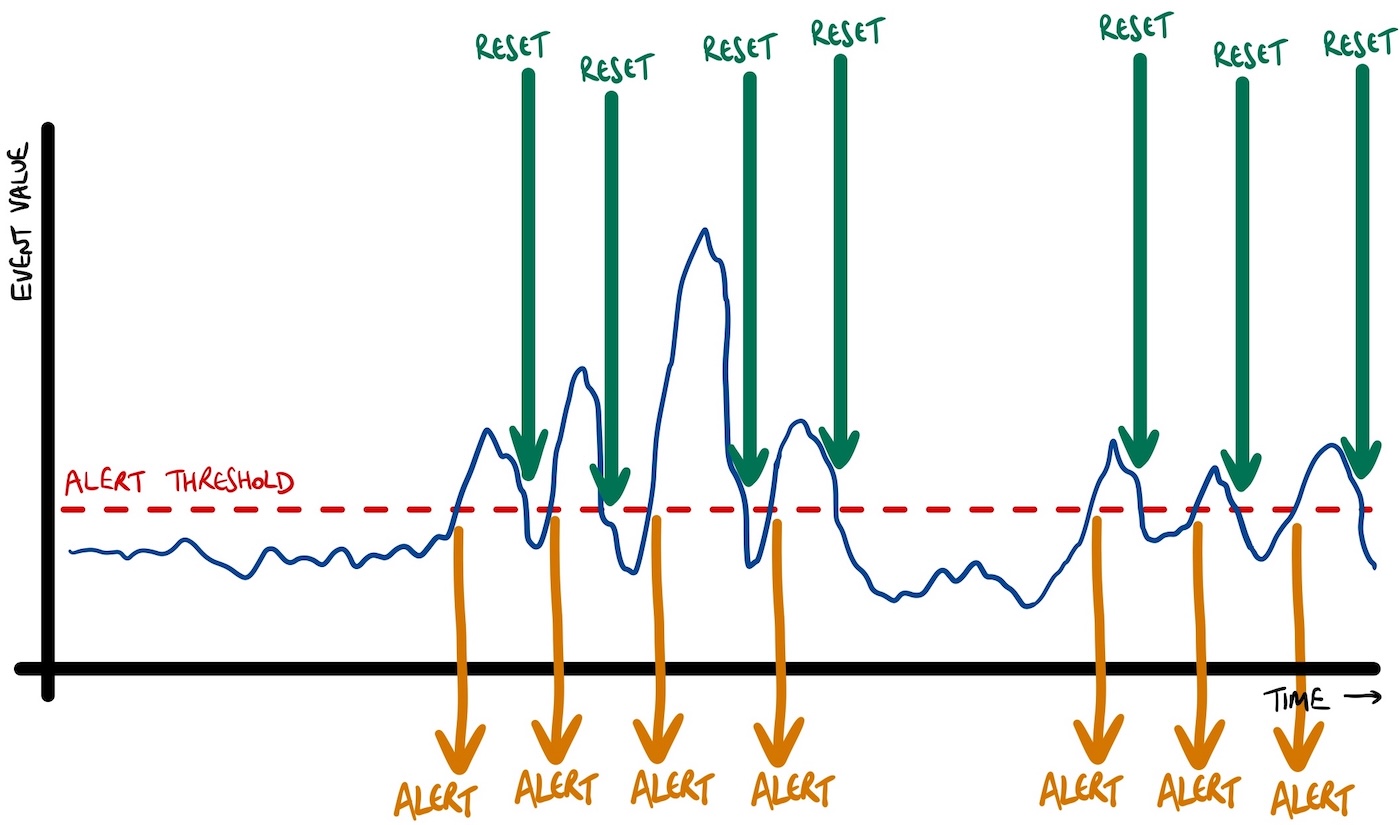
Alternatively, if the time to resolution for the actionable alert can be long, or even just difficult to predict, then the time interval approach may be less effective.
You will want to customize your event processing job to fit your specific requirements.
The key is that the better job you can do to describe the output you want, the more useful and actionable the output from your Flink jobs.
Tags: apachekafka, flink, kafka