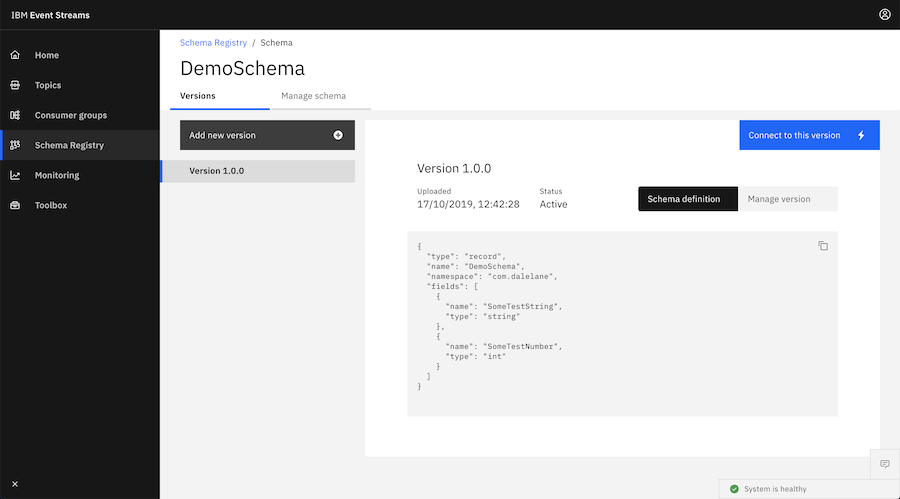
kafka-console-consumer.sh is one of the most useful tools in the Kafka user’s toolkit. But if your topic has Avro-encoded events, the output can be a bit hard to read.
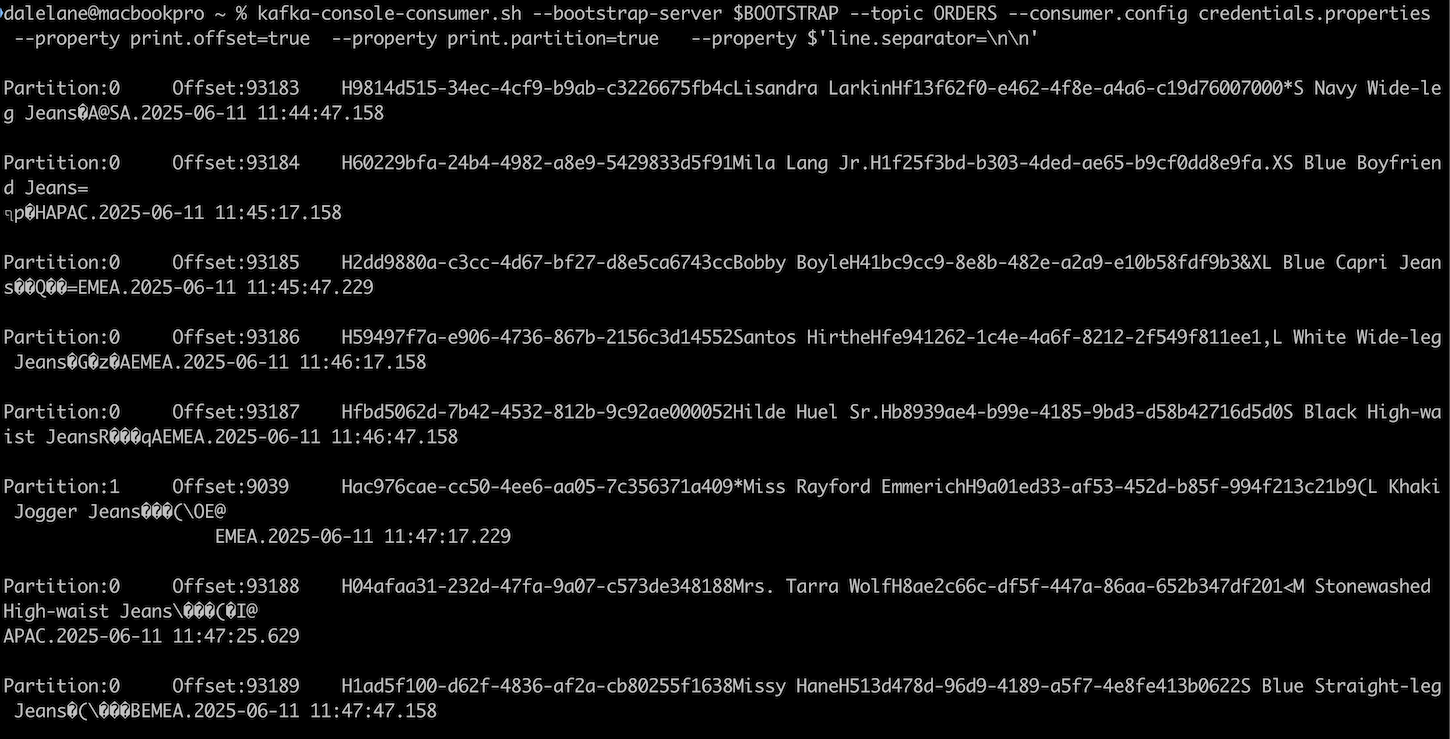
You don’t have to put up with that, as the tool has a formatter plugin framework. With the right plugin, you can get nicely formatted output from your Avro-encoded events.
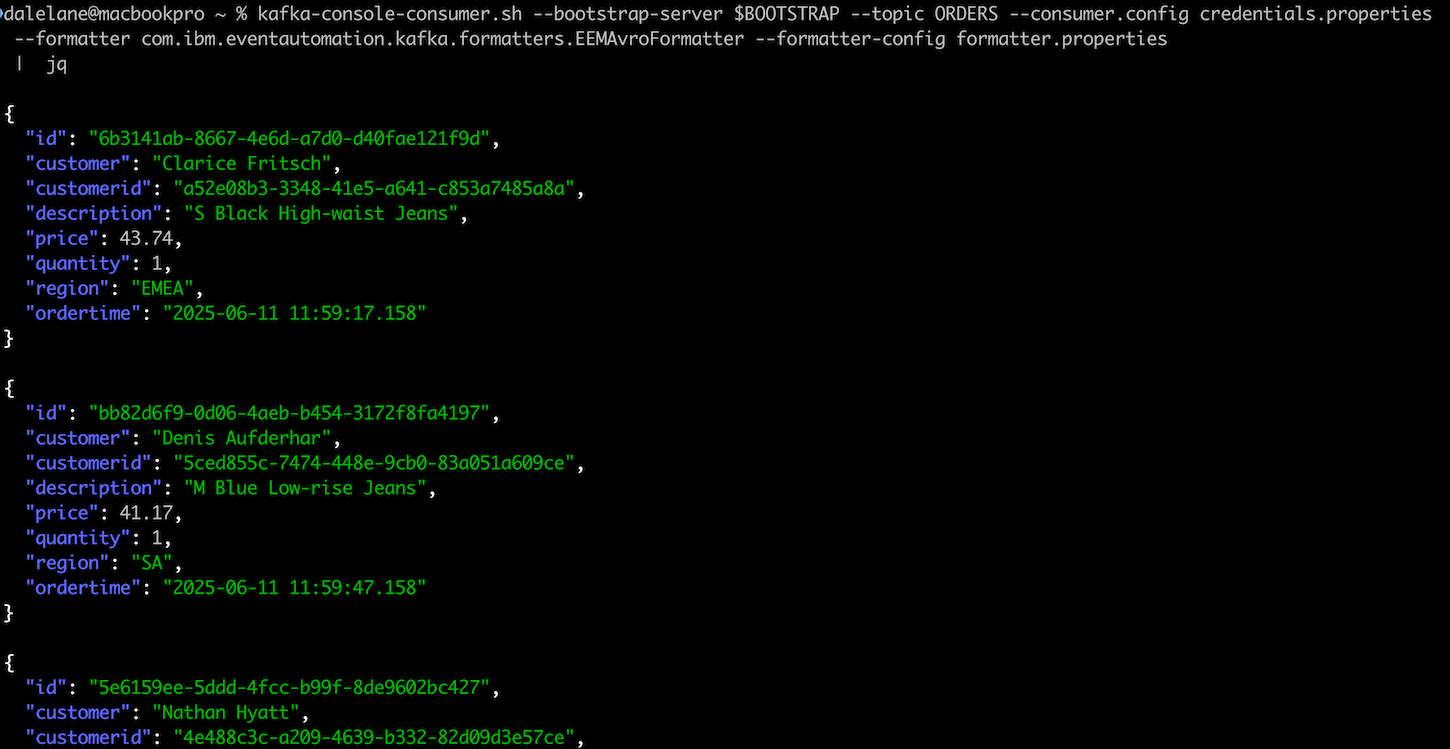
With this in mind, I’ve written a new Avro formatter for a few common Avro situations. You can find it at:
github.com/IBM/kafka-avro-formatters
The README includes instructions on how to add it to your Kafka console command, and configure it with how to find your schema.