In this post, I want to talk about what happens when you use Avro to deserialize messages on a Kafka topic, why it actually needs two schemas, and what those schemas need to be.
I should start by pointing out that if you’re using a schema registry, you probably don’t need to worry about any of this. In fact, a TLDR for this whole post could be “You should be using a good schema registry and SerDes client“.
But, there are times where this may be difficult to do, so knowing how to set a deserializer up correctly is helpful. (Even if you’re doing the right thing and using a Schema Registry, it is still interesting to poke at some of the details and know what is happening.)
The key thing to understand is that to deserialize binary-encoded Avro data, you need a copy of the schema that was used to serialize the data in the first place [1].
This gets interesting after your topic has been around for a while, and you have messages using a mixture of schema versions on the topic. Maybe over the lifetime of your app, you’ve needed to add new fields to your messages a couple of times.
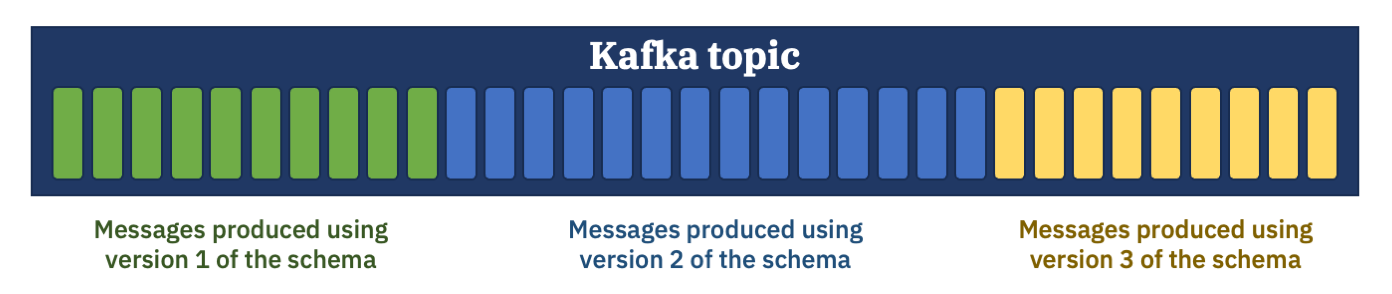
If you want a consumer application to be able to consume all of the messages on this topic, what does that mean?
To deserialize binary-encoded Avro data, you actually need two schemas:
- a schema that was used to serialize the event in the first place – what the API calls the “writer” schema
- a schema that describes how you want to consume and use the data – what the API calls the “reader” schema
To understand that, let’s simplify things down to the basics.
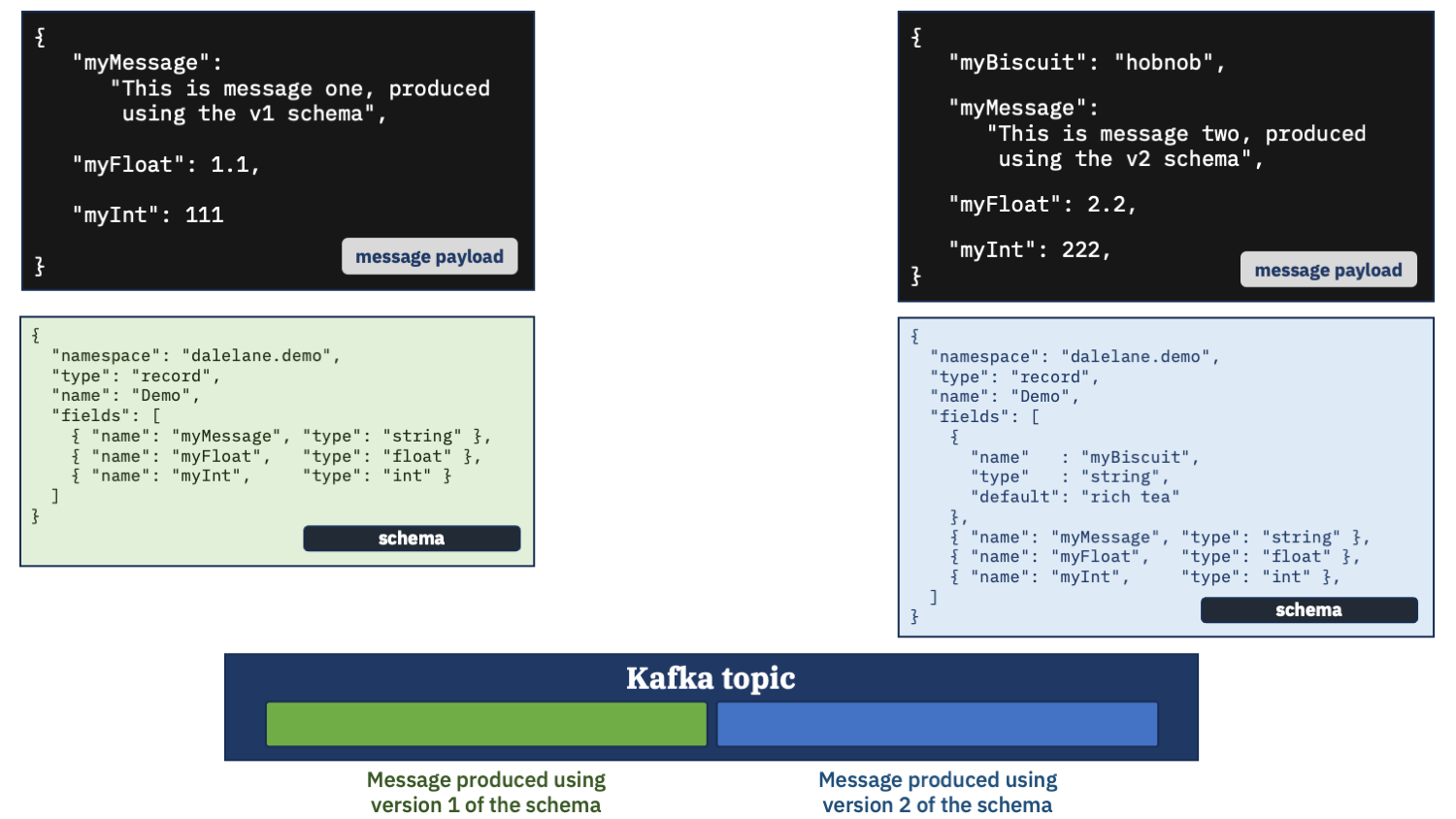
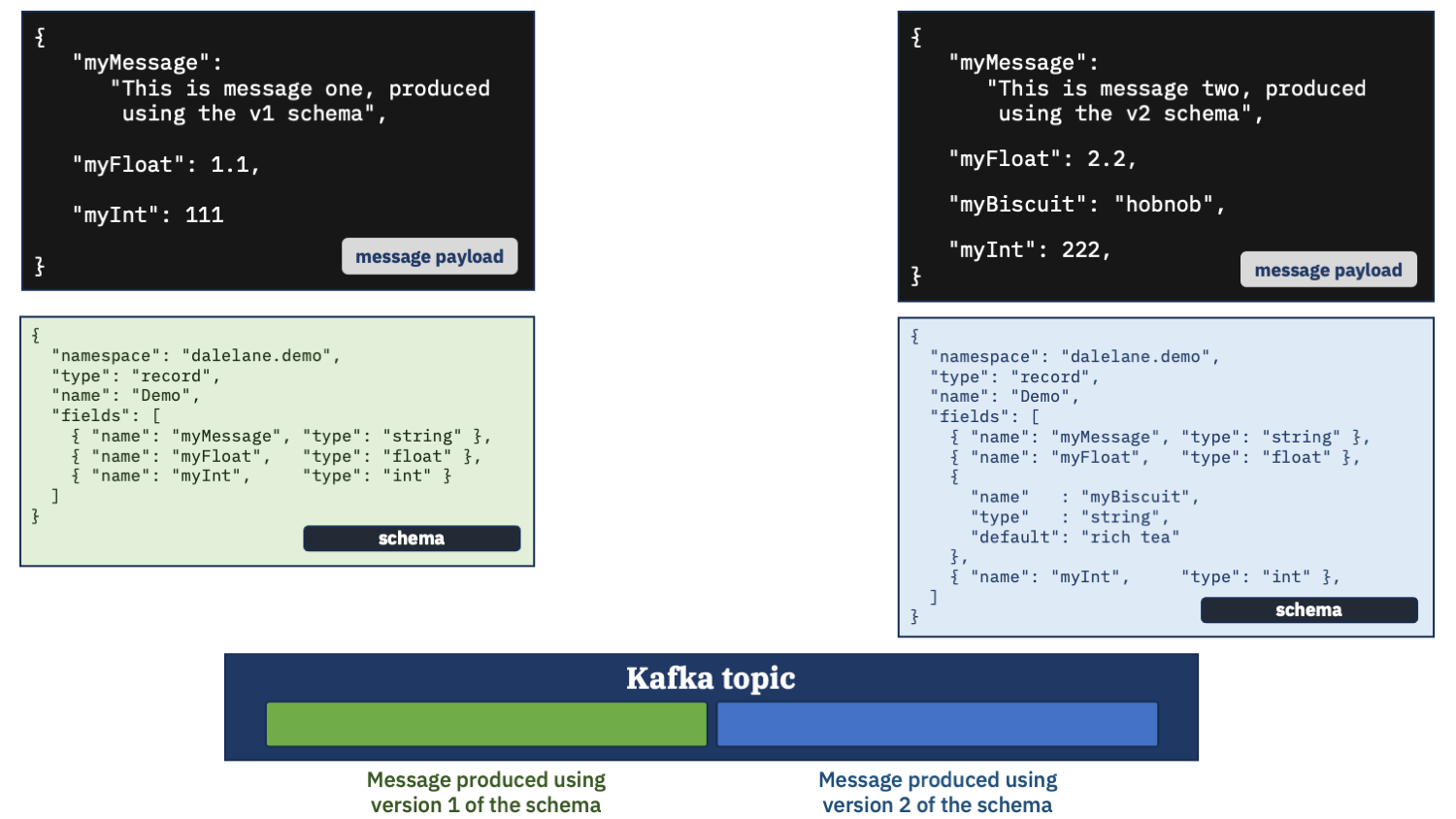
A Kafka topic with two messages.
The first message produced with a schema.
A second message produced with a modified schema.
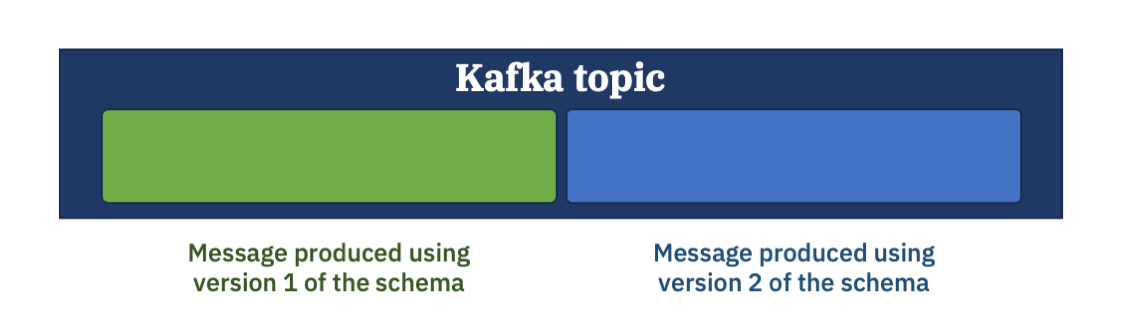
Imagine you are setting up a Kafka consumer that needs to consume both of these messages.
What will that consumer need?
EXAMPLE 1:
APPENDING A NEW FIELD TO THE SCHEMA
Let’s try it and see what happens. We’ll start with something simple – the new schema adds a new field to the end of the message.
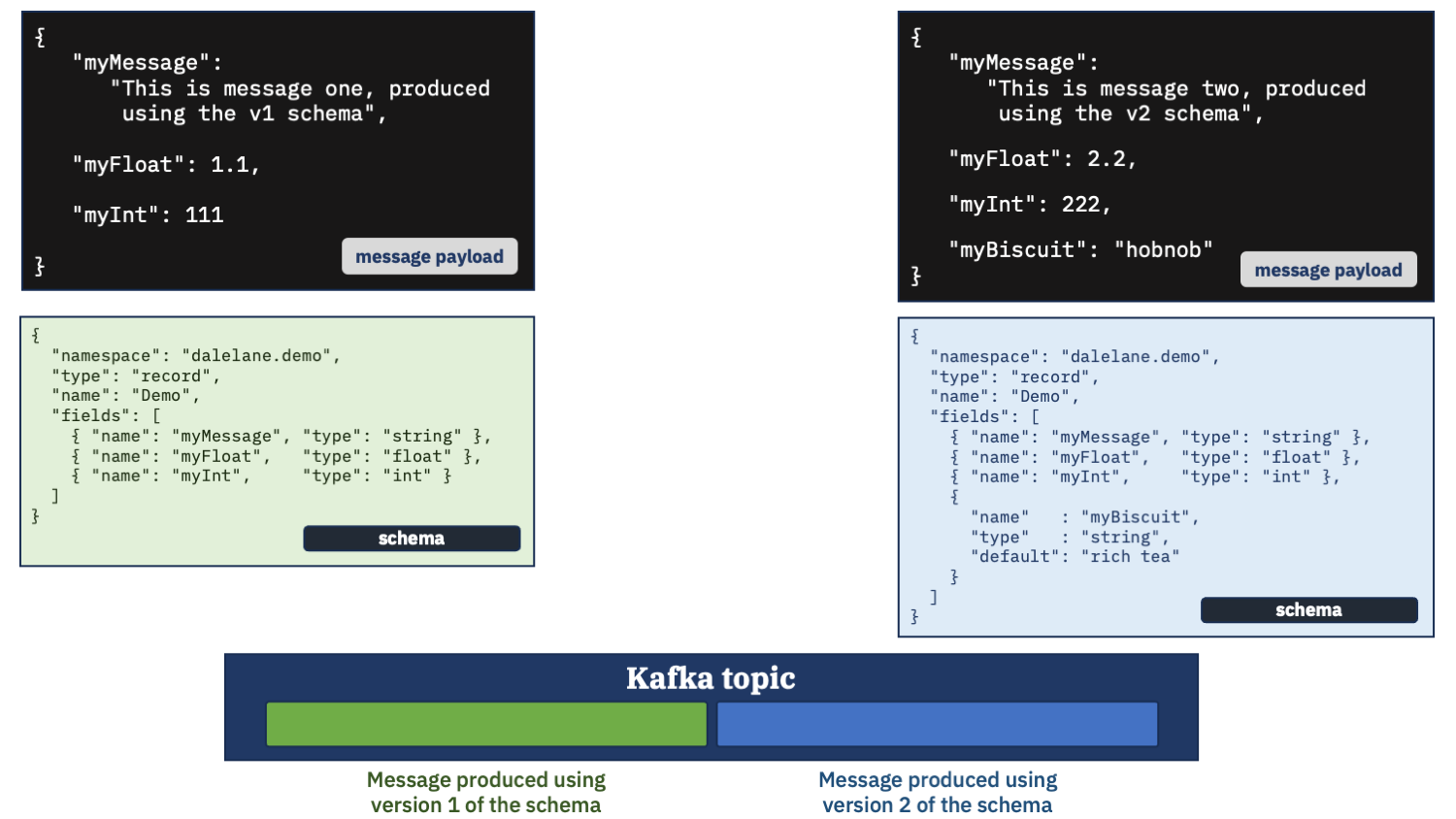
The second schema adds a new field called myBiscuit.
And the second message is setting that field to “hobnob” – the king of biscuits.
How would you configure your Kafka consumer to be able to read both of these messages?
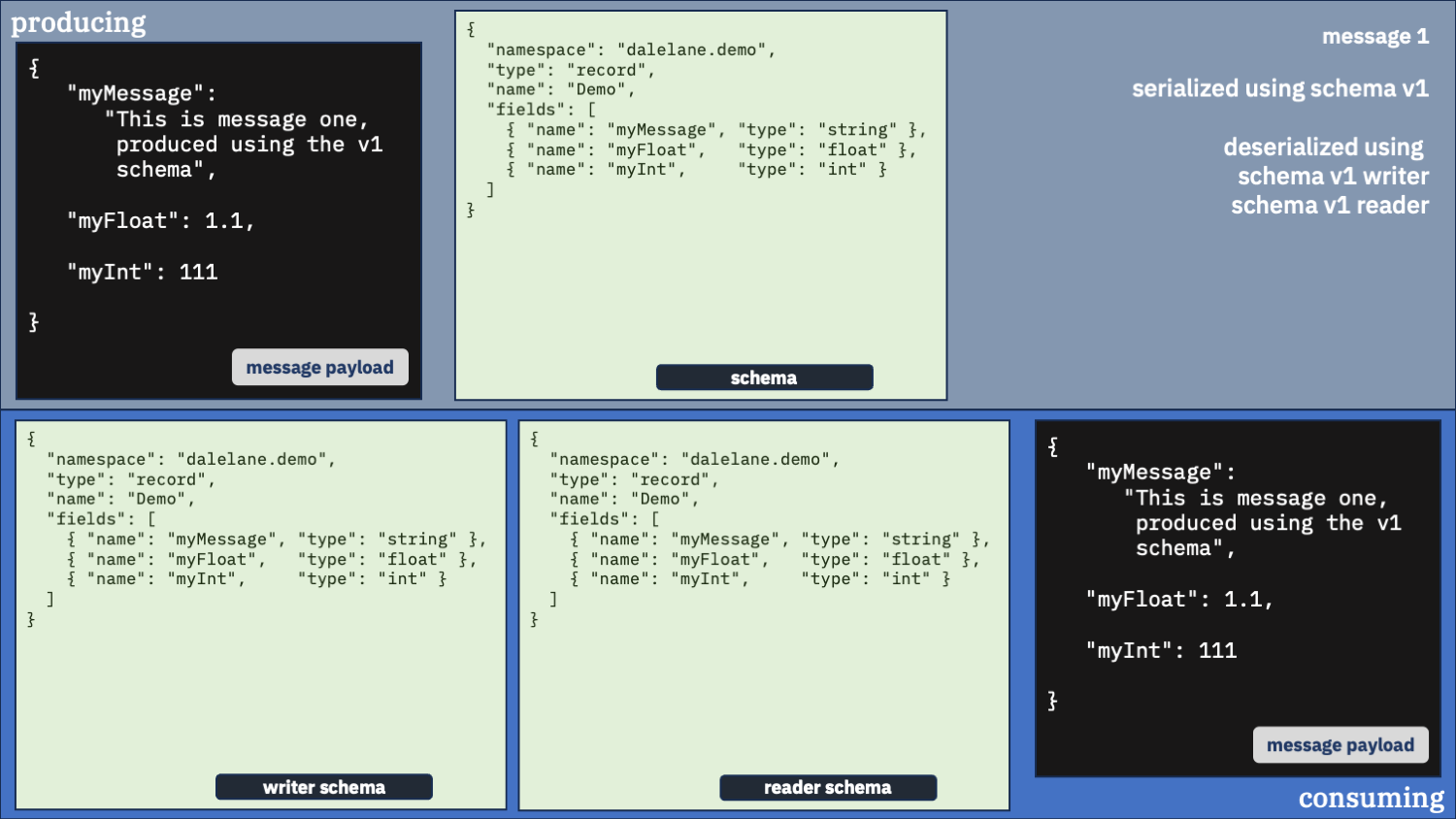
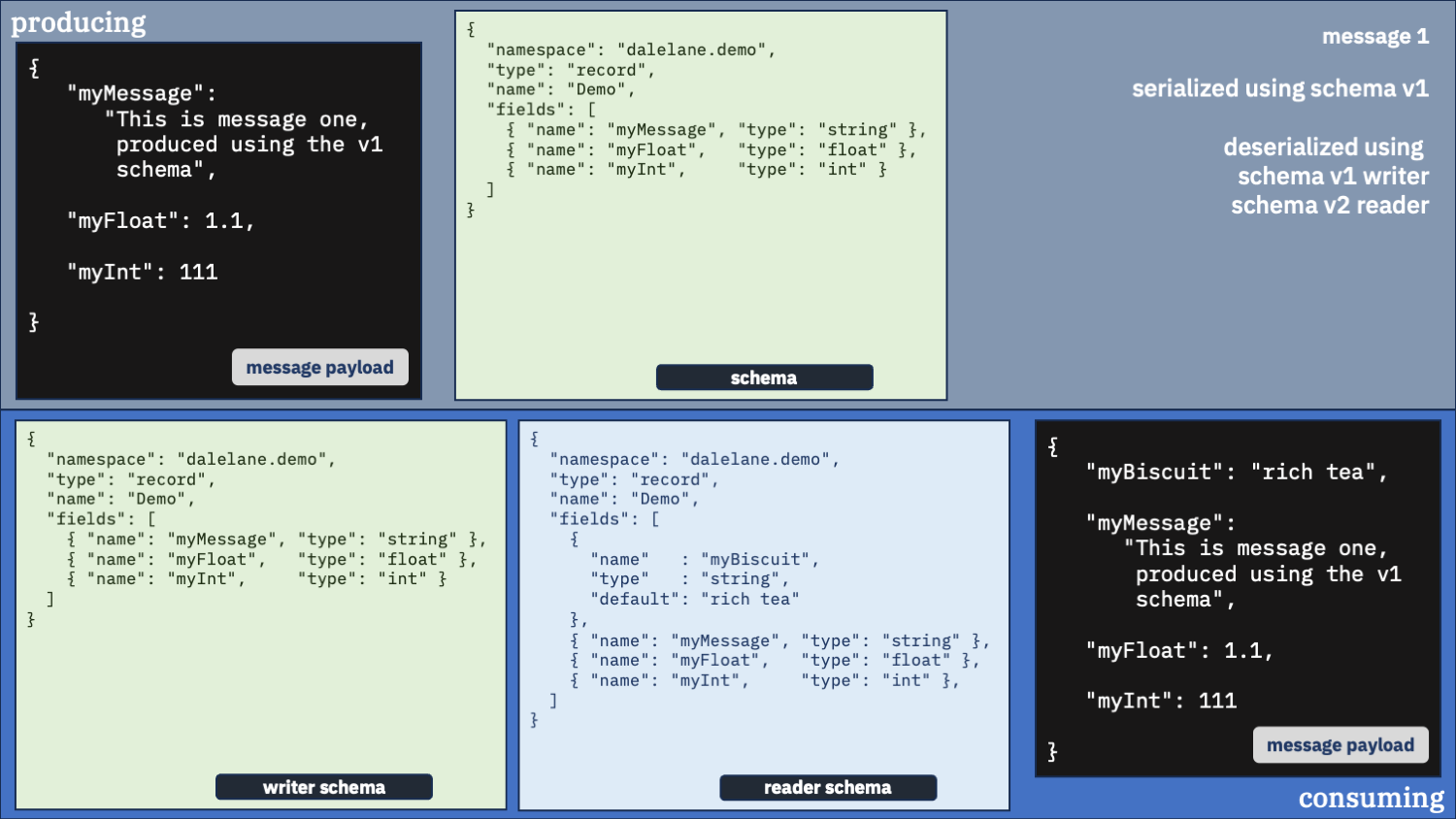
Unusual option 1:
Configure your consumer to use schema v1
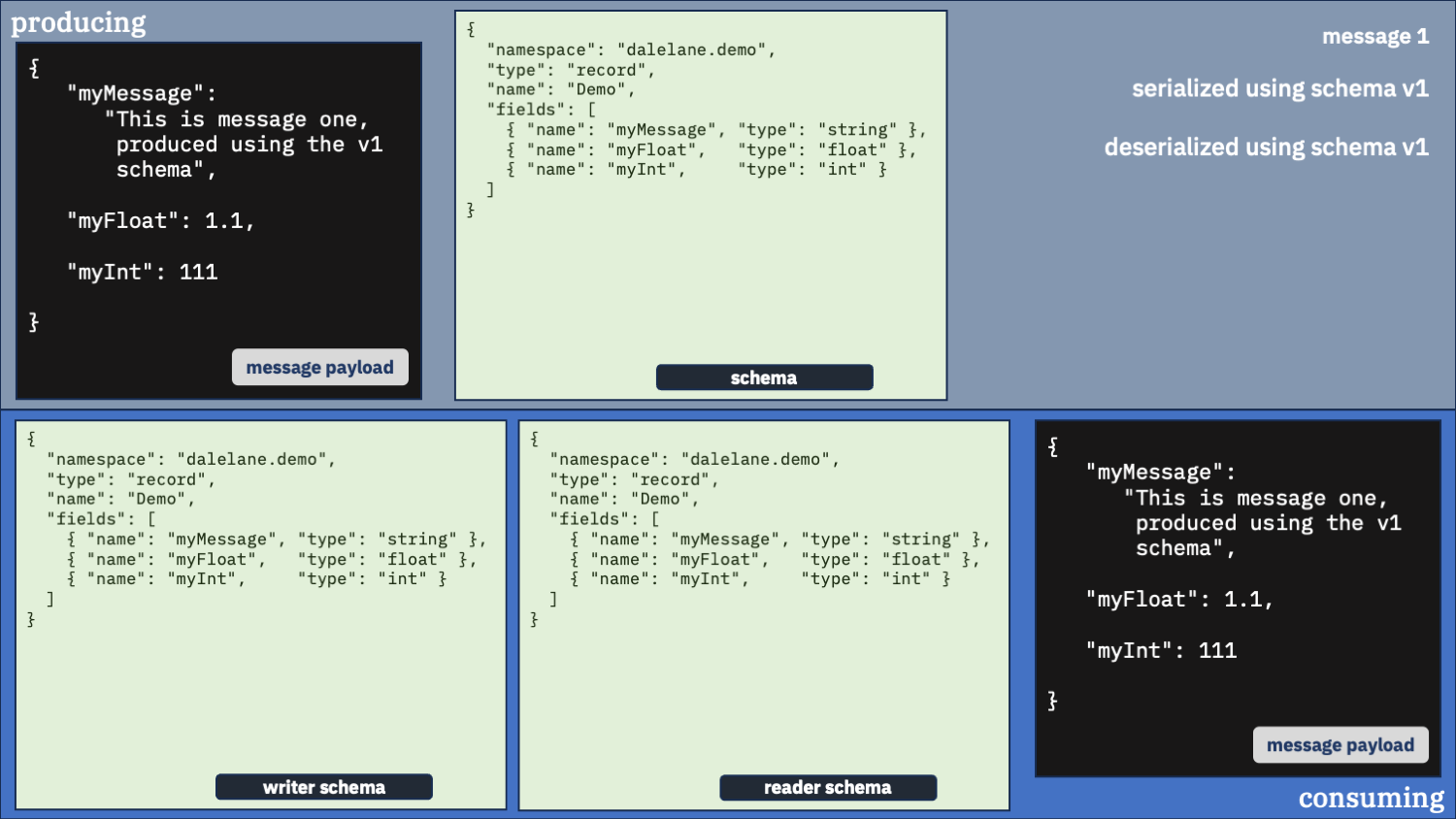
Let’s start by using the same schema for both messages – the older v1 schema.
first message
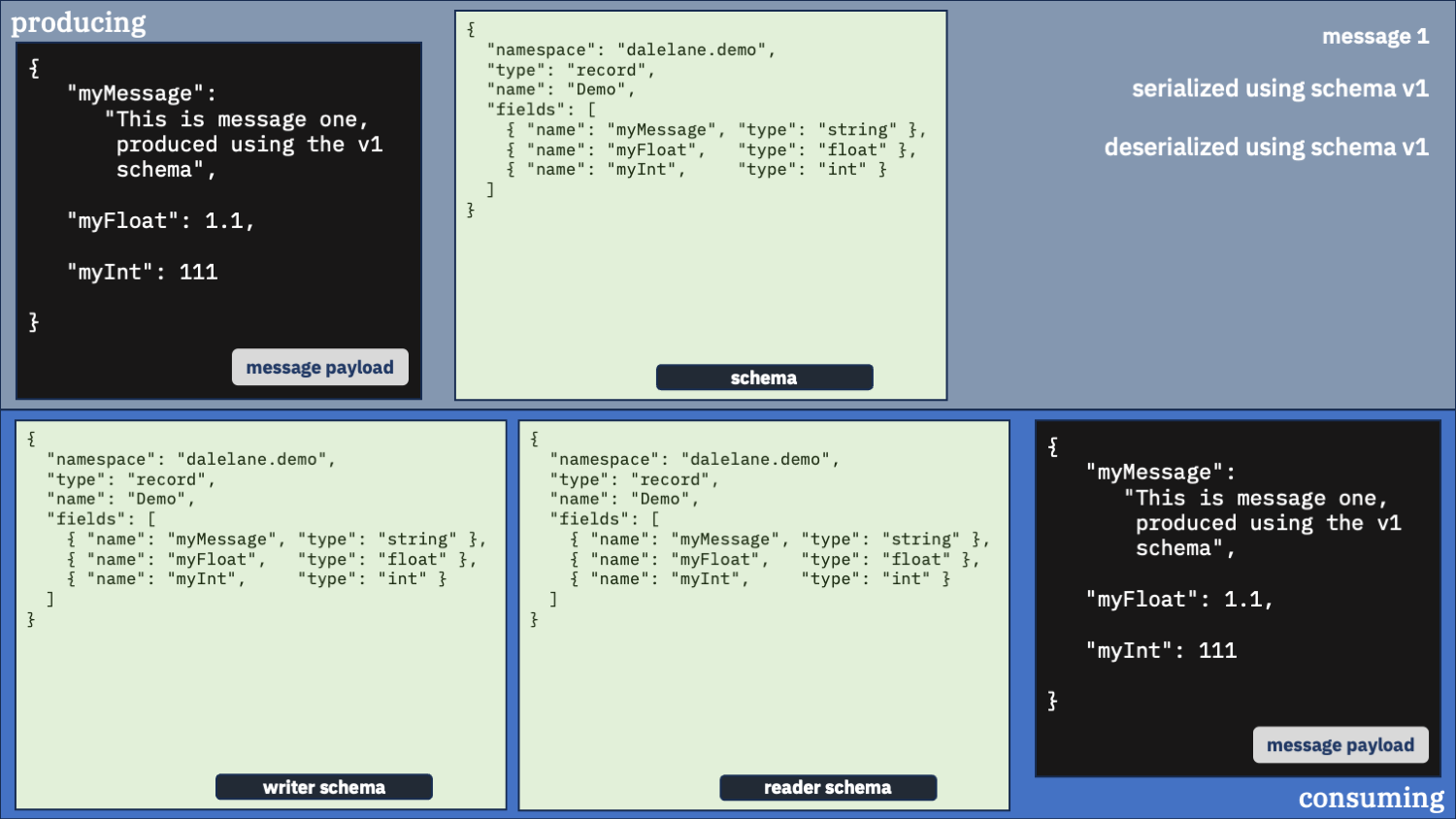
second message
What happened?
The first message was deserialized fine – as you’d expect. The same version was used for both producing and consuming.
The second message was mostly deserialized okay, but it doesn’t have the new field that was produced.
Is unusual option 1 okay?
It might look safe, but hold that thought – we’ll look at some other types of schema evolution in a bit that should change your mind.
Maybe your app will need that new field in the second message. Let’s try another approach.
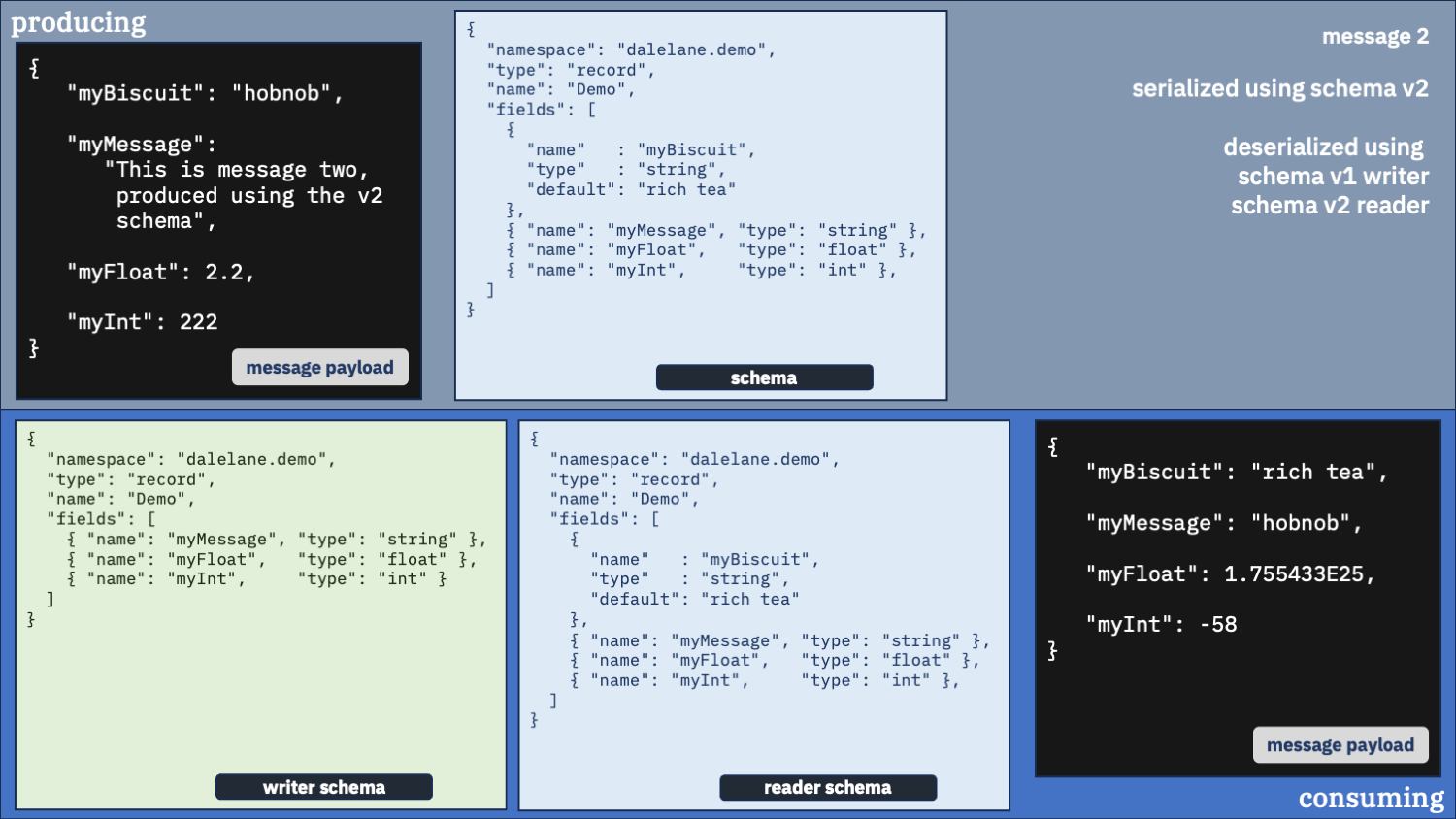
Unusual option 2:
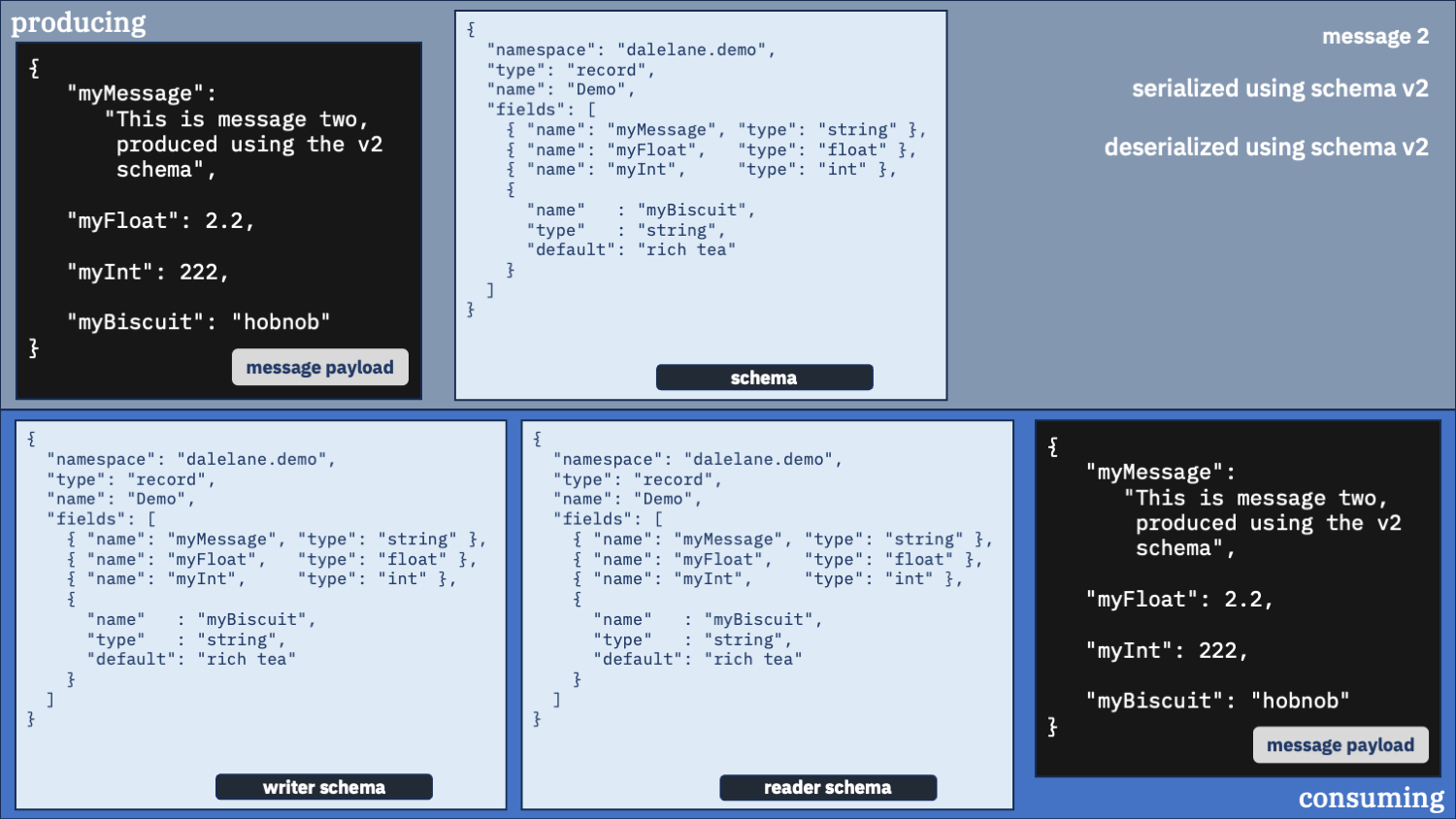
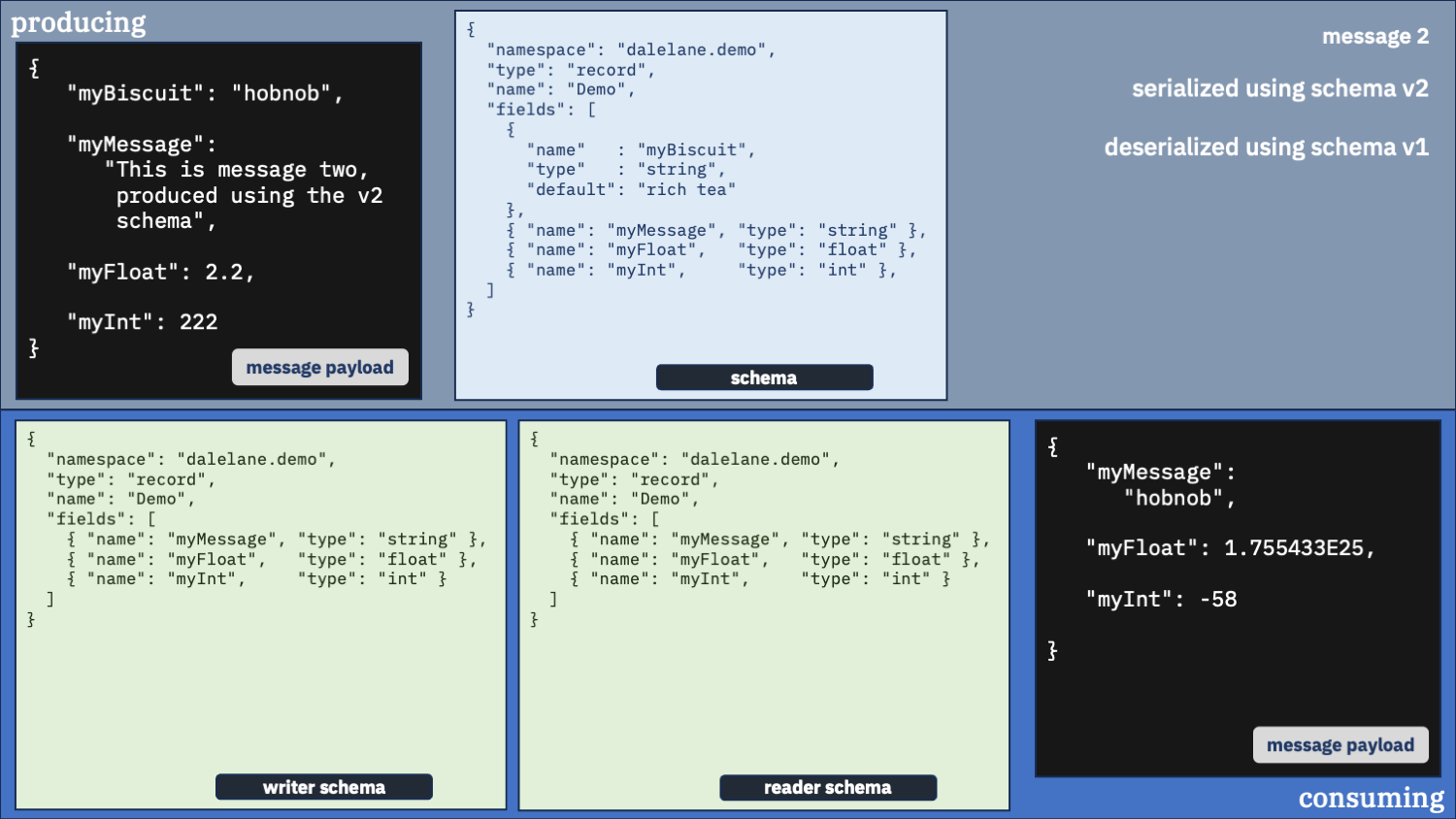
Configure your consumer to use schema v2
This time, we’ll still use the same schema to deserialize both messages, but we’ll use the newer v2 schema.
first message
second message
What happened?
Using the v2 schema was fine for the second message, but it went bang when it tried to deserialize the first message.
This wasn’t a good option.
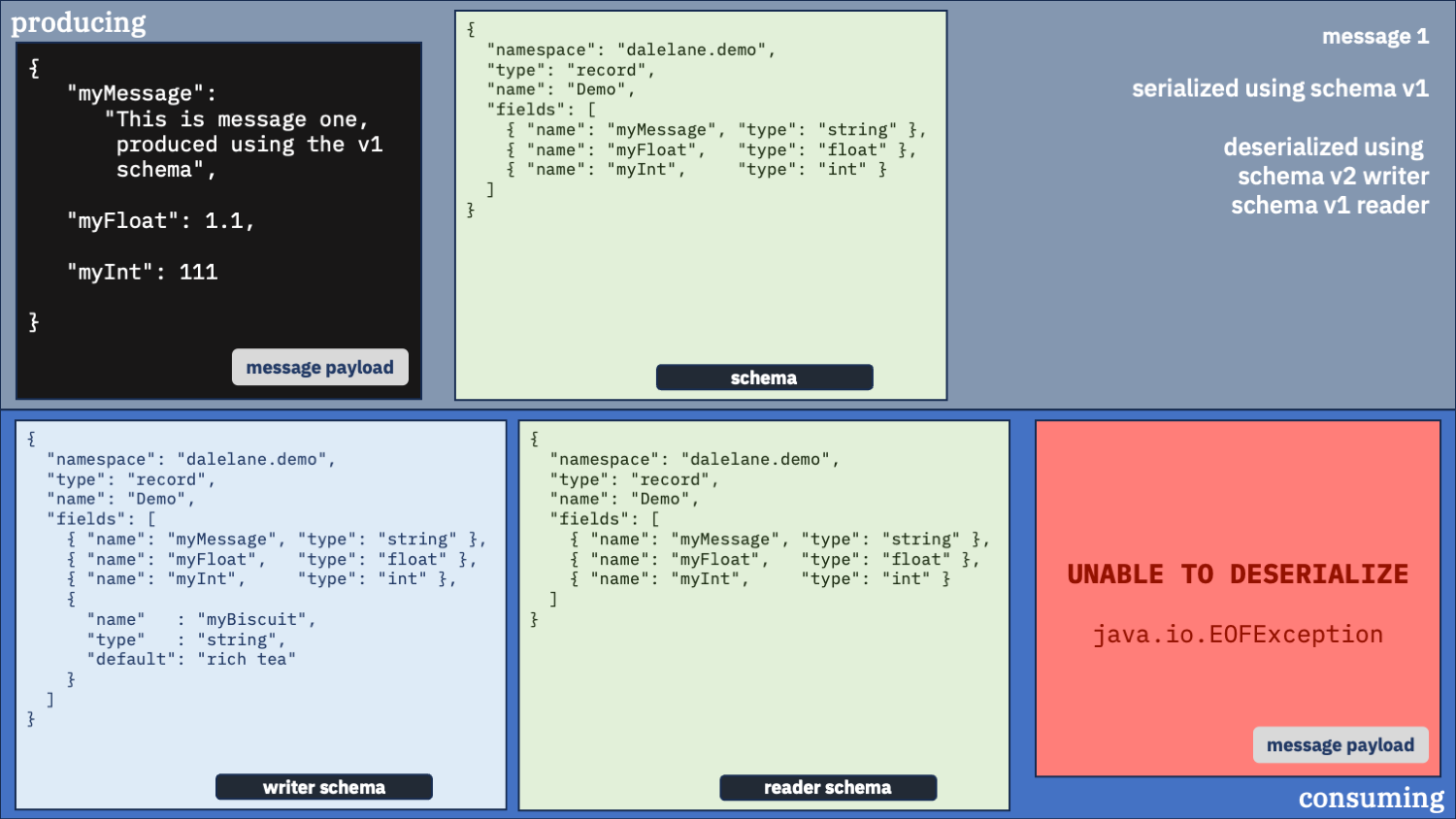
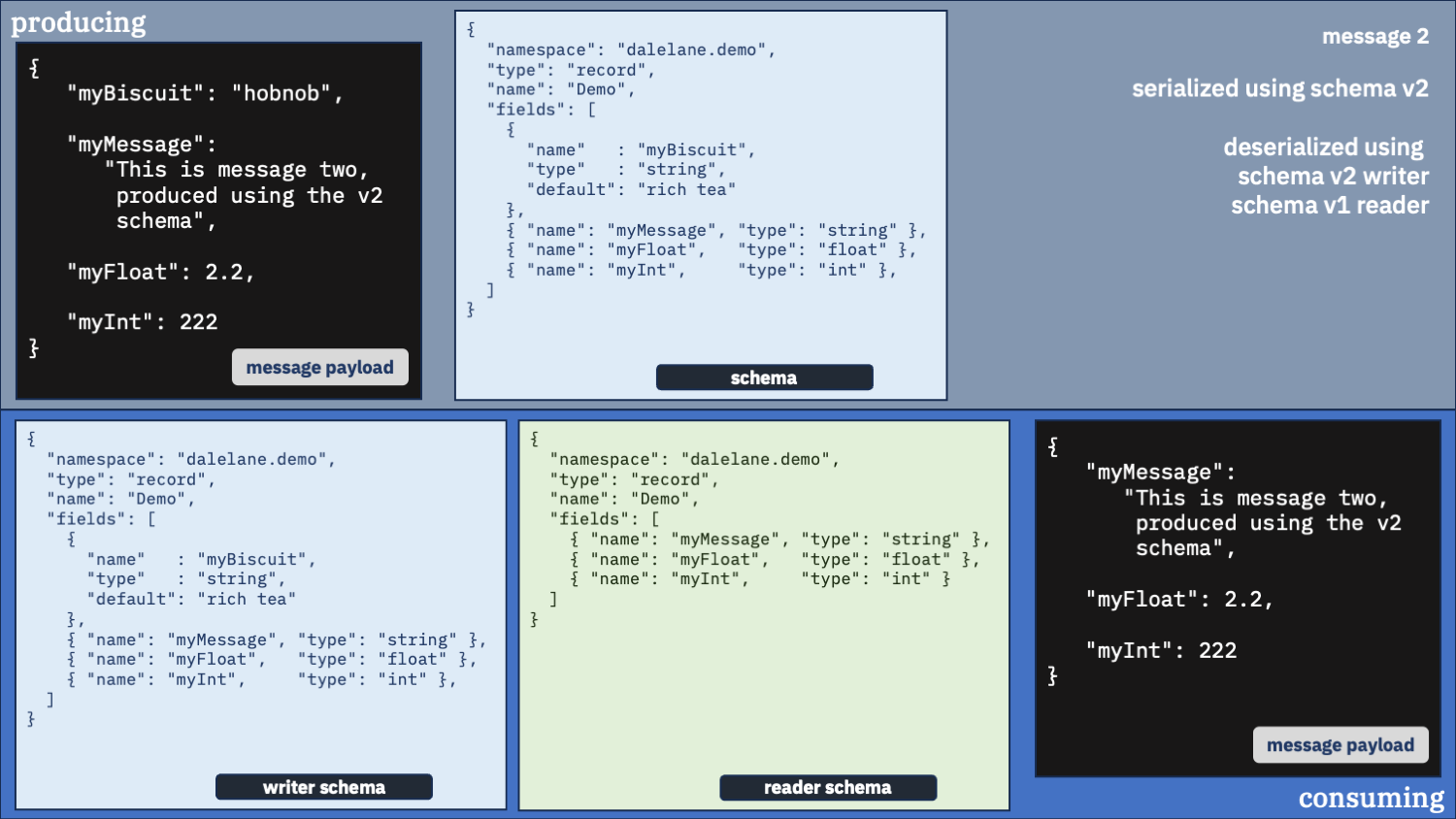
Unusual option 3:
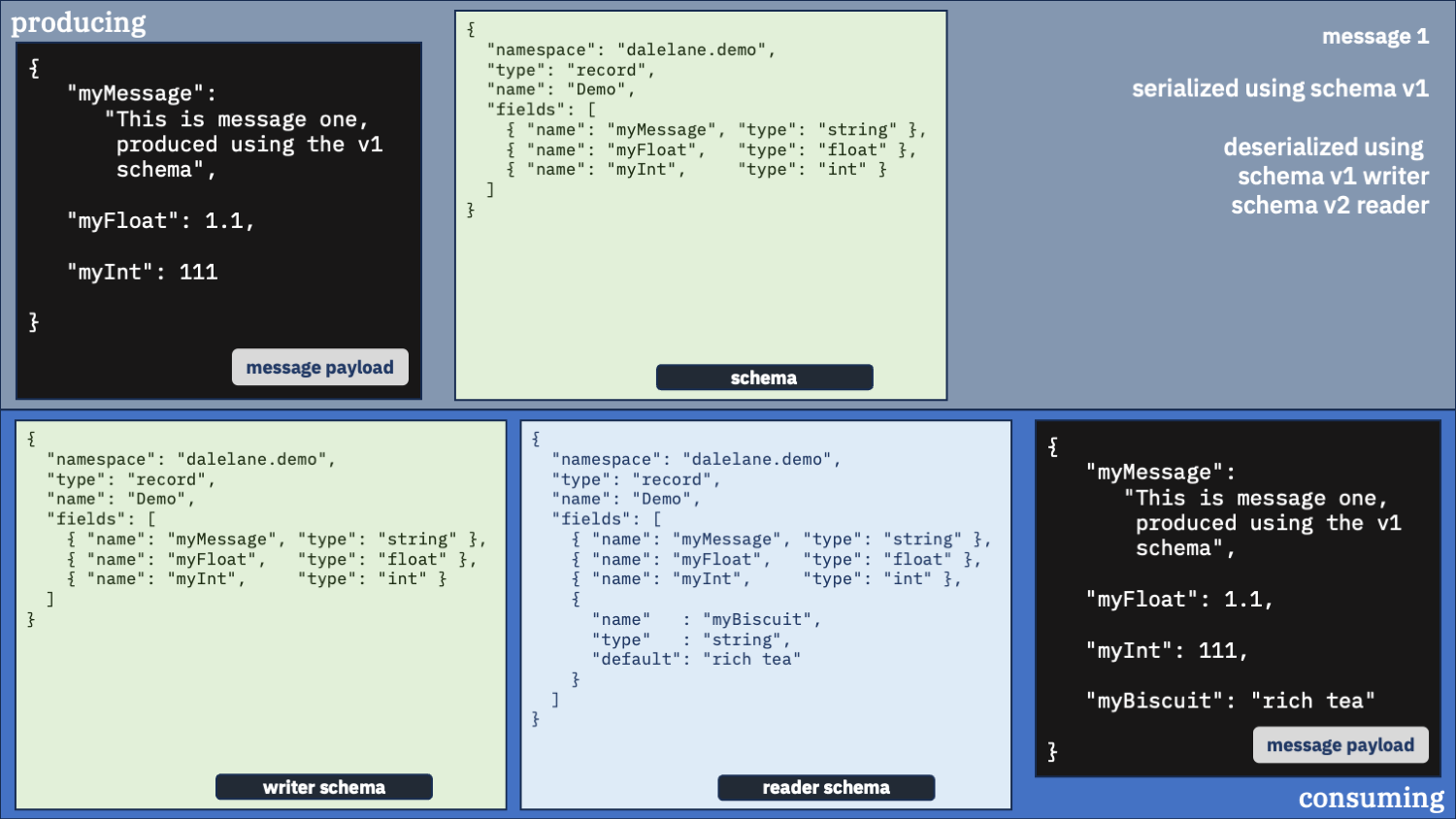
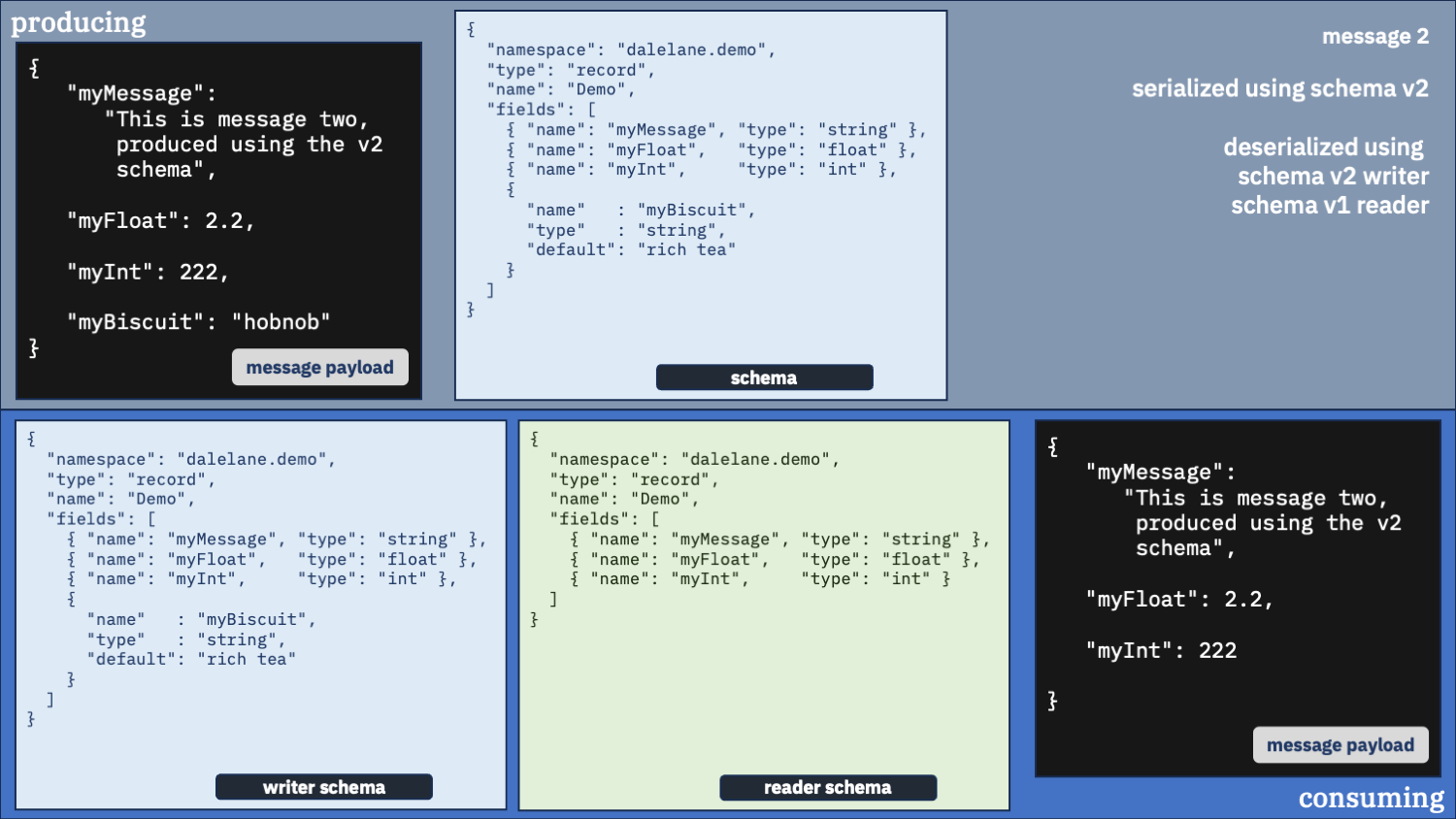
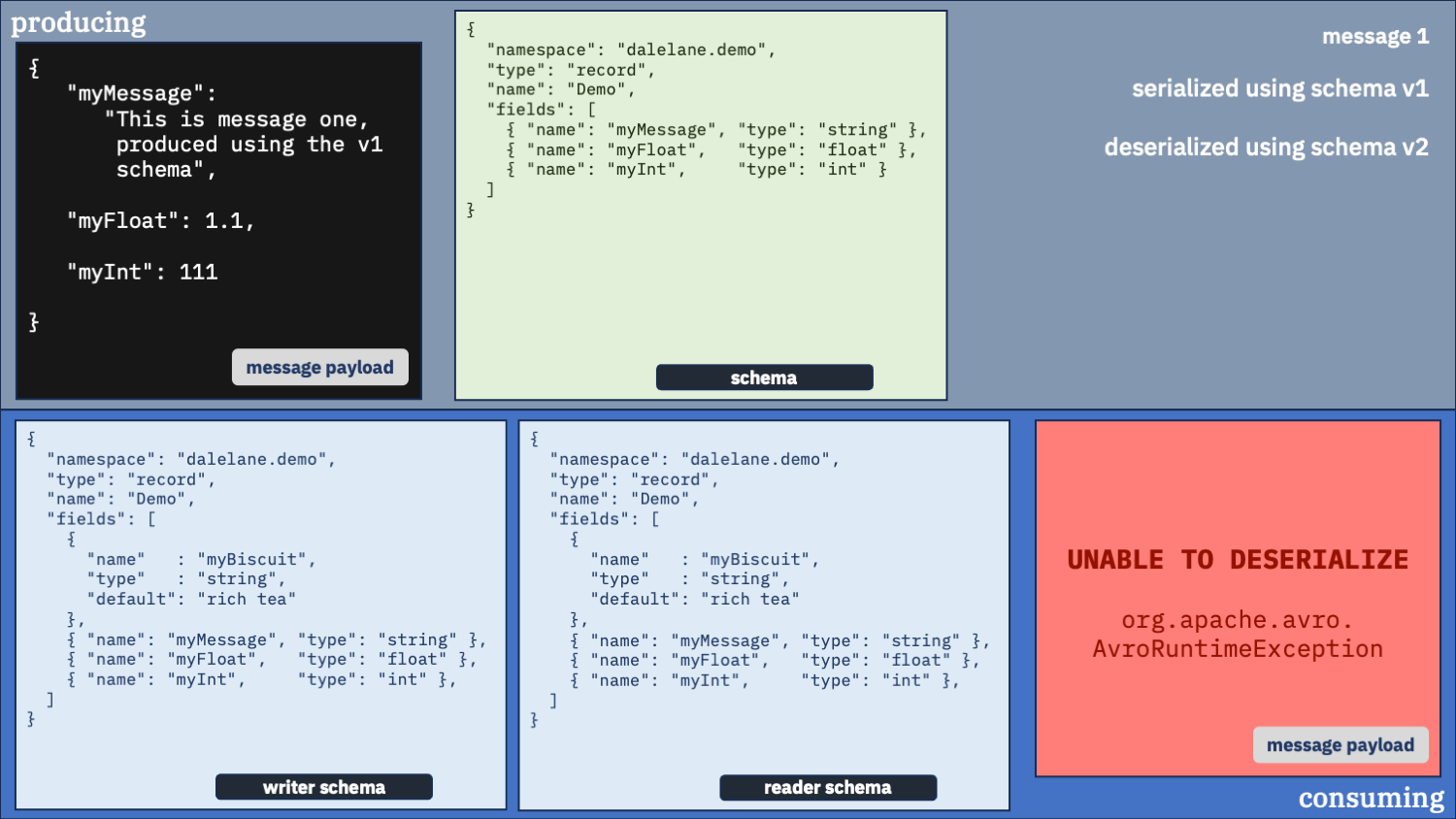
Use the v1 schema as the writer and the v2 schema as the reader
Maybe we shouldn’t be using the same schema for both writer and reader. Let’s try mixing it up.
first message
second message
It worked well for the first message. That’s an improvement.
But look at what we got for the myBiscuit field in the second message we deserialized.
It has the default “rich tea” value. That isn’t what was produced, so what do you think happened?
By telling the deserializer to use the v1 schema to unpack the message, we didn’t tell it about the myBiscuit field, so that was never pulled out of the message data.
We told it to use the v2 schema to describe what we wanted to consume, it knew we wanted a myBiscuit field in the output – because that wasn’t pulled out of the message data, we ended up with the default.
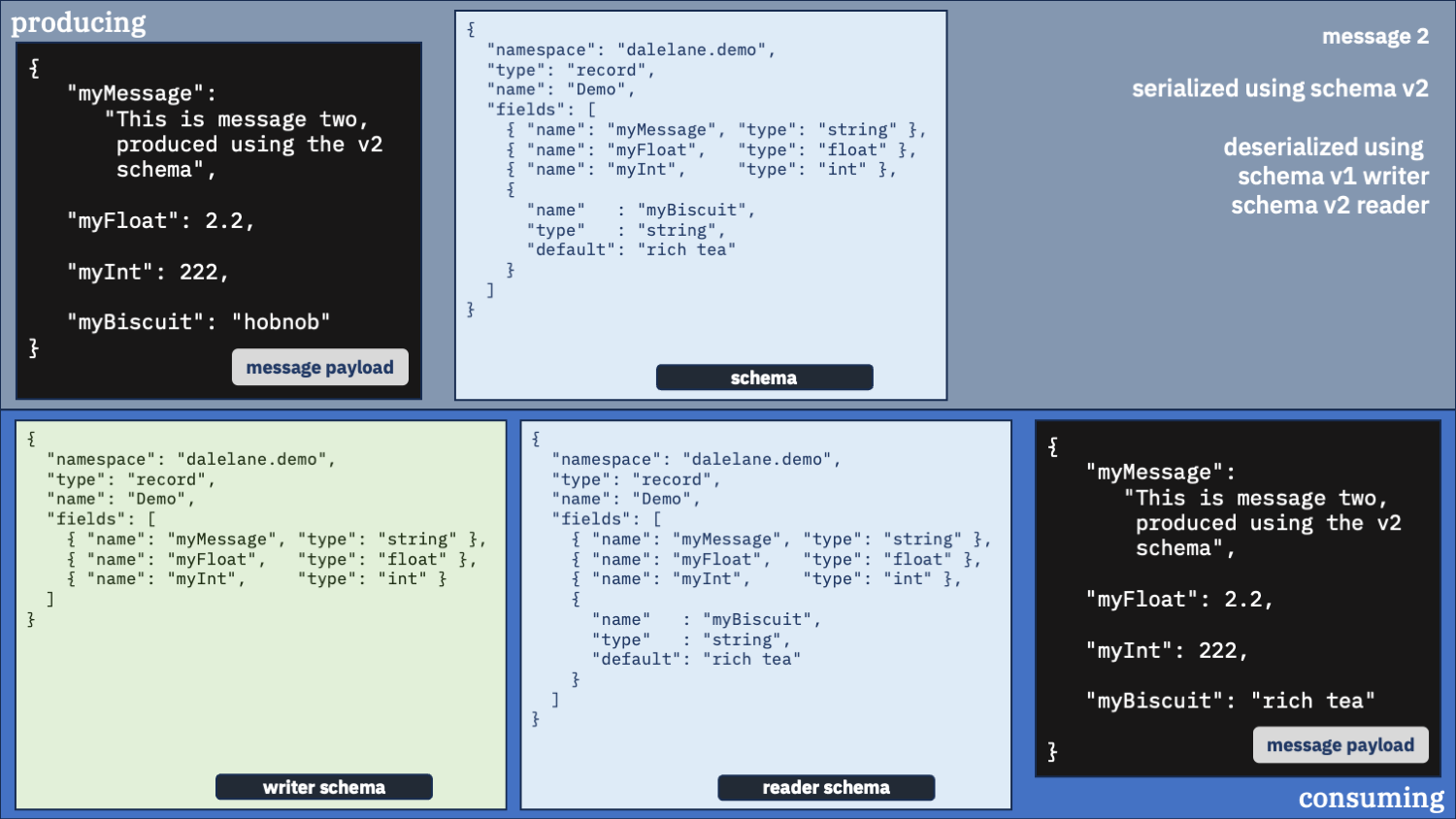
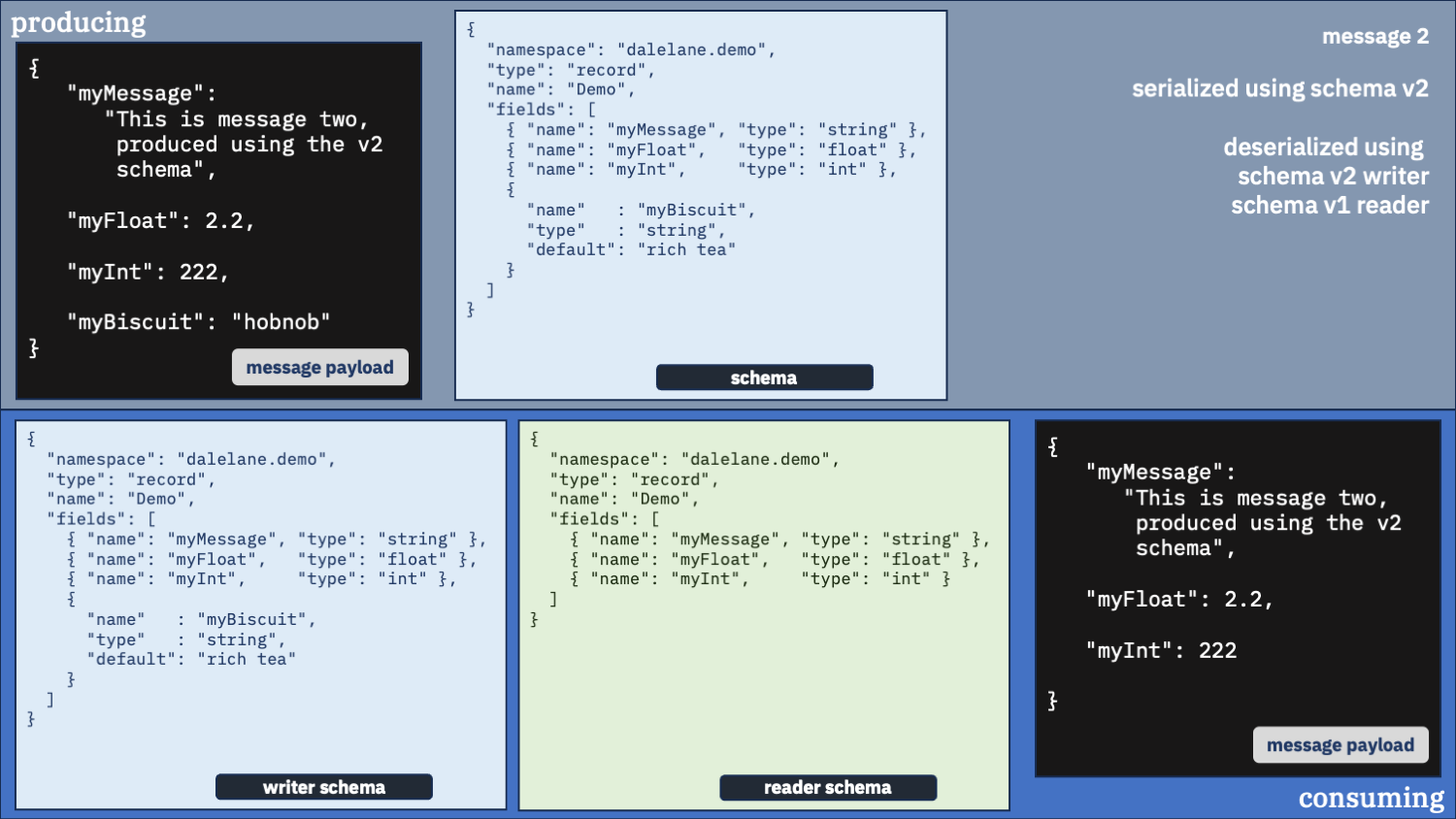
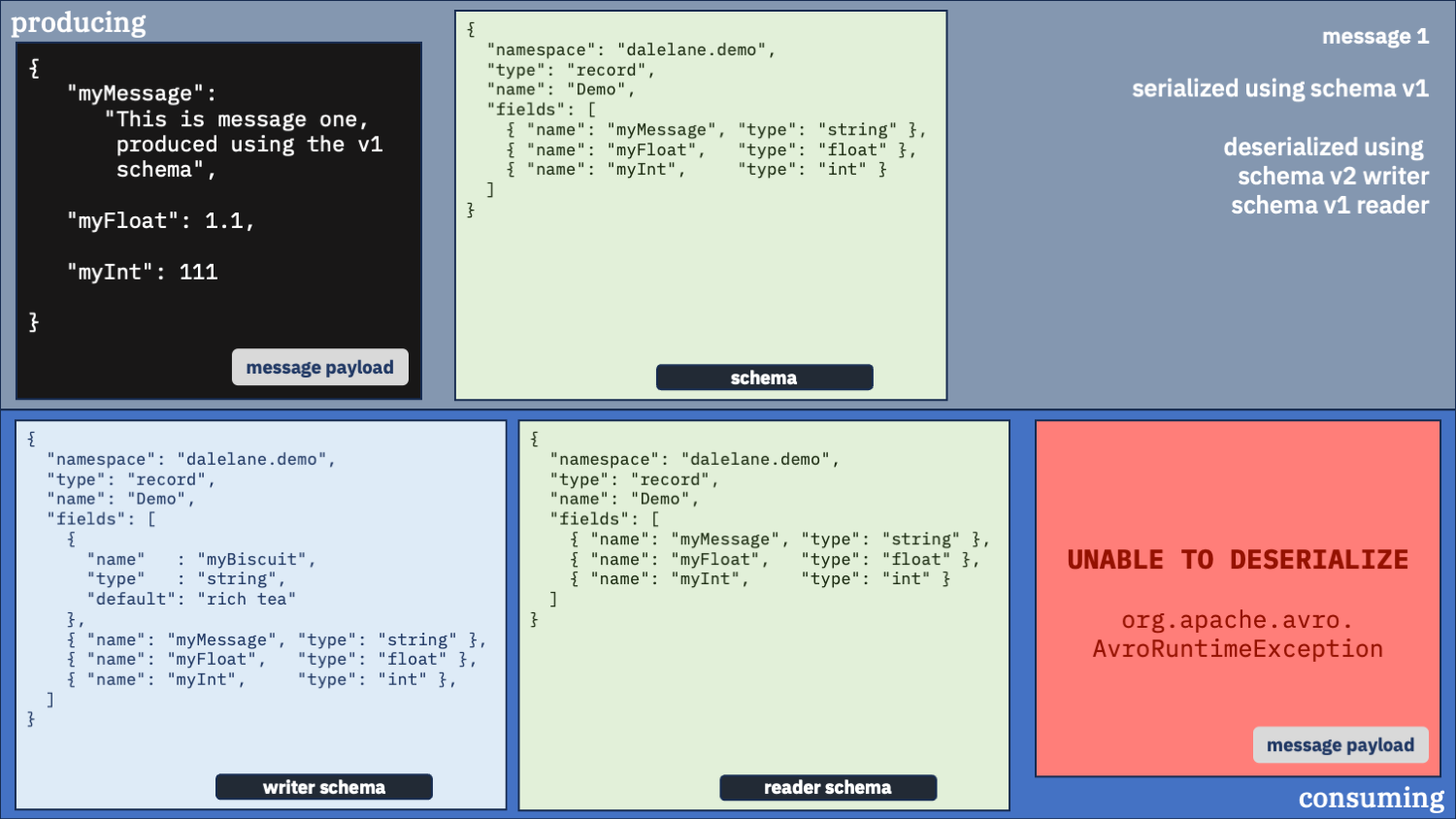
Unusual option 4:
Use the v2 schema as the writer and the v1 schema as the reader
Okay, for completeness sake, let’s see what happens if we swap the schemas around
first message
second message
This wasn’t a great combination.
With the first message, by telling the deserializer the message was originally written with the v2 schema – which isn’t true – it threw another exception trying to read it.
And with the second message, it unpacked the message but by telling it the v1 schema describes what output we want, it meant we didn’t ask it to include the new myBiscuit field – so we lost that.
Obviously, none of these options are correct.
You can’t use the same config for both messages.
You need to provide the schema that was used to serialize the message as the “writer” schema – so the message can be unpacked.
And then you can provide the schema that describes what you want as the “reader” schema.
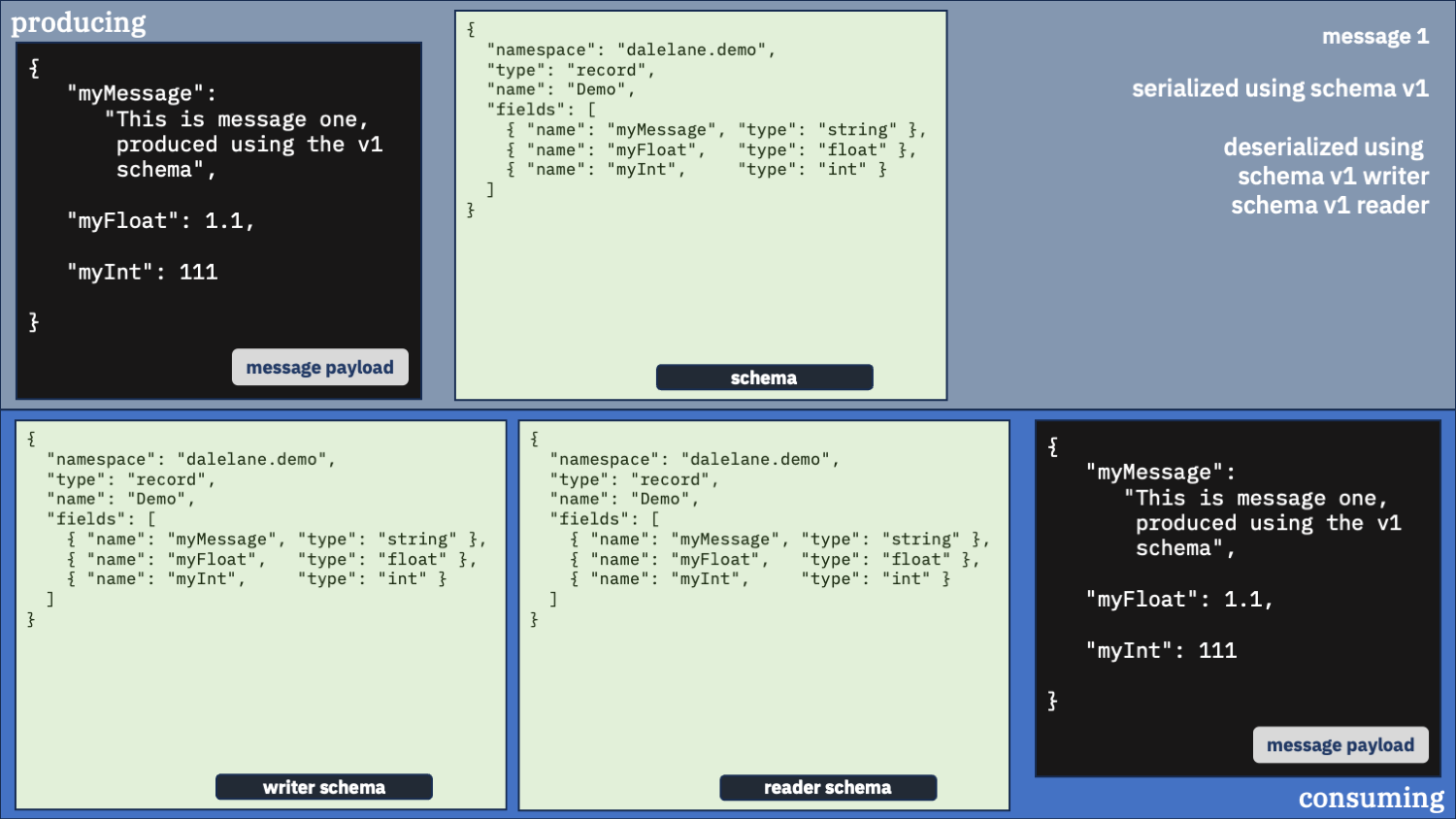
Correct option 1:
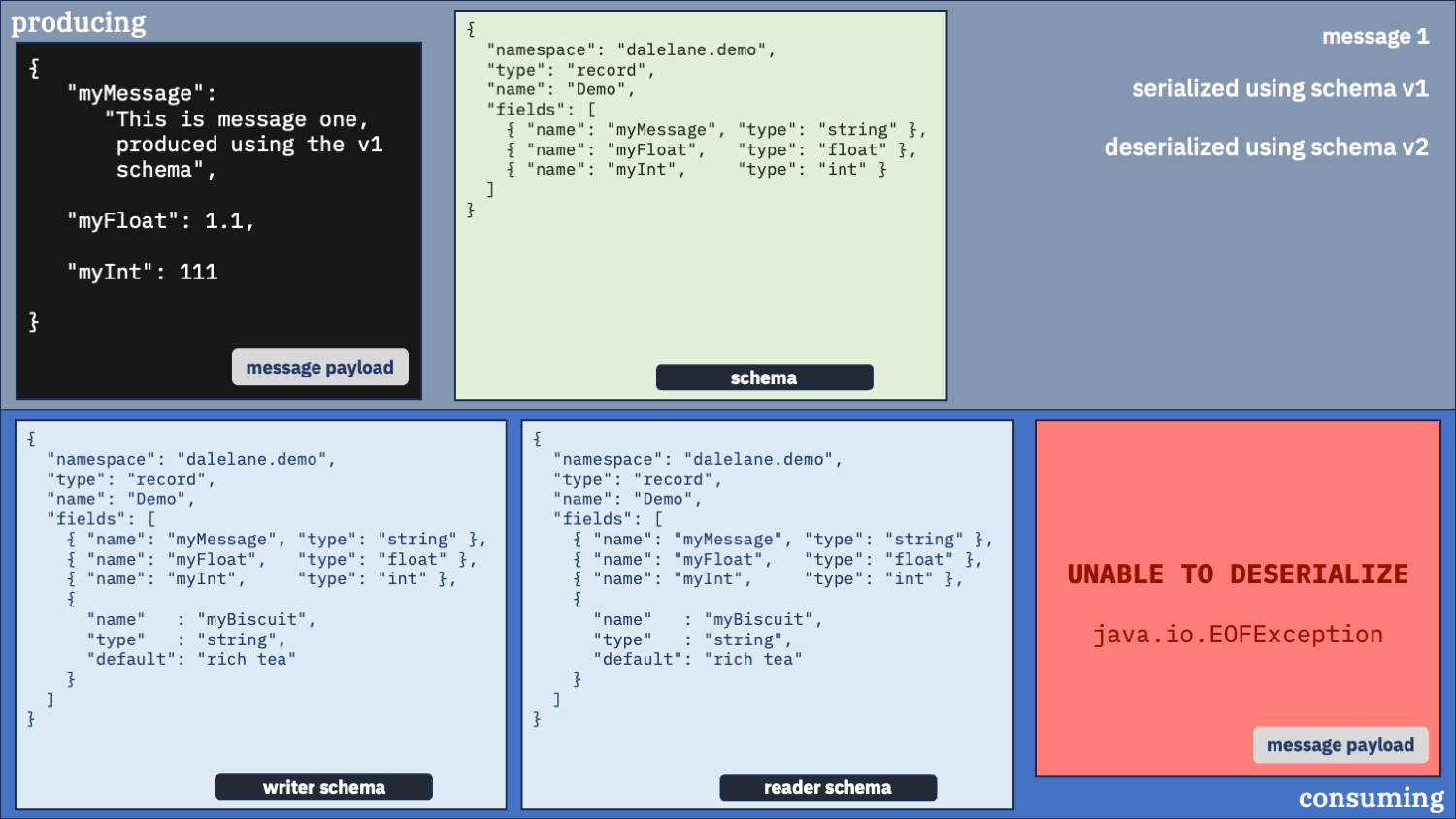
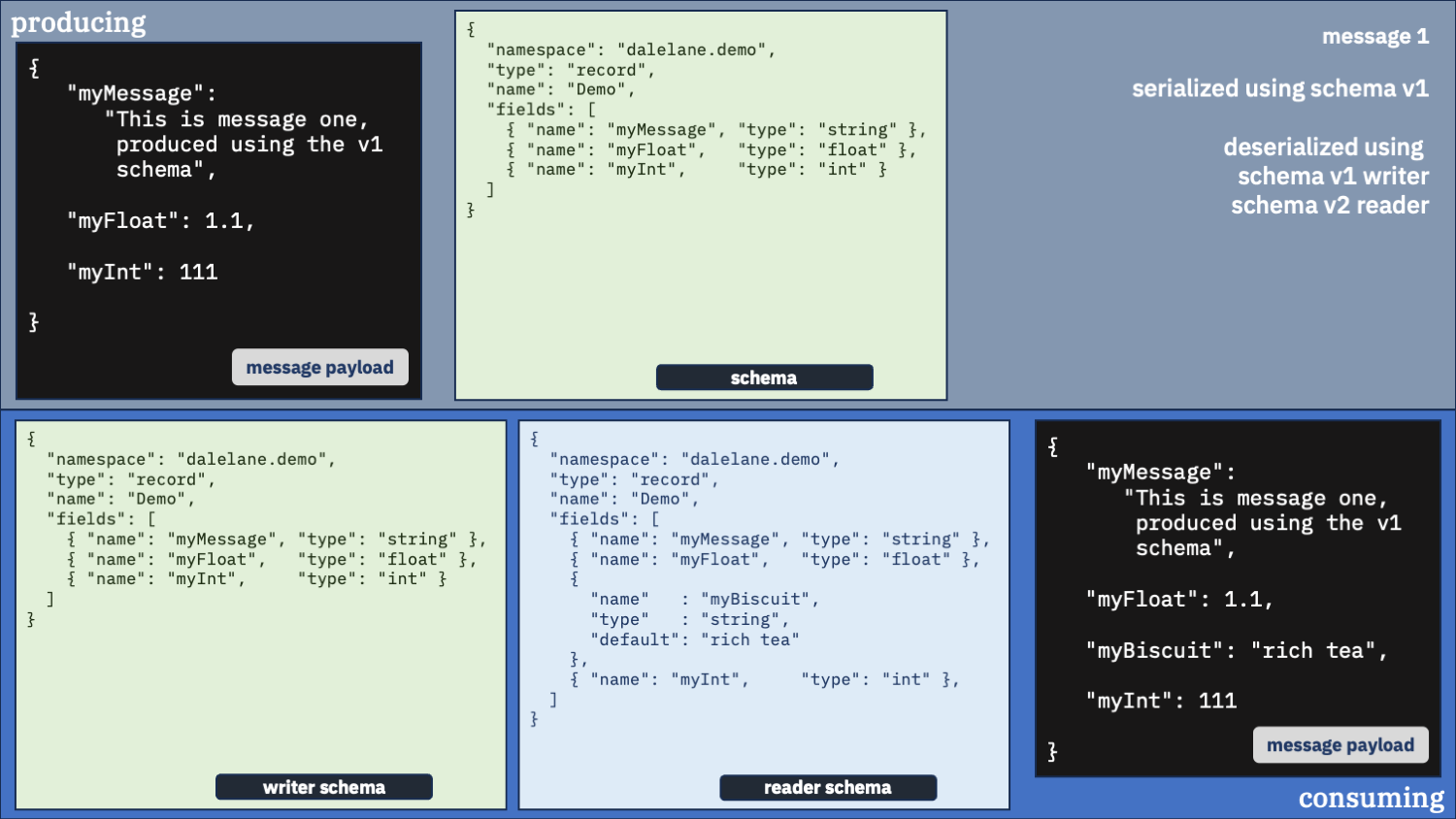
Use the correct schema for the writer schema, and the v1 schema as the reader
Do you only want the original v1 schema fields?
first message
second message
If you only want the fields as described in the v1 schema, you can have that.
You just need to make sure you use the writer schema that was used to serialize the data in the first place [1].
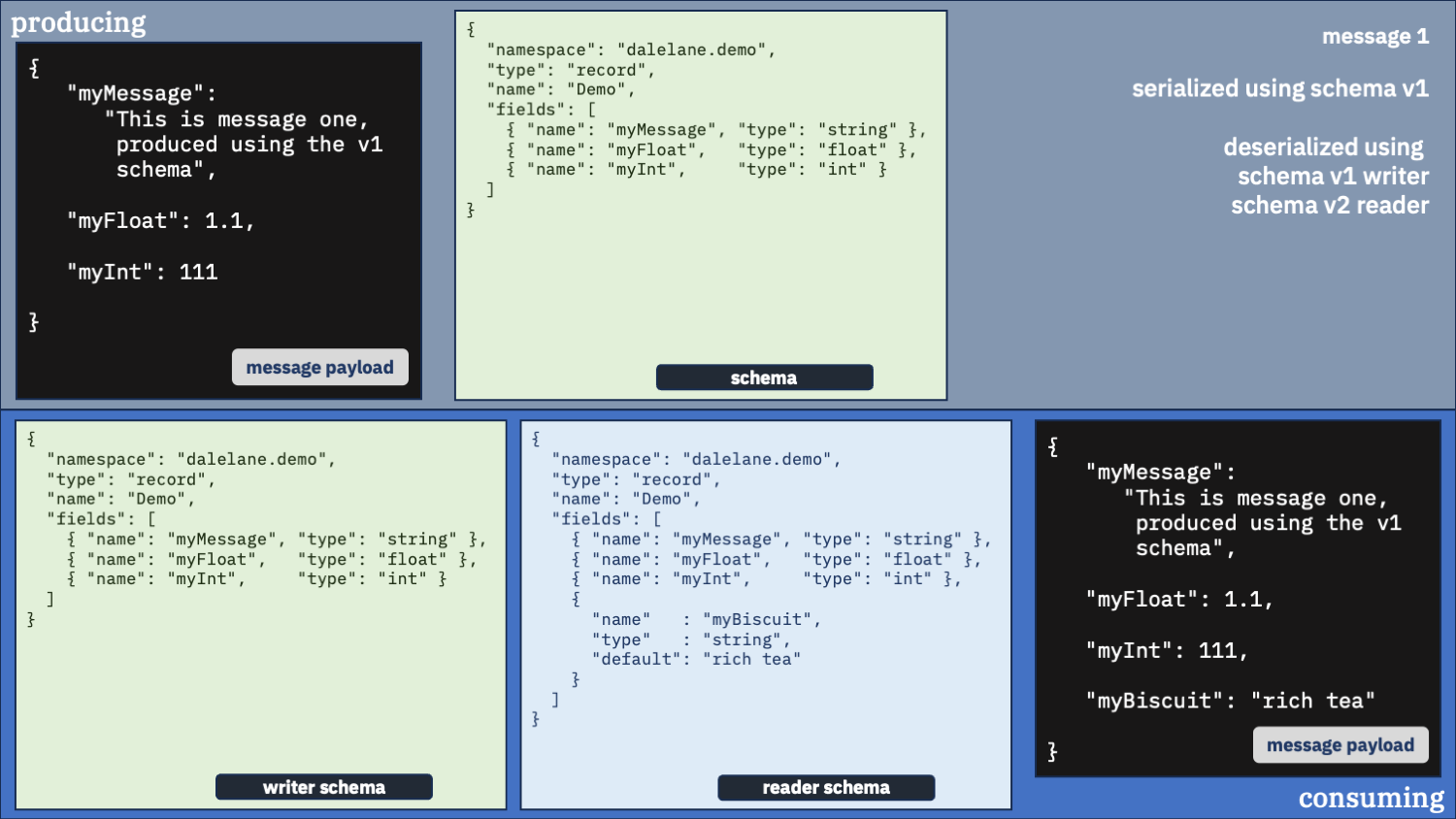
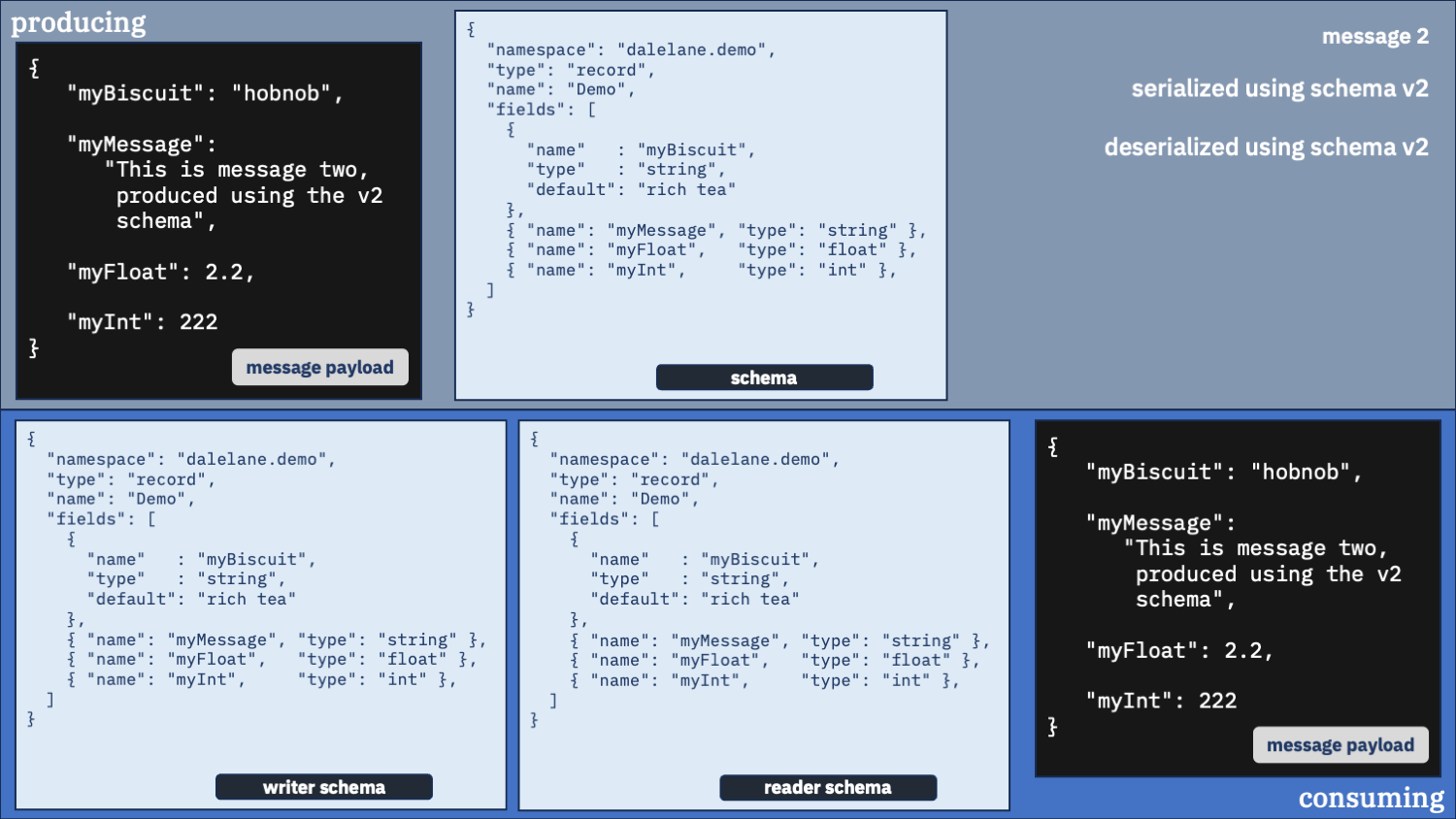
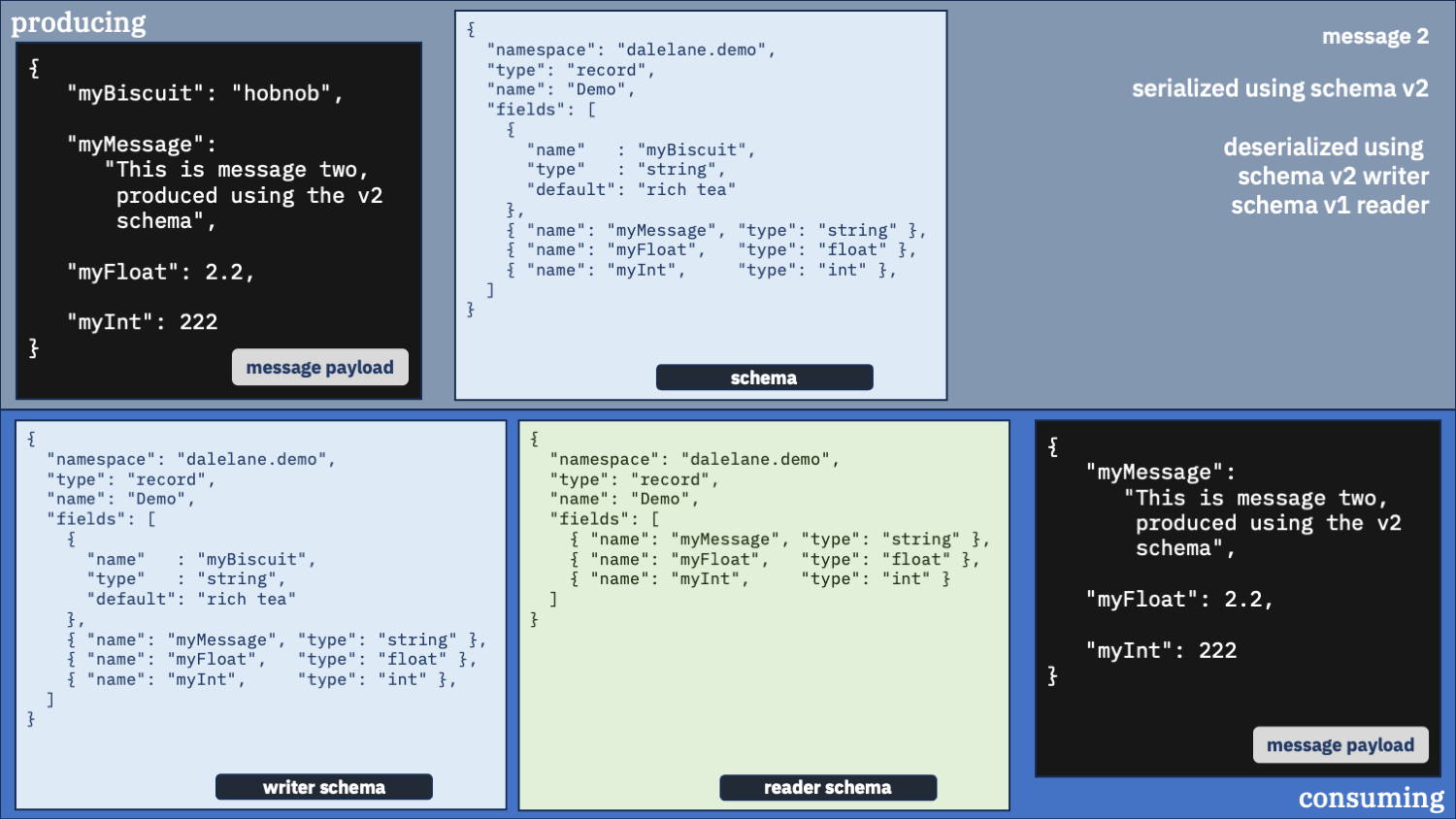
Correct option 2:
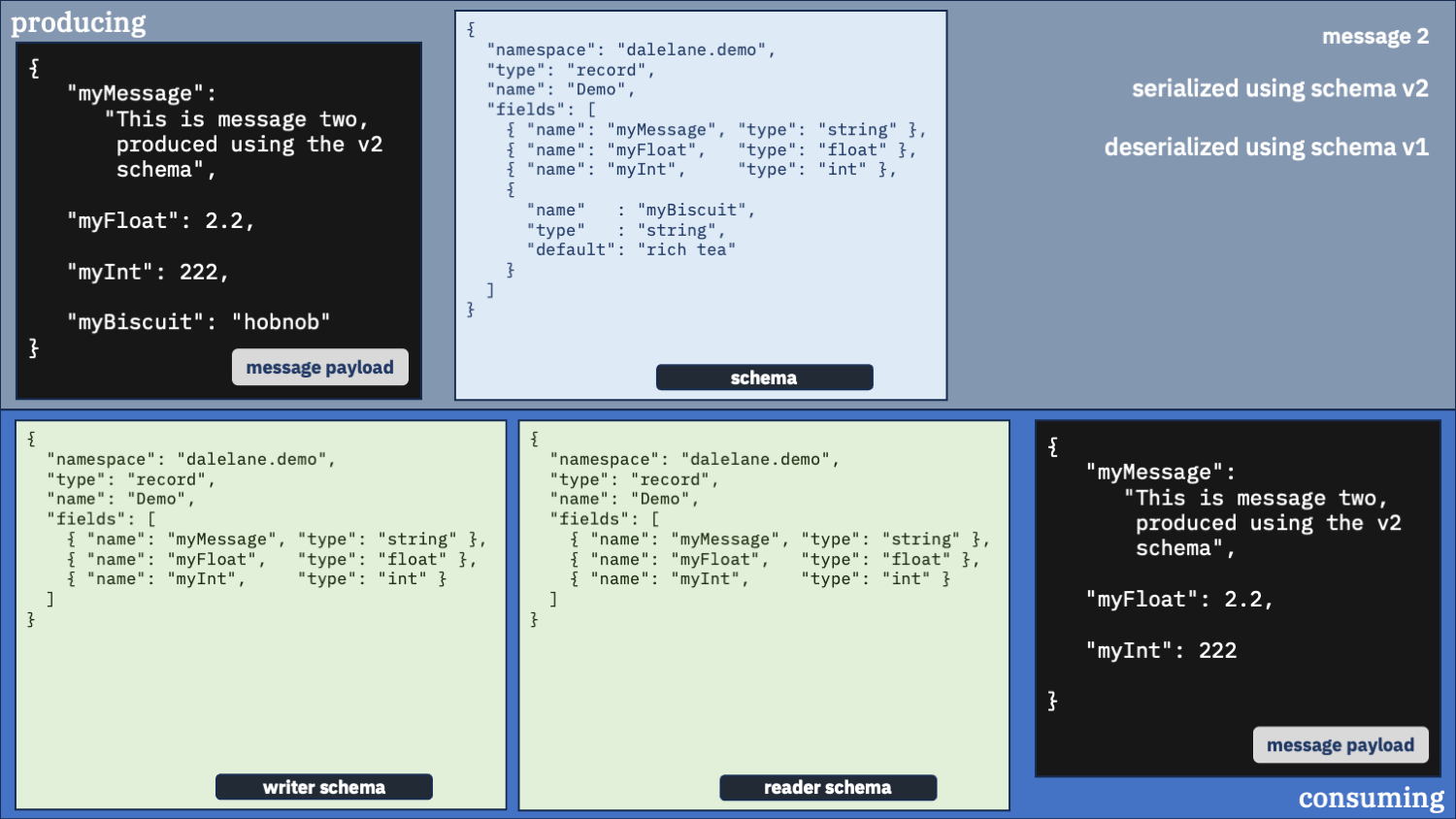
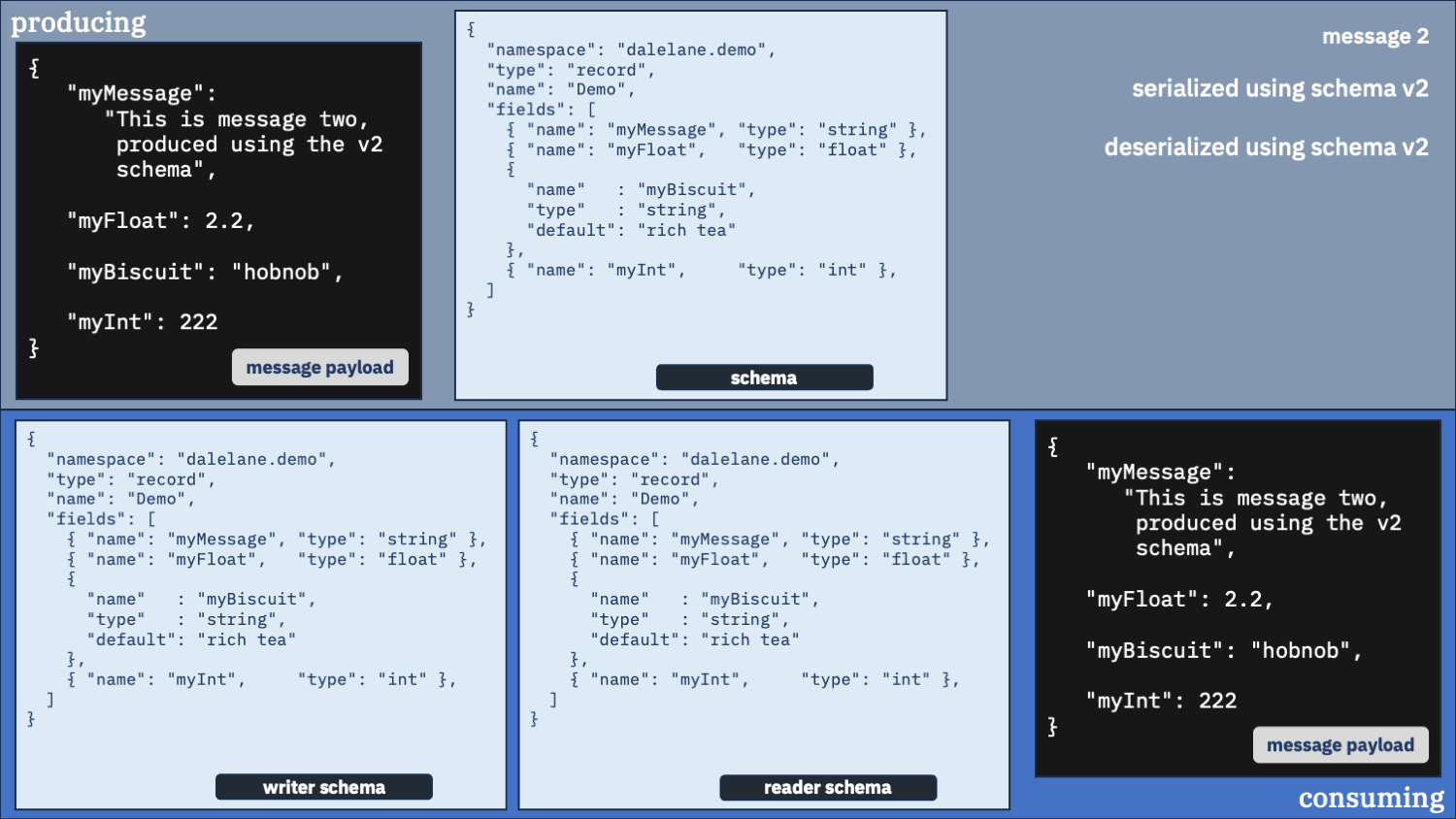
Use the correct schema for the writer schema, and the v2 schema as the reader
Newer is better. You probably want that new field.
first message
second message
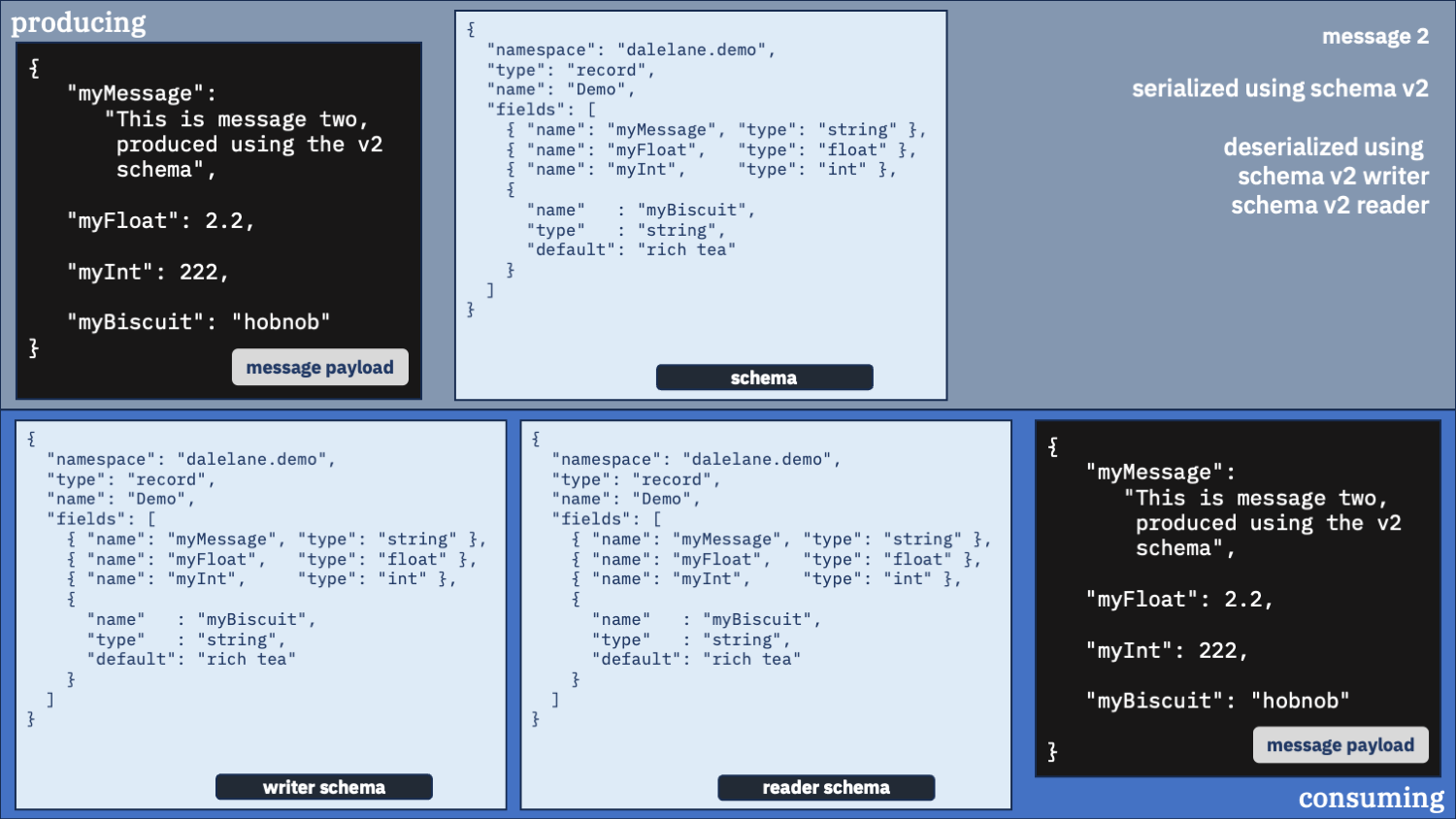
This feels like the right config to me.
You always get messages in the new v2 schema format. And you get the correct default value inserted for the first message which didn’t have that field.
But… you might not be convinced that the “correct options” are really the correct options. Some of those “unusual options” might not have looked that bad to you.
That’s because I started nice and simple by making the v2 schema have the new field added on to the end.
EXAMPLE 2:
PREPENDING A NEW FIELD TO THE SCHEMA
Let’s complicate things a little and put that new field at the start of the message.
The second schema still adds a new field called myBiscuit.
And the second message is setting that field to “hobnob” – the king of biscuits.
This time it’s being added to the start of the message.
Again, we’ll look at how you would configure a Kafka consumer to be able to read both of these messages – and we’ll go through all the different ways you could do this (before we do it properly!)
Unusual option 1:
Configure your consumer to use schema v1
You could just use schema v1 for both messages.
first message
second message
Remember “unusual option 1” didn’t look so bad before, but I said to hold that thought?
This is why.
Look at that second message.
We didn’t get the new myBiscuit field, but that’s fine – I wasn’t expecting to, as I’m using the old schema that doesn’t have that new field.
But look at the values we did get.
All three values are incorrect.
Remember, binary-encoded Avro is a binary format. Information about what-field-is-where is all in the schema. If you give the deserializer the wrong schema, it will trust you and try it.
The schema told it the message starts with a string called myMessage – so the deserializer put the first string it found at the start of the message in that field.
The schema told it it would find a float next. The message data actually contained another string, but the deserializer trusted the schema and tried to turn the bytes it found there into a float.
The invalid schema put the deserializer out of alignment with the way it should have read the data. But it didn’t report an error – it just returned a message with “random” values in, so you wouldn’t have any way of knowing that you’d turned the message data into gibberish.
This is why you don’t want to go with unusual option 1.
(We didn’t have that problem when the new field was at the end, because it just meant the deserializer stopped reading the message before it got to the data for the new field)
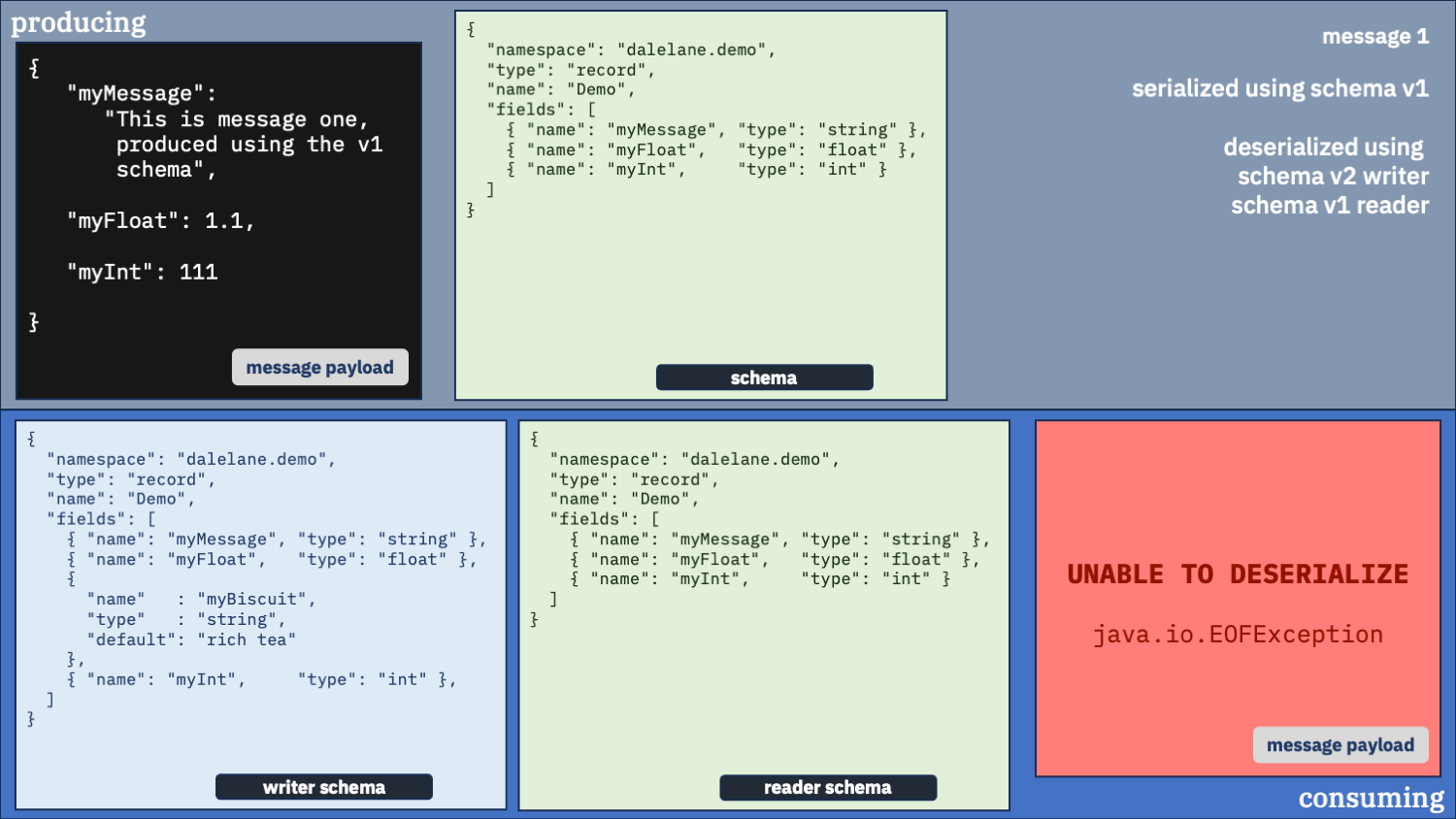
Unusual option 2:
Configure your consumer to use schema v2
Next, we’ll try using the newer schema to deserialize both messages.
first message
second message
Using the new schema for both messages still went bang when it tried to read the first message.
Different exception this time, which is interesting at least.
Don’t do this. You can’t lie to the deserializer. If you tell it the messages were both written using the v2 schema when they weren’t, bad things will happen.
Unusual option 3:
Use the v1 schema as the writer and the v2 schema as the reader
Mixing it up again. This time we’re telling the deserializer that the messages were written with the v1 schema, and that we want them output according to the v2 schema.
first message
second message
Look at what that outputs for the second message.
"myBiscuit" : "rich tea"
We don’t have a value for the myBiscuit field because that isn’t in the v1 schema we used to unpack the message data. And because the v2 schema we use to format the output says to use a default when we don’t have a value, we got the “rich tea” default value.
"myMessage" : "hobnob"
The v1 schema we used to unpack the message data told the deserializer that the first string it found is the myMessage field. The first string in the message data was “hobnob” so that’s what we got.
"myFloat" : 1.755433E25, "myInt": -58
Then because we’re out of alignment again, we turned string data into a gibberish pair of numbers for the remaining fields.
Unusual option 4:
Use the v2 schema as the writer and the v1 schema as the reader
For completeness, let’s finish off the wrong configurations by flipping the schemas round.
first message
second message
Not a great combination.
The deserializer goes bang trying to unpack the first message with the wrong schema.
And by using v1 schema as the reader schema, it means we lose the myBiscuit field from the second message.
We know what the right answer is by now. You can’t use the same config for both messages.
You need to provide the schema that used to serialize the message as the “writer” schema – so the message can be unpacked.
And then you can provide the schema that describes what you want as the “reader” schema.
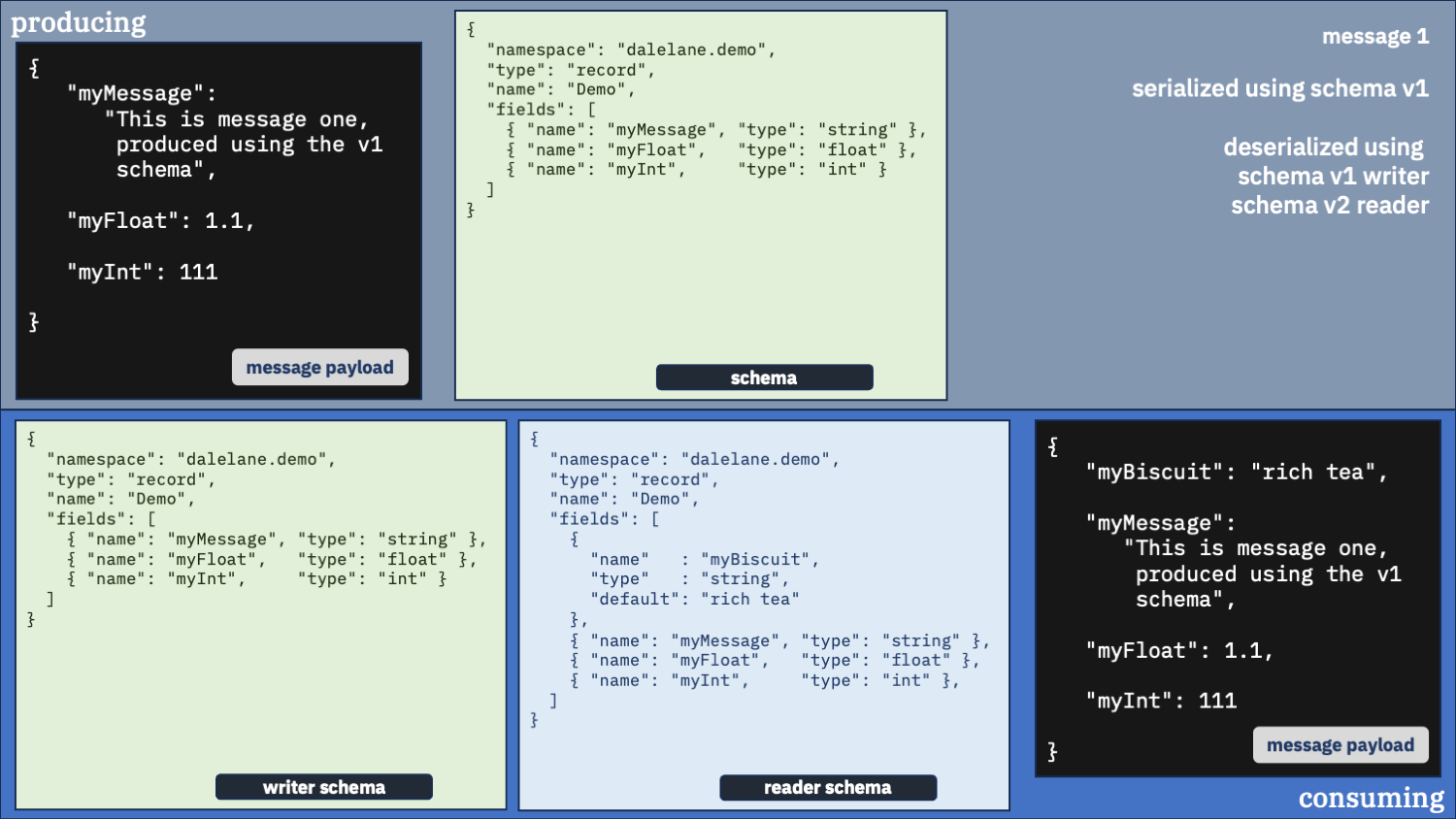
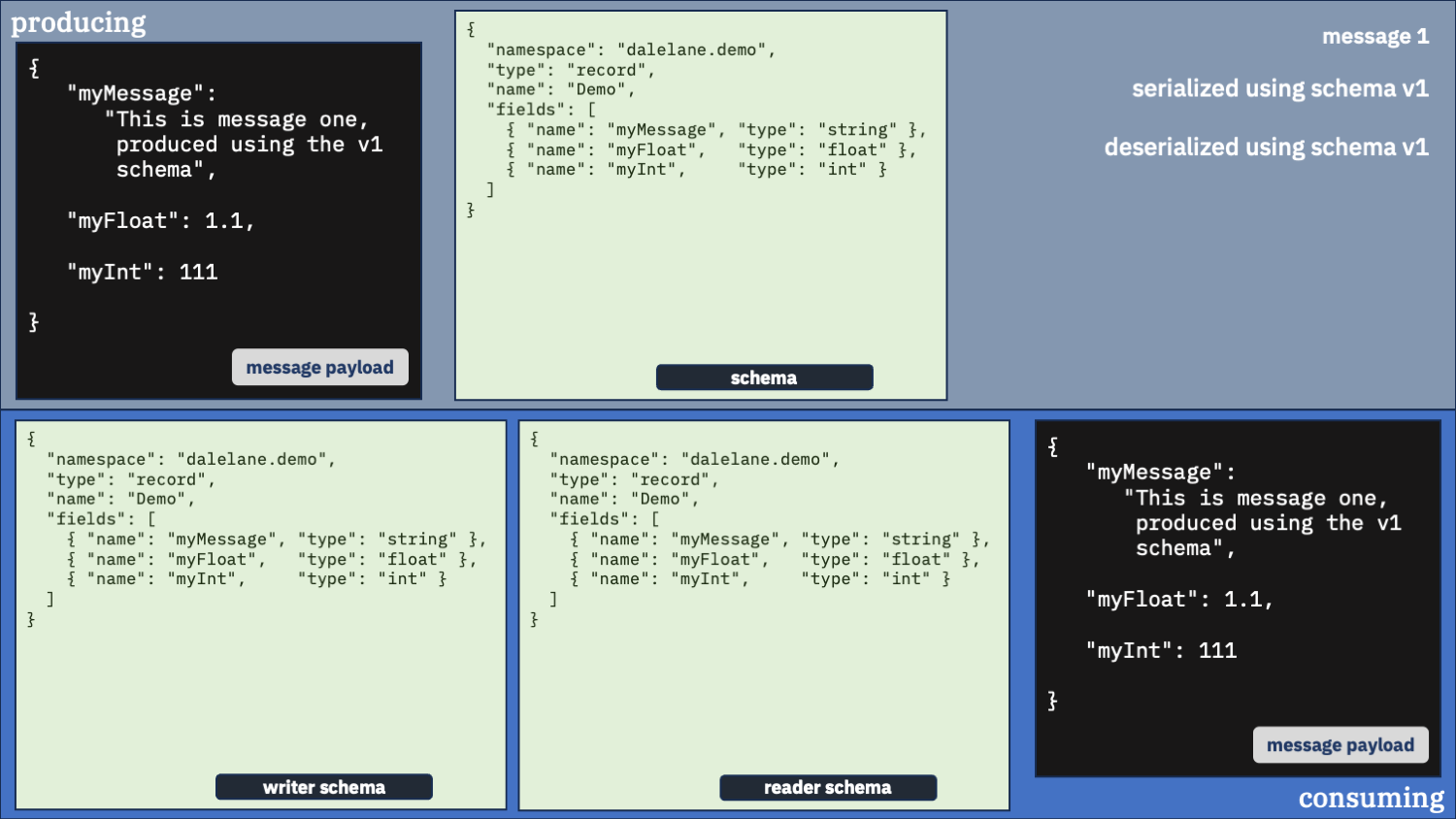
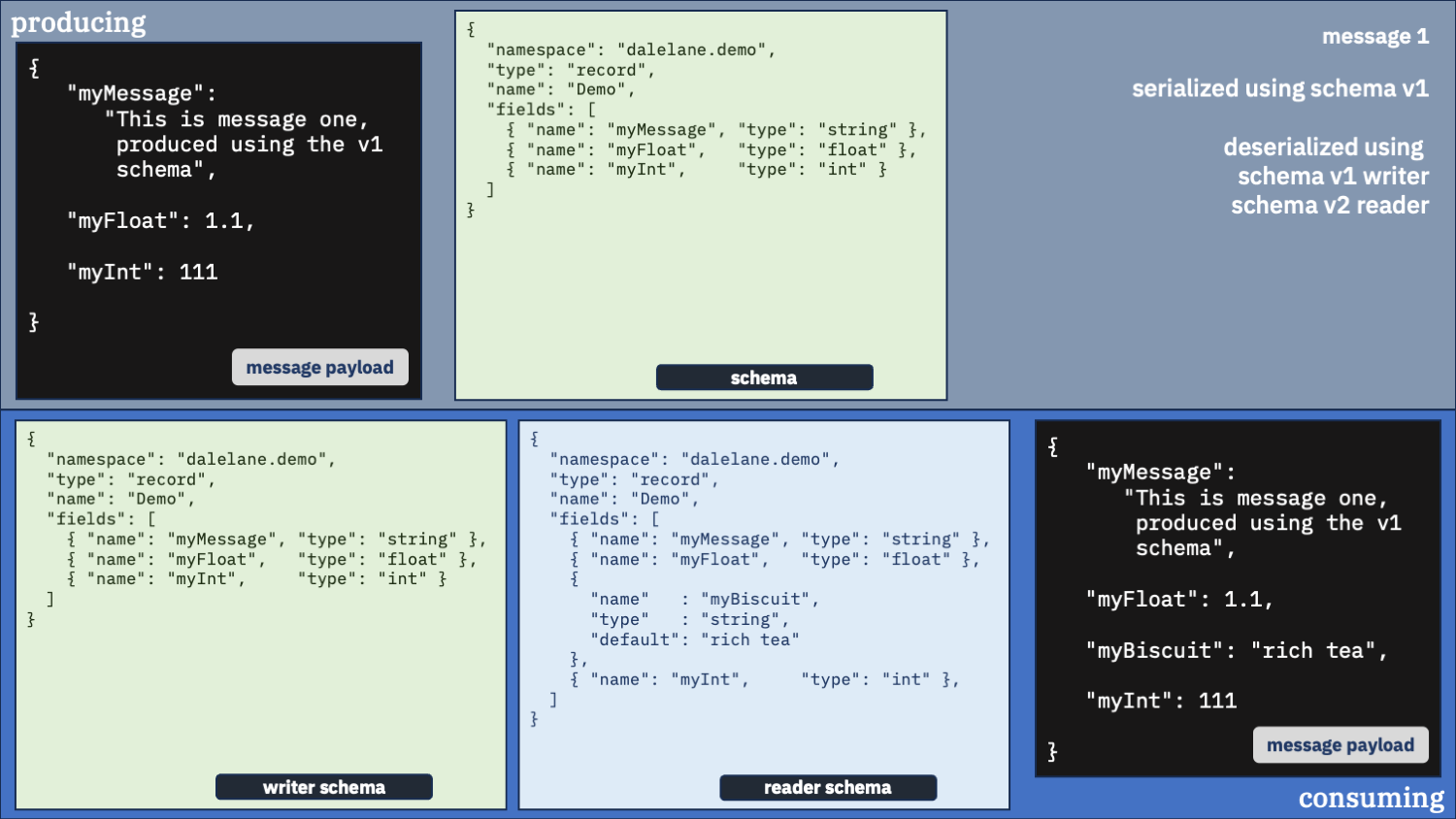
Correct option 1:
Use the correct schema for the writer schema, and the v1 schema as the reader
Let’s see that in action.
Do you only want the original v1 schema fields?
If that’s what you want, that’s what you can have.
first message
second message
You just need to make sure you use the writer schema that was used to serialize the data in the first place [1].
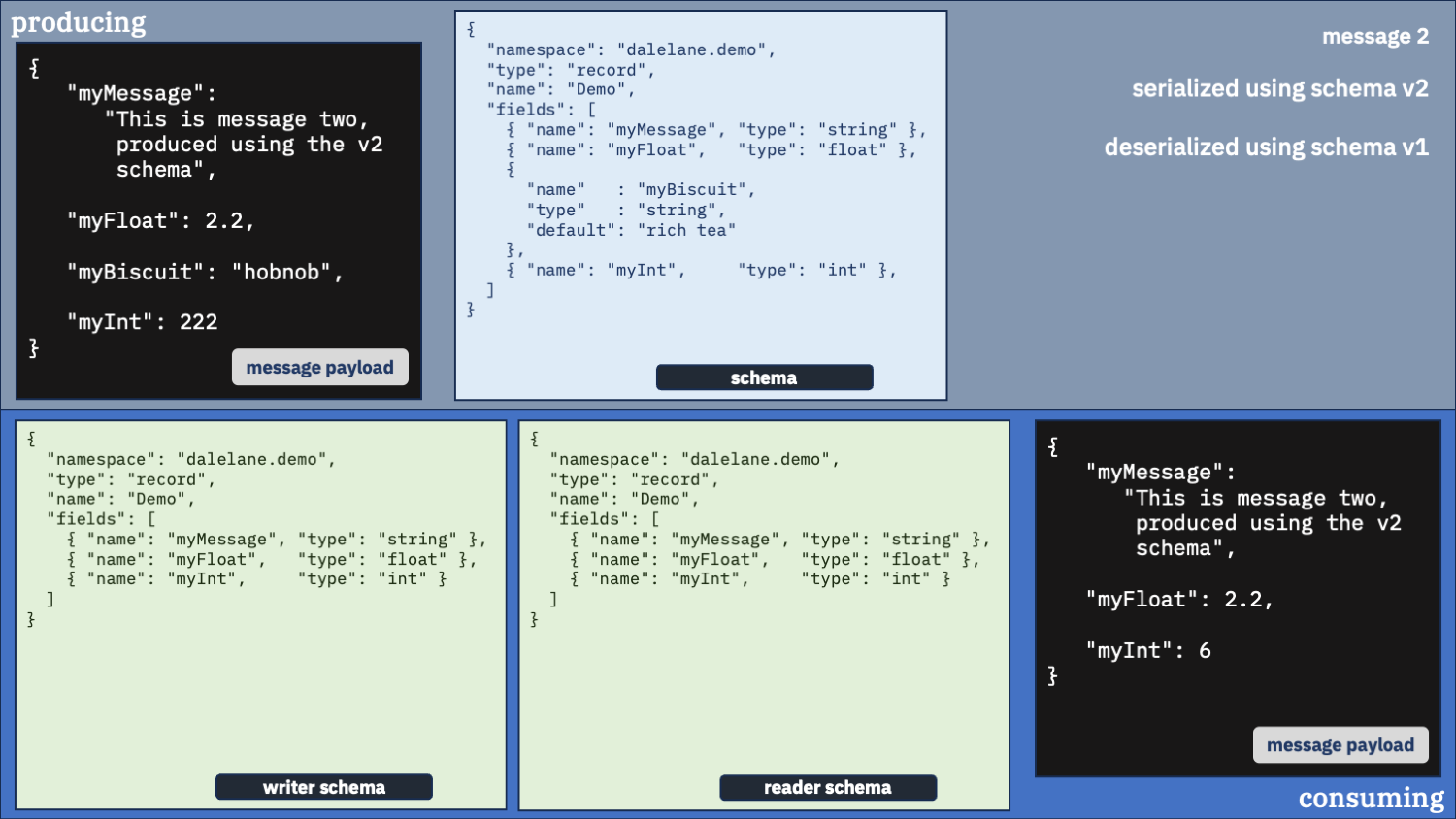
Correct option 2:
Use the correct schema for the writer schema, and the v2 schema as the reader
Newer is better, remember? And biscuits are important.
first message
second message
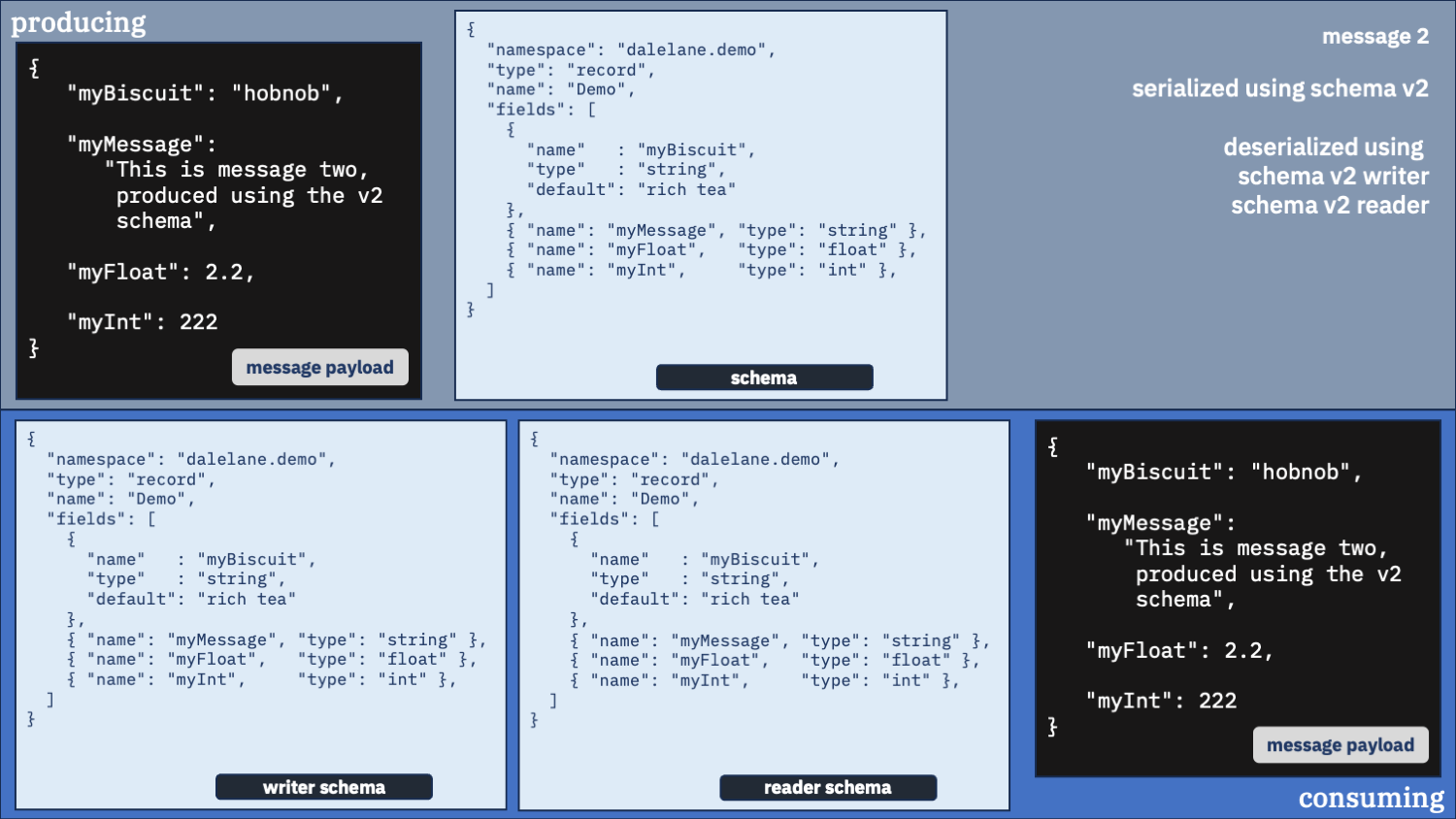
That’s more like it!
Even if the new field is added to the start of the message data, this combination of schema configurations will get you the correct results.
EXAMPLE 3:
INSERTING A NEW FIELD IN THE MIDDLE OF THE SCHEMA
Let us recap by looking at another way we could have modified the schema.
The second schema still adds a new field called myBiscuit.
And the second message is setting that field to “hobnob” – the only true companion to a mug of coffee.
This time it’s being inserted into the middle of the message.
For one final time, we’ll look at how you would configure a Kafka consumer to be able to read both of these messages – and we’ll go through all the more unusual ways you could do this (before we do it properly!)
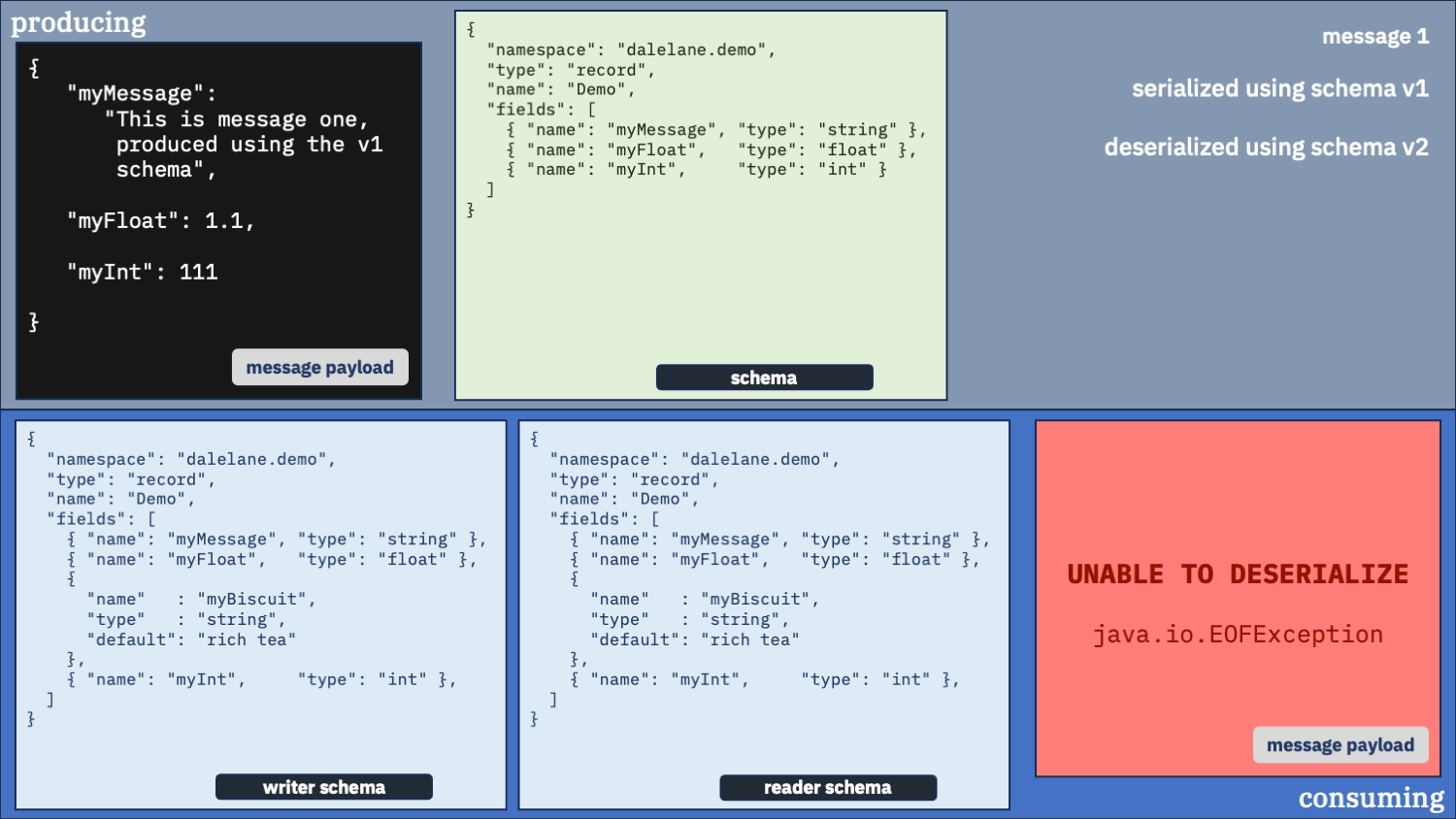
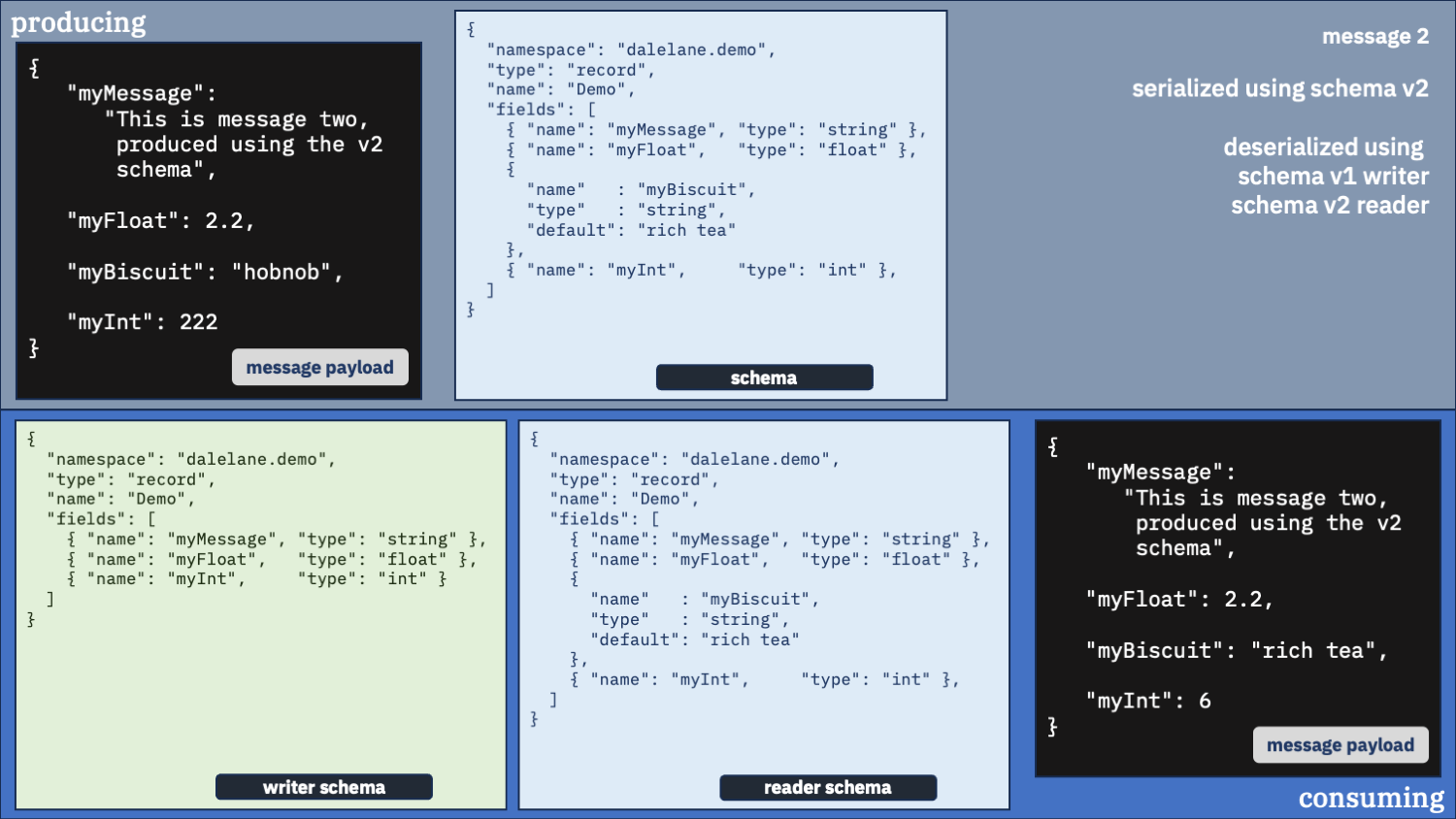
Unusual option 1:
Configure your consumer to use schema v1
Using the old schema to deserialize both messages.
first message
second message
Unusual option 1 didn’t look so bad when the new field was at the end.
But if the new field is anywhere else, it will mess things up. If you give the deserializer the wrong instructions to follow when unpacking the message data, it will put the wrong data into the wrong fields.
"myInt": 6
Look at the myInt value we got in the second message.
The deserializer found the “hobnob” string data after myFloat. And the schema it was using to unpack the data told it the data after myFloat was an integer called myInt. So it turned what it found into an integer and put that in there.
Unusual option 2:
Configure your consumer to use schema v2
Using the new schema to deserialize both messages.
first message
second message
Another exception again when it tried to deserialize the first message.
To deserialize a message, Avro needs a copy of the schema that was used to serialize the message. If you don’t give it the right schema for this, errors are likely.
Unusual option 3:
Use the v1 schema as the writer and the v2 schema as the reader
Let’s mix it up – using the old schema as the writer, and the new schema as the reader.
first message
second message
Look at how this messes up deserializing the second message again.
Using the old schema as the writer means that the new myBiscuit field isn’t unpacked. So the default value gets put in there instead.
And when the deserializer tries to read the myInt integer field that the schema told it came after myFloat, it found bytes from the “hobnob” string, which it turns into the number 6. For some reason.
Don’t do this.
Unusual option 4:
Use the v2 schema as the writer and the v1 schema as the reader
For the last of the bad configurations, let’s flip them round again.
first message
second message
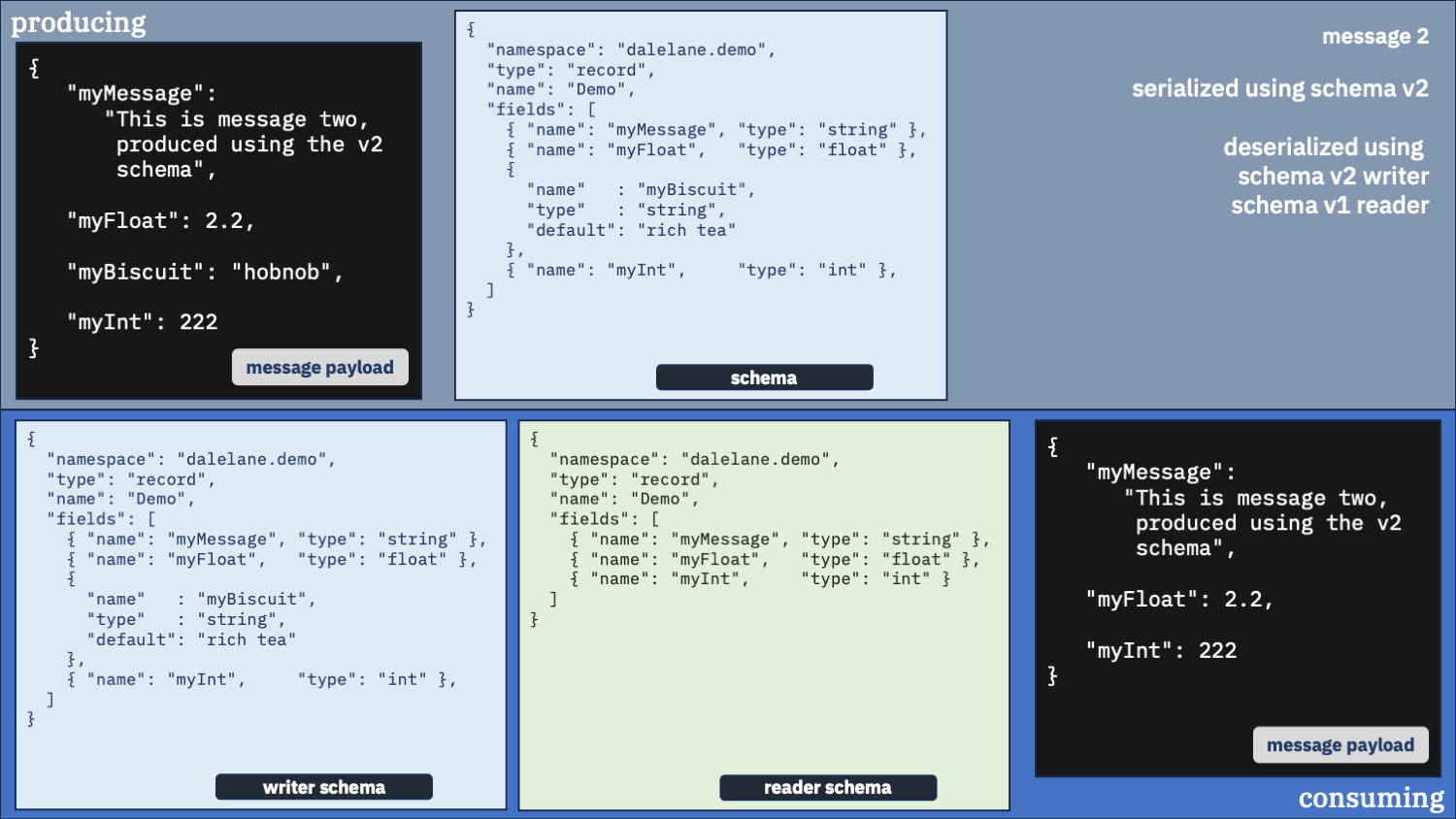
Another exception when trying to read the first message.
And by using v1 schema as the reader schema, it means we lose the myBiscuit field from the second message.
That brings us back to the chorus.
You need to provide two schemas if you want to deserialize binary Avro data.
One is the “writer” schema that tells the deserializer how to unpack the message data. This has to be the schema that was originally used to serialize the message [1].
The second is the “reader” schema. You’ve got more flexibility with this one. You can choose what you want, depending on what output you want.
Let’s see the two choices you have with the correct options one last time.
Correct option 1:
Use the correct schema for the writer schema, and the v1 schema as the reader
Do you only want the original v1 schema fields?
first message
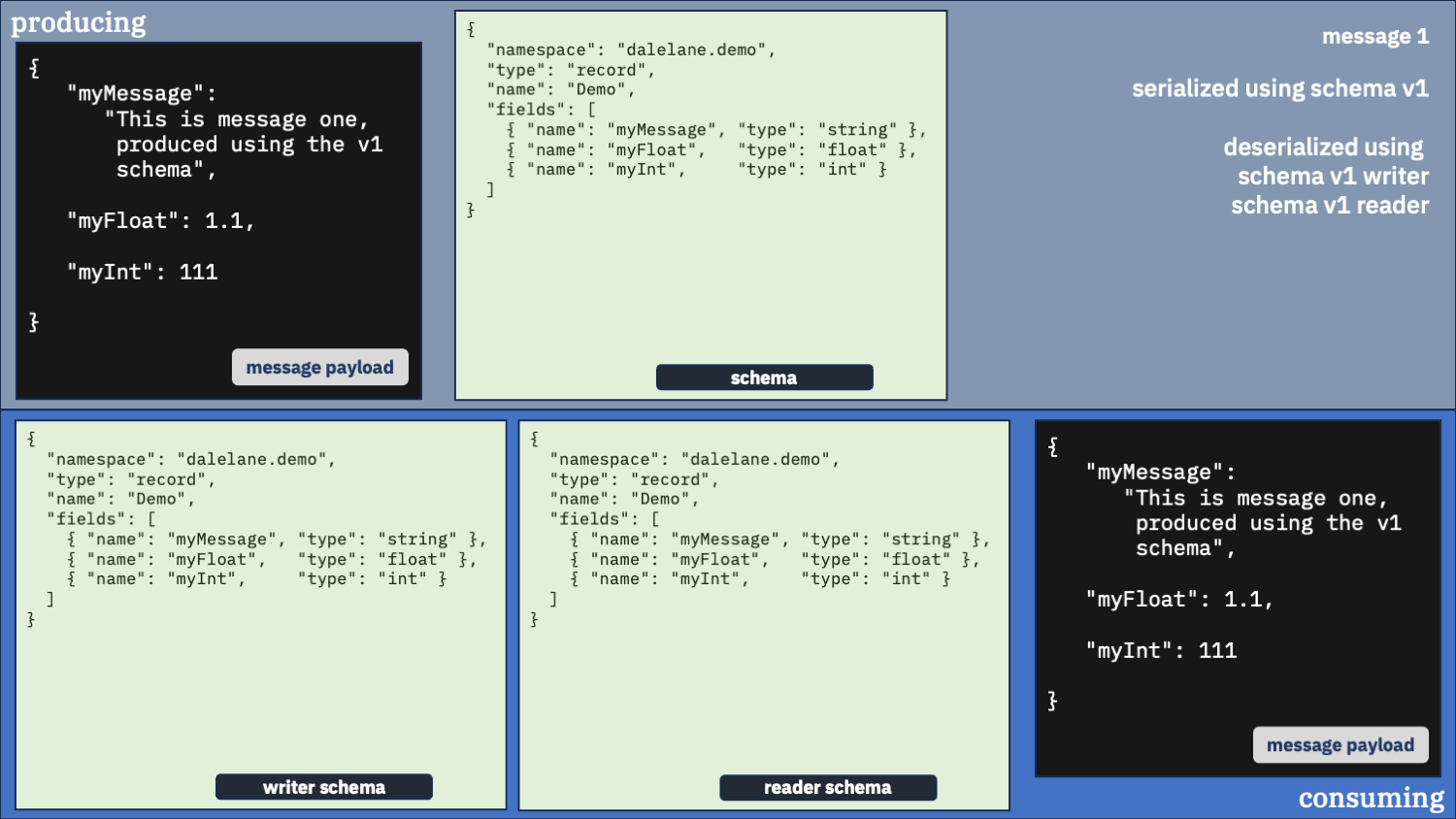
second message
If your application was only coded to use the original fields in the original schema, and isn’t going to use new fields added in newer schemas, it can keep using the original schema as the “reader” schema.
But it needs to use the newer schemas as the “writer” schema when it’s deserializing messages that were created with them.
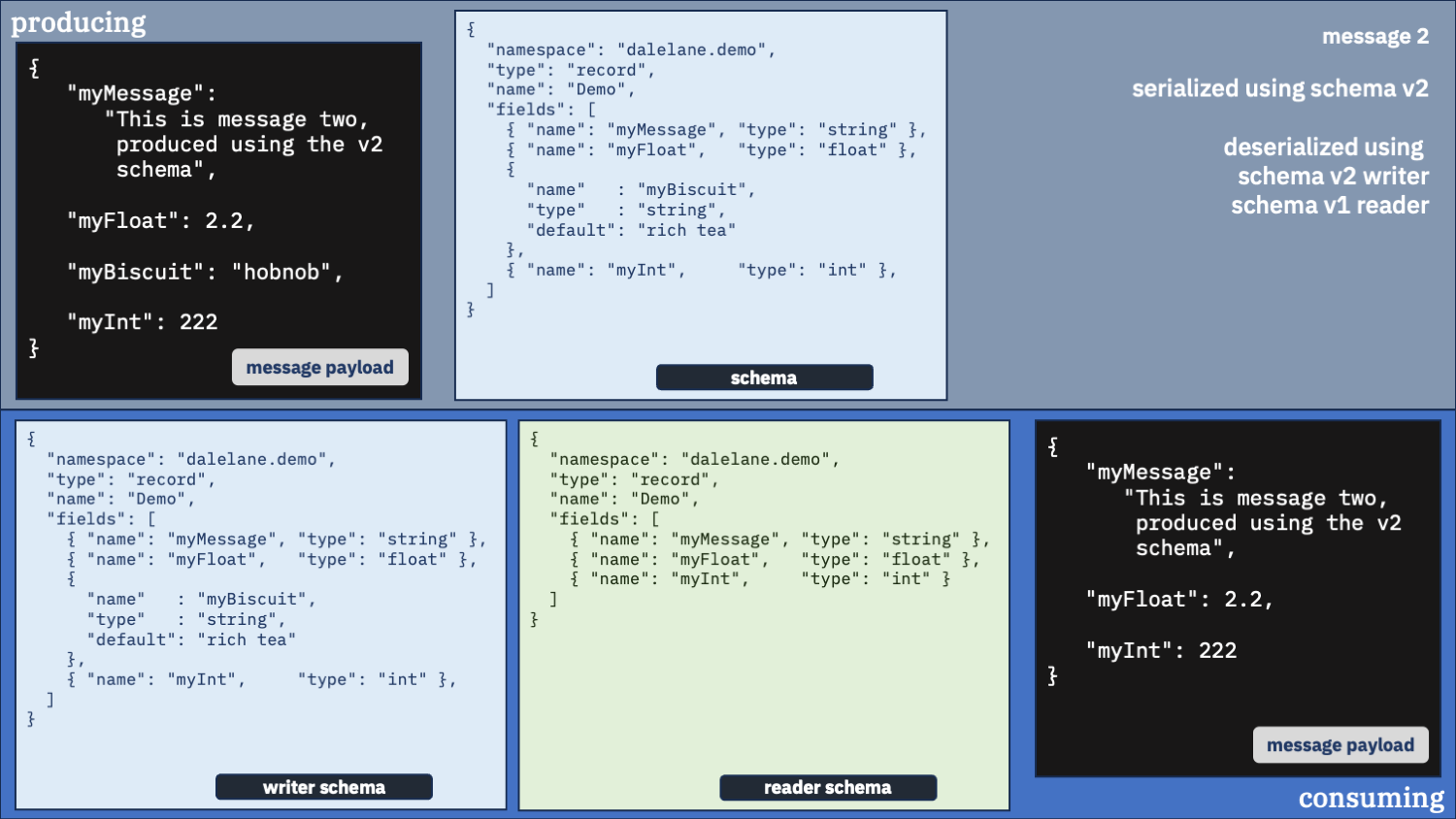
Correct option 2:
Use the correct schema for the writer schema, and the v2 schema as the reader
Do you need the fields in the new schema?
first message
second message
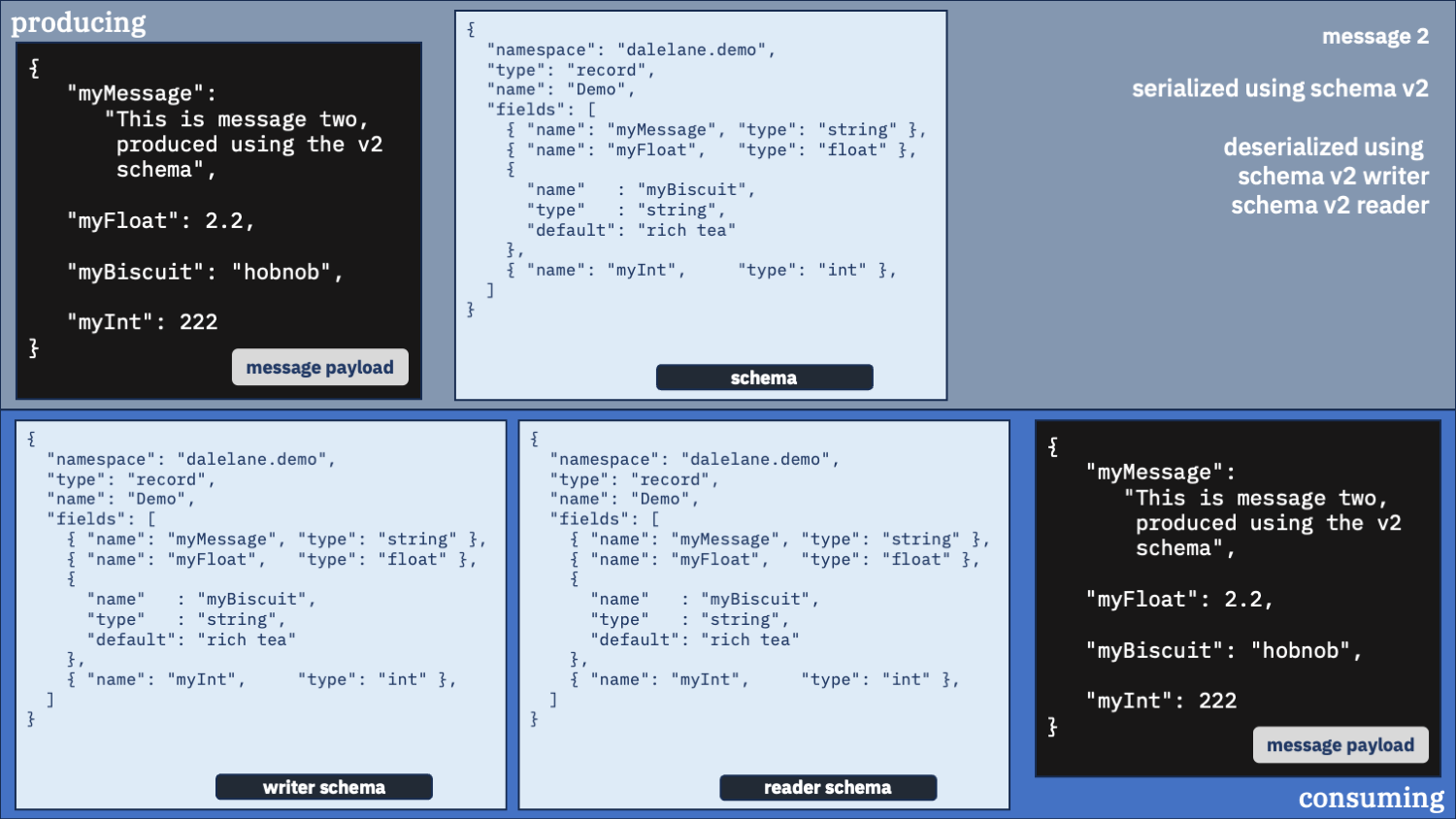
If your application needs to use the fields in the newer schema, it can use this as the “reader” schema.
But it still needs to use the older schemas as the “writer” schema for messages that were created with them.
What schemas do you need?
Let’s go back to the question I asked at the start of all of this.
If you want a consumer application to be able to consume all of the messages on this topic, what does that mean?
It means, the application will need to use all three schemas.
Assuming your application should use fields from the latest-and-greatest version 3 of the schema, you will use version 3 as the reader schema.
When it’s consuming the green messages, it needs to use version 1 of the schema as the writer schema.
When it’s consuming the blue messages, it needs to use version 2 of the schema as the writer schema.
And when it’s consuming the yellow messages, it needs to use version 3 of the schema as the writer schema.
How do you do that?
This sounds fiddly, but if you’re using a schema registry and client library, most of this will likely be sorted out for you automatically. Each message will be individually marked in some way [2] with the correct schema version, and the client library will use that to know which schemas to fetch and use.
What if you can’t do that?
Sometimes that might not be an option. For example, this week I was using Flink SQL to process Avro messages on a Kafka topic.
The Avro formatter in Flink uses your CREATE TABLE definition to dynamically generate an Avro schema, and then it uses that as both the writer and reader schema. It doesn’t give you a way to separately provide both schemas.
My ideal answer would’ve been a Flink Schema Registry formatter that works with client libraries such as Apicurio. This could still use the CREATE TABLE definition to dynamically generate the reader schema, but it could fetch the appropriate writer schema from a schema registry, specific to each message.
But in the meantime, I think the key is going to be to avoid mixing versions of schemas on a single topic. Keeping the schema versions consistent on each topic will avoid the sorts of errors described above.
Want to try this for yourself?
If you prefer to see running code instead of pictures, you can find a Java application ready to run at github.com/dalelane/avro-explorations
It reproduces everything I’ve shown here.
[1] – Pedantic note – it doesn’t need to be the exact same schema to be honest, but it needs to be structurally identical. And as the docs say:
“The best way to ensure that the schema is structurally identical to the one used to write the data is to use the exact same schema.”
[2] – How and where it stores this information depends on which library you use. Some modify the message payload, some use message headers. The principle is the same, and the point is you don’t need to worry about it.
Tags: apacheavro, apachekafka, avro, kafka
Great post. Thanks a lot with these great examples.