aka Approaches to managing Kafka topic creation with IBM Event Streams
How can you best operate central Kafka clusters, that can be shared by multiple different development teams?
Administrators talk about wanting to enable teams to create Kafka topics when they need them, but worry about it resulting in their Kafka clusters turning into a sprawling “Wild West”. At best, they talk about the mess of anonymous topics that are named and configured inconsistently. At worst, they talk about topics being created or configured in ways that negatively affect their Kafka cluster and impact their other users.
With that in mind, I wanted to share a few ideas for how to control the topics that are created in your Event Streams cluster:
Naming conventions & delegated authority
Perhaps the simplest approach is to give each team a unique prefix, and give them credentials that let them do whatever they want with topics that have names that start with that prefix.
For example:
apiVersion: eventstreams.ibm.com/v1beta2
kind: KafkaUser
metadata:
labels:
app.kubernetes.io/instance: my-kafka-cluster
eventstreams.ibm.com/cluster: my-kafka-cluster
annotations:
acme.teams/name: blue
acme.teams/admin: Joe Bloggs
acme.teams/contact: [email protected]
name: blueteam-admin
namespace: event-automation
spec:
authentication:
type: scram-sha-512
authorization:
acls:
- operations:
- All
resource:
name: BLUE.
patternType: prefix
type: topic
- operations:
- DescribeConfigs
resource:
type: cluster
- operations:
- Read
resource:
name: __schema_
patternType: prefix
type: topic
type: simple
That will create a username and password for the “blue team” administrator, and let them do whatever they want with topics – as long as they have a name beginning with BLUE..
This username and password will work with the Event Streams web UI, and only let them see and interact with the BLUE. topics. It will also be usable with the Kafka admin API, so even if they use tools like kafka-topics.sh the same restrictions will be applied.
Benefits:
- As the owner of the cluster, delegating to individual teams reduces your workload – you can leave individual teams to manage their topics without having to do it for them.
- Enforcing a naming convention gives you oversight of the topics on your cluster – you know that all the topics with names starting
BLUE.are being used by the “blue team”. - Giving the team administrator the freedom and flexibility to create and manage topics immediately allows them to be responsive and avoid delays.
- This works with standard Kafka admin tools, as well as the Event Streams web UI.
- (As a bonus, if you add annotations as shown in the example above, you also have a reminder of who your delegated administrator is for these topics, in case you need to reach out to them.)
Limitations:
- This depends on you trusting the administrators that you are delegating topic management to. The only thing you are enforcing is the topic name, otherwise they are free to do whatever they want – including things that could have a negative impact on your cluster, such as creating topics with much larger retention or higher number of partitions than you would like.
In summary…
This approach is well-suited to development environments, where you want to help multiple teams to avoid clashing with each other, while still enabling development teams to quickly and flexibly create and modify topics on-demand, using a variety of Kafka tools.
GitOps
Event Streams (and the Strimzi Operator that it extends) are a great fit with GitOps workflows. Every Kafka topic in Event Streams is represented with a Kubernetes custom resource.
One approach to topic management is to embrace this fully, and adopt GitOps:
- Make the Event Streams Kubernetes Topic Operator the only thing that has permission to create/delete/modify topics. Don’t give anyone the ability to dynamically manage topics.
- Don’t give anyone the ability to dynamically create/delete/modify the Kubernetes custom resources
- Make a GitOps tool (such as Argo CD) responsible for making all changes to the Event Streams Kubernetes custom resources
This gives you a rigorous, formal way to manage your Kafka topics:
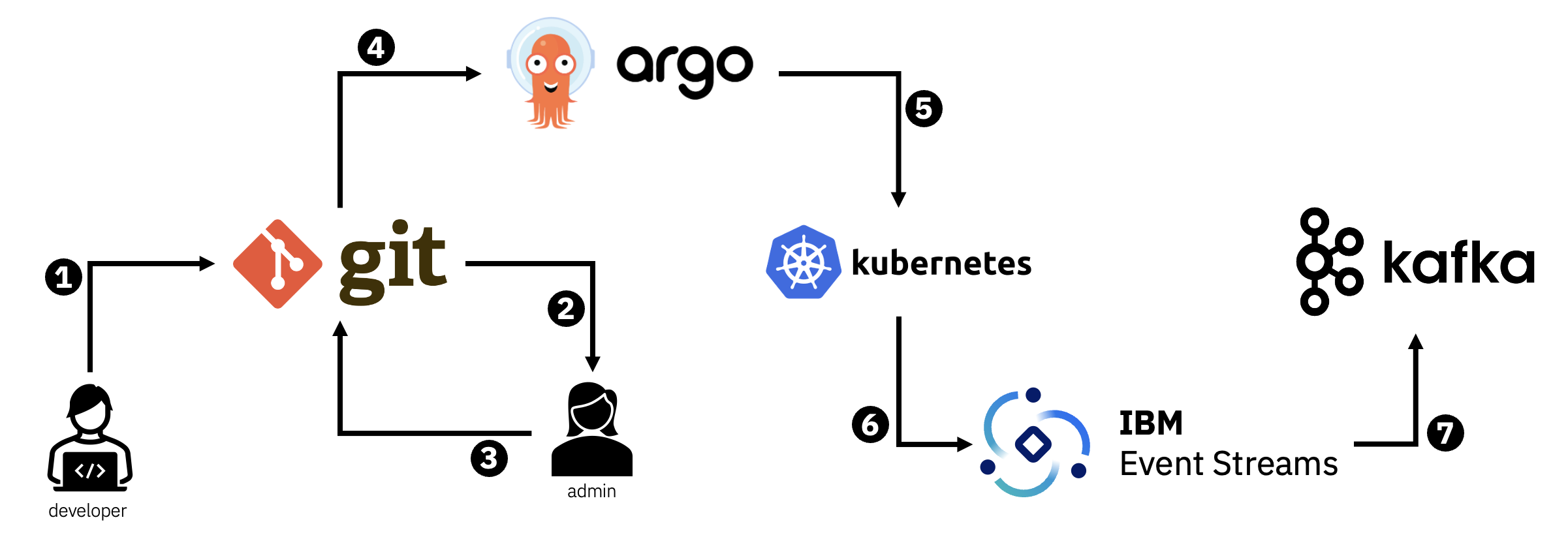
1 – A developer wants to create a new topic (or modify/delete an existing topic) so they document what they want in a YAML specification that they submit in a pull request
2 – Git notifies the cluster administrator that a change has been requested. The administrator can review this request to determine if this is an appropriate change.
3 – If appropriate, the cluster administrator approves the pull request, and merges the change. The new topic specification is now contained in the main branch.
4 – Argo CD is notified (or detects) that there has been a change in the git repository
5 – Argo CD compares the current specification in git with what is defined in Kubernetes, and makes whatever changes are necessary (creating / modifying / deleting resources) to make Kubernetes match the specification
6 – Event Streams is notified (or detects) that there has been a change in the Kubernetes resources
7 – Event Streams compares the current specification in Kubernetes with what is defined in Kafka, and makes whatever changes are necessary (creating / modifying / deleting topics) to make Kafka match the specification
Benefits:
- This gives the application developer teams a well-defined way to request precisely what they need (e.g. how many topics? what retention limits do they want? how many partitions? etc.)
- This defines a formal process that will be applied before anything is changed on the Kafka cluster. The cluster administrator must review and formally approve any changes first.
- The commit history for the git repository becomes an audit log for the Kafka cluster. Every topic on the Kafka cluster has a full history of who requested it, who approved it, and who changed it. (If the git commits have associated issues, you also know what project(s) or work items the topics were created in support of.)
- This detects and corrects configuration drift – where users might tweak Kafka configuration values in ways that might otherwise never be noticed.
- Automation can also deploy changes to a test or validation environment – before they are approved and deployed into a production environment.
- Having the specification of the Kafka cluster and all of the topics in a git repository means that the cluster can immediately be rebuilt from scratch if a disaster requires it.
Limitations:
- Requiring cluster administrator to review every change before it can be applied to the Kafka cluster is potentially a burdensome workload in environments with frequent topic changes.
- Requiring the cluster administrator to manually review every change depends on the administrator being able to foresee potential problems that a change could cause.
- Waiting for topic creation and modifications to be reviewed and approved will introduce a delay before topics can be available for application use.
- Restricting direct topic management to the Event Streams Topic Operator prevents the direct use of standard admin tools in the Kafka ecosystem.
In summary…
This approach is well-suited to production environments, where you are likely to prioritise the governance enabled by rigorous checks and controls.
Kubernetes Policies
Representing Kafka cluster configuration and all Kafka topics as separate Kubernetes custom resources also enables a policy-driven approach to managing your topics.
You can agree on limits that you want to apply to all Kafka topics, and implement them as validating policies that will prevent a topic being created that conflicts with a policy.
For example, perhaps you want to control the disk impact of the topics that individual application development teams create.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: kafka-topic-policies
spec:
validationFailureAction: Enforce
rules:
- name: max-topic-retention
validate:
message: This topic would exceed the maximum storage requirement allowed for this cluster
pattern:
spec:
config:
retention.bytes: <=50000000
match:
any:
- resources:
kinds:
- KafkaTopic
- name: max-partitions
validate:
message: This topic would exceed the maximum number of partitions allowed for this cluster
pattern:
spec:
partitions: <=50
match:
any:
- resources:
kinds:
- KafkaTopic
If you try to create a Kafka topic (either through the Event Streams web UI, or directly by creating a Kubernetes custom resource) the policy will prevent it, and display the message that you provide in the policy.
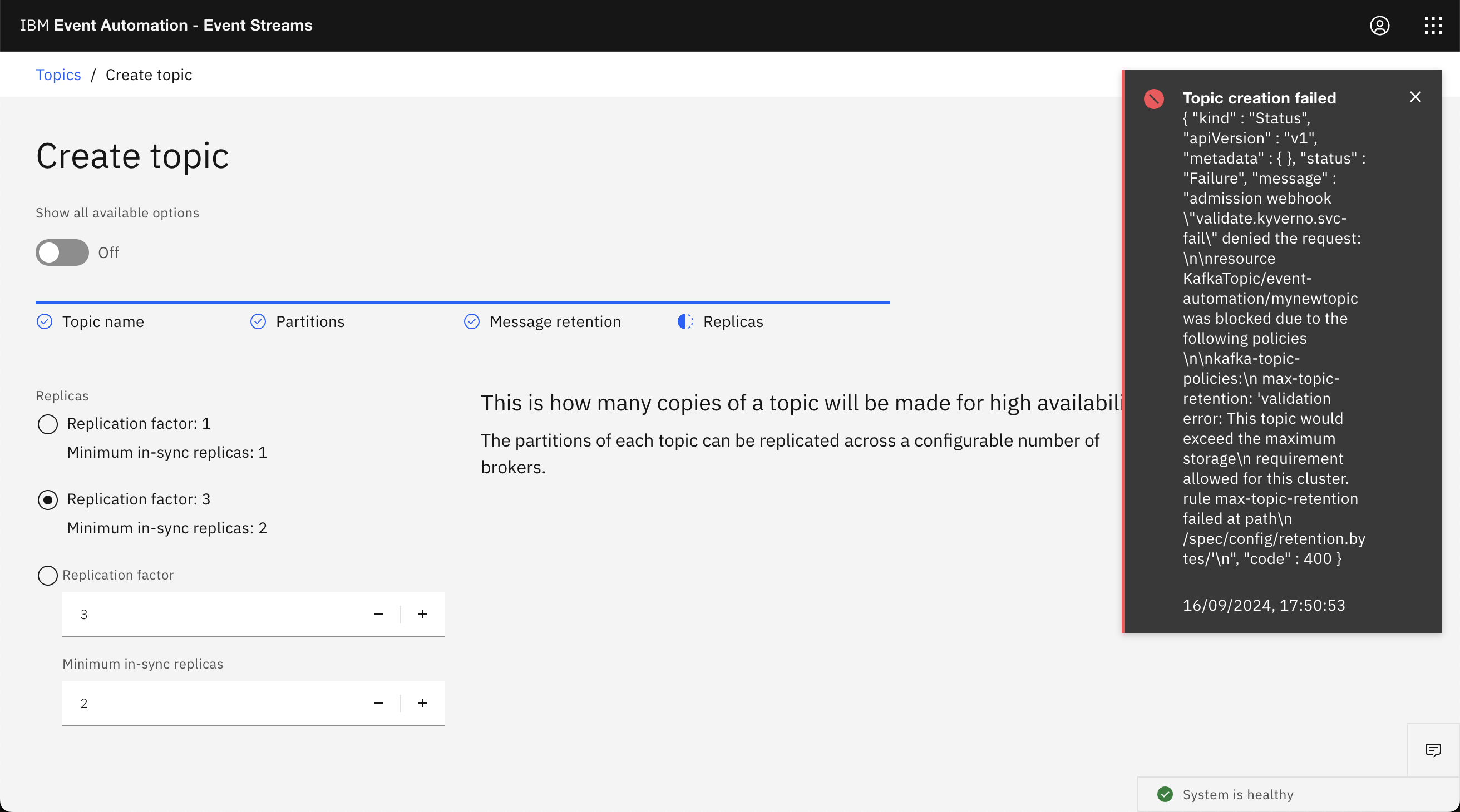
These can be used to apply your corporate best practices and conventions. Policies can be technical (e.g. topics should not allow very large messages, or topics should specify an explicit retention limit) or organisational (e.g. topics should be named consistently with the company naming convention, or topics should use the company’s preferred compression type, or topics must include contact information annotations).
Over time, these can evolve into a detailed set of policies that reflect your company adoption of Kafka.
The policy shown above was defined using Kyverno, but newer versions of Kubernetes natively support some of these capabilities using a Validating Admission Policy.
Benefits:
- Automating some of the checks for things that you want to control can catch problems that a human cluster administrator might miss in a manual review. This is particularly beneficial as the number of checks grows.
Limitations:
- As these policies are applied at the Kubernetes level, it depends on topics being managed entirely as Kubernetes custom resources, and will not be applied to topics created by Kafka admin clients outside of the Event Streams Topic Operator.
In summary...
This approach is well suited as being a supplement to the kinds of approaches described above.
For example, if you adopt a delegated authority approach, you can enforce some additional checks while leaving team administrators to otherwise manage topics for their own teams.
Thanks to Neeraj Laad and Graeme McRobert for contributing to this post.
Tags: apachekafka, eventstreams, ibmeventstreams, kafka
We have this (with vanilla Kafka). Though it gets more complicated when you have different teams consuming from your topics than publishing to it.
We use a mixture of delegated authority and GitOps as you described.
We have Terraform config in Git to control access by using naming conventions. These configs don’t change too often and a PR on that repo (for production) needs a Head of Engineering approval – this stops it becoming a big free for all. Test and dev environments anyone can approve.
The Terraform config also gives you a means to add permission to read from another team’s topic (Head of Engineering review should spot you doing something you shouldn’t be).
Then for creating topics every team has a provisioning service that runs in Kubernetes and is responsible for creating new topics. This service would only have permission to create topics under the naming convention of the team. This service follows the normal PR conventions of the team. In my team’s case it would need at least one other developer to approve the change. Having the provisioning service deploy alongside the other services that publish to the topics It creates means we can make sure the topic is provisioned before the services that publish to it are deployed (the deployment pipeline does the provisioning service first).
I came up with none of this, but it works pretty well. I should get someone to write about it.
P.S.
Hello!