A few technical details on how I’m implementing global load balancing to improve the availability of Machine Learning for Kids.
This wasn’t a great week for Machine Learning for Kids. I think the site was unavailable for a couple of days in total this week, spread across a few outages – the worst one lasting over twelve hours. I know I’ve lost some users as a result – a few teachers / coding group leaders did email me to say (not at all unreasonably) that they can’t use a tool that they can’t rely on.
I wrote in my last post that I would be making changes to prevent this sort of thing from happening again. Now that I’ve done it, I thought it’d be good to share a few details on how I did it.
(I should say that I owe a thanks to a ton of people at work who helped me with this. Times like this – when you need to do something new in a hurry – make me appreciate being able to get help from people across IBM in a hurry by asking a few questions in Slack!)
To start with, a recap of how the site was running before this weekend:
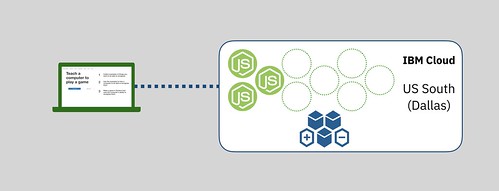
The site is implemented as a Node.js application. It was deployed into Cloud Foundry running in the US South (Dallas) region of IBM Cloud.
By default, there were three instances of the app running.
This improved reliability (if anything bad happened to cause one instance to crash, there would be two other instances available to keep handling requests without downtime).
It improved performance (requests were round-robined across the three instances, so they worked together to handle all the requests the site got).
It also made sure that I kept the implementation stateless, as I built everything assuming that consecutive requests might not go to the same instance.
I used an Auto Scaling service to add extra instances if things got busy. If the memory usage stayed above 80% for longer than a blip, it would start up an extra instance of the Node.js app to help share the load. And it was configured to keep adding instances if the site got even busier still.
And when things quietened down, and the memory usage dropped and stayed below 30%, the service would kill the extra instances, scaling it down as low as three.
That’s how I’d been running the site until now. It meant that the site handled spikes and busy periods (most recently Scratch Day, when the app was being used by kids all around the world).
But… it meant that went things went wrong in the Dallas region, my site dropped off the Internet.
It was time for the site to grow up a little.
Now the deployment looks like this:
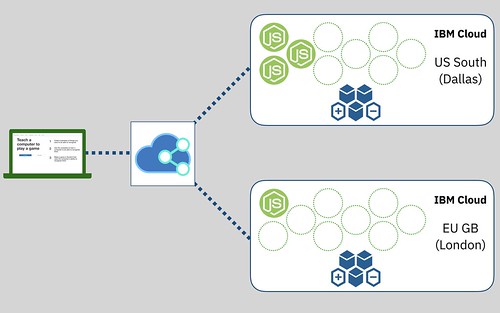
It’s still a multi-instance Node.js application, deployed to Cloud Foundry in IBM Cloud.
But now it’s deployed to two regions – the US South (Dallas) region and the EU GB (London) region.
And I’ve got a load balancer in front, directing the requests.
The US South instance is still going to be the primary instance and, if all is well, serve all of the API requests. When things get busy, there is still the Auto Scaling service to spin up additional instances of the Node.js app in the US South cloud.
But when things go wrong, if the US South instances can’t be contacted, then the load balancer will start sending requests to the EU GB instance instead. That is only running a single instance normally, as when things are running smoothly, it’ll be idle. But the Auto Scaling service is running there, too – so it can quickly increase the number of instances to match the needs of the current workload.
That first layer, in front of the two IBM Cloud regions, is also providing a cache for all the static resources. This means the Node.js applications won’t have to do much work to serve the HTML, CSS, JavaScript and images that make up the training tool and Scratch. I’m not sure I really needed that, as the site generally runs with pretty low CPU and memory even when busy, but it was trivial to add, so I added it anyway.
That’s the big picture summary… so a few quick pointers for how I set it up.
I’m using IBM’s Cloud Internet Services. The first step was creating one of those services from the IBM Cloud Catalog. That gave me a couple of addresses of nameservers I could use.
I bought the machinelearningforkids.co.uk domain from eukhost, so I needed to go to my admin page in eukhost and update the nameservers with those two new cloud.ibm.com addresses.

I deployed the Node.js applications to the two regions – to the Dallas and London regions.
I gave the US South deployment the following routes:
machinelearningforkids.co.uk
www.machinelearningforkids.co.uk
machinelearningforkids-ussouth.mybluemix.net

I gave the EU GB deployment the following routes:
machinelearningforkids.co.uk
www.machinelearningforkids.co.uk
machinelearningforkids-eugb.eu-gb.mybluemix.net

Both deployments have the normal/externally-visible site routes, and they both have a region-specific “internal” route.
Note that this means I needed to add the custom domain and it’s SSL cert to both regions.

I also added the certificate to the Cloud Internet Services instance, and set the TLS setting to “End to end (flexible)”

The setup process in Cloud Internet Services looks like this.
I defined a “Health Check” – based on GET request to an API endpoint that doesn’t do anything other than check the application is responsive.

I created a couple of “Origin Pools” – one for the US, and one for Europe.

The US origin pool points at the region-specific route for the US application deployment:
machinelearningforkids-ussouth.mybluemix.net
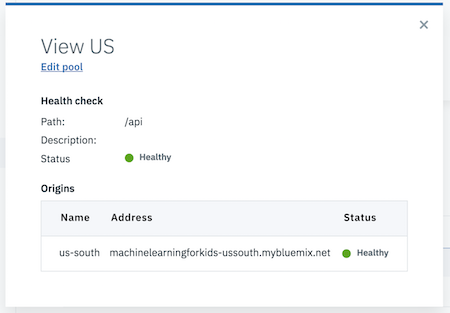
The Europe origin pool points at the region-specific route for the UK application deployment:
machinelearningforkids-eugb.eu-gb.mybluemix.net

I defined the “Load Balancer”, pointing to both of these origin pools. The order is defined to give priority to the US origin pool.
And the hostname is set to “www“.

Finally, I created a single DNS record.
A CNAME record with the name “@” and the value “www.machinelearningforkids.co.uk“. This points all records at the www load balancer.

As I said, I also enabled caching. It doesn’t really help with reliability, but was simple enough to turn on.
I just added a couple of Page Rules, identifying URLs where resources are safe to cache. I’ve long had all the static resources served at addresses starting https://machinelearningforkids.co.uk/static/* and every build adds a unique build timestamp in the resource paths, so it’s safe to cache everything under here forever.

That’s pretty much everything.
To sum it all up:

(1)
The user’s web browser goes to https://machinelearningforkids.co.uk
The nameservers for this address are now delegated to IBM CIS.
(2)
Any requests for static resources (CSS, images, JavaScript, HTML components) are returned from the CIS cache directly
API requests need to go to a Node.js application. The DNS routing directs the request to the www load balancer
(3)
The www load balancer uses the health check I defined to poll the two origin pools regularly.
If it knows that the US South deployment is healthy and responsive, it directs the request to machinelearningforkids-ussouth.mybluemix.net
(4)
The US South cloud is registered to handle requests to machinelearningforkids-ussouth.mybluemix.net because that route is in the application’s deployment manifest.yml file
(5)
Cloud Foundry directs the request to one of the Node.js app instances
(6)
The Auto Scaling service monitors the memory usage of all of the Node.js app instances, adding or removing instances to keep the memory within thresholds that I’ve set.
This means the site is still going to be able to handle spikes and busy periods. And it should now remain accessible in the event of regional outages.
Tags: mlforkids-tech