A few months ago, I mentioned that I was starting a new project. In this post, I’ll explain what we’ve been working on and what we’re trying to achieve with it.
The project was to build something new: a self-serve web-based tool to enable training the IBM Watson Retrieve and Rank service.
Earlier today, we released a first version of the tool. Now it’s finally out there, I can share what I’ve been working on!
My video walkthrough of the IBM Watson Retrieve and Rank tool
Retrieve and Rank is a service for developers who want to be able to include relevant responses to questions in their apps, where those answers are found in some large collection of documents.
As the name suggests, there are two main parts:
retrieve – a Solr-based search component, that can retrieve a list of possible matches from your documents given a query
rank – a machine learning component that learns how to rank those matches, to sort them so that the best possible match is moved to the top of the list
![]()
As a machine learning based solution, this means that to use it, a developer will need to train it. It will learn from the training they give it how it should handle their set of documents and the sorts of queries that their app will get.
For the last few months, my team has been creating a tool to help them do that.

Part of this has just been the mechanics of driving the service: creating and managing Solr clusters and collections, extracting the contents of documents in a variety of formats and adding them to the Solr index, viewing and managing documents in the corpus, creating and managing Retrieve and Rank rankers, and so on.
What I’m most proud of though, and where we’ve put a huge amount of effort, is the work we’ve done to drive the training through the tool.
It’s not just a raw data entry tool for collecting training data. We’ve tried to bake into the tool a methodology for training the service.
The tool directs the training. It looks at what the user has done so far, and tells them explicitly what would be the best thing for them to do next.
It prioritises questions to select for training using a variety of techniques. Initially this focuses on an analysis of words used in the questions. As more training is completed, the selection also includes an analysis of which questions are performing well and which aren’t.
The tool also has a variety of strategies and techniques for how the user can do training, which it switches the user between dynamically. This is also based on a continuous background analysis of the growing ground truth, how training is going, the results of tests created and run automatically in the background, and so on.
We’ve created a tool to help developers train the service as quickly and efficiently as possible, without them needing a background or expertise in machine learning techniques. We do this by guiding them step by step through a process based on best practices, a process that is automatically tuned and adapted based on their content and how their training is going.
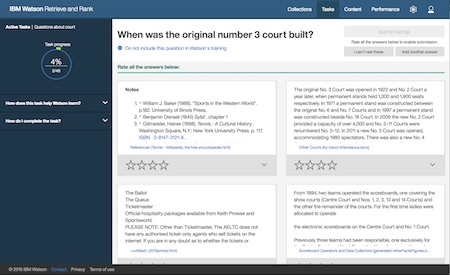
There’s a lot I didn’t get a chance to include in our initial release. It is absolutely an MVP and a lot of the things I would’ve liked us to add didn’t make it in the effort for a small team to get a product ready for release in just 90 days.
But we’ve made a solid start. And I hope our approach will enable developers to build some great things with the Retrieve and Rank service.
Excellent overview Dale! We look forward to watching and helping this evolve!
This is indeed an very good encapsulation. Is there any way we can club Alchemy Language and this tool with a front end using NLC to create a dynamic search tool bar