I gave a presentation about What are we missing in AsyncAPI? in the AsyncAPI track at apidays in London last week. My aim for the talk was to start a discussion on where there are opportunities to enhance and extend AsyncAPI.

The talk wasn’t recorded, so I’ll use this post to describe what I talked about.

I use AsyncAPI to document and describe Kafka applications. That was the (admittedly narrow!) perspective I brought. I suspect that a lot of the specific examples I raised have equivalents in other protocols. Even where they don’t, I was trying to make a protocol-agnostic point that we need to think about the different types of people who work in event driven systems and what information they need for their roles.

I started with something of a mea culpa.

One of the strengths that AsyncAPI inherits from OpenAPI is that it is extensible, through vendor extensions. If there is something that you want to capture that doesn’t have a dedicated place in the AsyncAPI spec, you can just add your own custom values.
There is nothing holding you back from documenting anything you want.

One of the weaknesses of AsyncAPI is vendor extensions. By not restricting what you can put in your own AsyncAPI documents, it is too easy to put off contributing your new ideas back into the spec.
The ideas I covered in this talk are things I’ve needed to store for a long time. Some examples in this session were thing I have used vendor extensions to record for over 18 months. Circling back and trying to write them up as a more general purpose proposal has been lurking at the bottom of my todo list forever, but never made it to the top.

This presentation was, in part, a bit of an apology for that failing.
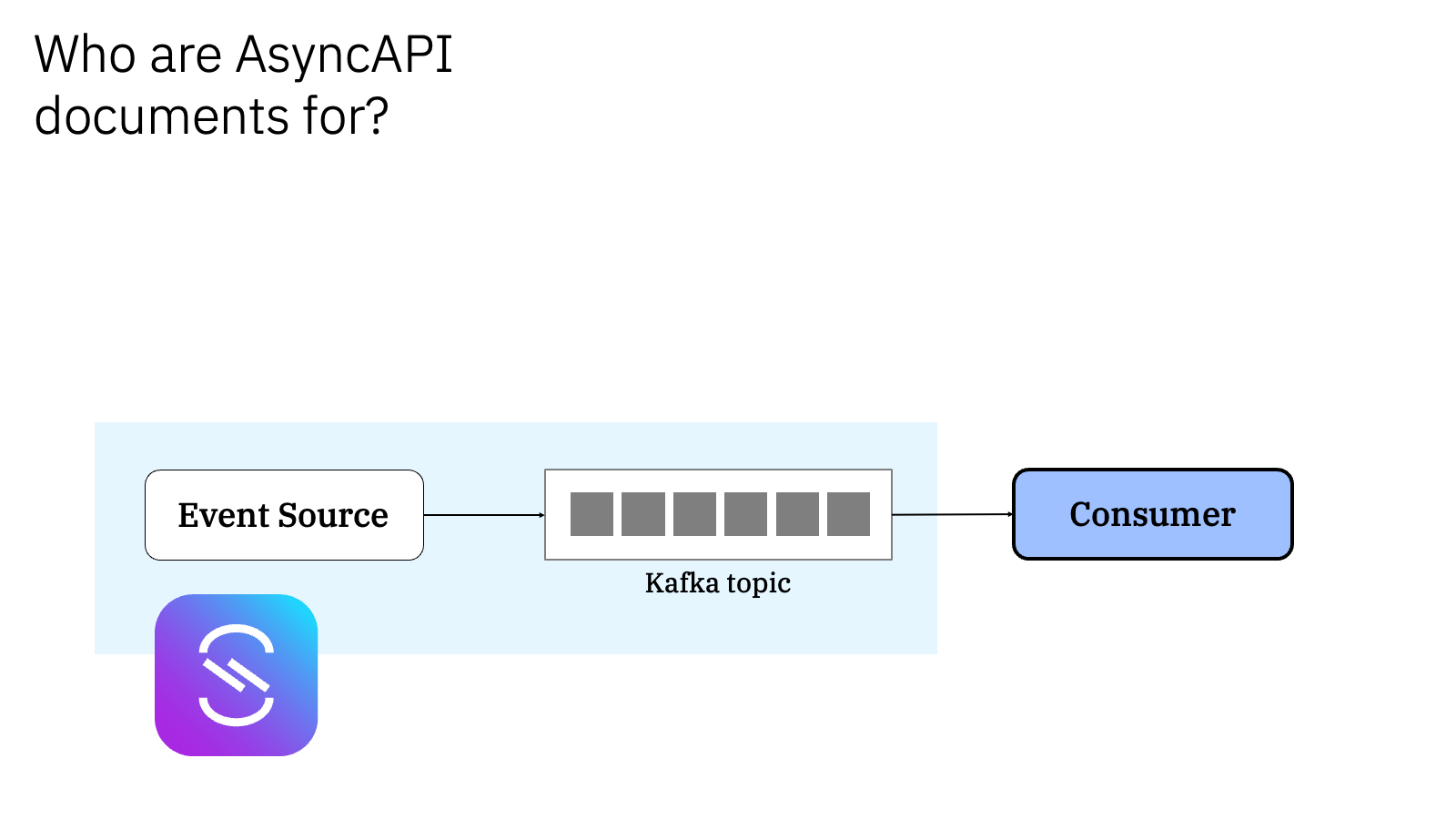
There are lots of things you can use an AsyncAPI document to describe.
As my apidays session was only short, rather than try to rush through an exhaustive list, I instead scoped my talk to just a single scenario and used this as an example of the sort of approach I think would be helpful.
I chose AsyncAPI documents written by the owner of an event source (e.g. connector or application that emits events) that produces events to a Kafka topic.
I used this as an example to look at what someone responsible for a Consumer (an application that will consume these events) needs to know, and illustrate how they would benefit if they could find all of that in an AsyncAPI document.
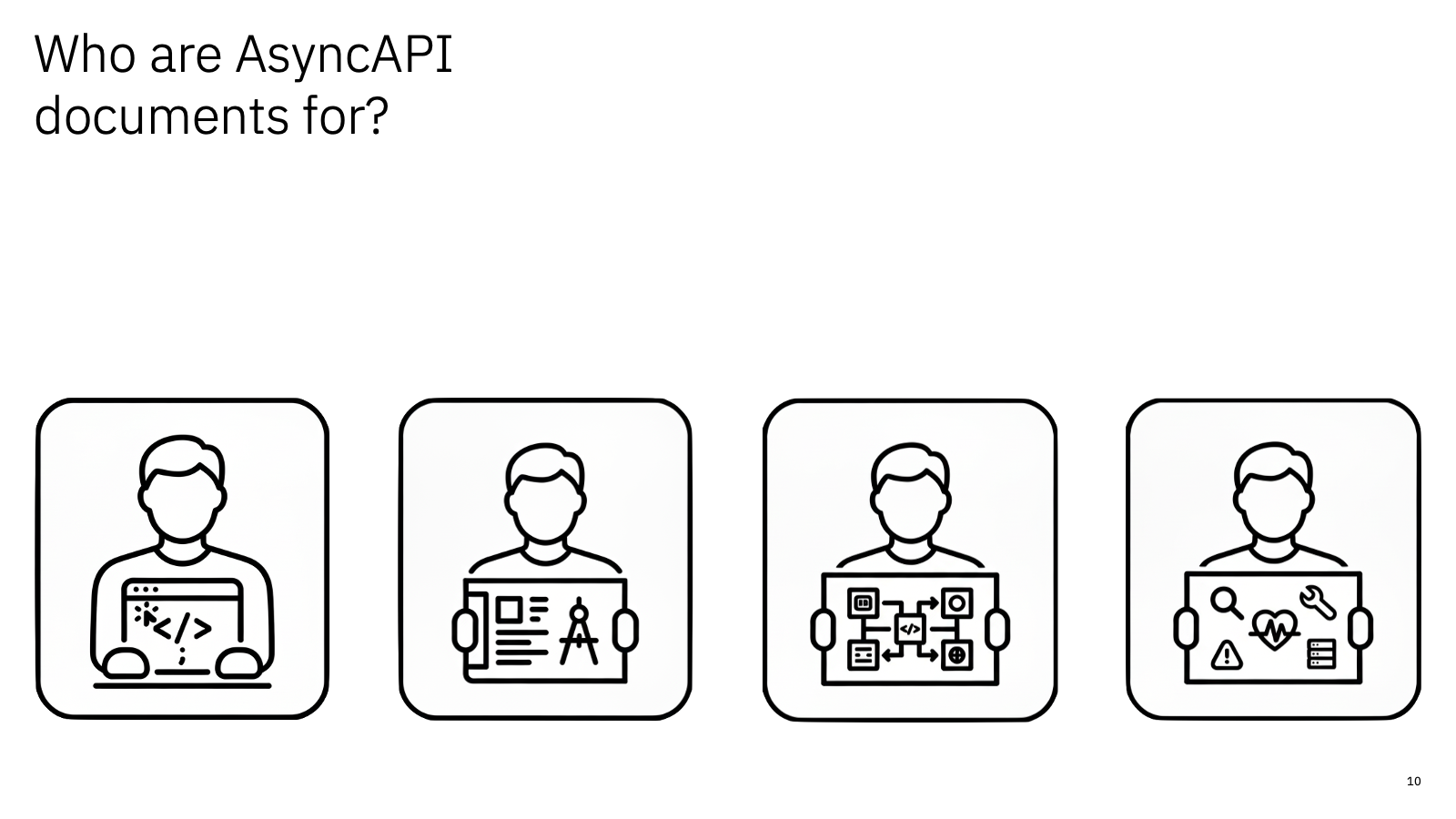
I chose four example personas, and looked at what someone in each of these roles might need in an AsyncAPI document:
- developer
Someone coding an application, or configuring a tool.
An AsyncAPI document should tell them how they need to use the Kafka API to make use of the event stream - senior developer / application architect
Someone responsible for the design of application
An AsyncAPI document should help inform the design decisions that they need to make - solutions architect
Someone responsible for the design and architecture of an overall solution, spanning multiple components or applications.
An AsyncAPI document should help inform the design decisions that they need to make - operations
Someone responsible for deploying, operating and monitoring the application.
An AsyncAPI document should help inform the scaling decisions that they make and the sorts of monitoring they need to do
I started with the developer.
Someone who is creating a new application needs to make decisions about how to use the Kafka API. Someone who is configuring an existing tool or connector needs to make decisions how to configure it.
Many of these decisions need to be made based on a knowledge of the stream of events that their application or tool is consuming. An AsyncAPI document should be a good place for them to find this.
The use of transactions by the event source is a good example of this.
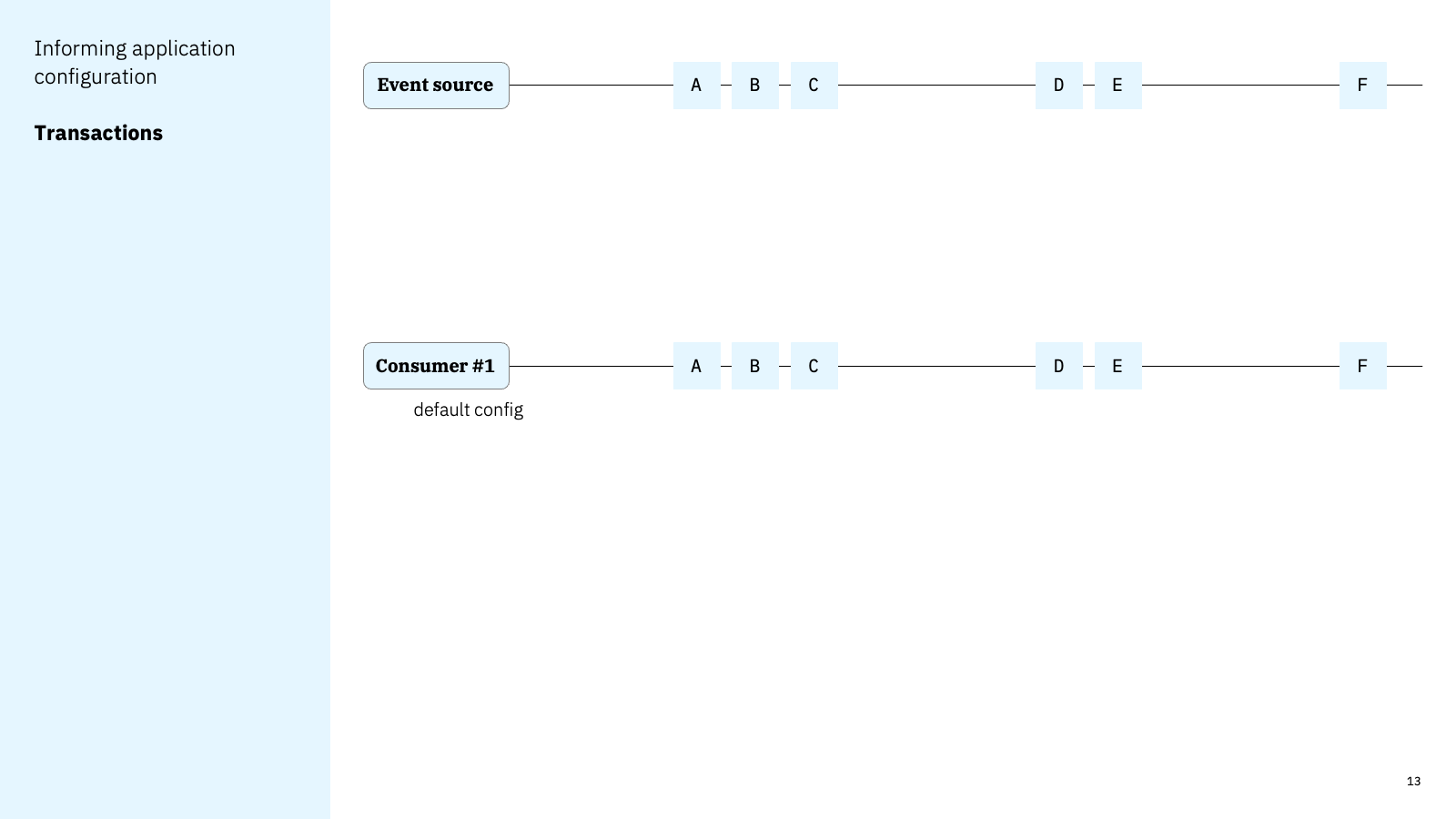
Consider this simple example. An event source produces events A, B, C, D, E, F.
The consumer using default config can expect to receive all of those events, at roughly the same time they are produced by the event source.

But if the event source is using transactions, then the consumer needs to choose which events they want to receive.
With a default configuration, they’ll still get all of the events, even those events that were in transactions that were aborted.
If they modify the configuration, they can get only events in transactions that are committed, but this introduces additional latency because of the need to wait for the transaction to be committed.
This is a critical difference. It’s hard to think of anything more important than which events a consumer will get and when they will get them. An application developer shouldn’t have to guess whether they need to make this decision. This is exactly the sort of thing that an AsyncAPI document should tell them.
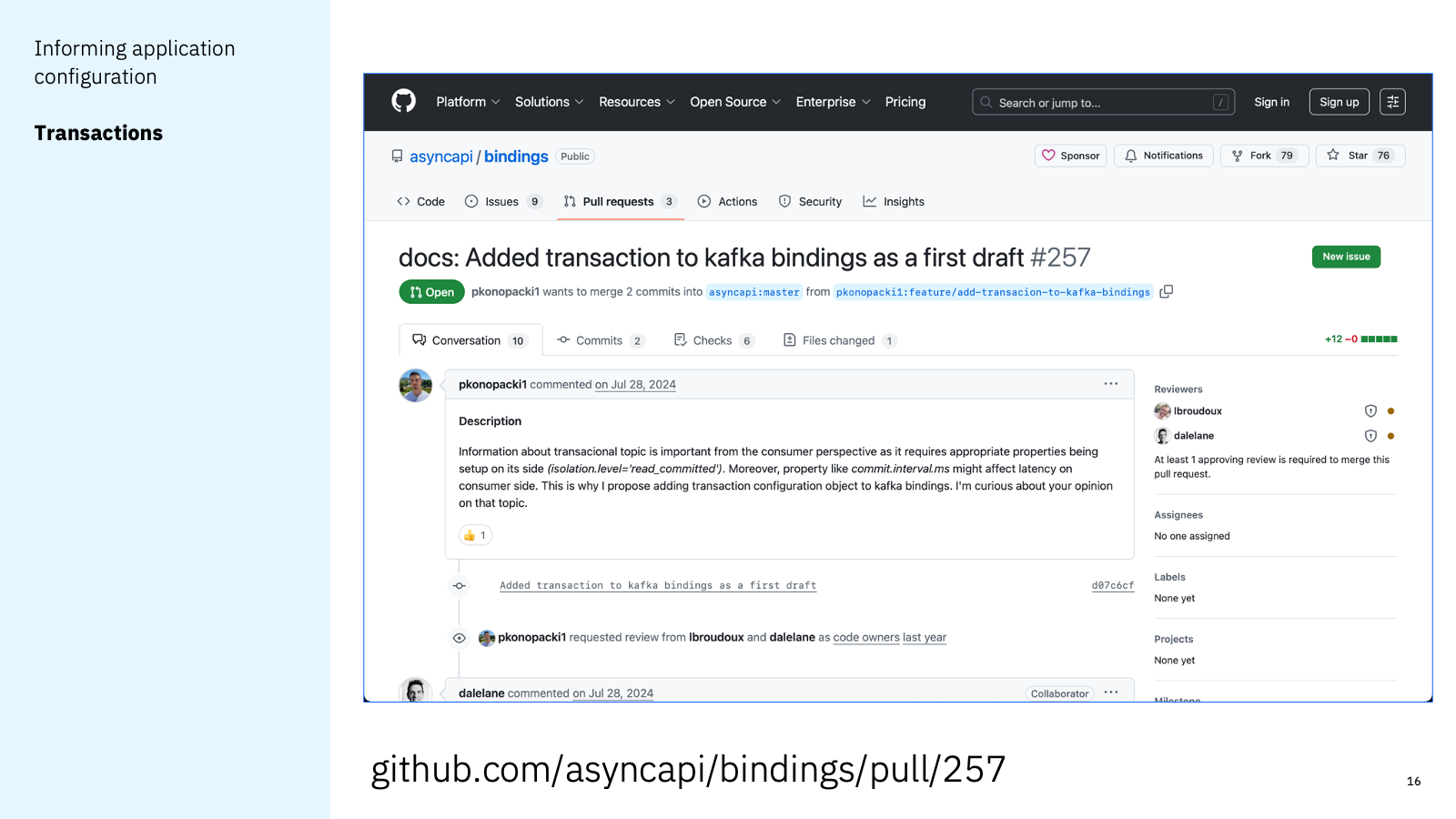
I’m not the only person to spot this. There is a (too-long overlooked) pull request making this same observation.
(Again… mea culpa.)

Time is an important part of event stream processing.
Our applications perform stateful, time-based processing of event streams.
How many times did an event occur in a the last five minutes?
How many orders were placed an hour?
How many times did event X occur within 30 minutes of event Y?
How soon after event A did event B occur?
This sort of processing starts with needing to know what you should use as the time for each event.
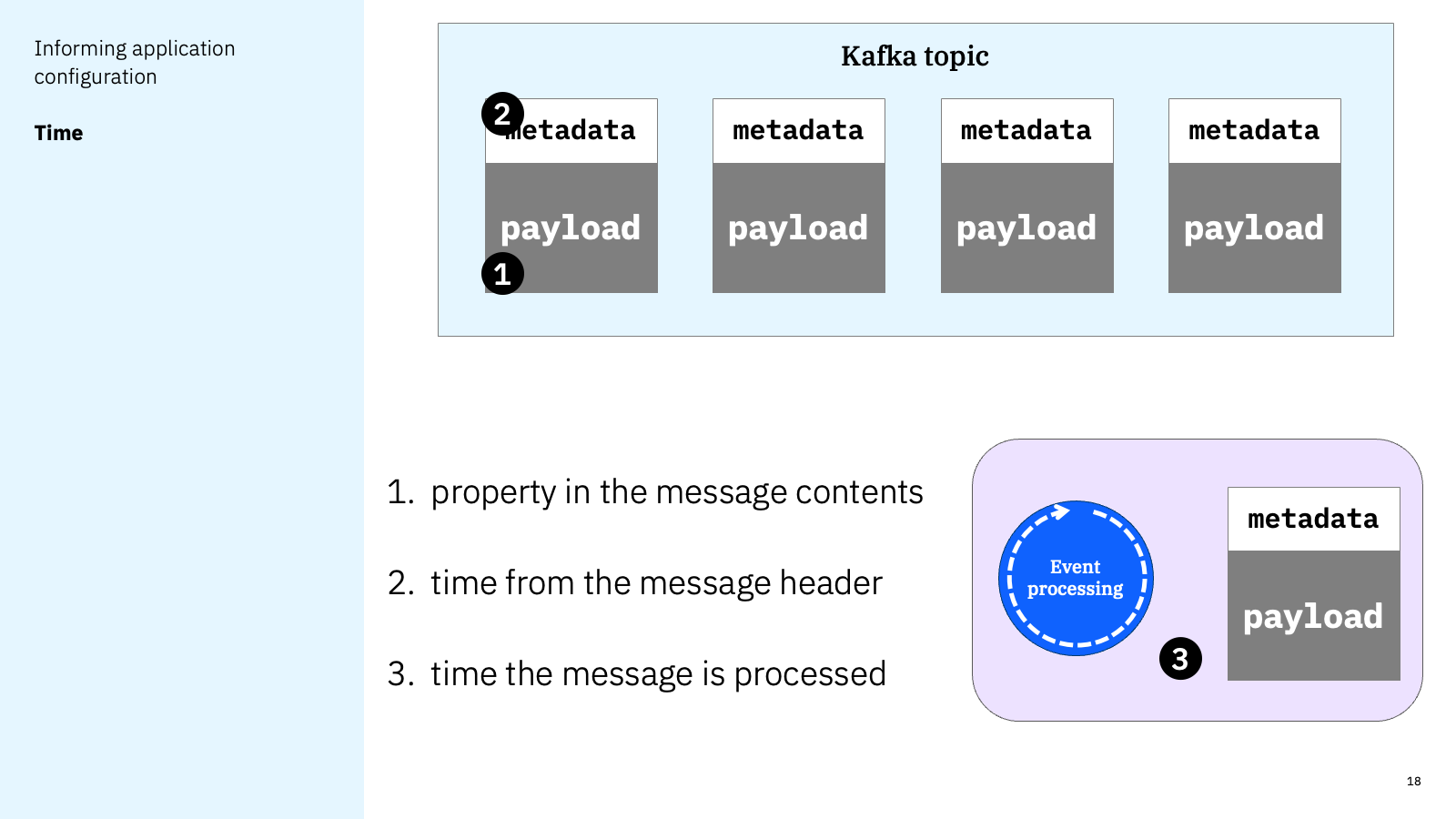
There are multiple places where a timestamp can be found in a Kafka event.
There is a timestamp in the metadata for a Kafka event – either set explicitly by the event source application, or defaulted to the time that it produced the event. This is a common approach if the event is being produced directly to the Kafka topic by the system that is emitting the event.
A more useful timestamp could be contained in the event payload. This is more common if there is some indirection between the actual event and something being produced to Kafka – such as event being recorded in a database, with a connector responding to that database row by emitting an event.
It’s not uncommon for an event payload to contain multiple timestamps. For example, an event about an order cancellation might contain the timestamp when the customer cancelled the order, as well as the timestamp for when the order was placed. One of these might contain the canonical timestamp for the event.
A developer needs to know what they should use as the canonical source of time for each event. This could be identified in an AsyncAPI document.

Related to time is event ordering.
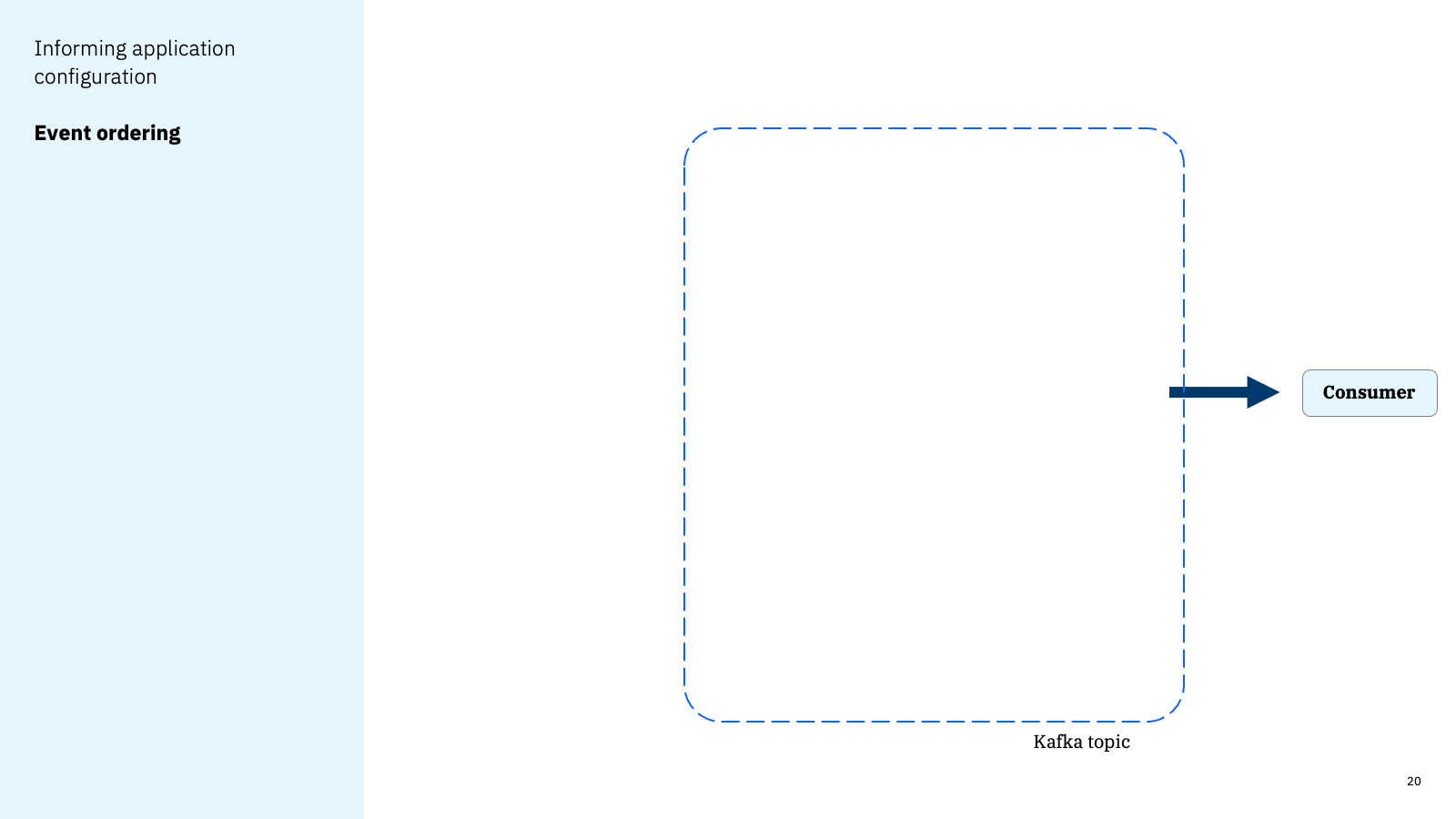
A developer can conceptually think of their consumer as receiving events from “a topic”.
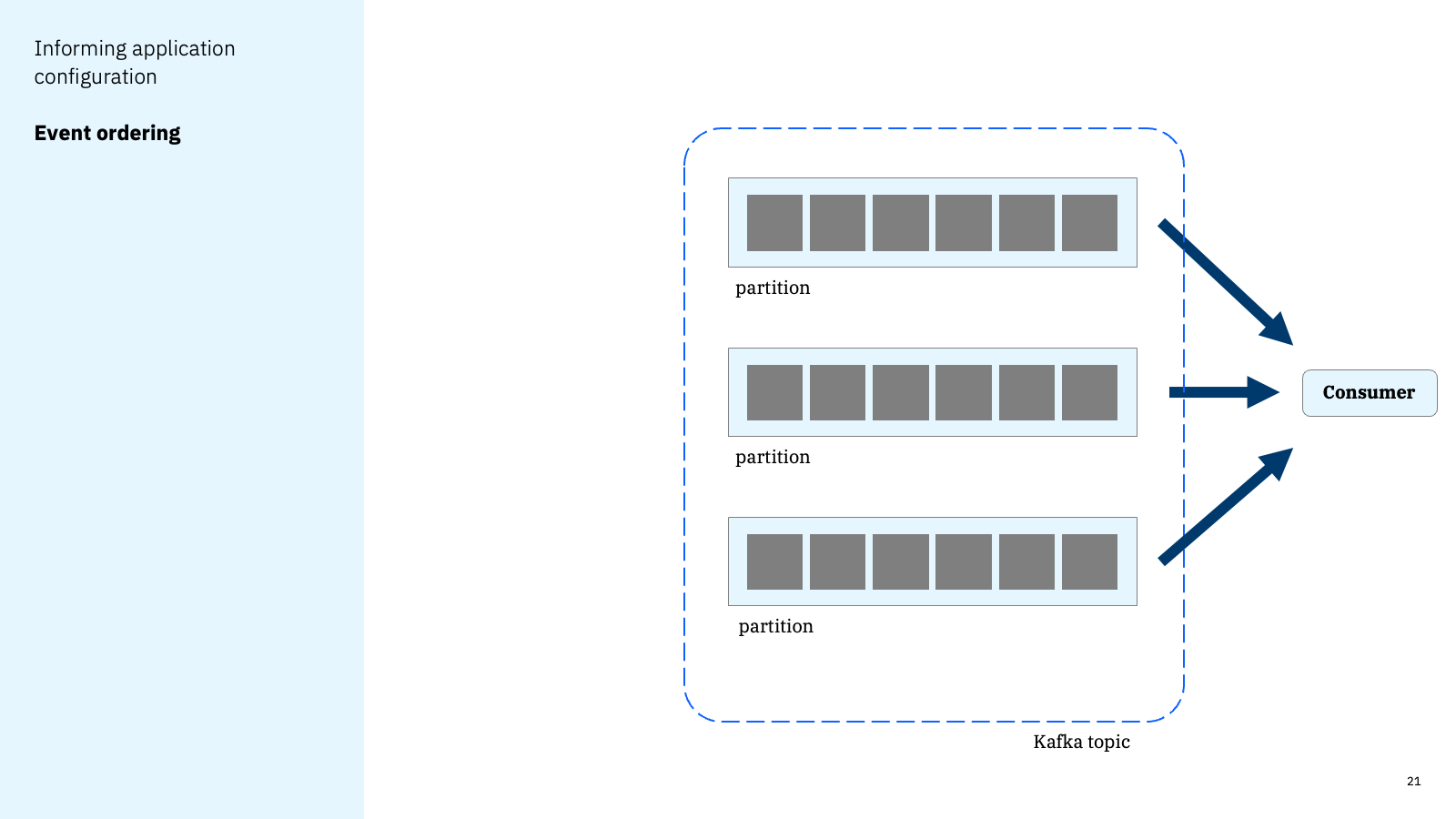
But in reality, these events likely come from multiple topic partitions – introducing a race condition for when events are received from each partition. This impacts the order that events are received.
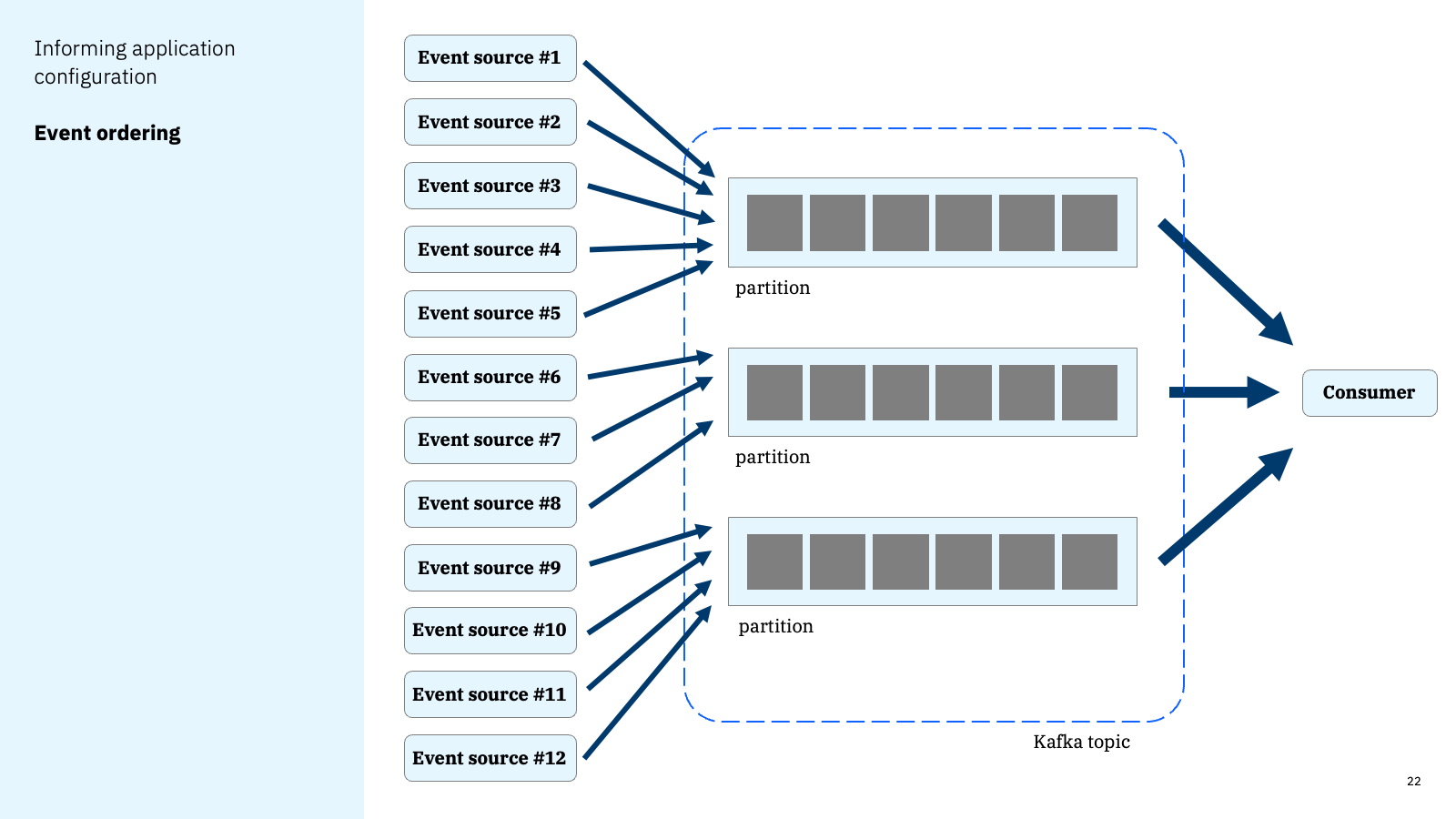
When events are being produced by multiple event source applications, this has a further impact.
Producers to the same topic, such as sensors, may emit events at different rates. They could buffer or batch events before sending them.
Produces could encounter errors, and need to retry sending events.
Producers can lose network connectivity, then send their events when their connection is restored.
Different producer applications could be impacted by different network latencies or other application performance issues which could impact when their events are produced.
And so on.
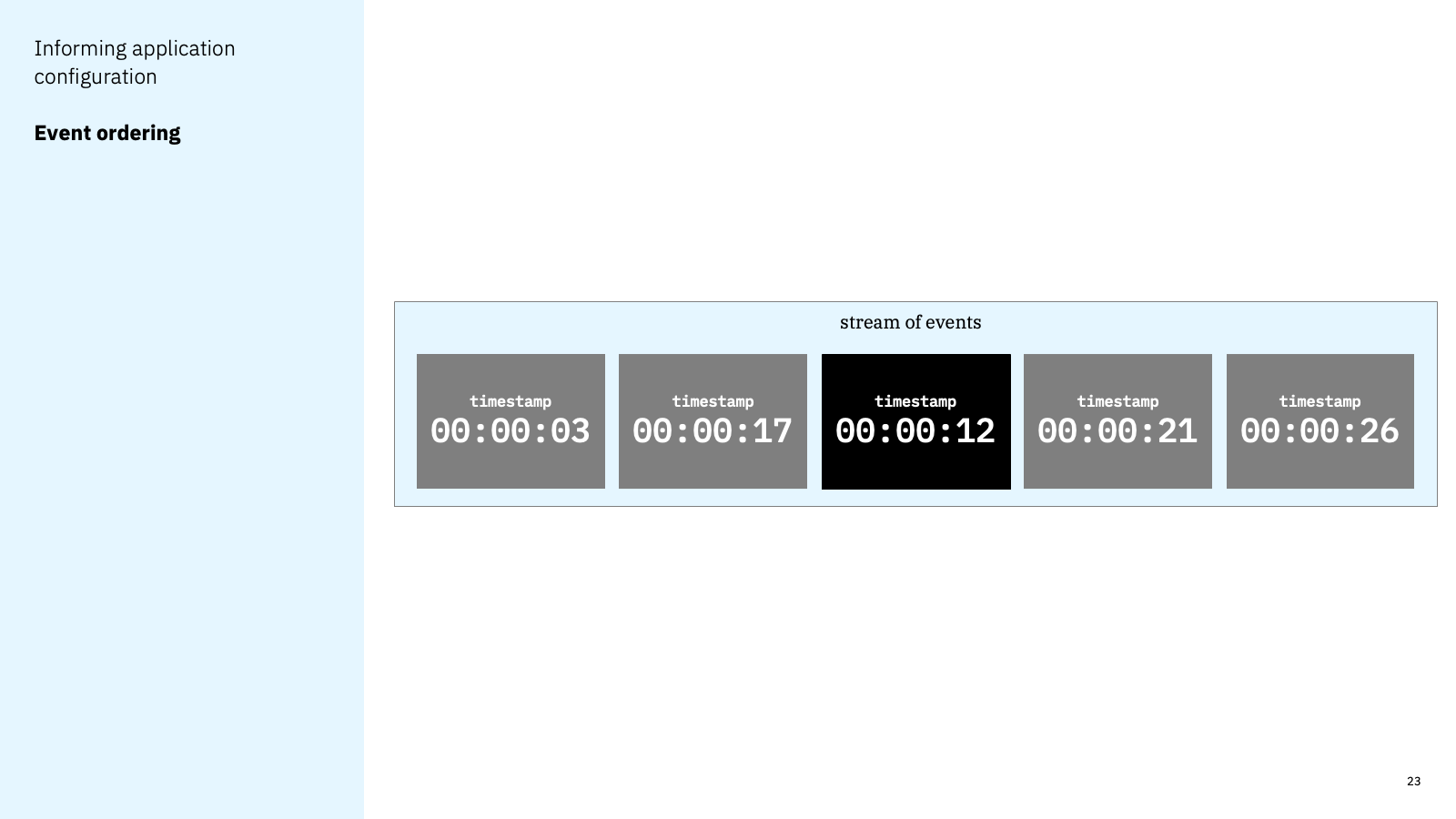
For all of these reasons, and several more, it is not unusual for a consumer to receive an event out of sequence, in relation to the timestamp for the events.
This doesn’t need to be a problem. A developer can handle this relatively easily. Many stream processing frameworks have a mechanism for handling this. I used Kafka Streams and Apache Flink to give specific examples, but other application frameworks have similar capabilities. A developer can simply configure or code their application to wait for late events to arrive before emitting results, so that even the events that arrive out of sequence are still included.
But the developer needs to know to configure that capability. And they need to know how long their consumer should wait for late events. Waiting too long introduces an unnecessary latency. Not waiting long enough means that some late events will still be missed.
This would be a great thing for developers to find in the AsyncAPI document.
Next, I talked about a senior developer or application architect.
Someone who is responsible for the design of application needs to make decisions that will be impacted by the behaviour of the stream of events the application is consuming. The AsyncAPI document should be a good place for them to find useful information, too.

Documenting individual events in isolation isn’t sufficient to enable someone to design an application to consume those events.
For example, the delivery assurance characteristics of the topic defines key requirements for the consumer.

For example, if the event source can only offer an at least once level of delivery assurance, then the consumer application may need to be designed to be idempotent. Or it could keep track of what it has already processed to avoid emitting duplicates.
If the event source can only offer a best effort level of delivery assurance (and the consumer application is dependent on deriving state from a sequence of events) it will need to be resilient to missing events.
It is not possible to reliably design an efficient application to consume the stream of events without knowing this, which makes it a useful characteristic to capture in an AsyncAPI document.

Part of designing an enterprise application is planning for how it will adapt and change over time. A major consideration is how the application will respond to future changes in data schemas. If your application is consuming events from a Kafka topic that you don’t own or control, you need to know what changes you should prepare your application for.

As this was a relatively short session, I tried to avoid diving too deep into the nuances of backward and forward compatible schema evolutions. My broader point was that the designer of an application needs to understand what approach the event source owner intends to take towards schema versioning.
In the best case, it helps them to design their application accordingly.
In the worst case, it could mean that the type of application they want to create may not be easily supported by this particular topic. For example, if you are creating an analytics application that requires continued access to historical events, then you need to know if the event source owner doesn’t commit to follow a backward compatible evolution.
An AsyncAPI document that only describes the schema of the events today is a good start, but not sufficient to help an architect effectively design a viable long-term application.

A lot of these application design factors can be summed up as the event source owner being explicit about the behaviour of their application, to help the architect of a new consumer application understand the requirements this introduces on their application.
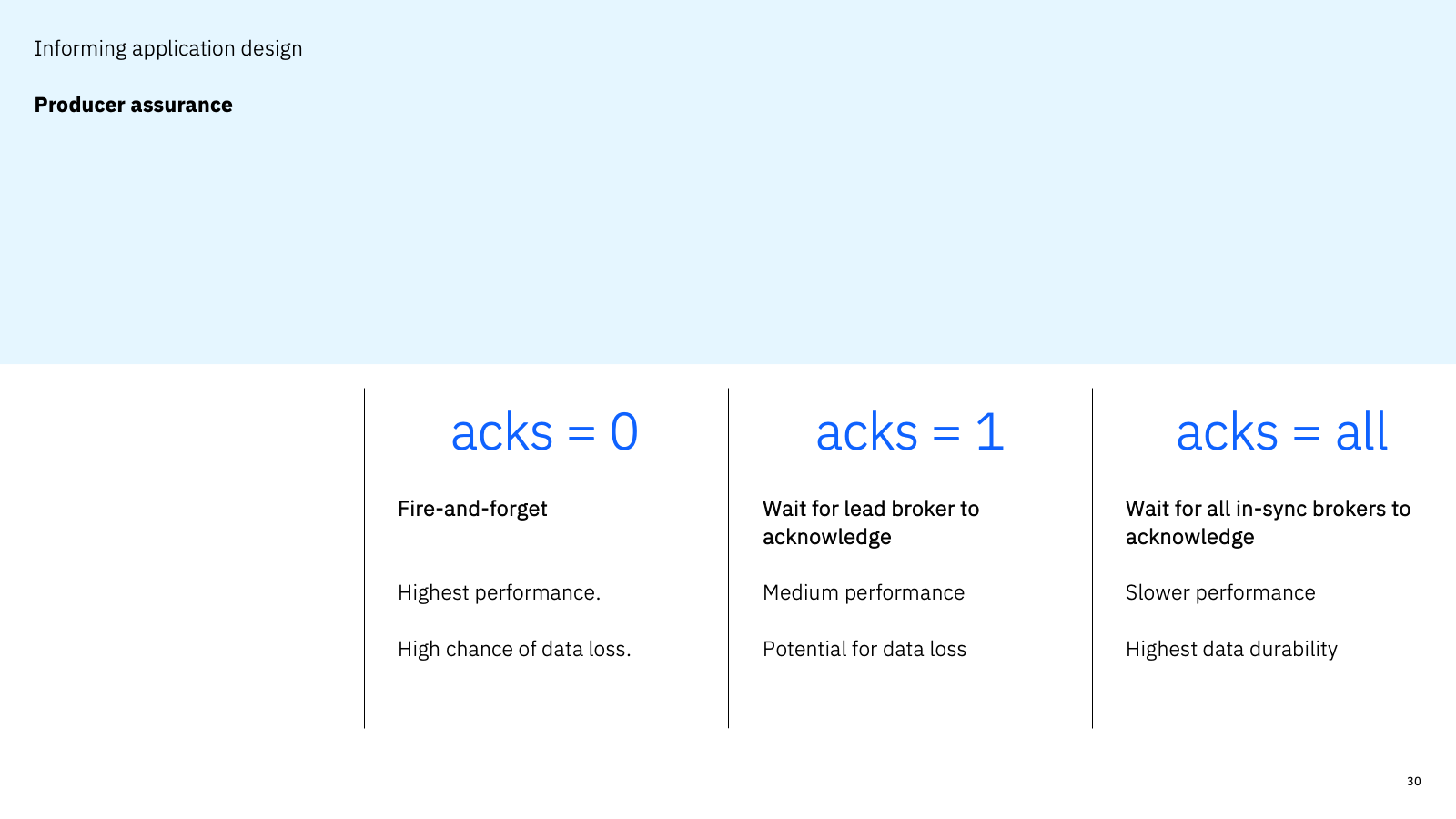
Another example of this was understanding the approach that the event source takes to producer assurance.
If the producer is using Kafka in a fire-and-forget way, then consumer applications should be designed to tolerate missing data.
There are subtleties to this. For example, if the producer is waiting for acknowledgements only from topic leaders, there is a chance that events that are consumed now might not still be available if the consumer tries to go back and re-consume the same event later. Some application types that depend on a consistent immutable history would need additional design considerations to work with such a topic.

There are a range of considerations that could perhaps be inferred from the message payload schema we can already describe in an AsyncAPI document. In this session, I argued that it could still be useful to have a way to call these out explicitly.

For example, an event source that emits full record events can enable stateless consumers for many types of processing.
But if the event source emits events that only contain the properties that have changed since the last event, this introduces a requirement for consumer applications to retain data from previous events.
If we had a way to clearly characterise this in an AsyncAPI document, it would make any persistence requirements obvious to an application designer.

Another example, particularly common with change-data-capture event sources, is the level of normalisation from the data source that the changes are coming from. An application processing change events from a normalised source will likely need some supplemental way to look up the meaning of the keys and IDs contained in the events that it processes.
An AsyncAPI document could not only highlight this requirement on consuming applications, but actually provide detailed guidance on how and where to look up this essential context.

Non-functional requirements have an impact in shaping the design of a new application, and we could use AsyncAPI documents to communicate these effectively to application architects.
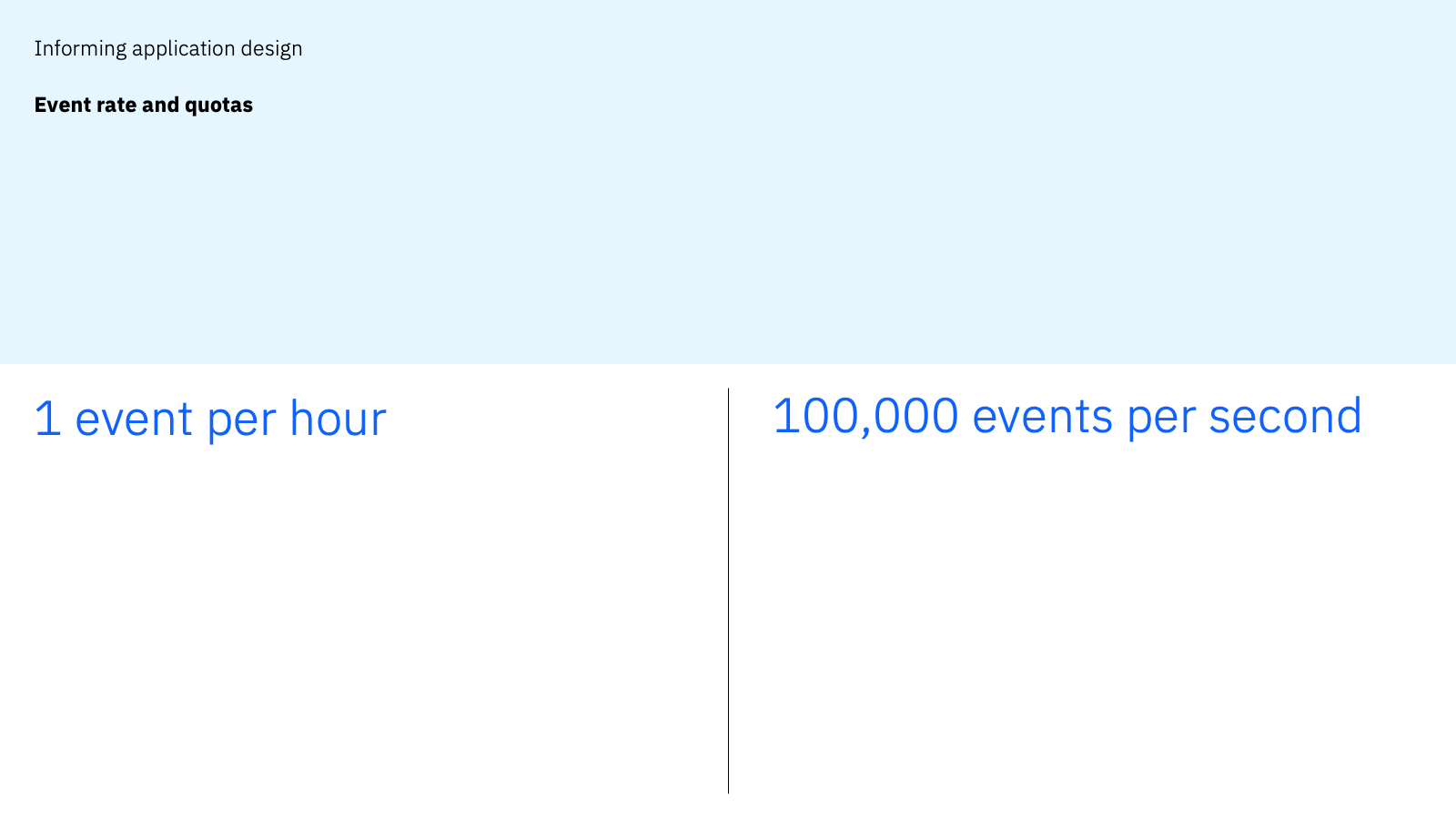
For example, the way you would design an application to process a 100 byte event that is emitted once-per-hour would be completely different to how you would design an application that receives 100,000 one-megabyte events per second.
The event size can possibly be inferred from an understanding of the payload schema, but if we only use AsyncAPI documents to describe an individual event in isolation, instead of the characteristics of the event stream, we make it harder for the application designer to fully understand their requirements.
(Quotas is perhaps less of a factor here as I was focusing on documentation requirements for a consuming application. I did briefly touch on the fact that someone running a producing application would more likely need to know what constraints there are on how much data they are allowed to produce and how quickly. If the AsyncAPI document for a topic your application is producing to identifies a particularly strict limit being enforced then this would impact the design of an application that needs to produce data with a high throughput. But this was a bit of a tangent…)
I next took a step back to look at how AsyncAPI documents could help inform design decisions for solutions – decisions that are perhaps broader than a single application.

I had discussed previously that understanding what to use as the canonical timestamp for events is particularly common when events go through multiple hops from something happening to a message being produced to a Kafka topic. For example, think about a source connector that is emitting events stored by an external system that records things that happen.
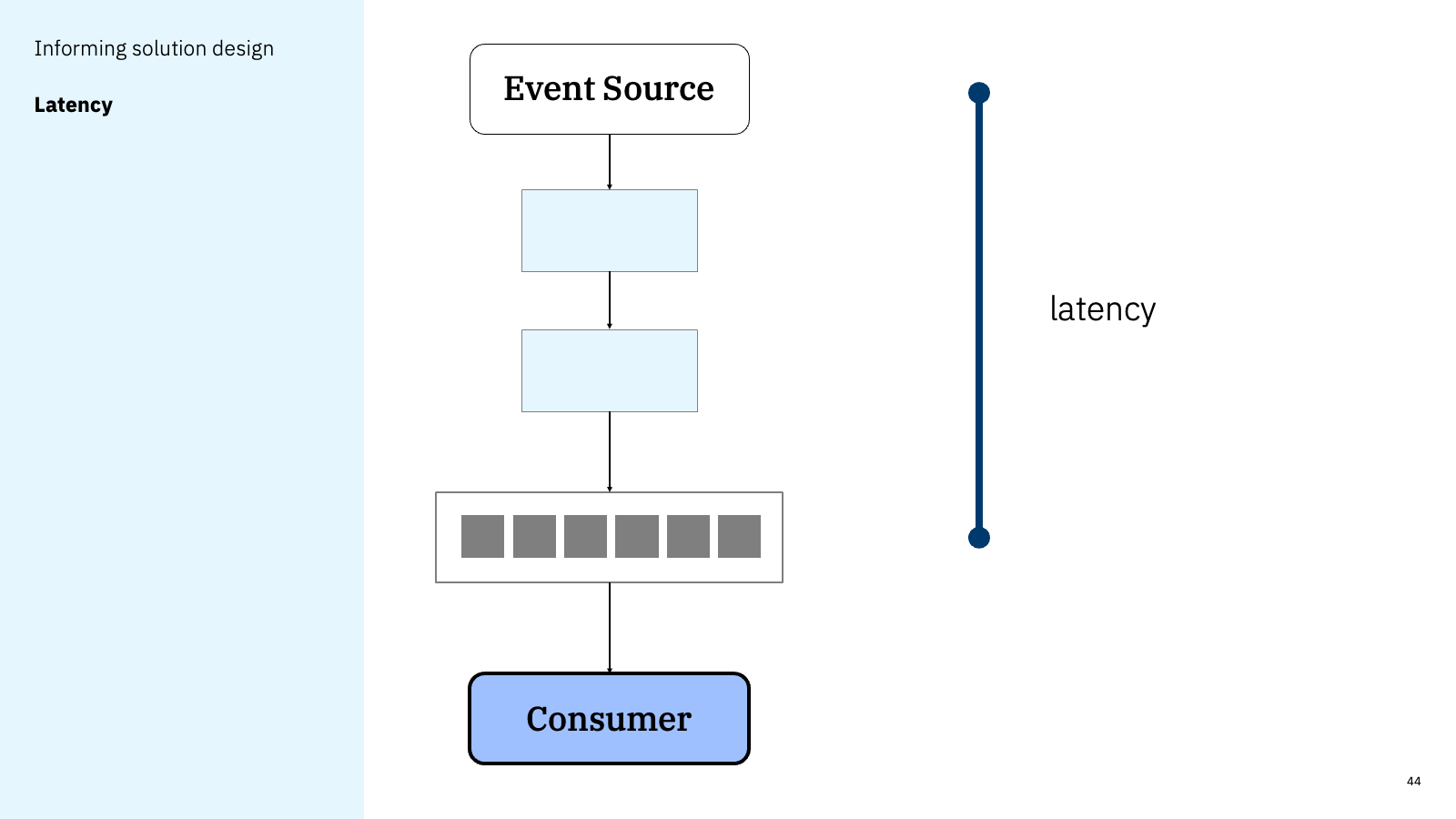
Another aspect of this is understanding the latency of such event sources. If you are designing a solution that needs to takes an action in response to something happening within a particular time constraint, you cannot know the viability of this without first understanding the latency of the initiating event and the message being available on the Kafka topic.
This is perhaps only likely to be useful in very high-performance, low-latency environments. In such circumstances, we would benefit from a way of documenting the latency objectives that the event source owner is working towards.

It is increasingly common for solution designers to need to meet availability targets for their new solution. Even if they don’t have hard requirements to meet, they will at least want to understand what availability levels their solution could achieve.

If a key part of their solution is processing a stream of events, then the availability of the topic that they are consuming events from becomes a key factor for their solution design. It perhaps shouldn’t just be viewed as the availability of the topic itself, but the continued stream of events. In other words, if the event source application or connector stops producing events due to an outage or maintenance window, this prevents the Consumer application from having anything to process, and could be viewed as impacting the availability of this solution.
The availability characteristics of a solution’s dependencies define a limit on the availability of the solution itself, so an AsyncAPI document is one place that we could find a consistent way to describe this.
Replication was perhaps not the best name for my next property. What I was talking about was the solution designer’s need to know where the data is available.
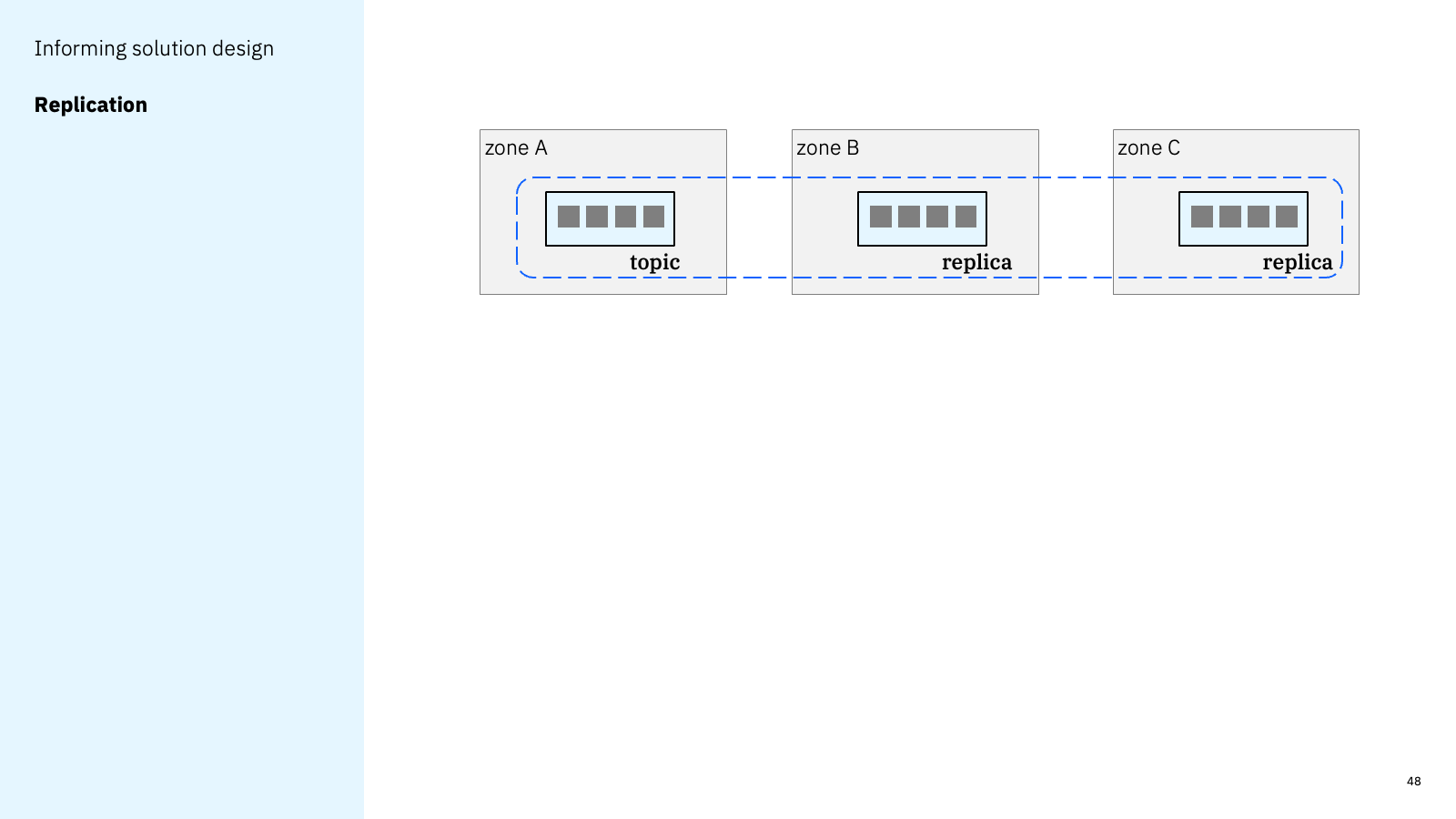
Network ingress and egress costs are an increasingly significant proportion of the costs for many cloud solutions today. As such, it could be helpful for AsyncAPI documents to describe the location of topics in a way that is meaningful to a solution designer.
Knowing which region the Kafka brokers are running in could influence a solution design. The consumer application could intentionally be deployed in the same region to minimise network costs.
This could perhaps be inferred from the hostname that we already document in the server entries in an AsyncAPI document but having a way to explicitly identify this would be useful.
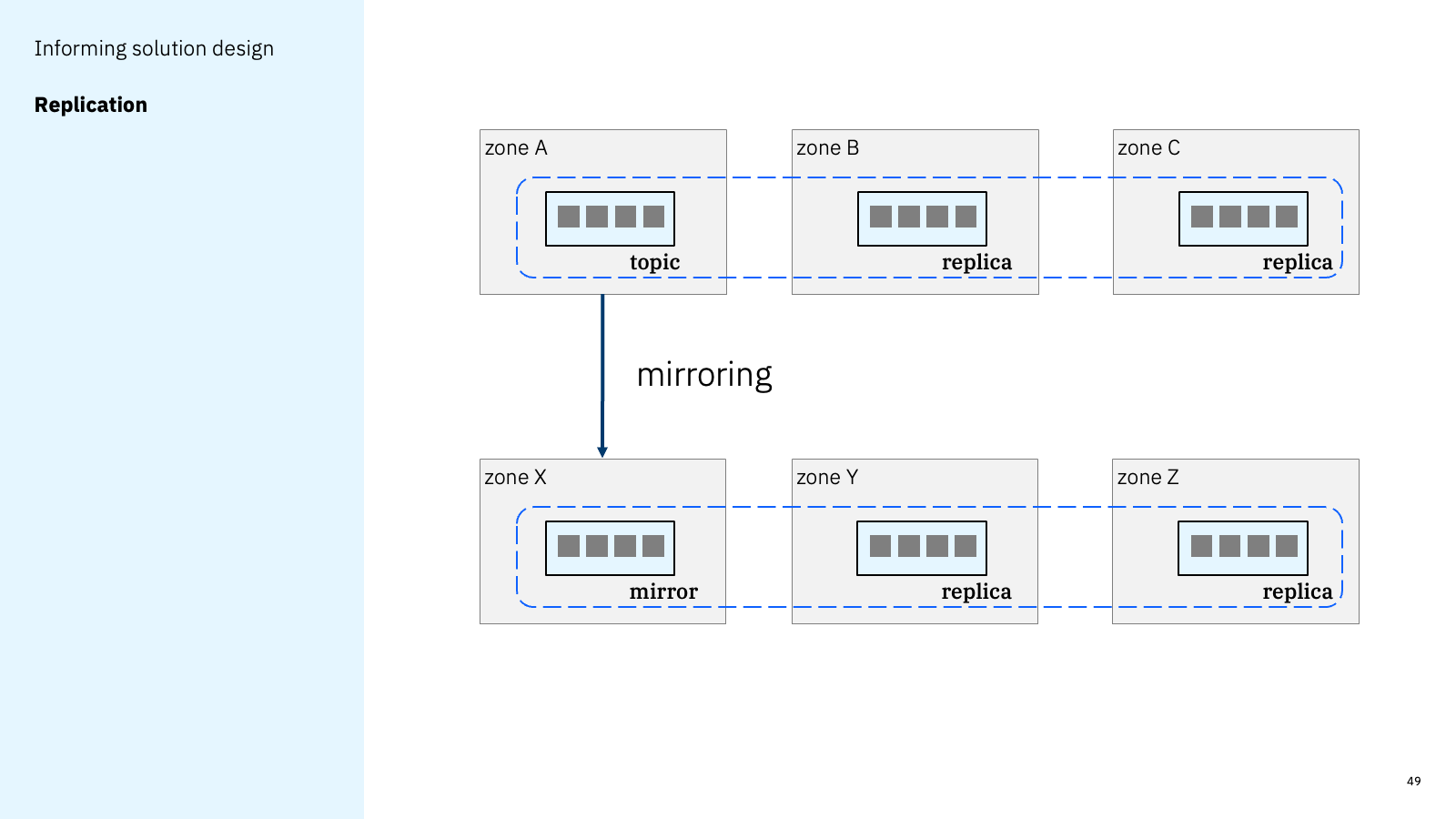
We could also use this to identify other locations where the events could be consumed from.
If something like Mirror Maker is being used to mirror the events to a different region, the events could be consumed from this region instead. This introduces additional latency, but for some solutions this might not be problematic. A solution designer could choose to consume from a mirror if this brings network (or other operational) cost savings.
Alternatively, documenting the availability of a remote mirror could be useful to inform disaster recovery planning, by identifying where the solution can failover to.
Finally, I talked about how AsyncAPI documents could be used to help communicate scaling and monitoring requirements to the ops team responsible for planning the deployment of a new event stream consuming application.

Many of these are the sort of non-functional requirements that I had already talked about earlier.
The size of events is perhaps the most obvious example of this. I mentioned this earlier when talking about design considerations, but it has obvious operational implications as well.
An application consuming 100 byte events has a different scaling profile to an application consuming 1 megabyte events. A consistent way to communicate these requirements in an AsyncAPI document would be beneficial.

Another obvious related example is the rate of events.
As I’d already discussed, knowing the rate of events that the application can expect to receive is perhaps the most single important factor in being able to plan how to adequately scale a new consuming application.

Some non-functional aspects are less obvious.
For example, the size of batches that the Kafka consumer will receive has an impact on how the application will need to be scaled, such as the memory requirements.
Kafka consumer applications can be configured to describe the data quantities that they would like to receive at a time. It is not well understood by many Kafka application developers that these options are just a preference – they are not a limit. If an event source is consistently producing very large batches their application will still receive large batches irregardless of options such as max.partition.fetch.bytes.
Ops engineers are often much more aware of this. Their planning would benefit from a clear communication in an AsyncAPI document by the owner of the event source about the nature of the event stream.

In general, any non-functional characteristics of the event streams that introduce scaling requirements for consuming applications would be useful to document in a consistent way.
For example, if the event source application is compressing the event batches that it produces, this introduces a requirement on the consuming application to be able to decompress those batches. This has an impact on scaling the consuming applications.
In summary, AsyncAPI fills an essential role in enabling teams to communicate consistently about the decisions made in creating event driven architectures. The current spec gives us a way to describe the schema of individual events, and the main connection details to produce and consume events.
My experiences with using this suggests that we could get even more value from AsyncAPI documents by expanding the information that we capture in them.
I think an effective way of doing this is to think about the different roles involved in designing, implementing, deploying and monitoring event driven applications – and to think about what each of these people need in order to do their job effectively.
What decisions do they need to make?
What information do they need in order to make that decision?
This approach can help us to highlight possible additions to the AsyncAPI spec.

Thanks to the organisers of apidays in general, and the AsyncAPI track in particular, for having me – and I hope this session was a thought-provoking addition to a few days that explored all aspects of the role of APIs.
Tags: apachekafka, asyncapi, kafka