Overview
UIMA stands for Unstructured Information Management Architecture. It’s an Apache technology that provides a framework and standard for building text analytics applications. I’ve mentioned it before.
In this post, I want to talk about an area of UIMA which isn’t covered well in the documentation.
I couldn’t find practical getting-started instructions for running UIMA-AS annotators in parallel. In this post I want to discuss why you might want to do it, and share some simple sample code to show how.
Background – the UIMA pipeline
UIMA provides a framework for managing a text analytics application. You break up the analytics functionality into discrete pieces called annotators. UIMA takes care of moving a text document through an analytics engine: a pipeline containing a series of annotators.
A document goes in one end of the pipeline, passes through a number of annotators, each of which adds some metadata to the document. What comes out the other side of the pipeline is an annotated copy of the document.
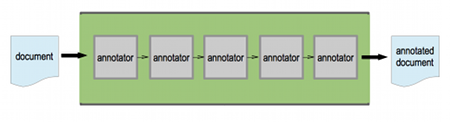
By default, you get UIMA to run these annotators one at a time – one after another.
Background – annotators in parallel
What if your annotators are quite slow – perhaps they take several seconds to run?
If there is no dependency between any or all of your annotators, then maybe running them one at a time isn’t the most efficient approach.
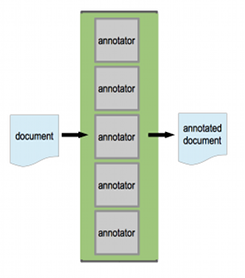
You can run all of them at the same time, in parallel. UIMA will merge the output from all of the annotators into a single annotated document.
My sample code
I’ve written two sample UIMA apps. Each demonstrates one of these approaches, to compare and contrast.
They are divided into three eclipse projects. You can import them into an eclipse IDE.
The UIMA eclipse plugins are very helpful if you want to make changes to the XML configuration files, but they’re not essential. If you want them, there are instructions on how to install them at uima.apache.org.
I’ve added comments to the sample code to explain how the apps work, but I’ll give an overview here.
For these samples, I have five simple annotators. They sleep for six seconds, then add an empty annotation to the document CAS.
public void process(JCas jCas) throws AnalysisEngineProcessException {
// sleep for six seconds...
try {
Thread.sleep(6000);
}
catch (InterruptedException e) {
e.printStackTrace();
}
// add an empty annotation to the CAS
jCas.addFsToIndexes(new AnnotationB(jCas));
}
They do enough to prove that all five of them are being run, and that they all really contribute to the final annotated document. They take long enough to demonstrate the differences between these two approaches to running the pipeline.
Sample code : running one annotator at a time
This can be done using UIMA. The first app uima-project demonstrates this.
An XML descriptor file (uima-project/conf/analysisEngine.xml) specifies which annotators should be included in the pipeline, and which order they should be run in.
<analysisEngineMetaData> <name>UIMA demonstration</name> <version>1.0</version> <flowConstraints> <fixedFlow> <node>annotatorA</node> <node>annotatorB</node> <node>annotatorC</node> <node>annotatorD</node> <node>annotatorE</node> </fixedFlow> </flowConstraints>
The descriptor file (uima-project/conf/analysisEngine.xml) imports a descriptor for each individual annotator.
<delegateAnalysisEngineSpecifiers>
<delegateAnalysisEngine key="annotatorA">
<import location="annotatorA/analysisEngine.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorB">
<import location="annotatorB/analysisEngine.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorC">
<import location="annotatorC/analysisEngine.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorD">
<import location="annotatorD/analysisEngine.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorE">
<import location="annotatorE/analysisEngine.xml"/>
</delegateAnalysisEngine>
</delegateAnalysisEngineSpecifiers>
Each of those imported descriptors identifies the Java class that implements the annotator, and specifies the metadata annotations that it can add to the output document.
For example,
uima-project/conf/annotatorC/analysisEngine.xml:
<annotatorImplementationName>com.dalelane.uima.annotators.DemoC</annotatorImplementationName>
<analysisEngineMetaData>
<name>annotatorC</name>
<typeSystemDescription>
<types>
<typeDescription>
<name>com.dalelane.uima.annotators.gen.AnnotationC</name>
<description/>
<supertypeName>uima.tcas.Annotation</supertypeName>
</typeDescription>
</types>
</typeSystemDescription>
The overall pipeline is started from
uima-project/src/com/dalelane/uima/serial/Pipeline.java. This reads in the descriptor file for the pipeline, and uses it to create an instance of a UIMA analysis engine.
File descriptorFile = new File("./conf/analysisEngine.xml");
XMLInputSource descriptorSource = new XMLInputSource(descriptorFile);
ResourceSpecifier specifier = UIMAFramework.getXMLParser().parseResourceSpecifier(descriptorSource);
analysisEngine = UIMAFramework.produceAnalysisEngine(specifier);
To summarise:
- The provided eclipse launch config starts a Java application
uima-project/src/com/dalelane/uima/serial/Application.java - The Java application creates
uima-project/src/com/dalelane/uima/serial/Pipeline.javawhich creates a UIMAAnalysisEngine - The analysis engine reads in the XML descriptor file
uima-project/conf/analysisEngine.xml - The analysis engine descriptor identifies the descriptors for each annotator
(e.g.uima-project/conf/annotatorC/analysisEngine.xml) - The descriptor for the annotator identifies the Java class which implements it
(e.g.uima-project/src/com/dalelane/uima/annotators/DemoC.java)
The output from running the launch config shows that it takes about 30 seconds (5 annotators, each of which takes about 6 seconds) to process the document text.
Sample UIMA application - serial ================================== Accessing analysis engine descriptor file Creating analysis engine Processing document... Time spent in pipeline: 30121 Confirming what was added... Found: org.apache.uima.jcas.tcas.Annotation Found: com.dalelane.uima.annotators.gen.AnnotationD Found: com.dalelane.uima.annotators.gen.AnnotationC Found: com.dalelane.uima.annotators.gen.AnnotationB Found: com.dalelane.uima.annotators.gen.AnnotationA
Sample code : running all annotators at once
This can be done using UIMA-AS – a variant of UIMA that provides support for asynchronous scale out. The second app uima-as-project demonstrates this.
To describe the approach at a high level, the idea is that you want to create five separate copies of the document to be analysed. Each of these copies can be run through a separate annotator at the same time. Once they’ve all finished, the output from all of the annotators can be collected together and merged to form the single output document.

Each of the annotators are run as a separate service. A by-product of this is that each can be run on a remote machine, and UIMA-AS manages moving the documents to/from the remote services using JMS messaging.
In my sample, I’m running them all on the same server, and using “localhost” to define the interactions. A JMS broker is still required for this. Instructions for starting the message broker is contained in uima-as-project/README
Because the annotators are run as “remote” services, this introduces an extra step – the services need to be deployed before the pipeline can be started.
uima-as-project/src/com/dalelane/uima/parallel/Pipeline.java deploys each of the services by specifying the deployment descriptors.
// creating UIMA analysis engine
UimaAsynchronousEngine uimaAsEngine = new BaseUIMAAsynchronousEngine_impl();
// preparing map for use in deploying services
Map<String,Object> deployCtx = new HashMap<String,Object>();
deployCtx.put(UimaAsynchronousEngine.DD2SpringXsltFilePath, System.getenv("UIMA_HOME") + "/bin/dd2spring.xsl");
deployCtx.put(UimaAsynchronousEngine.SaxonClasspath, "file:" + System.getenv("UIMA_HOME") + "/saxon/saxon8.jar");
// preparing map for use in deploying services
uimaAsEngine.deploy("./conf/annotatorA/deploy.xml", deployCtx);
uimaAsEngine.deploy("./conf/annotatorB/deploy.xml", deployCtx);
uimaAsEngine.deploy("./conf/annotatorC/deploy.xml", deployCtx);
uimaAsEngine.deploy("./conf/annotatorD/deploy.xml", deployCtx);
uimaAsEngine.deploy("./conf/annotatorE/deploy.xml", deployCtx);
The deployment descriptors for each annotator specify the name of the JMS endpoint that UIMA can use to send documents to the annotator for analysis, and the location of the analysis engine descriptor file that defines the annotator.
For example uima-as-project/conf/annotatorB/deploy.xml
<analysisEngineDeploymentDescription>
<deployment protocol="jms" provider="activemq">
<service>
<inputQueue endpoint="AnnotatorBRemoteQ" brokerURL="tcp://localhost:61616"/>
<topDescriptor>
<import location="analysisEngine.xml"/>
</topDescriptor>
</service>
</deployment>
</analysisEngineDeploymentDescription>
The individual annotator descriptors are the same as in the first project uima-project.
For example,
uima-as-project/conf/annotatorB/analysisEngine.xml
As before, it identifies the Java class which implements the annotator, and the types of annotations that it can create.
Once the UIMA services are deployed, the analysis engine descriptor for the overall pipeline can be deployed.
This is also done in
uima-as-project/src/com/dalelane/uima/parallel/Pipeline.java
uimaAsEngine.deploy("./conf/deploy.xml", deployCtx);
The deployment descriptor for the overall pipeline (uima-as-project/conf/deploy.xml), identifies how the pipeline can communicate with each of the “remote” services that make up it’s annotators.
<delegates>
<remoteAnalysisEngine key="annotatorA">
<inputQueue brokerURL="tcp://localhost:61616" endpoint="AnnotatorARemoteQ"/>
<serializer method="xmi"/>
</remoteAnalysisEngine>
<remoteAnalysisEngine key="annotatorB">
<inputQueue brokerURL="tcp://localhost:61616" endpoint="AnnotatorBRemoteQ"/>
<serializermethod="xmi"/>
</remoteAnalysisEngine>
<remoteAnalysisEnginekey="annotatorC">
<inputQueue brokerURL="tcp://localhost:61616" endpoint="AnnotatorCRemoteQ"/>
<serializer method="xmi"/>
</remoteAnalysisEngine>
<remoteAnalysisEnginekey="annotatorD">
<inputQueue brokerURL="tcp://localhost:61616" endpoint="AnnotatorDRemoteQ"/>
<serializer method="xmi"/>
</remoteAnalysisEngine>
<remoteAnalysisEngine key="annotatorE">
<inputQueue brokerURL="tcp://localhost:61616" endpoint="AnnotatorERemoteQ"/>
<serializer method="xmi"/>
</remoteAnalysisEngine>
</delegates>
UIMA-AS provides a sample (AdvancedFixedFlowController) that takes care of making the copies (a CAS Multiplier) of the document being analysed, and defines the sequence for the annotators to be run in parallel.
The deployment descriptor for my pipeline uses this sample.
<flowController key="AdvancedFixedFlowController">
<import location="UIMA_HOME/examples/descriptors/flow_controller/AdvancedFixedFlowController.xml"/>
</flowController>
<analysisEngineMetaData>
<configurationParameterSettings>
<nameValuePair>
<name>Flow</name>
<value>
<array>
<string>annotatorA,annotatorB,annotatorC,annotatorD,annotatorE</string>
</array>
</value>
</nameValuePair>
</configurationParameterSettings>
It also identifies the descriptor file for running the analysis engine
<topDescriptor>
<import location="analysisEngine.xml"/>
</topDescriptor>
The analysis engine descriptor file (uima-as-project/conf/analysisEngine.xml), similar to before, identifies the annotators that make up the aggregate pipeline.
<delegateAnalysisEngineSpecifiers>
<delegateAnalysisEngine key="annotatorA">
<import location="annotatorA/remote.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorB">
<import location="annotatorB/remote.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorC">
<import location="annotatorC/remote.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorD">
<import location="annotatorD/remote.xml"/>
</delegateAnalysisEngine>
<delegateAnalysisEngine key="annotatorE">
<import location="annotatorE/remote.xml"/>
</delegateAnalysisEngine>
</delegateAnalysisEngineSpecifiers>
These describe the way that the analysis engine can send documents to the remote services for analysis, using JMS. For example, uima-as-project/conf/annotatorB/remote.xml contains:
<customResourceSpecifierxmlns="http://uima.apache.org/resourceSpecifier">
<resourceClassName>org.apache.uima.aae.jms_adapter.JmsAnalysisEngineServiceAdapter</resourceClassName>
<parameters>
<parameter name="brokerURL" value="tcp://localhost:61616"/>
<parameter name="endpoint" value="AnnotatorBRemoteQ"/>
<parameter name="timeout" value="5000"/>
<parameter name="getmetatimeout" value="5000"/>
<parameter name="cpctimeout" value="5000"/>
</parameters>
</customResourceSpecifier>
To summarise:
- The provided eclipse launch config starts a Java application
uima-as-project/src/com/dalelane/uima/parallel/Application.java - The Java application creates an instance of
uima-as-project/src/com/dalelane/uima/parallel/Pipeline.java Pipeline.javacreates anUimaAsynchronousEnginewhich deploys each of the annotator services, such asuima-as-project/conf/annotatorD/deploy.xml- Each annotator’s deployment descriptor identifies the actual implementation of the annotator, giving the analysis engine XML
uima-as-project/conf/annotatorD/analysisEngine.xmlwhich in turn specifies the Java implementation class Pipeline.javathen deploys the overall analysis engine pipeline as specified in the deployment descriptoruima-as-project/conf/deploy.xml- This deployment descriptor identifies the way that the analysis engine should communicate with the remote services (by importing JMS specs such as
uima-as-project/conf/annotatorC/remote.xml) and the order that they should be invoked in (usingAdvancedFixedFlowController)
The output from running the launch config shows that it takes about 6 seconds (5 annotators run in parallel, each of which takes about 6 seconds) to process the document text.
Full sample output is at
uima-as-project/example-output/console.log
A summary is:
Sample UIMA application - parallel ================================== Deploying UIMA services Service:annotatorA Initialized. Ready To Process Messages From Queue:AnnotatorARemoteQ Service:annotatorB Initialized. Ready To Process Messages From Queue:AnnotatorBRemoteQ Service:annotatorC Initialized. Ready To Process Messages From Queue:AnnotatorCRemoteQ Service:annotatorD Initialized. Ready To Process Messages From Queue:AnnotatorDRemoteQ Service:annotatorE Initialized. Ready To Process Messages From Queue:AnnotatorERemoteQ Deploying analysis engine Service:UIMA demonstration Initialized. Ready To Process Messages From Queue:DemoAnnotatorQueue Initialising UIMA client Processing document... Time spent in pipeline: 6117 Confirming what was added... Found: org.apache.uima.cas.impl.AnnotationImpl Found: org.apache.uima.cas.impl.AnnotationImpl Found: org.apache.uima.cas.impl.AnnotationImpl Found: org.apache.uima.cas.impl.AnnotationImpl Found: org.apache.uima.cas.impl.AnnotationImpl Found: org.apache.uima.cas.impl.AnnotationImpl
Summary
This isn’t definitive model code for using UIMA-AS. It’s intended more as a helpful first step into getting started with UIMA-AS – which there seems to be a shortage of documentation for. But there is a *lot* more to UIMA-AS, with a lot of settings and features to tweak.
Even with this simple example, you can see that output which takes 30 seconds to get using UIMA can be completed in 6 seconds if run in parallel, and how this can be done with UIMA-AS and a few extra config files.
Hey,
your example is quite interesting and resolve my doubts about the parallelism of descriptor using flow controller. Please write a blog for the remote analysis engine uses in Uima AS.