In this post, I want to explain how to create a text analytics application in BlueMix using UIMA, and share sample code to show how to get started.
First, some background if you’re unfamiliar with the jargon.
What is UIMA?
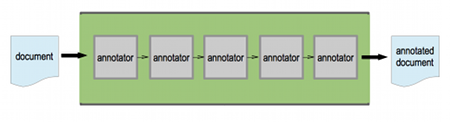
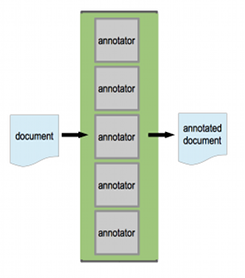
UIMA (Unstructured Information Management Architecture) is an Apache framework for building analytics applications for unstructured information and the OASIS standard for content analytics.
I’ve written about it before, having used it on a few projects when I was in ETS, and on other side projects since such as building a conversational interface to web pages.
It’s perhaps better known for providing the architecture for the question answering system IBM Watson.
What is BlueMix?
 BlueMix is IBM’s new Platform-as-a-Service (PaaS) offering, built on top of Cloud Foundry to provide a cloud development platform.
BlueMix is IBM’s new Platform-as-a-Service (PaaS) offering, built on top of Cloud Foundry to provide a cloud development platform.
It’s in open beta at the moment, so you can sign up and have a play.
I’ve never used BlueMix before, or Cloud Foundry for that matter, so this was a chance for me to write my first app for it.
A UIMA “Hello World” for BlueMix
I’ve written a small sample to show how UIMA and BlueMix can work together. It provides a REST API that you can submit text to, and get back a JSON response with some attributes found in the text (long words, capitalised words, and strings that look like email addresses).
The “analytics” that the app is doing is trivial at best, but this is just a Hello World. For now my aim isn’t to produce a useful analytics solution, but to walk through the configuration needed to define a UIMA analytics pipeline, wrap it in a REST API using Wink, and deploy it as a BlueMix application.
When I get a chance, I’ll write a follow-up post on making something more useful.
You can try out the sample on BlueMix as it’s deployed to bluemix.net
The source is on GitHub at github.com/dalelane/bluemixuima.
In the rest of this post, I’ll walk through some of the implementation details.