In this post, I want to explain how to get started creating machine learning applications using the data you have on Kafka topics.

I’ve written a sample app, with examples of how you can use Kafka topics as:
- a source of training data for creating machine learning models
- a source of test data for evaluating machine learning models
- an ongoing stream of events to make predictions about using machine learning models
I’ll use this post to explain how it works, and how you can use it as the basis of writing your first ML pipeline using the data on your own Kafka topics.
Overview
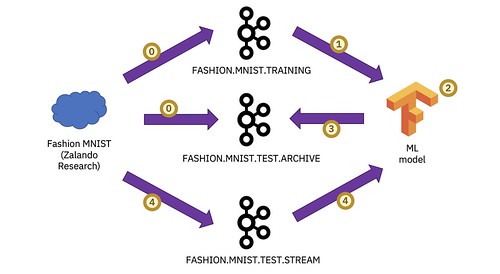
There are a variety of ways to do this, but for this post I’ll be starting with perhaps the simplest, aiming for something a bit like this:

(a) Get a source of events that you want to use as training data for your machine learning model.
I won’t be discussing this step for this post, but I’m assuming that you’ll use something like Kafka Connect or some custom client to get some interesting data into a Kafka topic.
(b) Prepare the source of events for use training your model
The specifics will depend on your domain, use-case and data, but I’m assuming that you’ll use something like Kafka Streams to cleanse, filter, or otherwise pre-process your training data.
(c) Train a machine learning model using the events on your training Kafka topic
For this post, I’m using TensorFlow with Keras, using some of the new APIs from TensorFlow I/O for the integration with Kafka.
(d) Try out your machine learning model to check it’s working
(e) Evaluate your machine learning model, using a second topic as a source of test data
Now you have a machine learning model, that you’re happy with the performance of, and you’re ready to start using it.

(f) Get a stream of events that you want to use your ML model to make predictions about
Again, the specifics will depend on your use case, but it may well be a combination of Kafka Connect and Kafka Streams components as with the training data.
(g) Use your ML model to make predictions against a stream of events
Unlike with the test topic before in (e), this isn’t a one-off batch test against a topic that already has the data ready on it.
This is a live stream of events, with your ML model used to make predictions based on each event as they arrive.
(h) Do something!
Take an action, make a notification… do something with the prediction your ML model made!
A demo
To show how to do this for real, I’ll be using a simplified demo Python application written using TensorFlow with IBM Event Streams.
I’ve put the complete working demo on GitHub as event-streams-tensorflow.
(You just need to edit the config.env file with the location of your own cluster, then it should be ready to run. To reset everything to start from the beginning again, just run run-cleanup-99.sh).
In this post, I’ll explain what it all does.
I’ll copy some of the more interesting snippets below, with links to where you can find it in the context of the full working app.
Step 0
Preparing Kafka topics with data for an ML project
To see this step running, run the run-step-0.sh script.
For an example of the output, see sample-output/step-0.txt

I’m calling this “Step 0” because the ideal scenario here is that you already have a Kafka topic with a useful stream of events, and you’re thinking about how to get further value from it through machine learning. This would mean you don’t have anything to do for this step, but for the purposes of this post, I need a topic with some data on it that I can use as the basis of a demo.
I’m using the Fashion MNIST dataset from Zalando.
If you’re not familiar with it, it’s a set of 70,000 images – each one a photo of a fashion item (e.g. a t-shirt, or coat, or boot). The images are all already pre-processed, available as 28×28 pixel grayscale images and labelled as one of ten types of fashion item.

I’ve chosen this because it’s a very commonly-used dataset for machine learning projects, with hundreds of tutorials based on it, and articles with a decent set of hyperparameters available for use as a starting point.
By taking the neural net specification for tackling the fashion MNIST dataset as a given it means I can concentrate on the Kafka-specific angle for this post, rather than try to cover too many things in one go.
This means that, for this post, step 0 is going to mean getting the training and test data from the fashion MNIST dataset, and loading them onto two different Kafka topics.
With such a well-known dataset, it perhaps wasn’t essential for me to use a schema for the data, but it’s a good idea to base your ML pipeline on well-known predictable data formats, so I’ll start by defining my Avro schema.

You can find the schema that I’ve written in fashion.avsc. It has two fields: a bytes field with the image data, and an int field with the code for the type of fashion item the picture is of.
The script is using the CLI to store the schema in the Event Streams registry.
cloudctl es schema-add --file fashion.avsc --name FashionMnist --version 1.0.0
For the purposes of this post, I’m just creating single partition topics, one for the training data, one for the test data.
cloudctl es topic-create FASHION.MNIST.TRAINING --partitions 1 --replication-factor 3 cloudctl es topic-create FASHION.MNIST.TEST.ARCHIVE --partitions 1 --replication-factor 3
With those defined, I’m ready to fetch the dataset and get it into my Kafka topics.
print ("-->>> Create a Kafka producer")
producer = KafkaProducer(bootstrap_servers=[KAFKA_BOOTSTRAP],
security_protocol="SASL_SSL",
ssl_cafile=CERT,
ssl_check_hostname=False,
sasl_plain_username="token",
sasl_plain_password=EVENT_STREAMS_API_KEY,
sasl_mechanism="PLAIN",
client_id="dalelane-load-topics")
print ("-->>> Download the training data to be used")
train, test = tfds.load("fashion_mnist", split=["train", "test"])
print ("-->>> Sending training data to Kafka topic %s" % TRAINING_TOPIC_NAME)
for features in train.batch(1).take(-1):
producer.send(TRAINING_TOPIC_NAME,
serialize(schema, {
"ImageData" : features["image"].numpy()[0].tobytes(),
"Label" : int(features["label"].numpy()[0])
}),
None,
create_headers_for_schema(SCHEMA_ID, SCHEMA_VERSION))
With this done, I now have Kafka topics ready to be a data source for my machine learning pipeline.

It’s worth pointing out that this was trivially simple for this project, because I’m using a clean well-prepared dataset.
For you, this stage of the pipeline is almost certainly more complicated, which is why I broke it out into two separate steps (getting the data into Kafka, and pre-processing the data) in my first diagram above.
Step 1
Using a Kafka topic as a source of training data for an ML project
To see this step running, run the run-step-1.sh script.
For an example of the output, see sample-output/step-1.txt

I’ve got the training data ready to use on my FASHION.MNIST.TRAINING topic, serialized using an Avro schema in my registry.
Now I’m ready to use it to train a machine learning model.
First, I define a TensorFlow dataset based on the Kafka topic.
dataset = kafka_io.KafkaDataset([ TRAINING_TOPIC_NAME + ':0' ],
servers=KAFKA_BOOTSTRAP,
group="dalelane-tensorflow-train",
config_global=[
"api.version.request=true",
"sasl.mechanisms=PLAIN",
"security.protocol=sasl_ssl",
"sasl.username=token",
"sasl.password=" + EVENT_STREAMS_API_KEY,
"ssl.ca.location=" + CERT
])
Then, I deserialize it using the Avro schema.
def deserialize(kafkamessage):
trainingitem = kafka_io.decode_avro(kafkamessage,
schema=schemastr,
dtype=[tf.string, tf.int32])
image = tf.io.decode_raw(trainingitem[0], out_type=tf.uint8)
image = tf.reshape(image, [28, 28])
image = tf.image.convert_image_dtype(image, tf.float32)
label = tf.reshape(trainingitem[1], [])
return image, label
dataset = dataset.map(deserialize).batch(1)
With the dataset ready, I can define the neural net.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(dataset, epochs=4, steps_per_epoch=1000)
I’ve copied this neural net definition from the TensorFlow Keras classification tutorial (as it’s also based on the same Fashion MNIST dataset).
Now I have a working machine learning model.
Step 2
Try out the machine learning model
To see this step running, run the run-step-2.sh script.
For an example of the output, see sample-output/step-2.txt

Before continuing, let’s give the ML model a quick try.
I’m picking one of the test images from the Fashion MNIST dataset at random, and using the machine learning model to make a prediction for what is in the image.
print ("-->>> Get information about the Fashion MNIST dataset")
datasetinfo = tfds.builder("fashion_mnist").info.features["label"]
print ("-->>> Choose a random item from the test set")
test, = tfds.load("fashion_mnist", split=["test"])
for features in test.shuffle(10000).batch(1).take(1):
testdata = features["image"].numpy()[0]
print ("-->>> Use the ML model to make a prediction for the test item")
prediction = model.predict(testdata.reshape(1, 28, 28))
prediction_idx = prediction.argmax()
prediction_name = datasetinfo.int2str(prediction_idx)
prediction_confidence = prediction[0][prediction_idx] * 100.0
print ("-->>> Prediction : %s with %d%% confidence" %
(prediction_name, prediction_confidence))
print ("-->>> Saving random test item to test.png for verification")
plt.xticks([])
plt.yticks([])
plt.grid(False)
testimage = testdata.reshape([-1, 28, 28, 1]) / 255
plt.imshow(1 - testimage[0][:, :, 0], cmap='gray')
plt.savefig("test.png")
To check if the ML model is correct, I’m saving the test image to a file so you can open it and see what you think it is.
Step 3
Using a Kafka topic as a source of test data for an ML project
To see this step running, run the run-step-3.sh script.
For an example of the output, see sample-output/step-3.txt
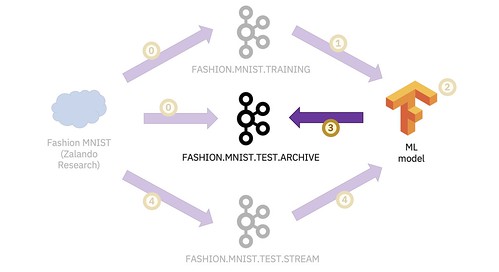
Individual predictions aren’t good enough for testing a model, so the next step is to run the complete test set through the ML model and measure the accuracy of the predictions.
In Step 0, I filled the FASHION.MNIST.TEST.ARCHIVE topic with the test data from the Fashion MNIST dataset.
In Step 1, I trained a machine learning model.
Now I’m ready to evaluate the ML model using the data from the test topic.
Notice that the dataset is defined using eof=True which means it will read until the end of the topic and then close the consumer. This is useful in situations like this, where the test data is already on the topic, and you want to read all of it into a dataset to use.
print ("-->>> Prepare a test dataset using test data from Kafka")
dataset = kafka_io.KafkaDataset([ TEST_ARCHIVE_TOPIC_NAME + ":0"],
servers=KAFKA_BOOTSTRAP,
group="dalelane-tensorflow-test",
eof=True,
config_global=[
"api.version.request=true",
"sasl.mechanisms=PLAIN",
"security.protocol=sasl_ssl",
"sasl.username=token",
"sasl.password=" + EVENT_STREAMS_API_KEY,
"ssl.ca.location=" + CERT
])
dataset = dataset.map(train_model.deserialize).batch(1)
print ("-->>> Evaluate the machine learning model using test data from Kafka")
model.evaluate(dataset)
from 3_train_and_test_model.py
One benefit of using Kafka topics as data sources for projects like this is that you can tweak the definition of your neural net, and replay the training and test data.
And you can go round that loop of tweak, re-train, and re-test repeatedly until you’re happy with the test accuracy.
Step 4
Using an ML model to make predictions about a stream of events on a Kafka topic
To see this step running, run the run-step-4.sh script.
For an example of the output, see sample-output/step-4.txt
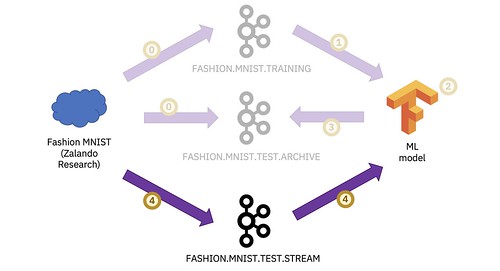
At this point, I have a working neural network, trained using the data from my training topic and verified using the data from my test topic.
Now I’m ready to start using my machine learning model with a live stream of events on a Kafka topic.
I don’t actually have a Kafka topic with a stream of photo events with fashion items, so for the purposes of this demo I’ll simulate it, again using the test data from the fashion MNIST dataset.
First, I create a new empty topic.
cloudctl es topic-create FASHION.MNIST.TEST.STREAM --partitions 1 --replication-factor 1
Creating my live stream of events to be classified is similar to how I populated the FASHION.MNIST.TEST.ARCHIVE topic before, but I’m adding a sleep call in there so I only produce one image a second.
As there are 10,000 test images in the dataset, this means I’ll have a stream of events for over two-and-a-half hours, which is easily enough for a quick demo!
print ("-->>> Create a Kafka producer")
producer = KafkaProducer(bootstrap_servers=[KAFKA_BOOTSTRAP],
security_protocol="SASL_SSL",
ssl_cafile=CERT,
ssl_check_hostname=False,
sasl_plain_username="token",
sasl_plain_password=EVENT_STREAMS_API_KEY,
sasl_mechanism="PLAIN",
client_id="dalelane-load-topics")
print ("-->>> Download the test data to be used")
test, = tfds.load("fashion_mnist", split=["test"])
print ("-->>> Starting to create test events to %s every second" % TEST_STREAM_TOPIC_NAME)
for features in test.batch(1).take(-1):
producer.send(TEST_STREAM_TOPIC_NAME,
serialize(schema, {
"ImageData" : features["image"].numpy()[0].tobytes(),
"Label" : int(features["label"].numpy()[0])
}),
None,
create_headers_for_schema(SCHEMA_ID, SCHEMA_VERSION))
sleep(1)
producer.flush()
While this is running, the next step is to create a streaming dataset based on that topic.
Notice the eof=False, so (unlike before) the consumer won’t be closed when it reaches the end of the topic. This dataset will stay open until you kill it with Ctrl-C, as the objective is to keep a long-running streaming dataset.
dataset = kafka_io.KafkaDataset([ TEST_STREAM_TOPIC_NAME + ":0"],
servers=KAFKA_BOOTSTRAP,
group="dalelane-tensorflow-test",
eof=False,
config_global=[
"api.version.request=true",
"sasl.mechanisms=PLAIN",
"security.protocol=sasl_ssl",
"sasl.username=token",
"sasl.password=" + EVENT_STREAMS_API_KEY,
"ssl.ca.location=" + CERT
])
dataset = dataset.map(train_model.deserialize).batch(1)
from 4_train_and_stream_model.py
And finally, to classify the image received in each message on the Kafka topic, using the machine learning model.
for image, label in dataset:
prediction = model.predict(image)
from 4_train_and_stream_model.py
And that’s the demo.
Hopefully this is enough to make it easy for you to setup your own neural net based on the data on your own Kafka topics.
If there is anything else you think it would be useful to add to the sample, please let me know.
Tags: apachekafka, eventstreams, ibmeventstreams, kafka, machine learning