I’ve been talking about MirrorMaker 2 this week – the Apache Kafka tool for replicating data across two Kafka clusters. You can use it to make a copy of messages on your Kafka cluster to a remote Kafka cluster running on a different data centre, and keep that copy up to date in the background.
For the discussion we had, I needed to give examples of how you might use MirrorMaker 2, which essentially meant I spent an afternoon drawing pictures. As some of them were a little pretty, I thought I’d tidy them up and share them here.
We went through several different use cases, but I’ll just describe two examples here.
Active / active
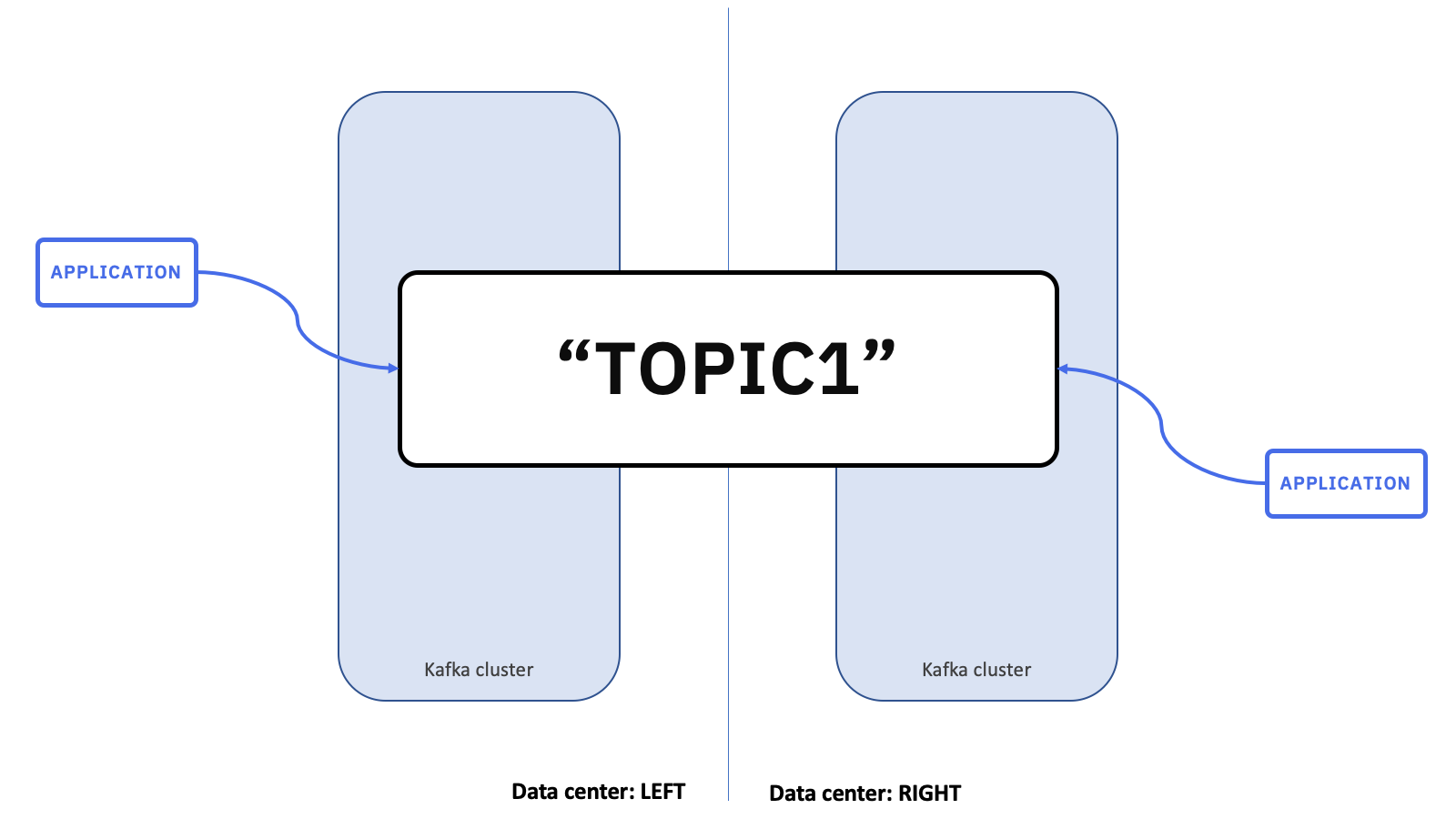
In this pattern, your goal is to have one conceptual, logical topic, which is spread across two separate Kafka clusters, and accessible to client applications running in either data centre.

You do this by creating two pairs of topics.

And you use MirrorMaker 2 to copy messages between them.
There is a TOPIC1 topic on the “LEFT” data centre, which MirrorMaker 2 is replicating to a copy called LEFT.TOPIC1 on the “RIGHT” data centre.
And the same going in the opposite direction. There is a TOPIC1 topic on the “RIGHT” data centre, which MirrorMaker 2 is replicating to a copy called RIGHT.TOPIC1 on the “LEFT” data centre.
This naming convention (prefixing the logical topic name with the name of where the canonical copy is hosted) helps to keep everything organized.

Applications running in each data centre send messages to the canonical topic hosted by the Kafka cluster in their local data centre. This means that producers in the “LEFT” data centre produce messages to the TOPIC1 topic hosted in the Kafka cluster in the “LEFT” data centre.
And producers running in the “RIGHT” data centre produce messages to the TOPIC1 topic hosted in the “RIGHT” Kafka cluster.

In this scenario, we want applications to receive all messages produced in either data centre. To do this, consuming applications need to consume from both copies of the topic in their local Kafka cluster. This means that they receive messages produced from applications in the same data centre as them, as well as messages produced in the remote data centre.
This is most easily done by using a wildcard in the topic subscription. For example, the consumer applications here can consume from topics with names like .*TOPIC1.
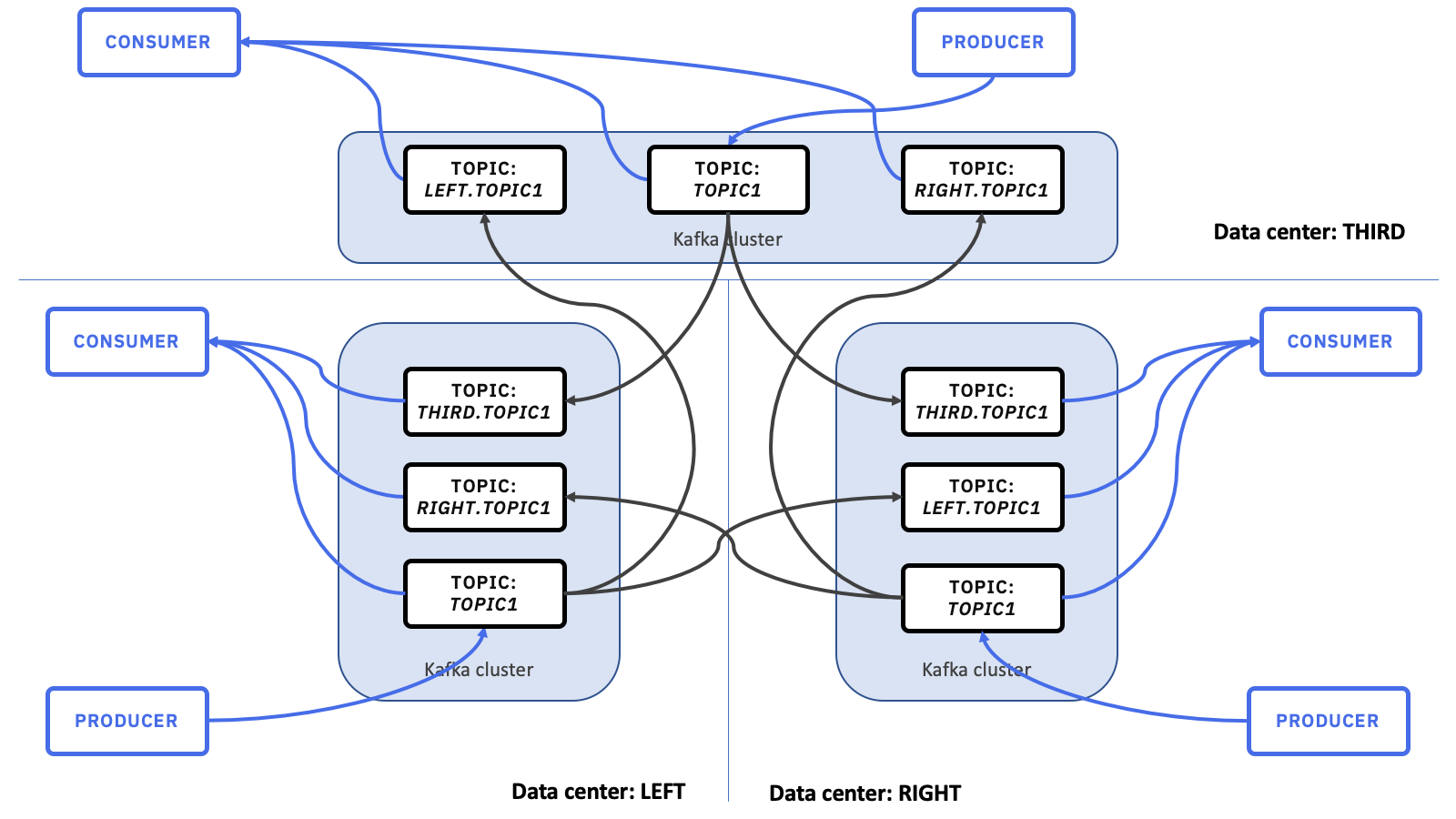
Using wildcards for this also makes it very easy to expand this set-up to add a third Kafka cluster in a third data centre.

Although I’ve been referring to pairs until now, it doesn’t need to be limited to two Kafka clusters. The same patterns apply if you add a third data centre.
The new Kafka cluster will host its own canonical local copy of the topic, and a copy of each topic from the remote data centres.

MirrorMaker 2 still has the same objective, but now it is being used to replicate a topic to two different remote Kafka clusters.

If you do that for all the topics, the MirrorMaker 2 flows (shown above as dark grey arrows) end up looking a bit like this.

Producing applications still just produce to the same topic (TOPIC1 in this case) on their local Kafka cluster. Their configuration doesn’t need to change with the addition of the third Kafka cluster.

Similarly, consuming applications still consume from .*TOPIC1 on their local Kafka cluster. Even though they will now start receiving messages from a new additional topic (THIRD.TOPIC1) there was no configuration change in the application needed to enable this.
This approach has a lot of flexibility. Application configuration is simplified as all applications only connect to their local Kafka cluster. And the complexity of adding new remote Kafka clusters is contained solely in the MirrorMaker 2 configuration.

In the event of the loss of a data centre hosting one of the Kafka clusters, the applications running on the remaining data centre will not be impacted.
They only ever connect to their local Kafka cluster, so they are unaffected by remote data centre outages and will continue processing without interruption and without needing any configuration changes.

The same is true if it is the “LEFT” data centre that has the outage. The two data centres are peers, without this approach treating either of them as the primary cluster.
You can think of this approach as providing a single logical conceptual topic that spans both clusters and data centres. It means that processing for messages on that conceptual topic is resilient even in the event of the loss of a whole data centre.

There are other benefits to this pattern, besides resiliency.
I’ve already mentioned flexibility – such as not needing to modify application configurations when I added a third data centre. As the number of applications increases, the flexibility of being able to make changes to the remote Kafka clusters without reconfiguring any client applications becomes even more valuable.
There are potentially performance benefits as well. In scenarios where the network connection between data centres is expensive, or where this connection has limited bandwidth, this use of MirrorMaker 2 brings useful network traffic efficiencies.
Assume that consumers running in the “LEFT” data centre want to process all messages sent by producer applications running in the “RIGHT” data centre.
With this approach, each message is brought across from “RIGHT” to the “LEFT” data centre once (and only once). It can then be consumed hundreds of times, by hundreds of consumer applications, without having to pay the cost of that slow and/or expensive network transfer every time.

Without MirrorMaker 2, you would need every client application to make connections to both Kafka clusters.
That is more complex (as the details of the remote Kafka cluster is duplicated many times).
More importantly, it significantly increases the amount of network traffic flowing between the two data centres. Every message needs to be transferred across the slow and/or expensive connection between data centres for every client that consumes it. One hundred consumers brings a 100x increase in network traffic.

This approach does have implications for message ordering which needs careful consideration.
Let’s start by looking at the simple case where everything is happening one at a time.
Imagine that a producer in the “LEFT” data centre produces message “0” to its local topic TOPIC1.

Message “0” will be consumed by consumer applications running in the “LEFT” data centre. And at the same time, MirrorMaker 2 will copy it to the “RIGHT” data centre so that it can be consumed from consumer applications running there.

Conversely, if a producer running in the “RIGHT” data centre sends message “A”, it will go to its own local topic.

From there, it can be consumed by local consumer applications, and MirrorMaker 2 will copy it to the “LEFT” data centre so that it can be consumed by applications running there.

However, if everything happens at once, it will impact message ordering.
Applications will receive messages from their local Kafka clusters very quickly. MirrorMaker 2 flows using slower network connections across a greater distance will likely take longer.
This means consuming applications in the “LEFT” data centre will possibly receive messages in a different order to the applications running in the “RIGHT” data centre, as shown in the diagram above.
For many use cases, this isn’t a problem. But it is something to keep in mind when designing a solution like this around MirrorMaker 2.
Active / passive

The second pattern is similar.
Again, the goal is to support a single conceptual logical topic, hosted across two different Kafka clusters, each running in a different data centre.
This time, the applications are hosted separately to the Kafka clusters. Their availability is not tied to the availability of either of the data centres where Kafka clusters are running, and they are able to connect to either cluster.

The intended usage is a little different though.
In this scenario, the Kafka cluster on one data centre is notionally hosting the logical topic, and all applications connect to it.
The “RIGHT” Kafka cluster maintains a copy that is ready for use in the event of an outage of the “LEFT” data centre, but is otherwise passive and idle.

In the event of an outage, applications switch to use the backup copy of the topic.

As before, this is implemented as two pairs of actual Kafka topics, with MirrorMaker 2 making copies of messages between data centres.
Messages on TOPIC1 in the “LEFT” Kafka cluster are copied to LEFT.TOPIC1 in the “RIGHT” Kafka cluster.
And messages on TOPIC1 in the “RIGHT” Kafka cluster are copied to RIGHT.TOPIC1 in the “LEFT” Kafka cluster.
Again, as before, the MirrorMaker 2 naming convention makes it obvious where everything comes from.

Applications only connect to a single Kafka cluster.
For example, producers produce to TOPIC1 on the “LEFT” Kafka cluster.
And consumers consume from .*TOPIC1 on the “LEFT” Kafka cluster.
In this scenario, the Kafka cluster running on the “RIGHT” data centre is passive, acting as a backup for the Kafka cluster running in the “LEFT” data centre. MirrorMaker 2 is constantly keeping that copy up to date in the background.

In the event of an outage of the “LEFT” data centre, applications can connect to the “RIGHT” data centre, and carry on from where they left off.
Producers can start producing again, still to TOPIC1 (but this time, a TOPIC1 that is hosted by a different cluster).
And consumers can start receiving messages again. Using a .*TOPIC1 wildcarded subscription means they’ll receive new messages produced directly to the “RIGHT” data centre (from TOPIC1) as well as any messages they hadn’t yet processed from the “LEFT” data centre (from LEFT.TOPIC1).
(If ordering is a concern, they could start by subscribing to LEFT.TOPIC1 and consume all of the messages from the “LEFT” data centre first. After there are no remaining messages they could then subscribe to TOPIC1 and start receiving new messages. Doing something like this means the message ordering should be consistent and predictable.)
Note that MirrorMaker 2 replicates consumer offsets as well as the TOPIC1 messages, so the consumer can use this to manage their state. This is how consuming applications are able to resume processing from the last offset they committed on the “LEFT” data centre.

Let me demonstrate how this all behaves by following a few messages through the system.
Imagine the producer sends message “0” to TOPIC1 on the “LEFT” Kafka cluster.

This will be received by the consumer.
A copy will also be made by MirrorMaker 2 to LEFT.TOPIC1 on the “RIGHT” Kafka cluster.

This will happen for each message that is produced.

In the event of an outage of the “LEFT” Kafka cluster (or the whole “LEFT” data centre), the applications can connect to the “RIGHT” Kafka cluster instead.

Now the producer will send messages to TOPIC1 on the “RIGHT” Kafka cluster.

These will be received by the consumer application.

And so on.

Messages that are produced directly to the “RIGHT” data centre are kept separate from messages that were copied across from the “LEFT” data centre.

This means that when the “LEFT” data centre is restored, MirrorMaker 2 is able copy the new messages (produced while “LEFT” was unavailable) back to the “LEFT” Kafka cluster.
Applications can stay using the “RIGHT” data centre (and start treating the “LEFT” Kafka cluster as the new backup copy – flipping the way that the two clusters are used).

Or, applications can switch back and reconnect to the “LEFT” Kafka cluster and start thinking about the “RIGHT” data centre as the copy again.
(As before, if the applications switch clusters, the way that MirrorMaker 2 copies consumer offsets across using the checkpoint connector allows state to be maintained after moving between clusters. And consuming from the remote copy first before the directly-produced topic can help to make message ordering predictable.)

After switching back, messages will be produced and consumed as before.
Summary
Let’s recap.
One approach is to think of MirrorMaker 2 as providing a single logical conceptual topic that is being hosted by multiple Kafka clusters. Applications can be configured to access this logical topic entirely from their own local Kafka cluster.
This is well suited to situations where client applications are co-located with the Kafka clusters. Also, as you can use all your clusters, you don’t need to worry about “wasting” resources running passive backup clusters.
In the event of an outage, processing will continue in the applications that are connected to the remaining Kafka clusters. And this happens automatically without needing to do anything to re-configure or re-start your client applications. This is particularly helpful when you have a large number of client applications.
But, message ordering on different clusters may not be consistent.
Another approach is to identify your clusters as active or passive, and use MirrorMaker 2 to maintain a passive backup copy that you can switch to in the event of an outage.
It’s well suited to situations where client applications are managed and hosted separately to the Kafka clusters, or situations where a predictable message ordering is more important.
In the event of an outage, applications do need some fiddly administration tasks – they need to disconnect from the unavailable Kafka cluster, and connect to the address of the passive backup cluster. Consumer applications will need to lookup the offset to resume from (but this is only a line or two of code) and if message ordering is a concern then there will need to be some application logic to consume from the backup topic before starting to consume from the local topic. If there are a large number of client applications, this can become onerous without some planning and automation.
More info
These are by no means the only scenarios that MirrorMaker 2 enables. They’re just two that we happened to discuss this week. But I think they give an idea of the sort of patterns that you can use. It’s often talked about as a disaster recovery tool, which it is useful for. But thinking of it as a general purpose way of moving messages between Kafka clusters opens up a variety of other use cases, such as enabling hub-and-spoke architectures as I hinted at above.
For more info, including specific steps for how to run MirrorMaker 2 for yourself, you can see:
IBM Event Streams documentation for “geo-replication”
We describe these sorts of use-cases as “geo-replication”. Event Streams sets up MirrorMaker 2 for you to make all of this as easy as possible, and adds some useful bits (like an administration UI for configuring and controlling it, and monitoring so you can check that MirrorMaker 2 is keeping up and get notified about the outage of a cluster).
Under the covers, we use MirrorMaker 2 to do this, so the concepts and code snippets shown in our docs will still be useful if you’re planning to set up MirrorMaker 2 yourself.
Strimzi blog post and documentation
Using the open source Strimzi Kafka Operator makes it much easier to run MirrorMaker 2. The Strimzi docs show you how you can get it all running.
The original KIP where MirrorMaker 2 was proposed, and still a good source for descriptions of how it all works.
Tags: apachekafka, eventstreams, ibmeventstreams, kafka
Hi Dale – Thanks for this informative blog on MM2 (https://dalelane.co.uk/blog/?p=4074). It doesn’t look like one can subscribe to wild card topics (“.*topic1) as you suggest above. Can you kindly clarify if this possible or not. Looks like Kafka doesn’t allow it, but I’m not 100% sure.
Thank you in advance!
Best,
Prem
The way you do it will vary depending on the client library and programming language you’re using, but for a Java example, see https://kafka.apache.org/26/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html#subscribe-java.util.regex.Pattern-org.apache.kafka.clients.consumer.ConsumerRebalanceListener-
Thank you for the remarkable writing. Finally, there is an HA solution for strongly-ordered Kafka topics.
Superbly explained. Thanks Dale.