In this post, I share a few examples for how to run Event Gateways for Event Endpoint Management.
When we talk about Event Endpoint Management, we often draw logical diagrams like this, with Kafka client applications able to produce and consume events to back-end Kafka clusters via an Event Gateway.
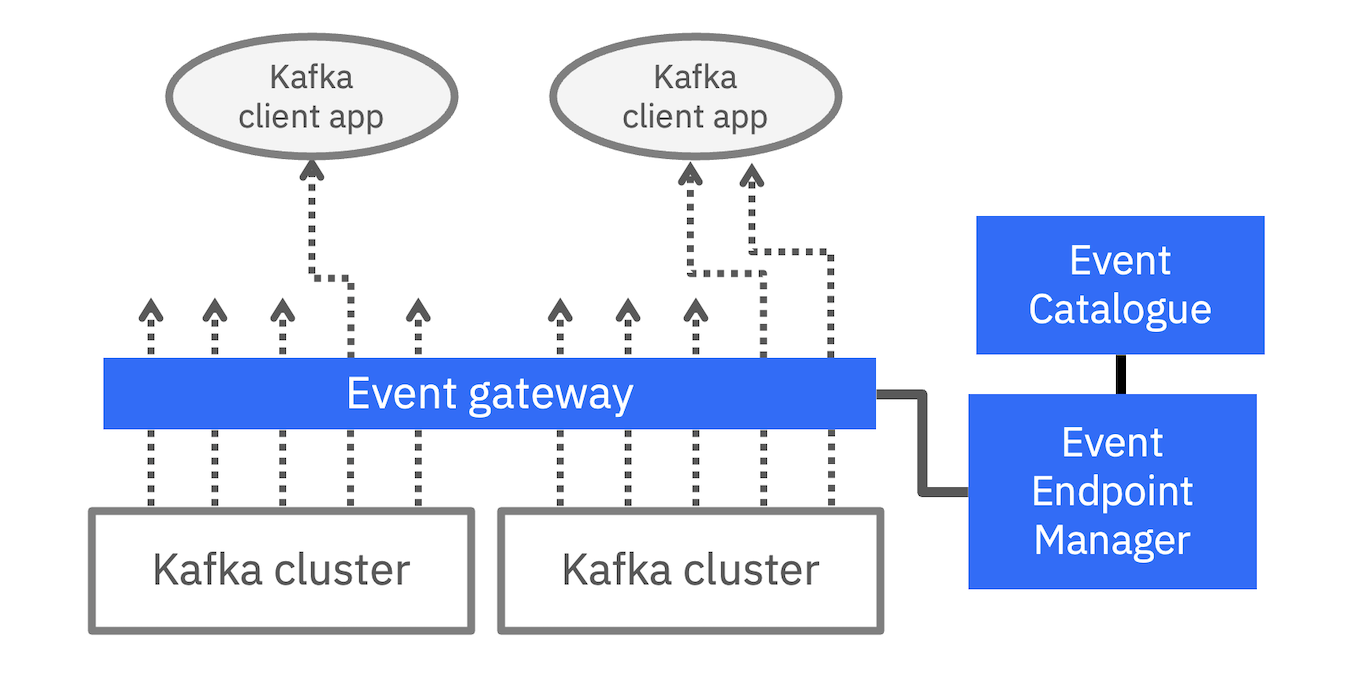
When it comes to start planning a deployment, we need to make decisions about the best way to create that logical Event Gateway layer. This typically includes running multiple gateways, but there are many different ways to do this, depending on your requirements for scaling and availability.
For this post, I want to show two approaches for running two Event Gateways, as a way of illustrating the kind of topologies that are possible.
Example 1 – more gateways
When creating an EventGateway instance, the replicas property can be used to request multiple instances of the gateway.
apiVersion: events.ibm.com/v1beta1
kind: EventGateway
metadata:
name: my-eem-gateway
namespace: environment-one
spec:
gatewayGroupName: gateway-group
gatewayID: gateway-1
replicas: 2
managerEndpoint: 'https://my-eem-manager-ibm-eem-gateway-event-automation.apps.dale-lane.cp.fyre.ibm.com'
tls:
caSecretName: my-eem-manager-ibm-eem-manager-ca
license:
accept: true
license: L-HRZF-DWHH7A
metric: VIRTUAL_PROCESSOR_CORE
use: EventAutomationNonProduction
This will result in the Operator deploying multiple pods which will collectively provide the Gateway service.
% oc get pods --all-namespaces -l "app.kubernetes.io/instance=my-eem-gateway" NAMESPACE NAME READY STATUS RESTARTS AGE environment-one my-eem-gateway-ibm-egw-gateway-5464fb95-mx5zr 1/1 Running 0 29m environment-one my-eem-gateway-ibm-egw-gateway-5464fb95-wk4k6 1/1 Running 0 29m
This will be displayed in the Event Endpoint Manager catalog as a single address.
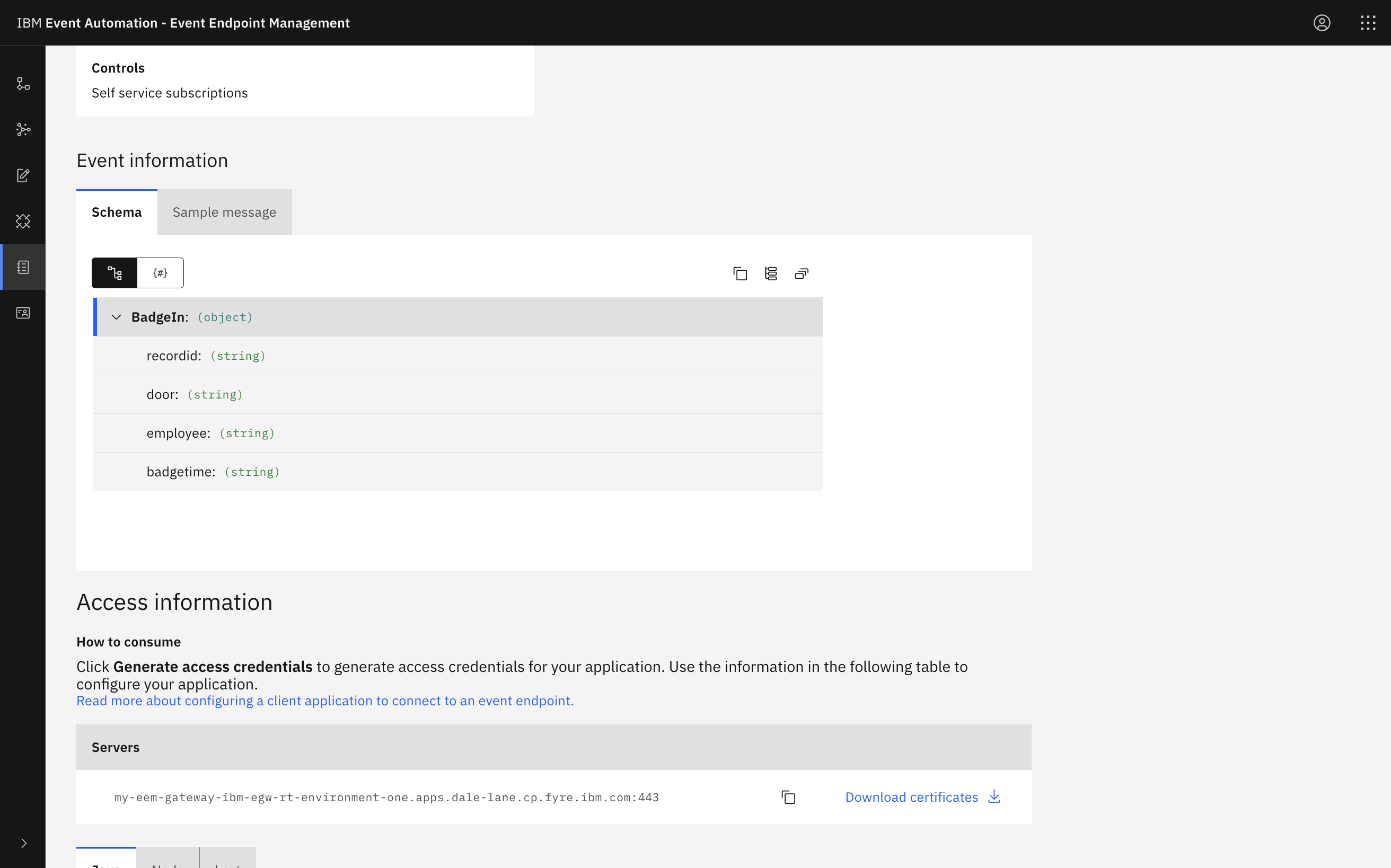
Click on the image for a larger version
At a simplified level, this is what is created as a result. The routes configured to front the gateway pods are configured to route requests to both / either of the replicas.
(Routes are what are created when running in Red Hat OpenShift, but the same can be achieved using ingress on other Kubernetes distributions.)
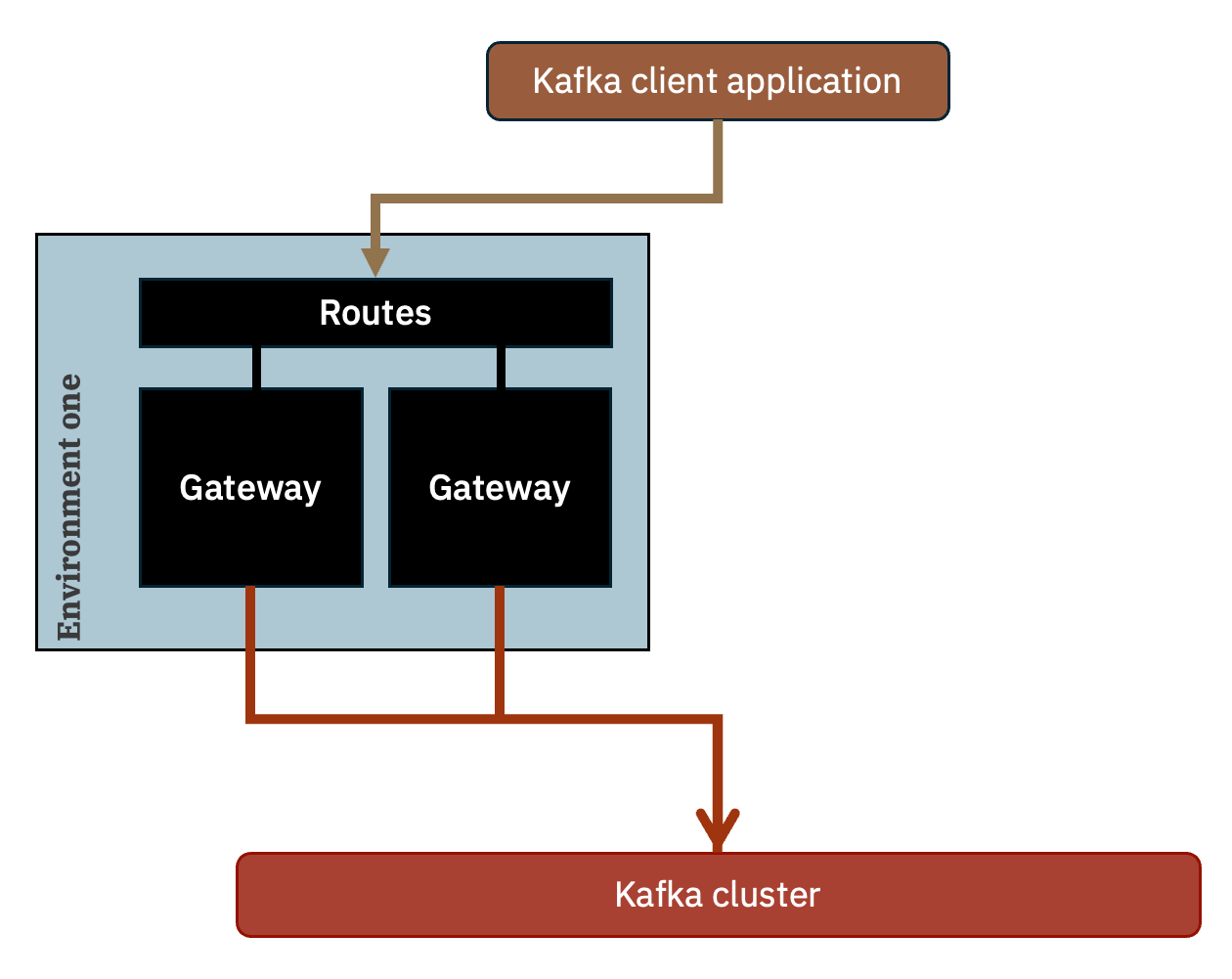
When you run a Kafka consumer or producer, you configure it with bootstrap.servers set to the single bootstrap address being used by both the gateway replicas.
bootstrap.servers=my-eem-gateway-ibm-egw-rt-environment-one.apps.dale-lane.cp.fyre.ibm.com:443
The Route will route the connection to one of the gateway pods, which will proxy the connection to the back-end Kafka cluster.
One benefit of doing this could be scaling, with multiple gateway pods collectively handling requests to the gateway routes.
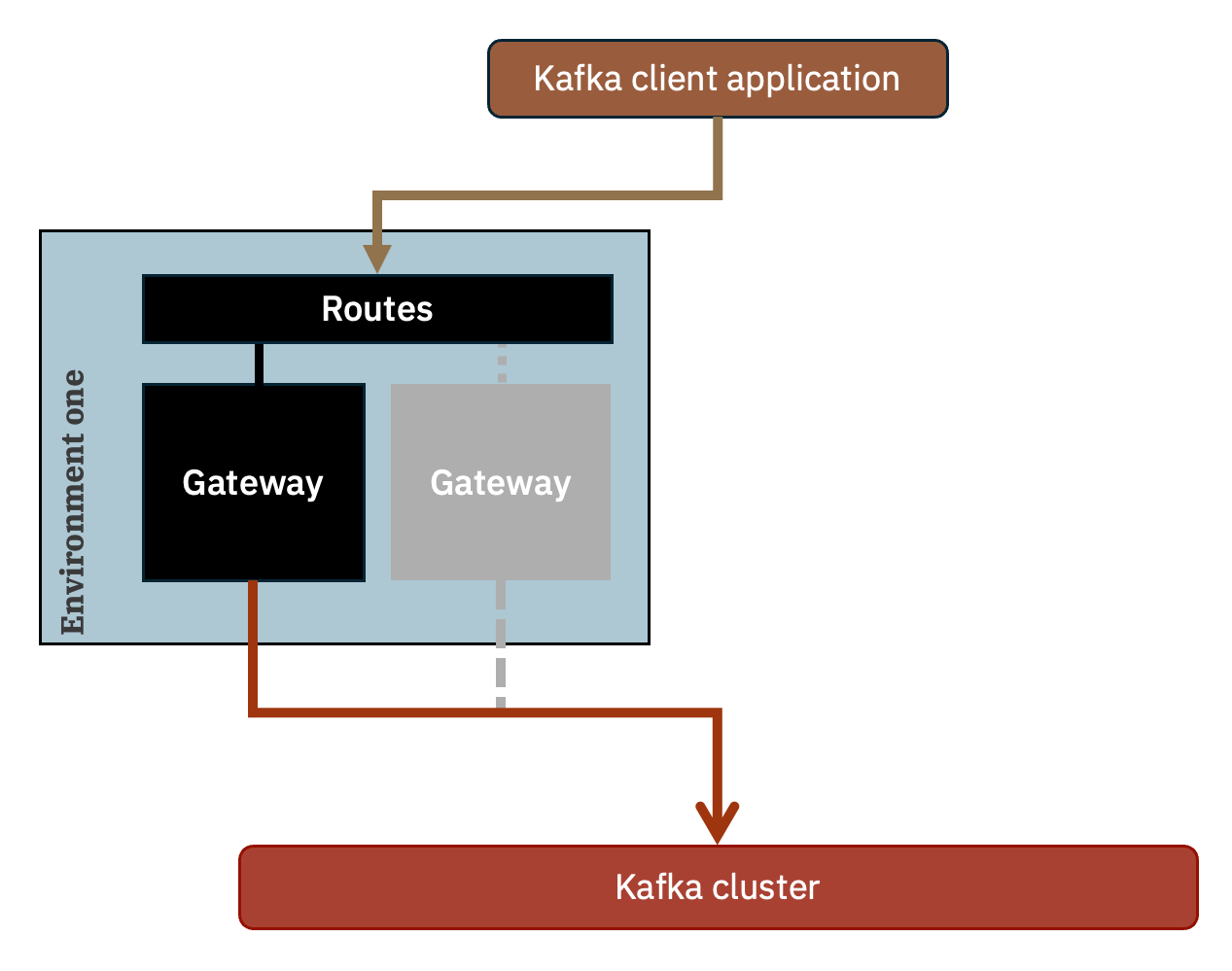
Another benefit is availability. It is useful if anything happens to cause the gateway pod (that is handling the connection for a client application) to become unavailable. This could be due to an unexpected error, or simply due to a scheduled restart to apply maintenance.
In such circumstances, Kafka client applications will automatically attempt to reconnect, and the same Routes will automatically route the connection to the remaining available gateway pod.
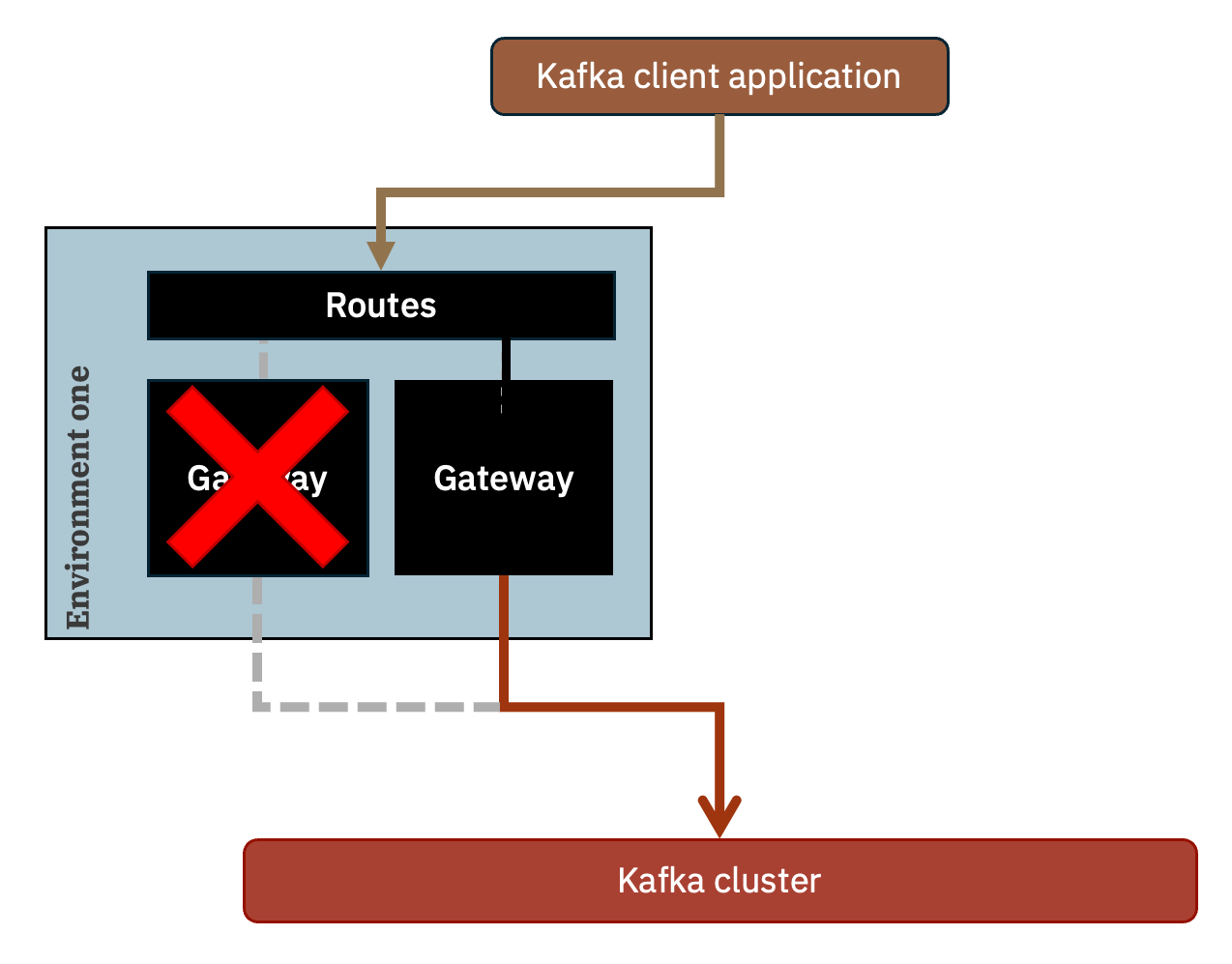
This means applications continue running without needing any administrative intervention.
Example 2 – gateways in more locations
Alternatively, the two gateways can each be created in different environments.
(For this simple example, I’m using Kubernetes namespaces to represent different environments, but this would work in the same way if I had used different Kubernetes clusters running in different availability zones.).
This can be achieved by creating two EventGateway instances, each with a unique gatewayID.
Specifying a common gatewayGroupName value indicates that the two gateway pods are part of the same logical group.
apiVersion: events.ibm.com/v1beta1
kind: EventGateway
metadata:
name: my-eem-gateway
namespace: environment-one
spec:
gatewayGroupName: gateway-group
gatewayID: gateway-1
replicas: 1
managerEndpoint: 'https://my-eem-manager-ibm-eem-gateway-event-automation.apps.dale-lane.cp.fyre.ibm.com'
tls:
caSecretName: my-eem-manager-ibm-eem-manager-ca
license:
accept: true
license: L-HRZF-DWHH7A
metric: VIRTUAL_PROCESSOR_CORE
use: EventAutomationNonProduction
apiVersion: events.ibm.com/v1beta1
kind: EventGateway
metadata:
name: my-eem-gateway
namespace: environment-two
spec:
gatewayGroupName: gateway-group
gatewayID: gateway-2
replicas: 1
managerEndpoint: 'https://my-eem-manager-ibm-eem-gateway-event-automation.apps.dale-lane.cp.fyre.ibm.com'
tls:
caSecretName: my-eem-manager-ibm-eem-manager-ca
license:
accept: true
license: L-HRZF-DWHH7A
metric: VIRTUAL_PROCESSOR_CORE
use: EventAutomationNonProduction
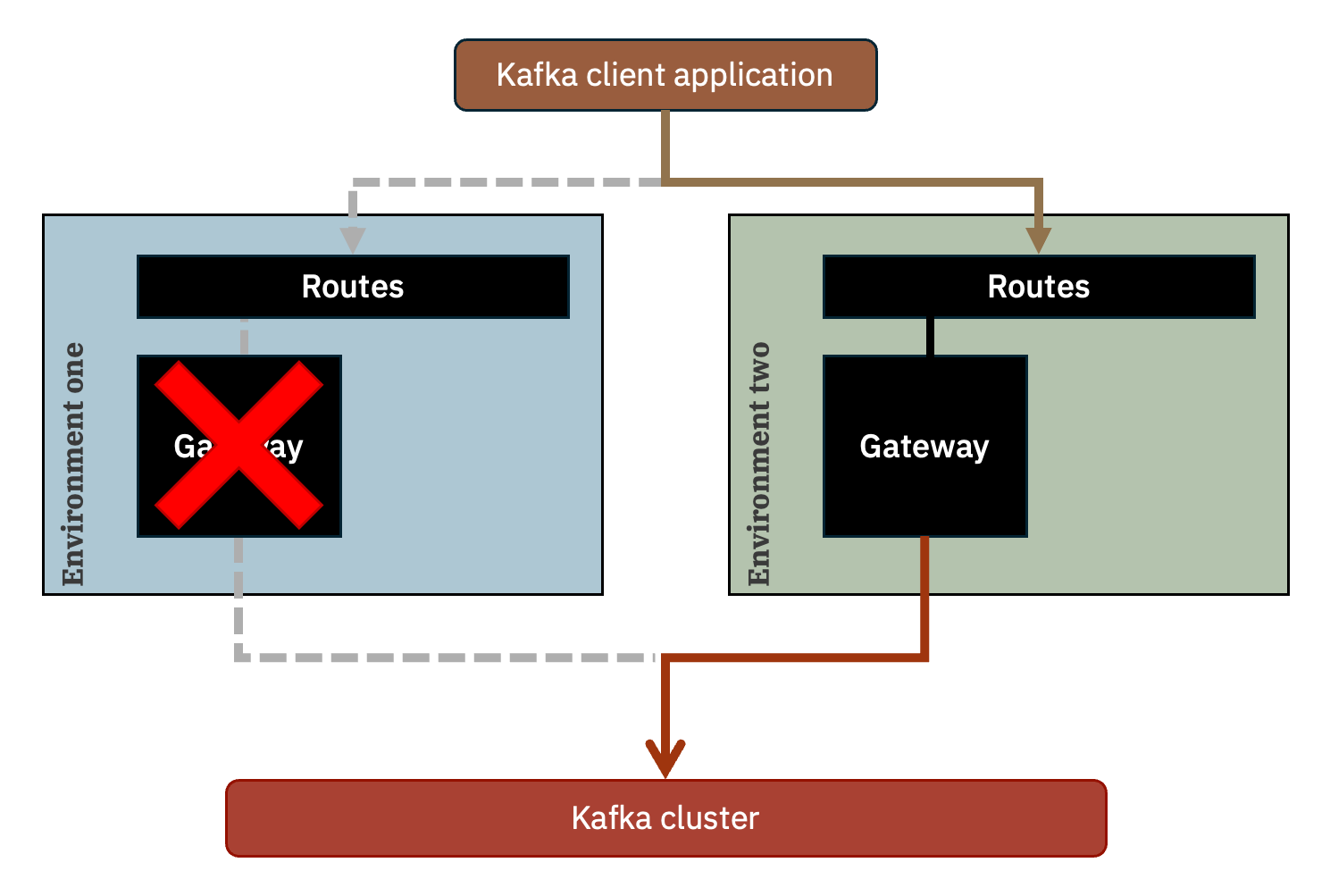
This results in the Operator deploying a gateway pod in each of the EventGateway locations.
(Again, I’m using namespaces to represent environments – if doing this for real, it would more likely be different clusters.)
% oc get pods --all-namespaces -l "app.kubernetes.io/instance=my-eem-gateway" NAMESPACE NAME READY STATUS RESTARTS AGE environment-one my-eem-gateway-ibm-egw-gateway-9b7458c5f-pqjpl 1/1 Running 0 3m1s environment-two my-eem-gateway-ibm-egw-gateway-7f954b486-cxsrj 1/1 Running 0 3m10s
This will be displayed in the Event Endpoint manager catalog as separate addresses, one for each environment.
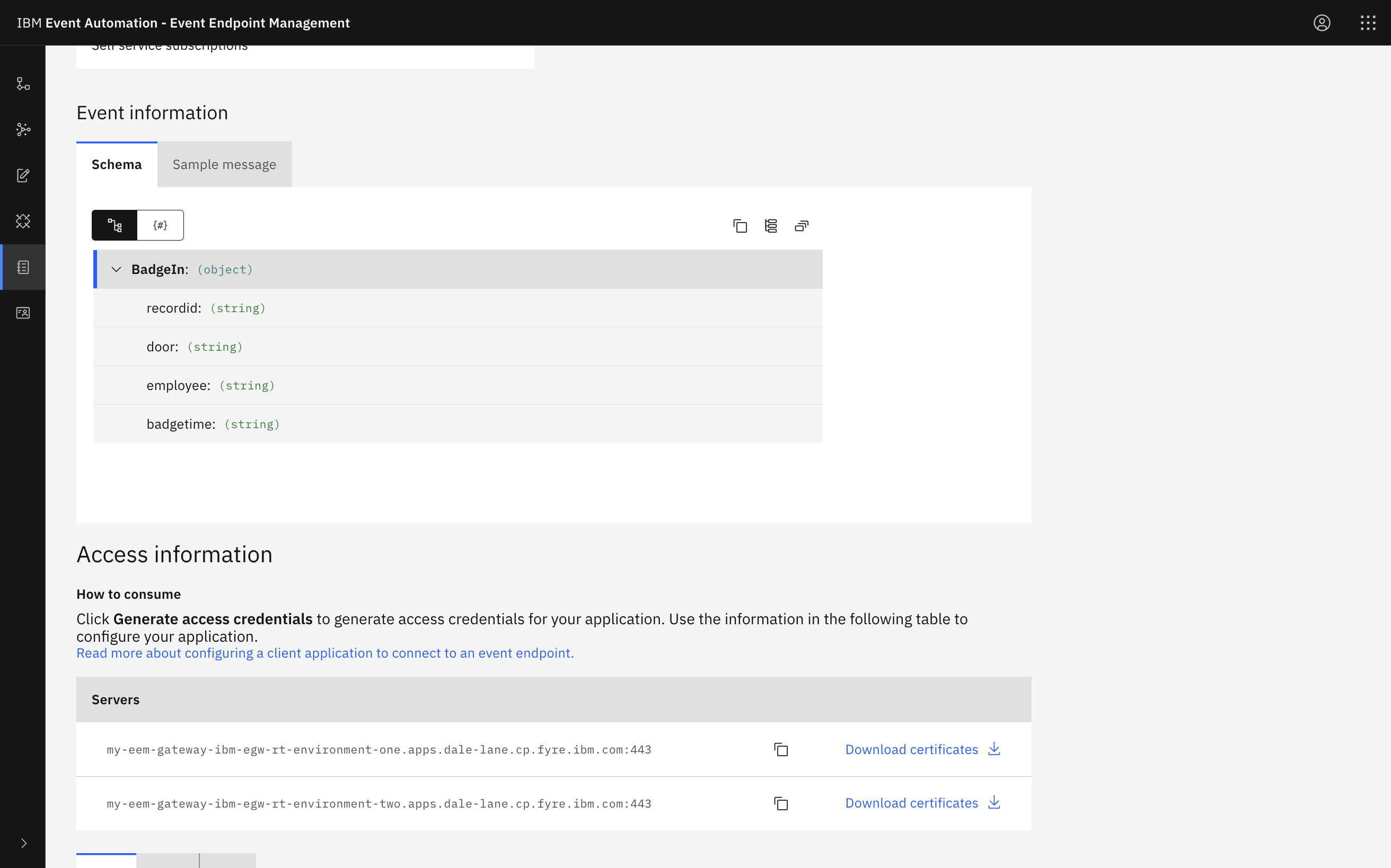
Click on the image for a larger version
At a simplified level, this is what is created as a result. Each gateway deployment has it’s own collection of Routes fronting the connections to the gateway pod.
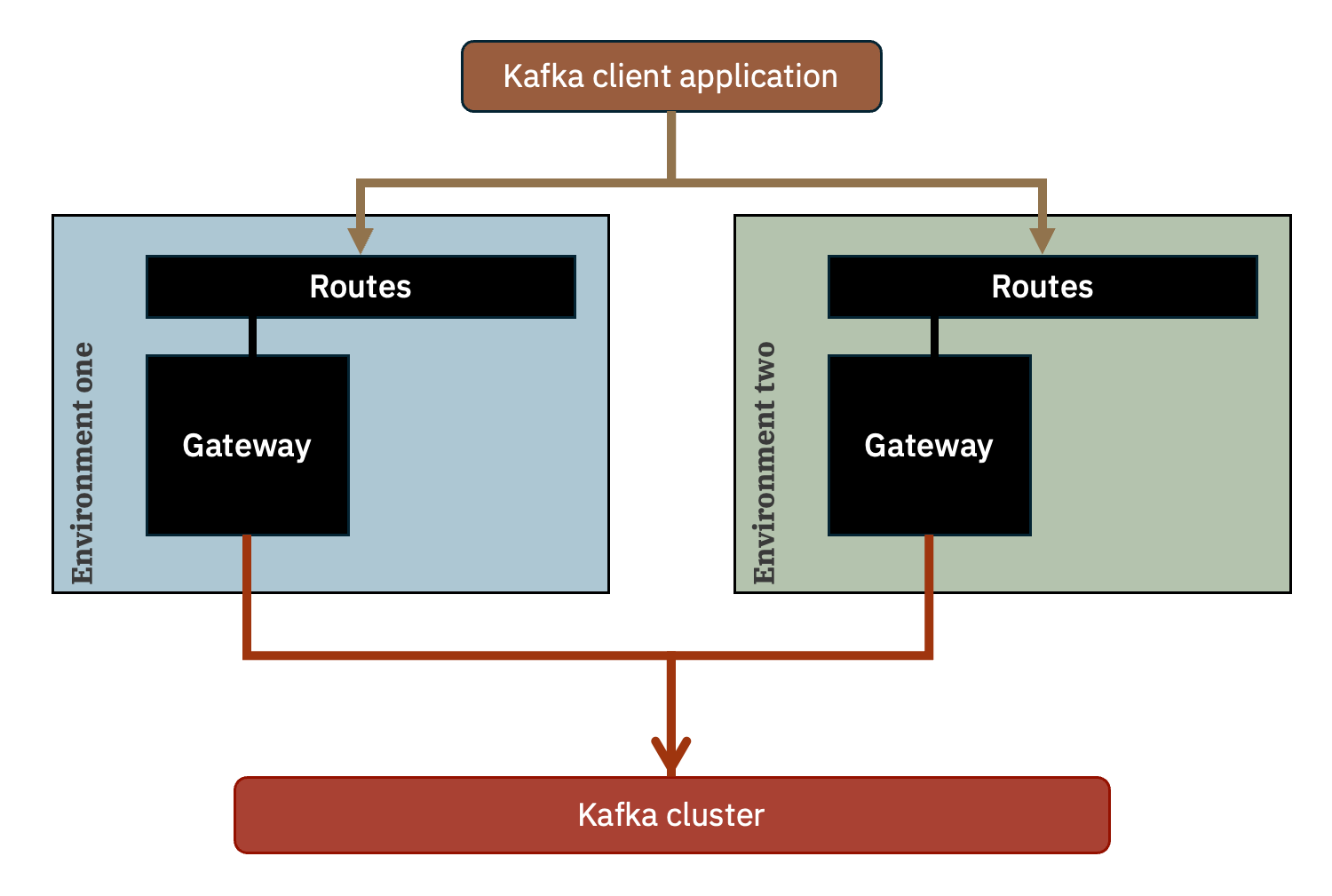
When you run a Kafka consumer or producer, you configure it with bootstrap.servers set to a comma-separated list of both of the gateway addresses.
bootstrap.servers=my-eem-gateway-ibm-egw-rt-environment-one.apps.dale-lane.cp.fyre.ibm.com:443,my-eem-gateway-ibm-egw-rt-environment-two.apps.dale-lane.cp.fyre.ibm.com:443
Kafka clients will attempt to connect to the first address in the comma-separated list. If that connection is unsuccessful, it will retry with the next address in the list. This continues until it has made a successful connection, or it has tried every address in the list.
This normal Kafka behaviour means you can choose how to use the two gateway environments.
Configuring the Kafka application to randomize the order of addresses in the bootstrap.servers list means it will randomize which environment the application uses to connect to the Kafka cluster via.
Configuring the Kafka application with bootstrap.servers set to environment-one,environment-two as above means that all connections will be made to the gateway running in environment one.
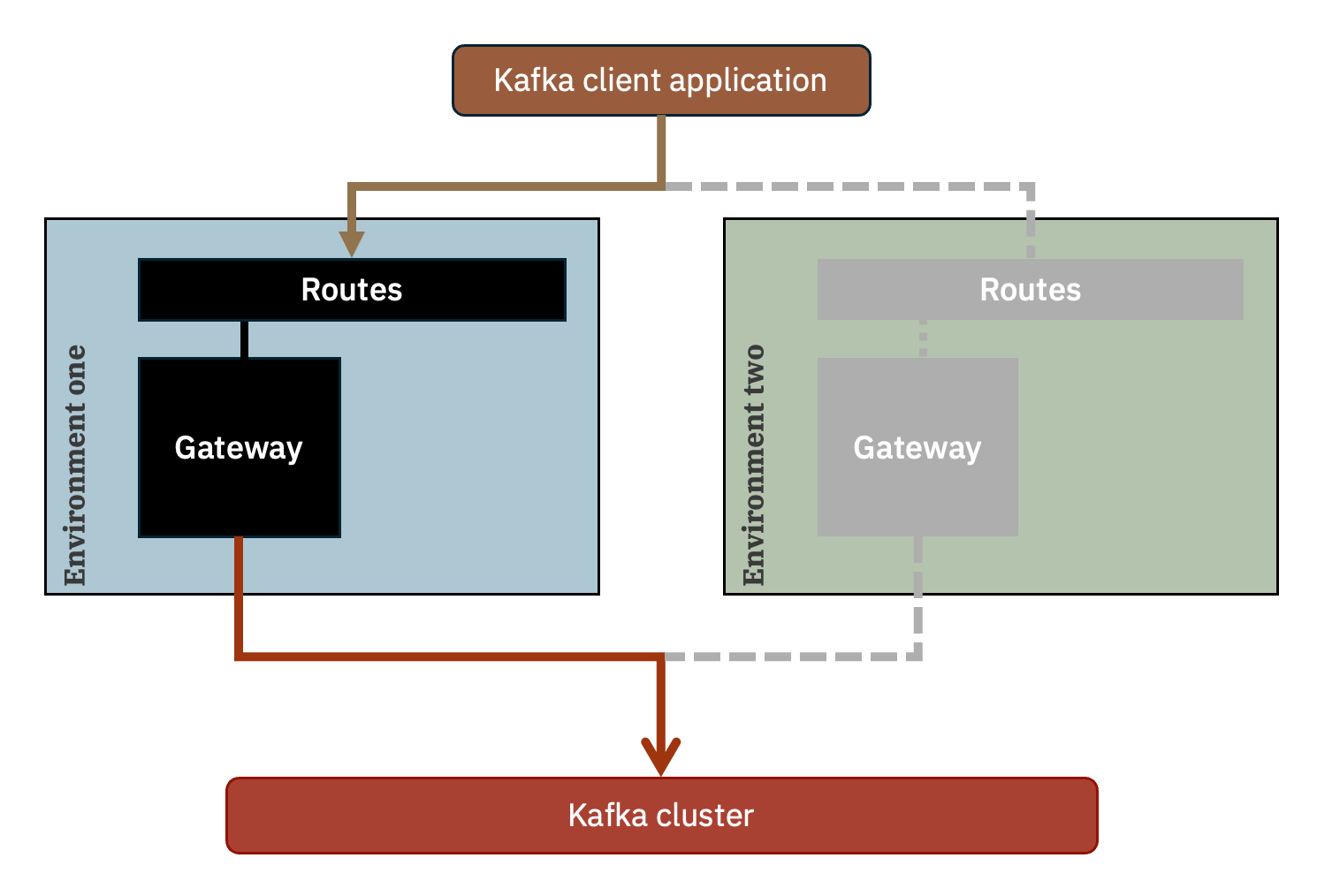
If anything happens to make the gateway in environment one unavailable (whether due to an unexpected or scheduled restart), Kafka client applications will automatically reconnect to the next address in the list, and start using the gateway in environment two.
This means applications continue running without needing any administrative intervention.
Example 3 – more gateways in more locations
These are just two examples of several topologies that can be created. For example, combining the two approaches described above would result in something like this – running Event Gateways in multiple environments, with multiple replicas in each environment.
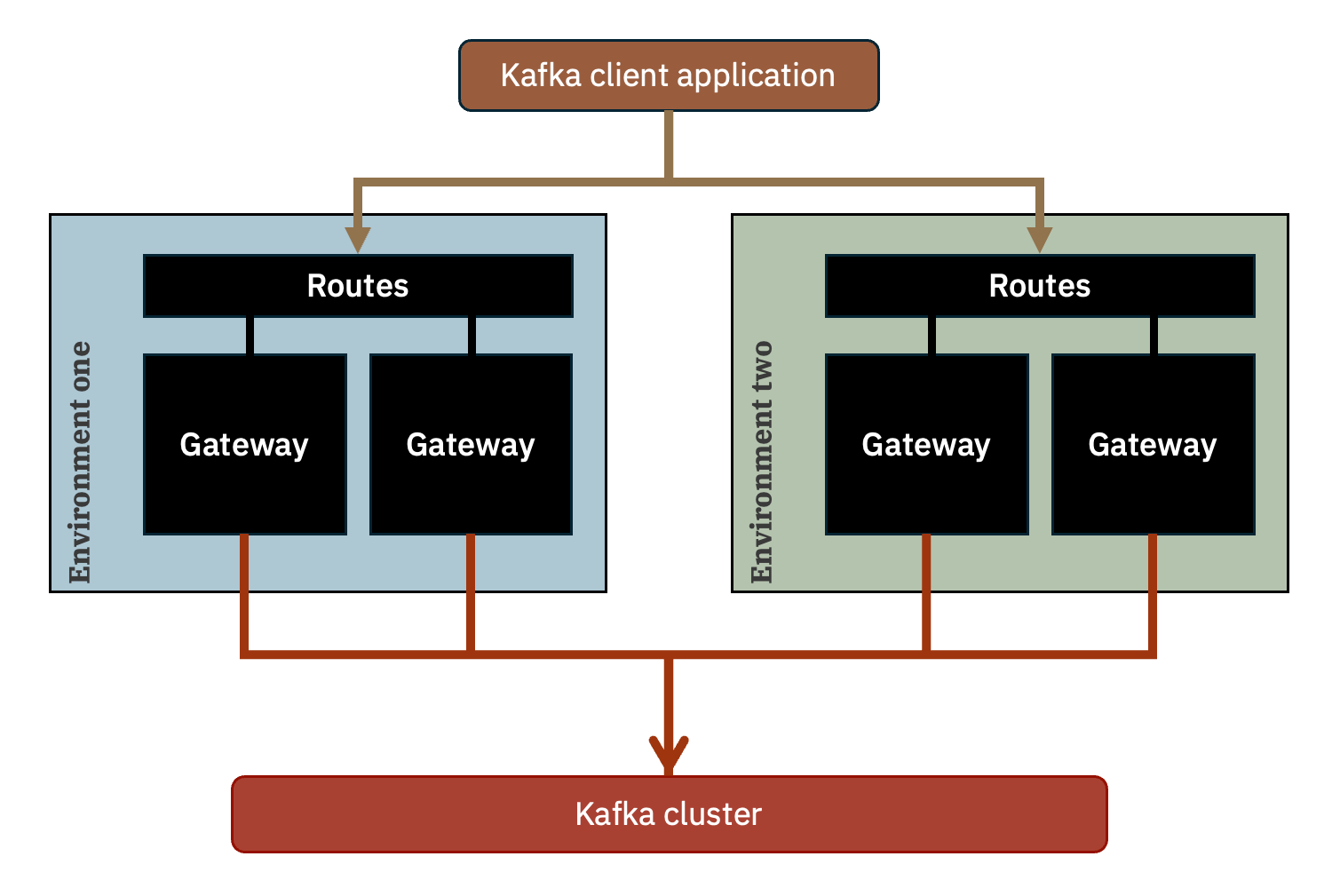
The ideal topology for any project will depend on the availability and throughput requirements for that project, but these examples will hopefully show you the kinds of options available.
Tags: apachekafka, kafka