You’ve discovered a topic in the IBM Event Endpoint Management catalog that someone in your company has shared. It looks useful, so you want to use that stream of events to maintain a local projection in your database.
Or maybe you’ve discovered a topic in the Catalog that is available to produce to, and you want to contribute events to it from your MQ queue.
What are the options for using Kafka Connect to produce to, or consume from, topics that you discover in Event Endpoint Management?
In this post, we’ll share options that you can consider, and briefly outline the pros and cons of each.
Co-written with Andrew Borley
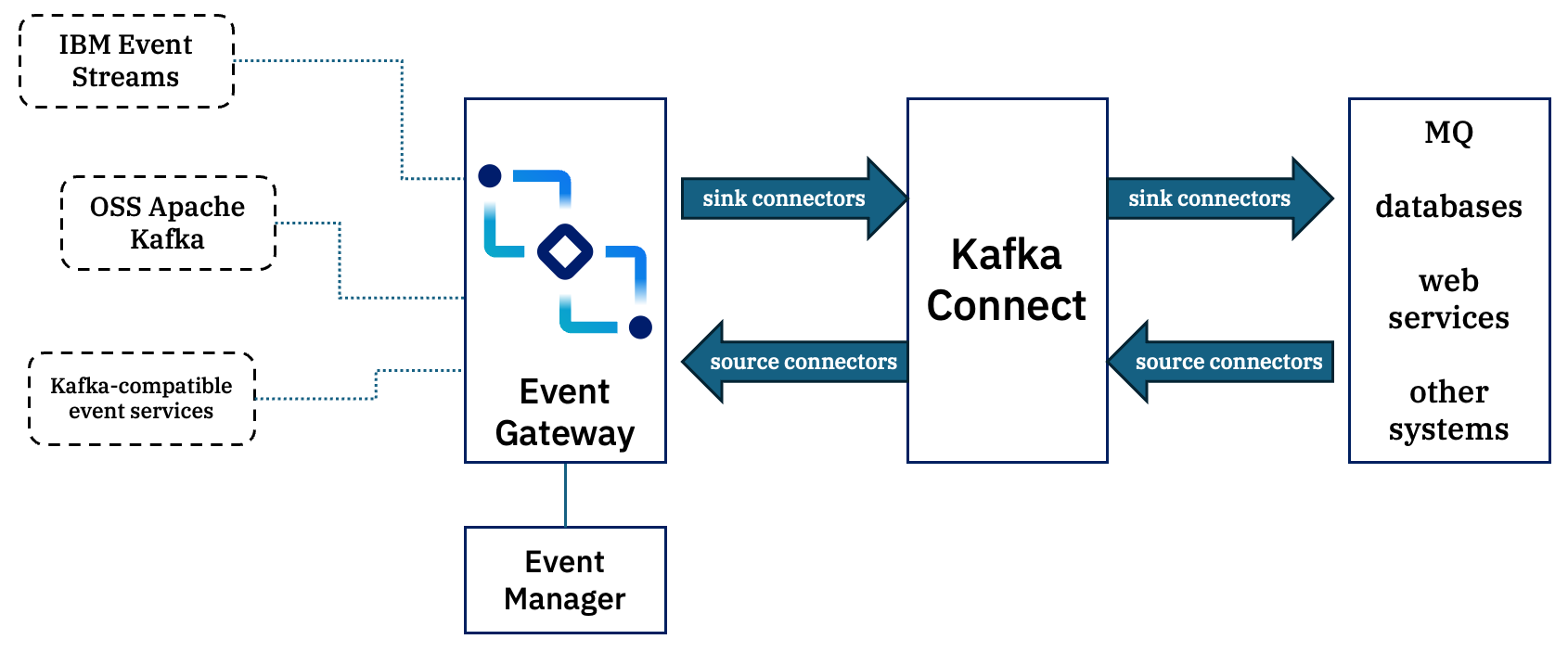
Connect typically uses multiple Kafka topics
First, a quick reminder about how Kafka Connect works, and why this is a factor if you want to use it with Event Endpoint Management.
A Kafka Connect runtime can support and manage a wide variety of connectors – bringing events from external systems into Kafka, or sending data from Kafka to external systems.
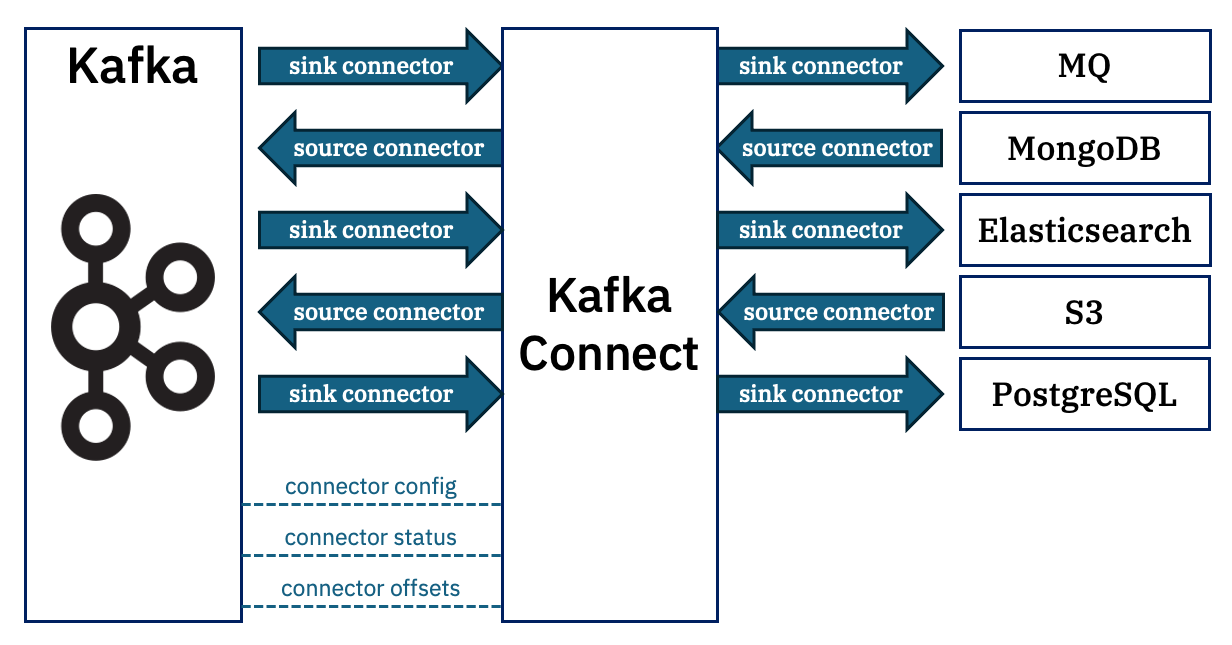
In addition to those topics that individual connectors interact with, Connect also uses a few topics to store information:
– one topic stores the configuration for the connectors it is managing
– another topic stores the current status of the connectors
– a third topic stores the progress that each connector has made so far to allow them to resume after a restart
When you use Event Endpoint Management, you have the self-service opportunity to create individual credentials for a single, specific topic that you’ve discovered from another team’s Kafka cluster.
But that doesn’t let you use their Kafka cluster for your Connect runtime to also store it’s config, status, and offsets.
So what can you do instead?
Option 1 – Using an existing Kafka Connect runtime
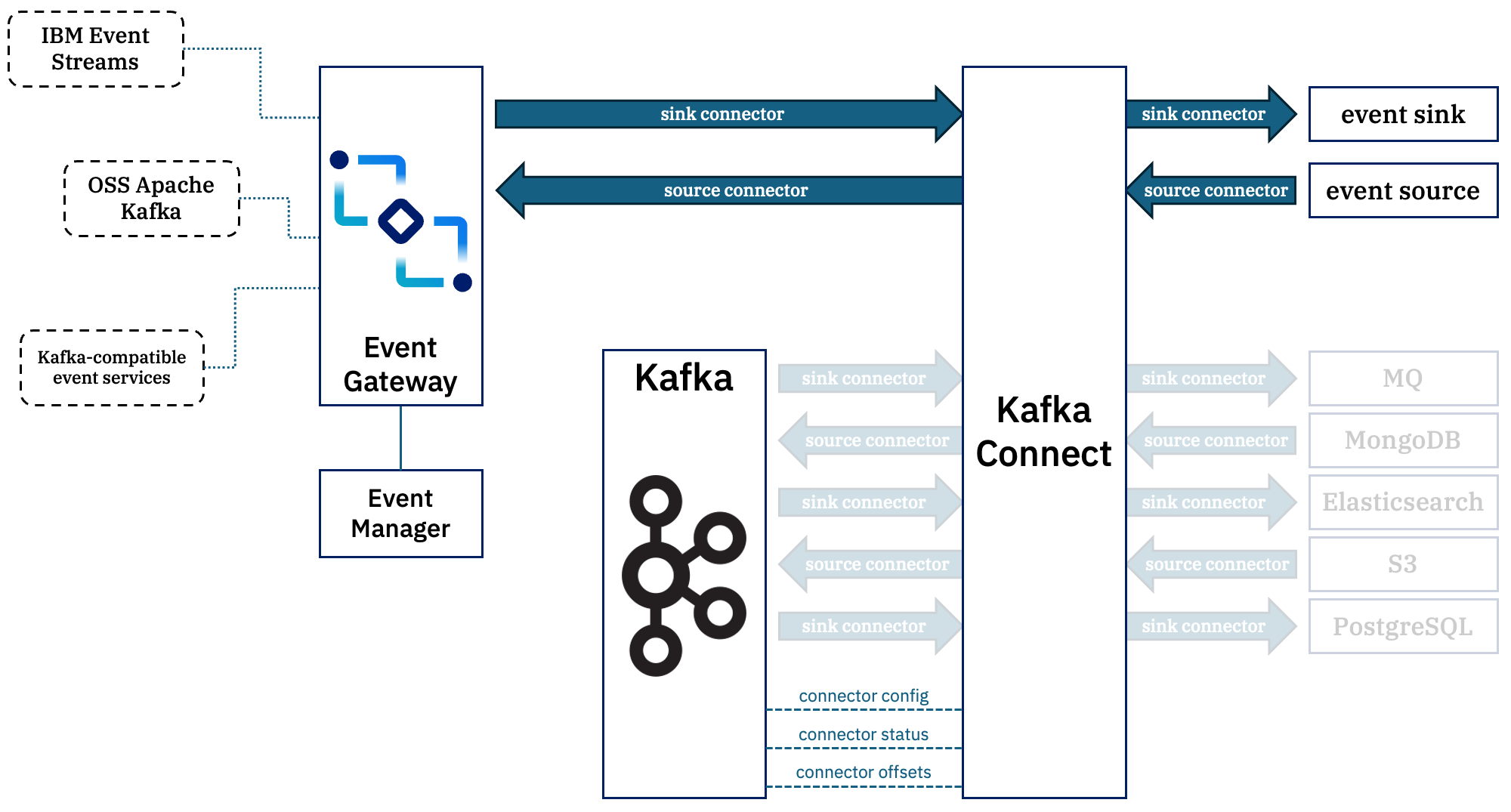
If you are already using Kafka Connect, running existing Connectors with your own Kafka cluster, then it is simple for you to continue using that.
Your Connect runtime will continue to use your own Kafka cluster to store it’s config, status, and offsets.
apiVersion: eventstreams.ibm.com/v1beta2
kind: KafkaConnect
metadata:
annotations:
eventstreams.ibm.com/use-connector-resources: 'true'
name: your-kafka-connect
spec:
config:
group.id: your-kafka-connect
client.id: your-kafka-connect
config.storage.topic: connect-configs
offset.storage.topic: connect-offsets
status.storage.topic: connect-status
bootstrapServers: 'your-kafka-cluster-bootstrap:9092'
authentication:
type: scram-sha-512
username: your-kafka-cluster-credentials
passwordSecret:
password: password
secretName: your-kafka-cluster-credentials
tls:
trustedCertificates:
- certificate: ca.crt
secretName: your-kafka-cluster-ca-cert
externalConfiguration:
volumes:
- name: eem-cert
secret:
secretName: eem-gateway-ca-cert
...
Most of your sink and source connectors will be consuming and producing using topics in your own Kafka cluster.
Individual source connectors can be configured to produce to topics that you discover in Event Endpoint Management by using `producer.override.`.
apiVersion: eventstreams.ibm.com/v1beta2
kind: KafkaConnector
metadata:
name: source-connector-to-eem-topic
labels:
eventstreams.ibm.com/cluster: your-kafka-connect
spec:
class: com.acme.externalsystem.SomeSourceConnector
config:
acme.externalsystem.source.config: config-values
...
topic: EEM.PRODUCER.TOPIC
producer.override.sasl.mechanism: PLAIN
producer.override.sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="eem-e2cb10d0-74ec-45ee-9741-c185b20059c3" password="60b2dae1-d663-4a3c-8b1f-1e2475150616";
producer.override.bootstrap.servers: 'eem-gateway-address:443'
producer.override.security.protocol: SASL_SSL
producer.override.ssl.truststore.location: /opt/kafka/external-configuration/eem-cert/eem-truststore.jks
producer.override.ssl.truststore.type: JKS
producer.override.ssl.truststore.password: truststorepwd
producer.override.ssl.protocol: TLSv1.3
Individual sink connectors can be configured to consume from topics that you discover in Event Endpoint Management by using `consumer.override.`.
apiVersion: eventstreams.ibm.com/v1beta2
kind: KafkaConnector
metadata:
name: sink-connector-from-eem-topic
labels:
eventstreams.ibm.com/cluster: your-kafka-connect
spec:
class: com.acme.externalsystem.SomeSinkConnector
config:
acme.externalsystem.sink.config: config-values
...
topics: EEM.CONSUMER.TOPIC
consumer.override.sasl.mechanism: PLAIN
consumer.override.sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="eem-e2cb10d0-74ec-45ee-9741-c185b20059c3" password="60b2dae1-d663-4a3c-8b1f-1e2475150616";
consumer.override.bootstrap.servers: 'eem-gateway-address:443'
consumer.override.security.protocol: SASL_SSL
consumer.override.ssl.truststore.location: /opt/kafka/external-configuration/eem-cert/eem-truststore.jks
consumer.override.ssl.truststore.type: JKS
consumer.override.ssl.truststore.password: truststorepwd
consumer.override.ssl.protocol: TLSv1.3
Benefits
This approach is a good fit if you are already using your own Kafka cluster for your own applications and microservices, and are looking to use some additional select topics that you have found in the Event Endpoint Management Catalog.
This is because you already have a Kafka cluster that you can use for Connect to store it’s state in, and can just use the Event Gateway for individual select source and sink topics.
Challenges
This approach is less appropriate if you don’t have a Kafka cluster, as the overhead of creating a new Kafka cluster solely to host a few state topics for Connect is likely onerous.
Option 2 – Using Kafka Connect in standalone mode
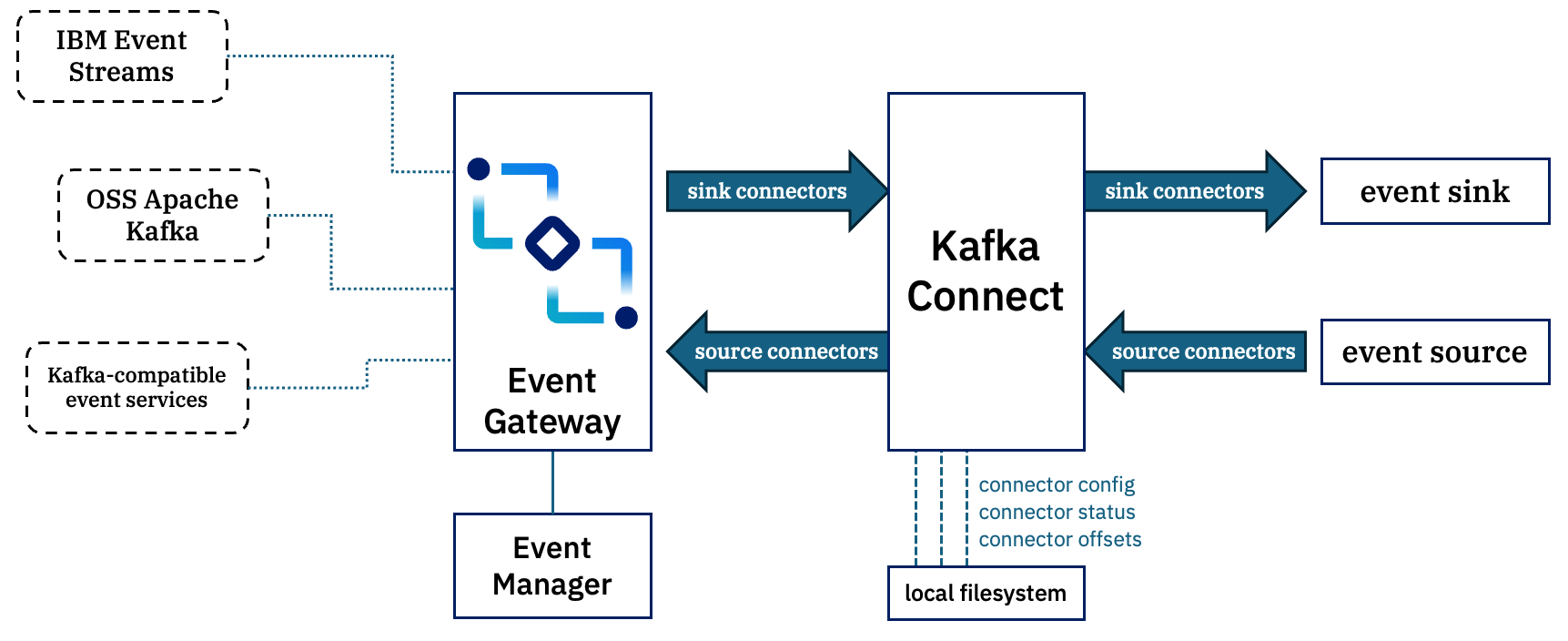
If you are not already running Kafka Connect, and are going to be deploying it solely for using topics that you discover in Event Endpoint Management, then it may be more appropriate to run Connect in standalone mode.
In this mode, Kafka Connect uses its local filesystem to store config, status, and progress offsets in a file on the local disk.
offset.storage.file.filename=/location/connect.state bootstrap.servers=eem-gateway-address:443 sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="eem-e2cb10d0-74ec-45ee-9741-c185b20059c3" password="60b2dae1-d663-4a3c-8b1f-1e2475150616"; security.protocol=SASL_SSL ssl.truststore.location=eem-truststore.jks ssl.truststore.type=JKS ssl.truststore.password=truststorepwd ssl.protocol=TLSv1.3 key.converter=org.apache.kafka.connect.storage.StringConverter key.converter.schemas.enable=false value.converter=org.apache.kafka.connect.storage.StringConverter value.converter.schemas.enable=false
Individual source or sink connectors can identify the topic that they want to use, and it will use the credentials from the Event Endpoint Management catalog that you have put in the Connect properties config.
connector.class=com.acme.externalsystem.SomeSinkConnector acme.externalsystem.sink.config=config-values topics=EEM.CONSUMER.TOPIC
connector.class=com.acme.externalsystem.SomeSourceConnector acme.externalsystem.source.config=config-values topic=EEM.PRODUCER.TOPIC
Benefits
This approach is a good fit if you are don’t have access to another Kafka cluster, other than the topics you find in Event Endpoint Management.
Challenges
Running Connect in a standalone mode like this requires a little more effort. You will need to consider issues such as how to restart it if it crashes. You will need to ensure that the file used to store config and state is safe and highly available. All of these are things that are handled for you when running managed Kafka Connect clusters.
This approach also restricts you from being able to distribute multiple Connect tasks across multiple workers, as you are running the whole connector within a single Java process. As a result, it may not be optimal for high-throughput connectors that would benefit from being parallelised across multiple workers.
Option 3 – Using Mirror Maker 2 to maintain a local copy
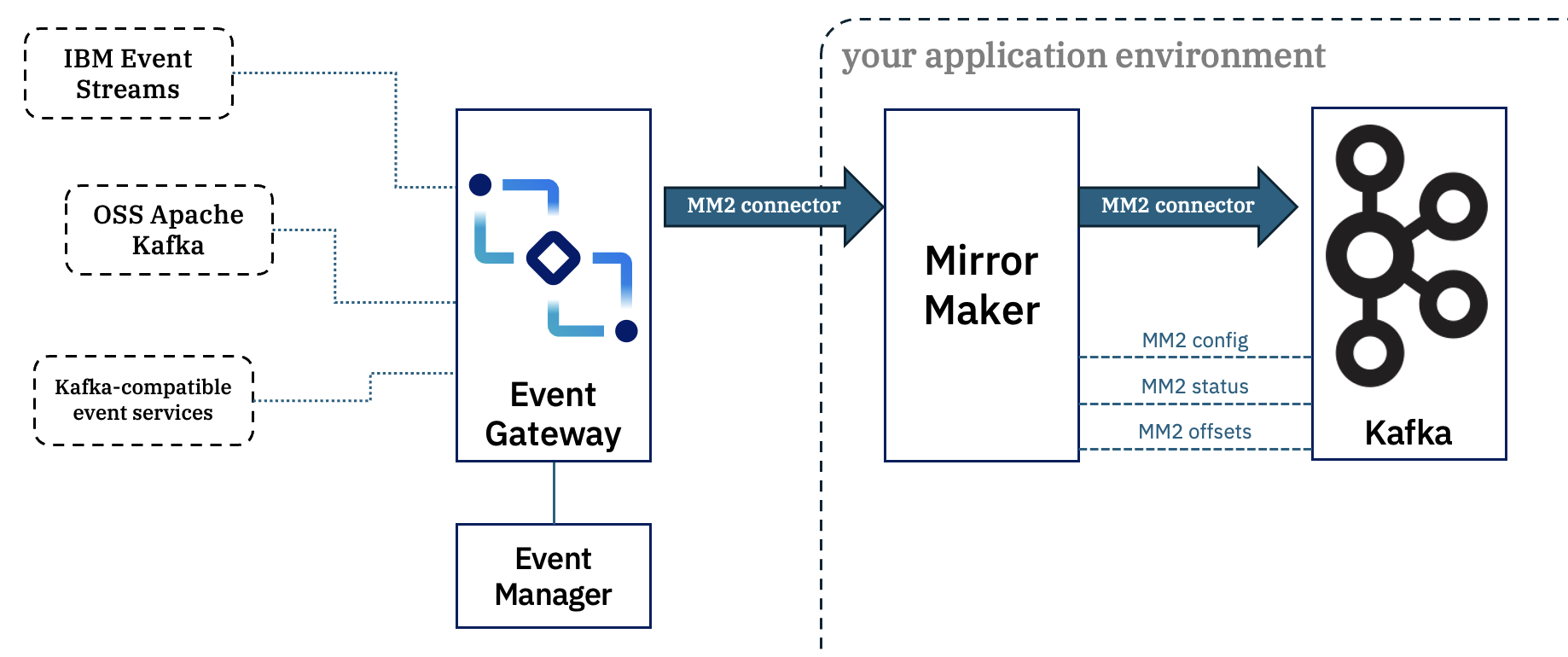
This is a special-case variant of option 1, but is an interesting use case to call out.
Consider that you’ve found a topic in the Event Endpoint Management catalog that you think looks useful or interesting for your own application(s).
You could get your application(s) to consume directly from the Event Gateway, and that is the typical way people use topics from Event Endpoint Management.
However, in some situations you may prefer to have your own local copy of the topic for your local applications to consume from.
This can be achieved by running Mirror Maker 2, with the credentials and certificates that you obtain from Event Endpoint Management.
kind: KafkaMirrorMaker2
apiVersion: eventstreams.ibm.com/v1beta2
metadata:
name: mirror-eem
spec:
# run Mirror Maker with the local mirror
connectCluster: local-mirror
clusters:
# the Event Endpoint Management gateway where a topic was found
- alias: event-endpoint-management
bootstrapServers: eem-gateway-address:443
authentication:
username: eem-7ea2c1b7-229d-4acd-b019-2a9e7326df65
passwordSecret:
password: password
secretName: eem-username
type: plain
tls:
trustedCertificates:
- certificate: eem-ca.pem
secretName: eem-ca-cert
# your local mirror where you want to maintain a copy of the EEM topic
- alias: local-mirror
bootstrapServers: local-mirror-kafka-bootstrap:9094
authentication:
username: local-mirror-user
passwordSecret:
password: password
secretName: local-mirror-user
type: scram-sha-512
tls:
trustedCertificates:
- certificate: ca.crt
secretName: local-mirror-cluster-ca-cert
mirrors:
- sourceCluster: event-endpoint-management
targetCluster: local-mirror
topicsPattern: EEM.CONSUMER.TOPIC
sourceConnector:
config:
# use topics on the local mirror to store offset mappings
offset-syncs.topic.location: target
offset-syncs.topic.replication.factor: 1
# only a single topic will be mirrored so no need to refresh list
refresh.topics.enabled: false
# don't try to mimic the ACLs provided by EEM
sync.topic.acls.enabled: false
...
Benefits
Maintaining a local clone of a topic is beneficial if your network connection to the Event Gateway is slow and/or expensive. This is particularly valuable if you intend to repeatedly re-consume events on the topic multiple times, and/or from many different client applications.
This pattern allows you to fetch the data from the remote cluster (through the Event Gateway) once only, which you can then repeatedly consume from locally.
More generally, the idea here is that Mirror Maker can be used to maintain a local clone of a topic that you discover in the Catalog, that you are then free to do with as you wish.
Challenges
As with Option 1 above, the cost of this pattern is that you need to run your own local Kafka cluster, however if you already have this, then it is worth considering.
Tags: apachekafka, kafka