In this post, I want to share the most recent section I’ve added to Machine Learning for Kids: support for generating text and an explanation of some of the ideas behind large language models.
After launching the feature, I recorded a video using it. It turned into a 45 minute end-to-end walkthrough… longer than I planned! A lot of people won’t have time to watch that, so I’ve typed up what I said to share a version that’s easier to skim. It’s not a transcript – I’ve written a shortened version of what I was trying to say in the demo! I’ll include timestamped links as I go if you want to see the full explanation for any particular bit.
The goal was to be able to use language models (the sort of technology behind tools like ChatGPT) in Scratch.
youtu.be/Duw83OYcBik – jump to 00:19
For example, this means I can ask the Scratch cat:
Who were the Tudor Kings of England?
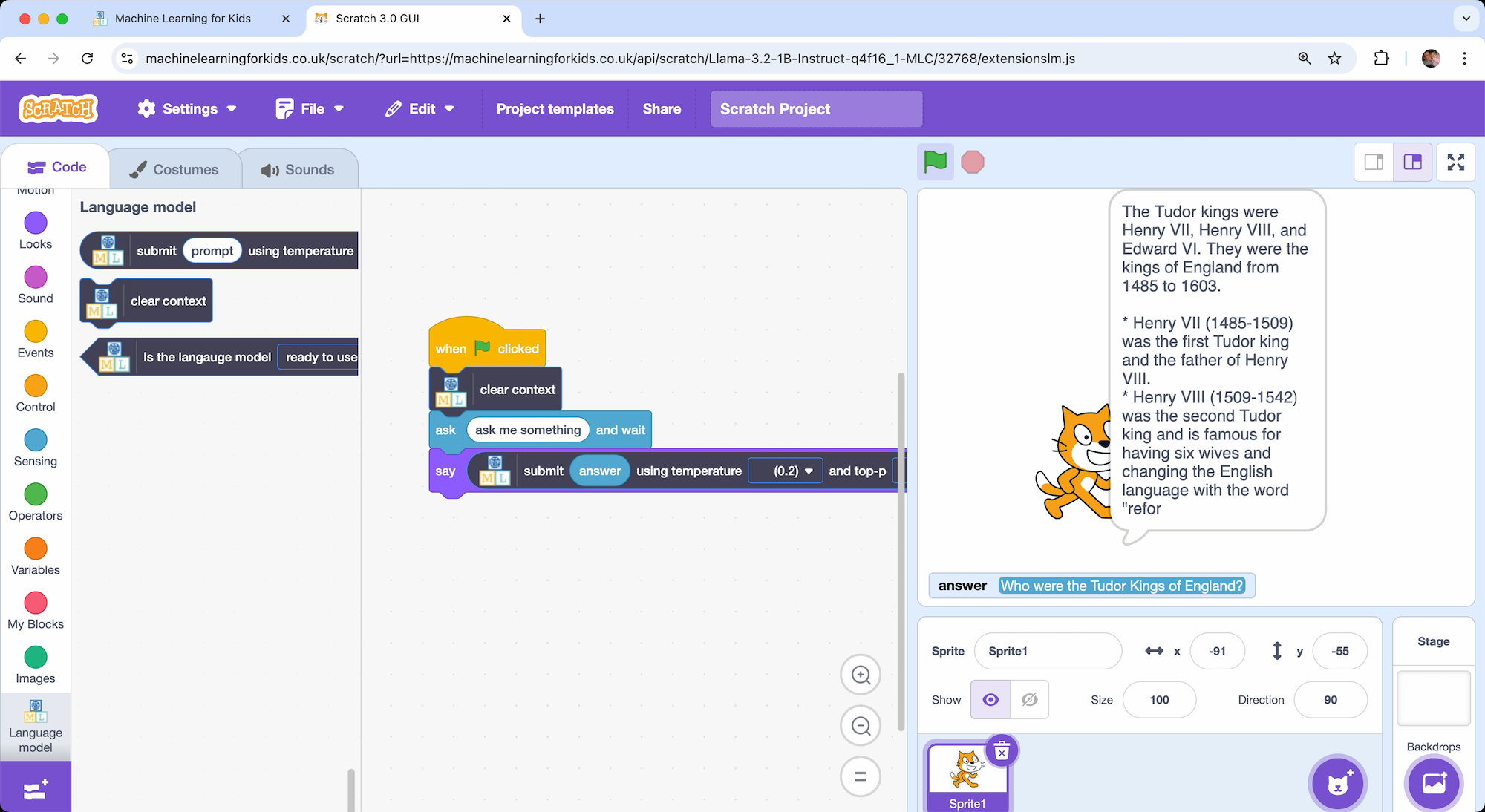
Or I can ask:
Should white chocolate really be called chocolate?
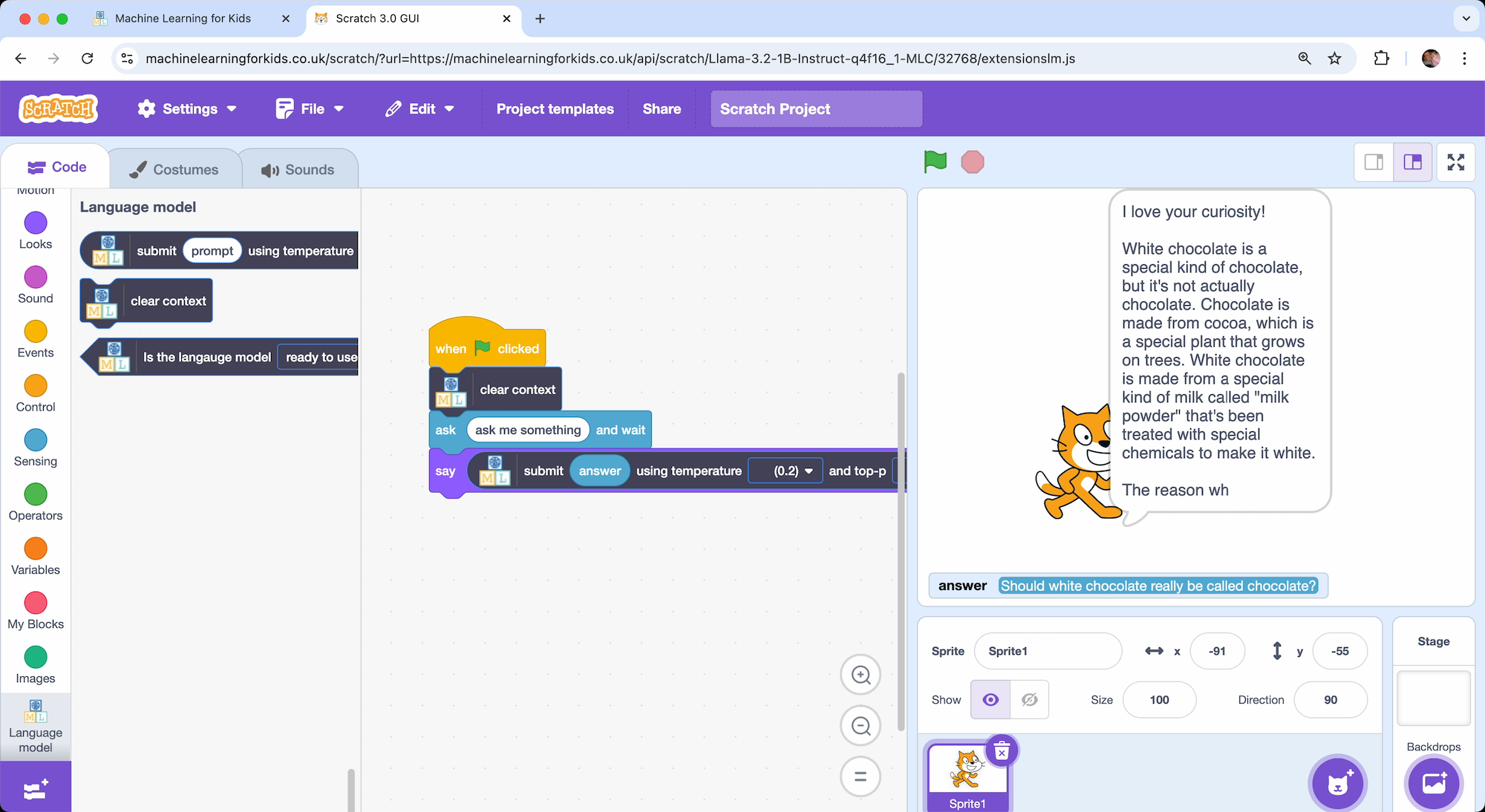
Although that is fun, I think the more interesting bit is the journey for how you get there.
Generating text
youtu.be/Duw83OYcBik – jump to 01:40
I’ve added “generating text” alongside the existing types of projects in Machine Learning for Kids: support for recognising things (text, images, sounds, and numbers), and predicting numbers.
Building an understanding in stages
youtu.be/Duw83OYcBik – jump to 02:18
I want to help children understand the technologies that make generative AI possible. I think it helps to do this in a few stages.
The first stage is to create what I’m describing as a toy language model.
The benefit of creating a toy language model is that it is so simple. You can understand exactly how it works. You can see what it’s doing with text – text that you provide yourself. All of this gives you an introduction to the concepts, which is a great place to start.
Stage 1 : Creating a toy language model
I called my first project “Volcano expert”, with the plan to get it to generate text about volcanoes.
The core idea is to use the computer to look for patterns in the text that I give it – getting the computer to count how many times each word follows each other word. I can use those statistical patterns to generate new text – by using those patterns of what normally comes next to choose the next word, and then the next, and then the next.
youtu.be/Duw83OYcBik – jump to 03:28
The starting point is that I need some text to look for patterns in – what we call a “corpus”. For my model to generate text about volcanoes, I gave it documents about volcanoes.
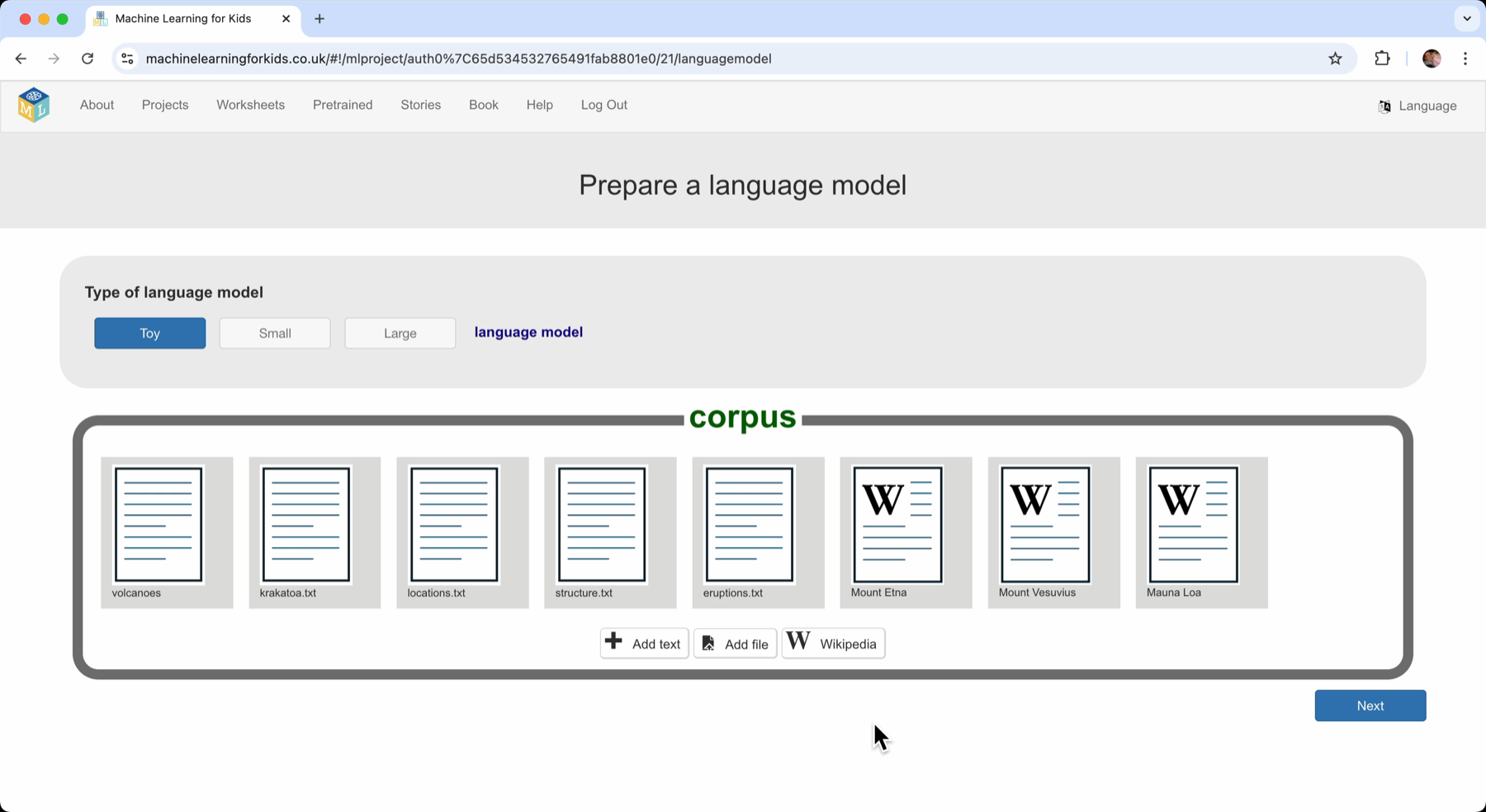
I did this by pasting in text, by uploading files, and by selecting pages from Wikipedia.
Choosing a “context window”
youtu.be/Duw83OYcBik – jump to 05:33
The model generates one new word at a time.
At each point, it’ll use the most recent text it has so far. The patterns it found in the documents I gave it is how it decides which word should come next.
But how much of the text it has so far should it use to make that decision?
This is a bit like what we would call a “context window” in a real language model.
Imagine the computer needs to choose a word to come next after “the“.

Which word should come next?
With a small amount of context, this is difficult. What normally comes next after the word “the”? It’s hard to know. It could be almost anything!
With more context, it’s a bit easier. What normally comes next after “sat on the”? I’d probably choose something like “chair”?

With a little more context, if I were given “the cat sat on the” and asked what could come next, maybe I’d choose “mat”?

The amount of context will change the word you pick. The more context you have, the better choices you can make, but the more complex the language model needs to be to handle it.
For my toy language model, I started with the smallest possible “context window” size.
Reviewing the tokens
youtu.be/Duw83OYcBik – jump to 07:08
Here are the words that the computer found in the text I’ve given it.
I can see that “the” was the most common word in the documents I collected. It came up 1696 times.
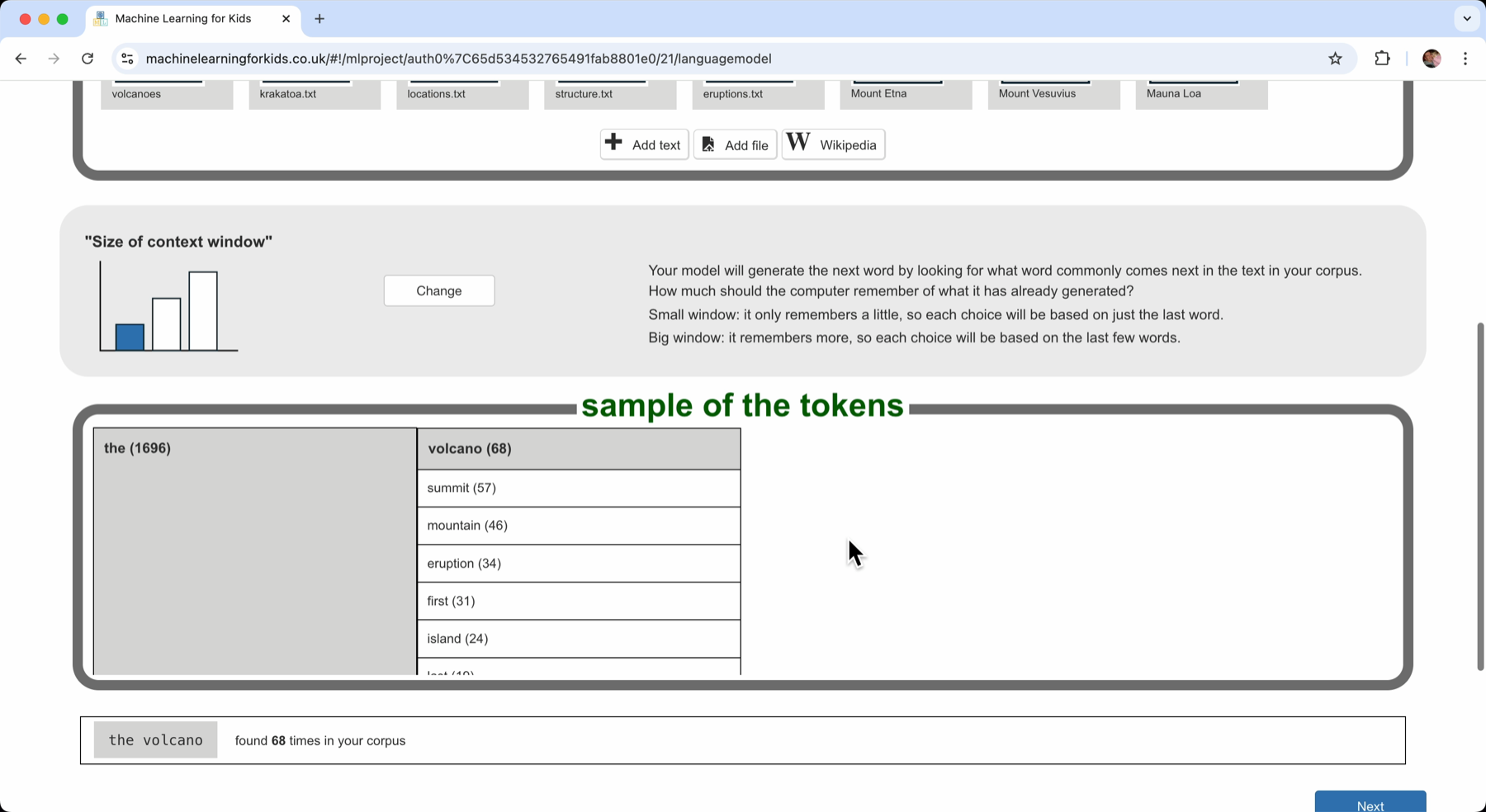
Of all of those 1696 times, what came next? What was the word after “the”?
- 68 times it was the word “volcano” : “the volcano” was found 68 times in my corpus
- 57 times the next word was “summit” : “the summit” was found 57 times in my documents
- 46 times the next word was “mountain” : “the mountain” shows up 46 times in all of my corpus
“eruption” was another common word in my corpus – it came up 157 times in my documents.
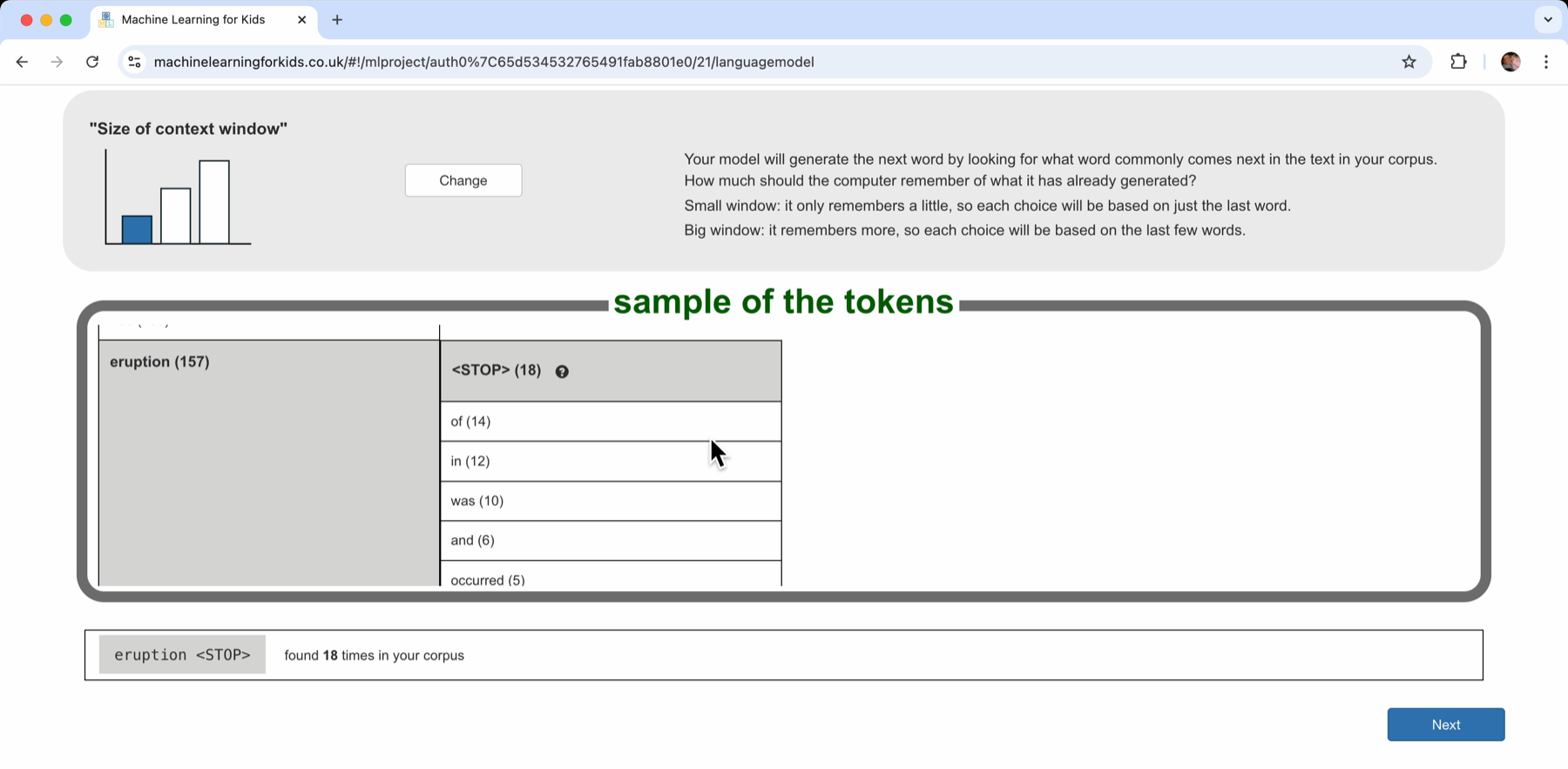
Of all of those 157 times, what came next? What was the word after “eruption”?
- 18 times, “eruption” was the end of the sentence. It was followed by something like a full-stop, a period, an exclamation mark, or question mark
- 14 times, “eruption” was followed by “of” – “eruption of”
- 12 times, “eruption” was followed by “in” – “eruption in”
And so on.
The table doesn’t show a complete list of all the words found in the corpus. To keep things simple, the page only shows a sample – just the most common tokens. The aim of this page isn’t to be a complete dictionary, rather to give a feel for what the computer is doing with the documents.
“Temperature” and “Top-P”
youtu.be/Duw83OYcBik – jump to 08:57
How do we use these patterns to generate text? How do we use these patterns to choose the next word to generate? The table shows some of the many options that are found after each word, but of all the words that we’ve seen come next in the corpus, how do we choose the one to come next when generating text?
This is implemented as two controls that are a bit like what we would call “temperature” and “Top-P” in a real language model.
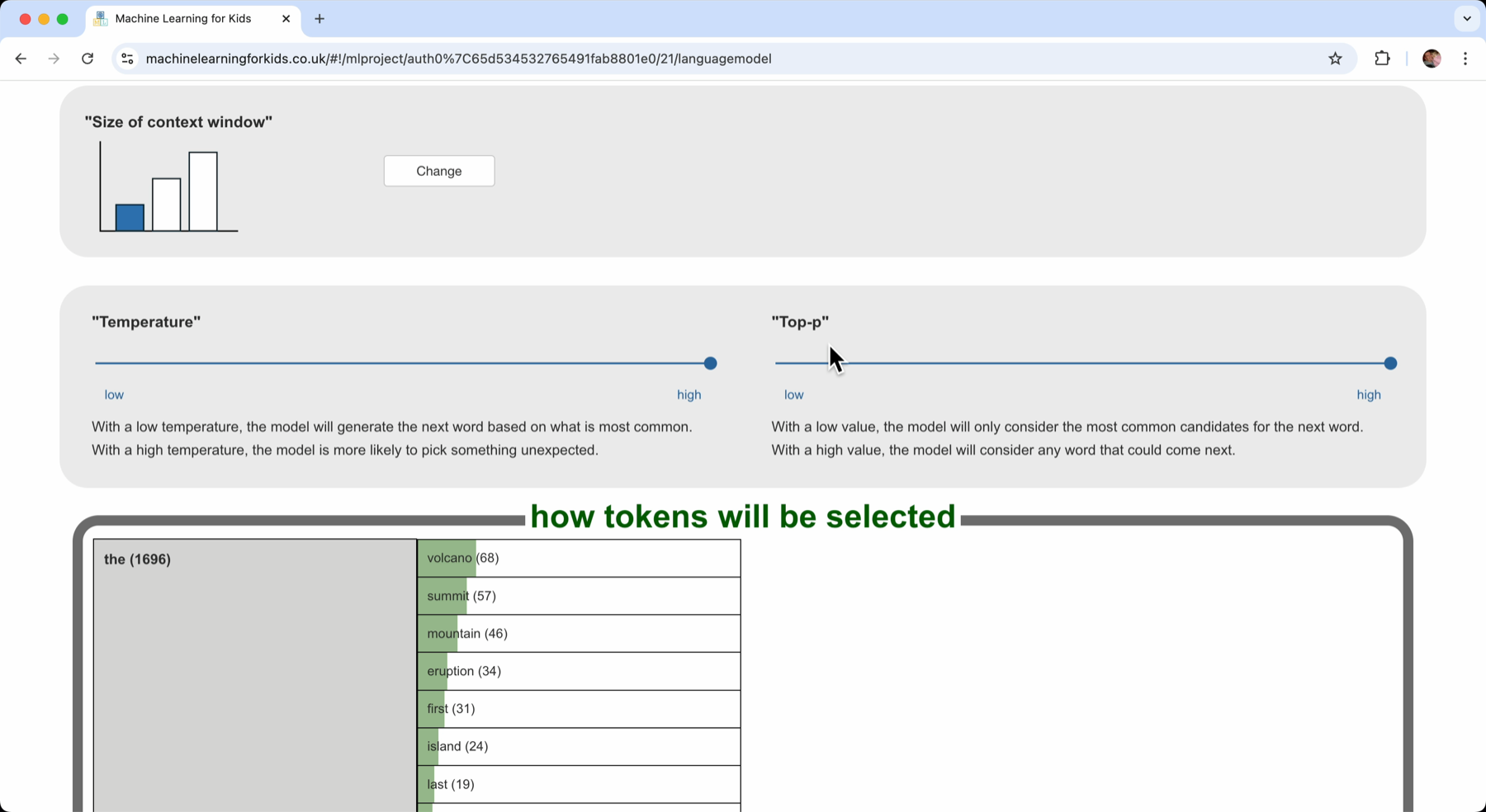
“Top-P”
“Top-P” is how I can describe which of the words that came next should be a candidate.
Going back to “eruption”. Remember that it came up 157 times, and it was followed by words like “of”, “in”, and “was”.
With a high “Top-P” value, these are all candidates. That means that when the computer is choosing the next word to generate, if it has “eruption”, it can pick from any of these – anything that has come after “eruption” in the documents I collected.
If I lower the “Top-P” value, the less frequent words are removed as candidates. This is shown in the table by making the words go grey as I drag the “Top-P” slider.
How do I want the computer to generate new text? Do I want to choose the next word by sticking only to what comes next very often? (a low “Top-P”) Or do I want it to have anything that has ever come next as an option? (a high “Top-P”)
“Temperature”
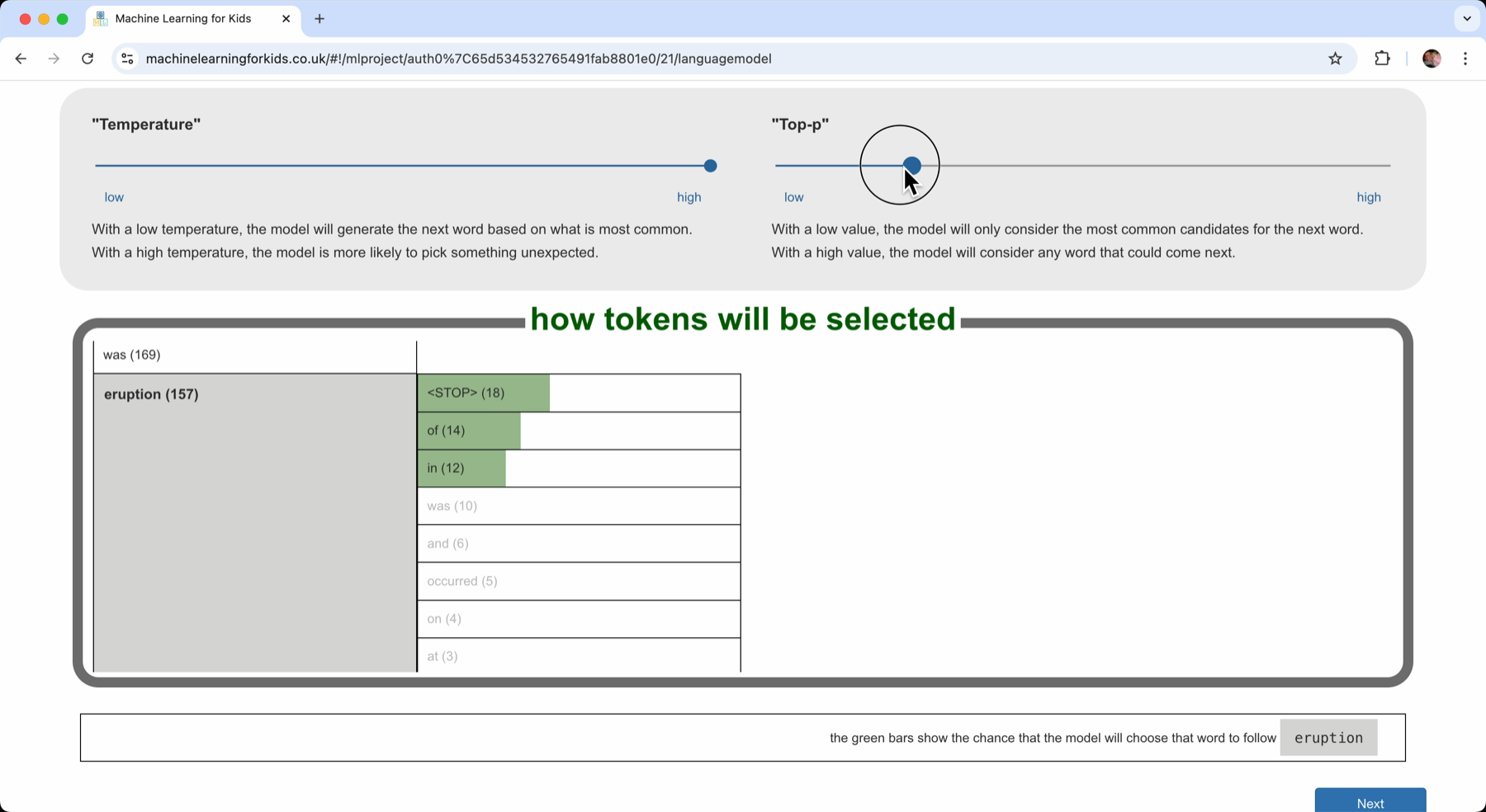
The table shows the probability that each word would be selected as the next word using a bar chart. The longer the green bar, the higher probability that the computer will choose that word to come next.
The probability is controlled by the “temperature”.
With a high “temperature”, it will give all of the candidate words a chance. It has a higher probability of picking the more common ones, but they all get a chance.
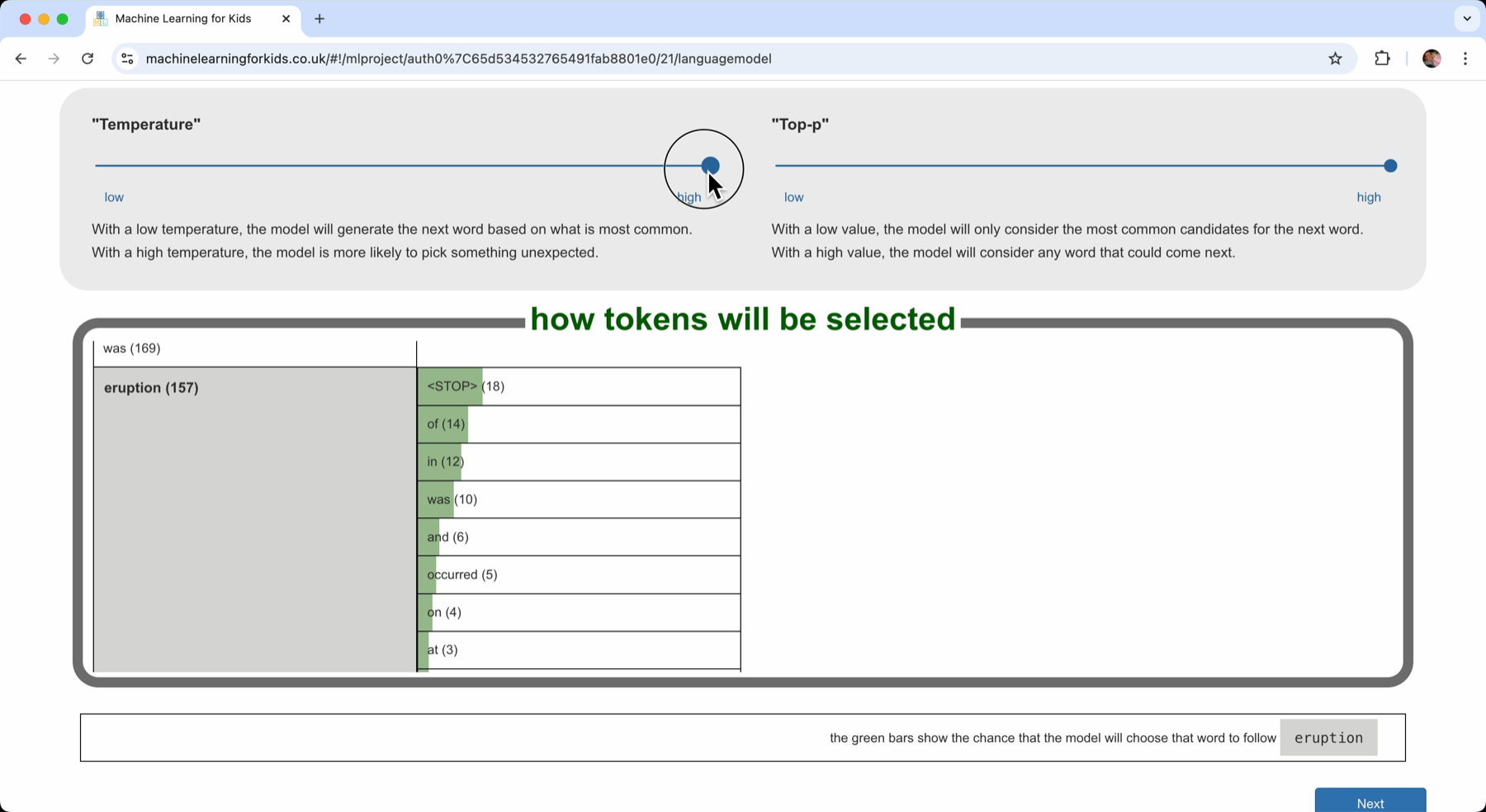
If I lower the “temperature” value, I reduce the probability of picking those less common ones.
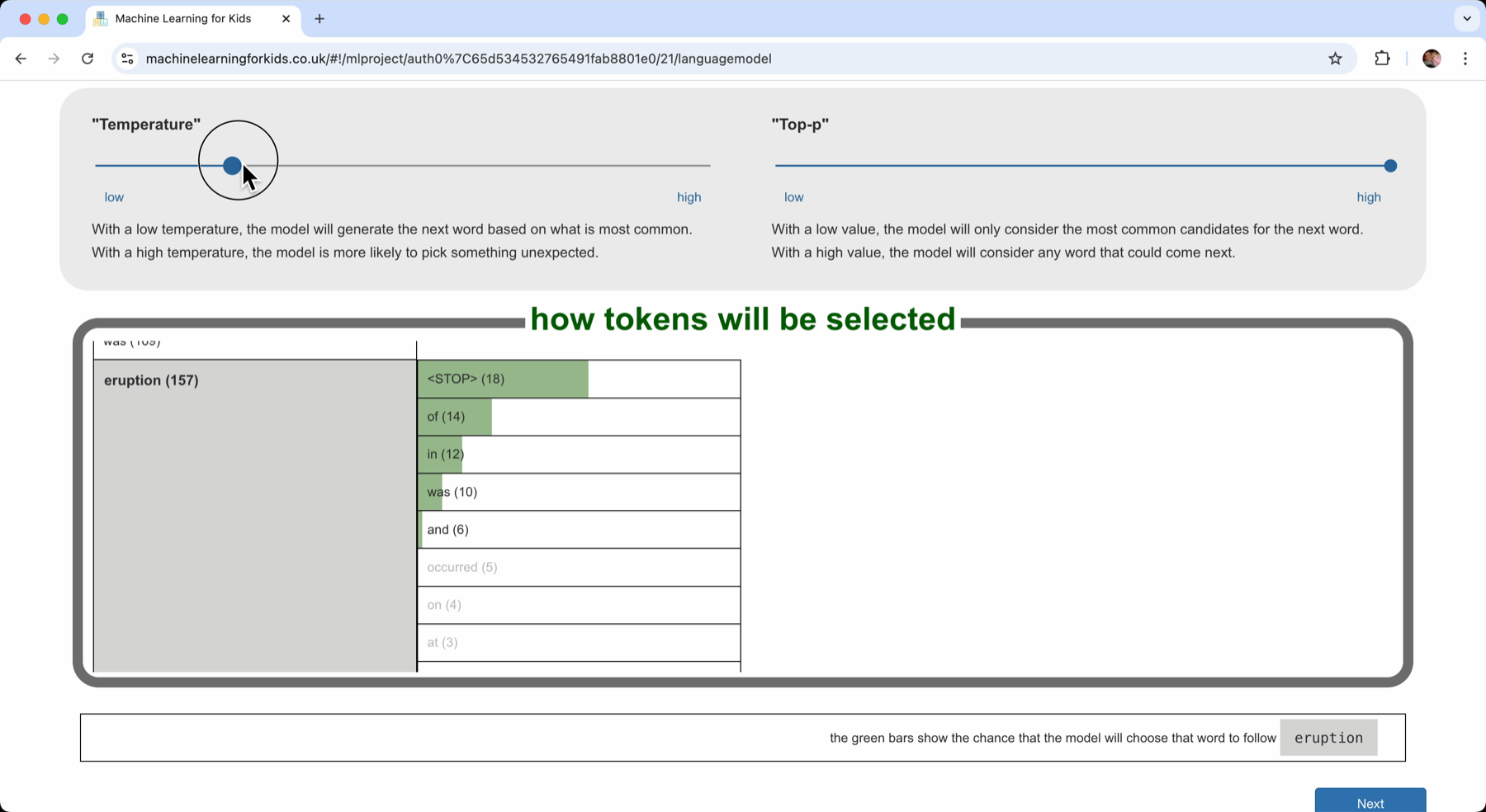
If I lower the “temperature” value, the more common words increase in probability even more, I increase the chance that the computer will pick one of the more common words.
How do I want the computer to generate new text? Do I want to almost always pick the next word that came next the most often in the documents? (a high “temperature”) Or do I want it to sometimes pick a next word that is a bit more unusual? (a low “temperature”)
Experimenting with the sliders for “temperature” and “Top-P”, and seeing the visualisation of the probabilities update is a good way to get an intuitive feel for the sorts of controls used to adjust the behaviour of real language models.
Testing
youtu.be/Duw83OYcBik – jump to 13:15
The next step is to give it a try. I can give it a word to start from, and then click “Generate”.
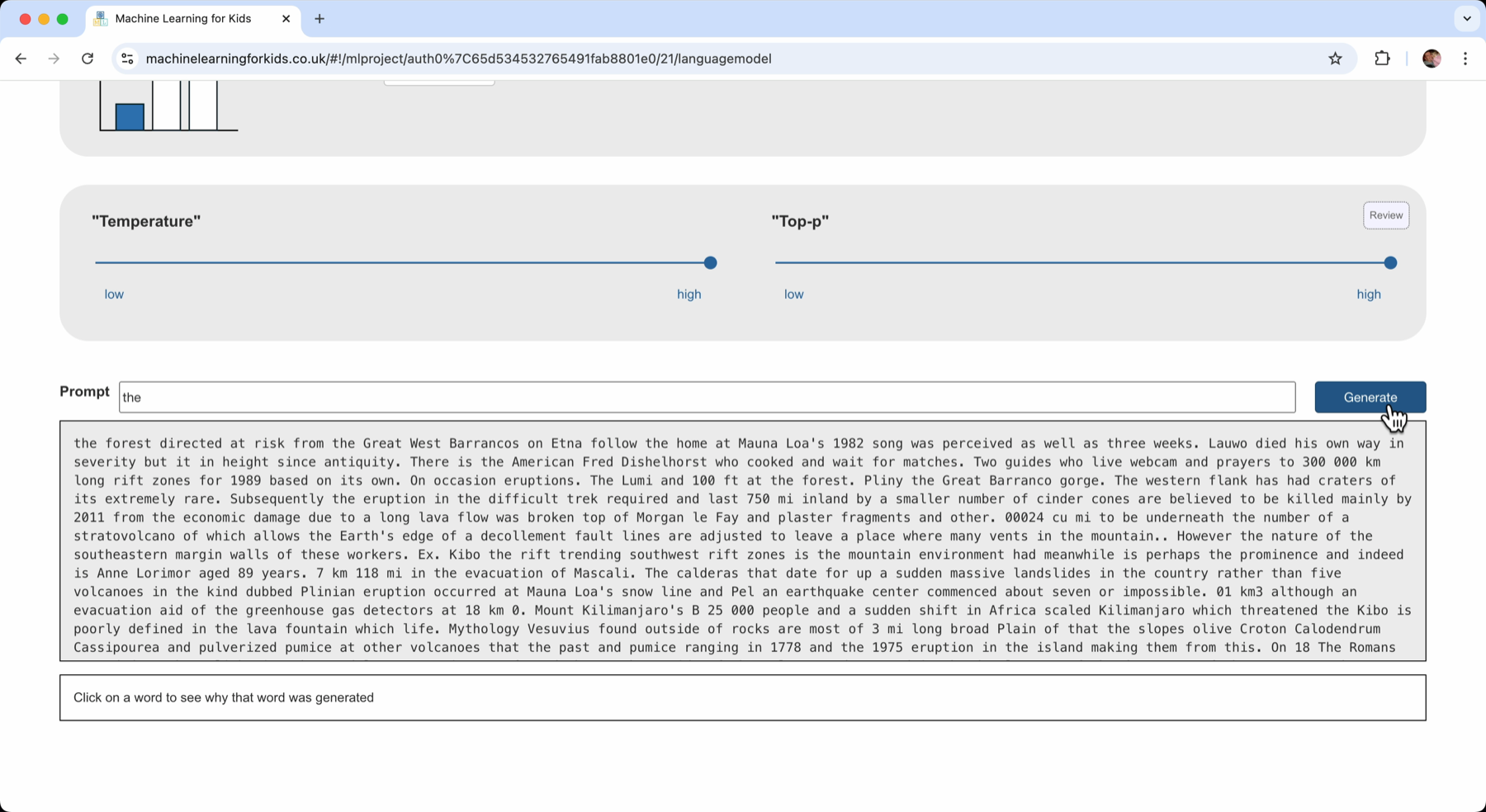
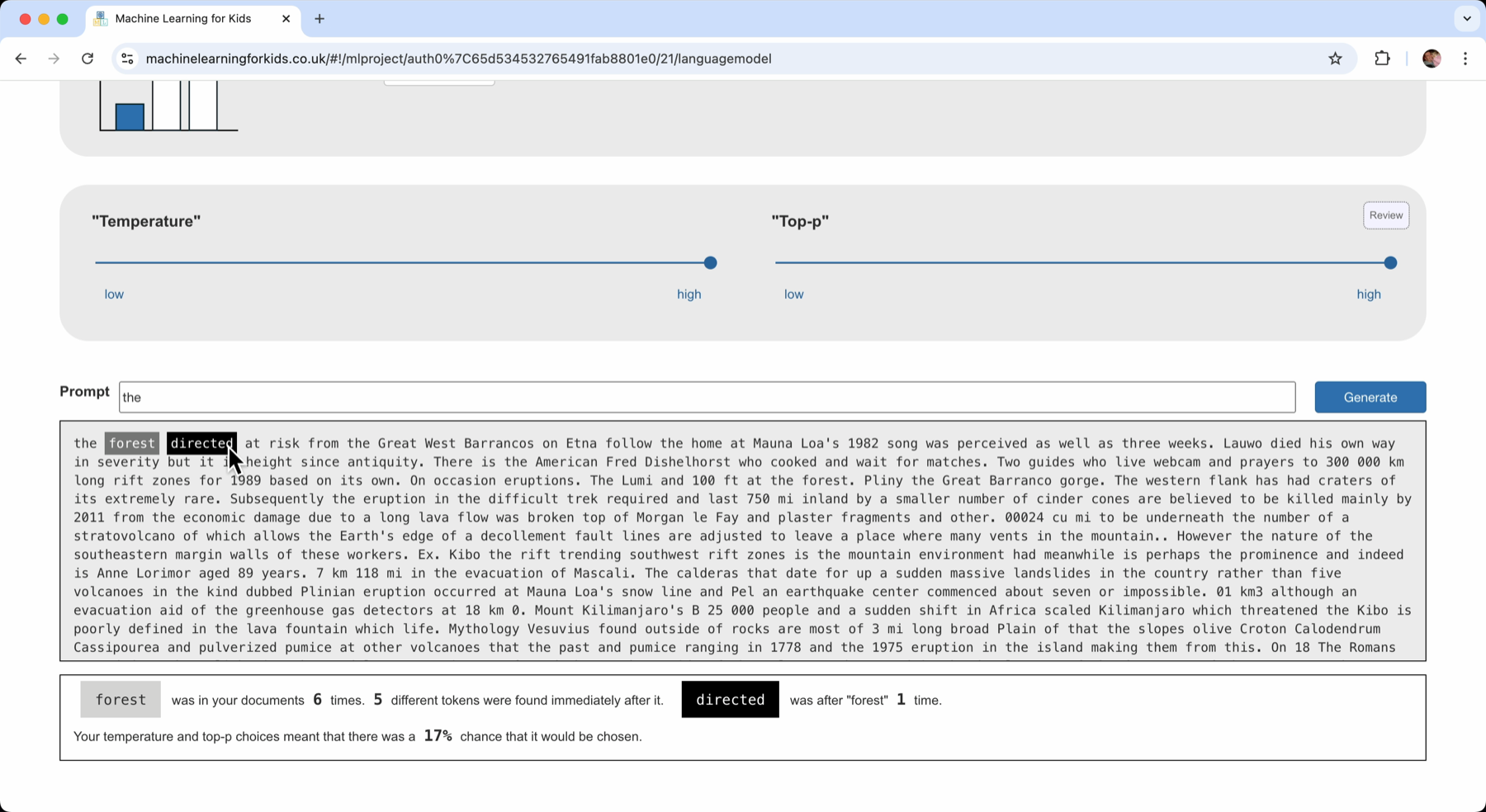
If I click on any word in the generated passage, the text is annotated to explain why it was chosen.
Each click on “Generate” generates a new passage – and even with the same starting word, the level of randomness involved means a different passage is generated.
With a high temperature and high Top-P, very random text is produced – text that doesn’t make much sense.
Sliding the Top-P value down to the lowest possible value and clicking Generate resulted in the generated text being a loop:
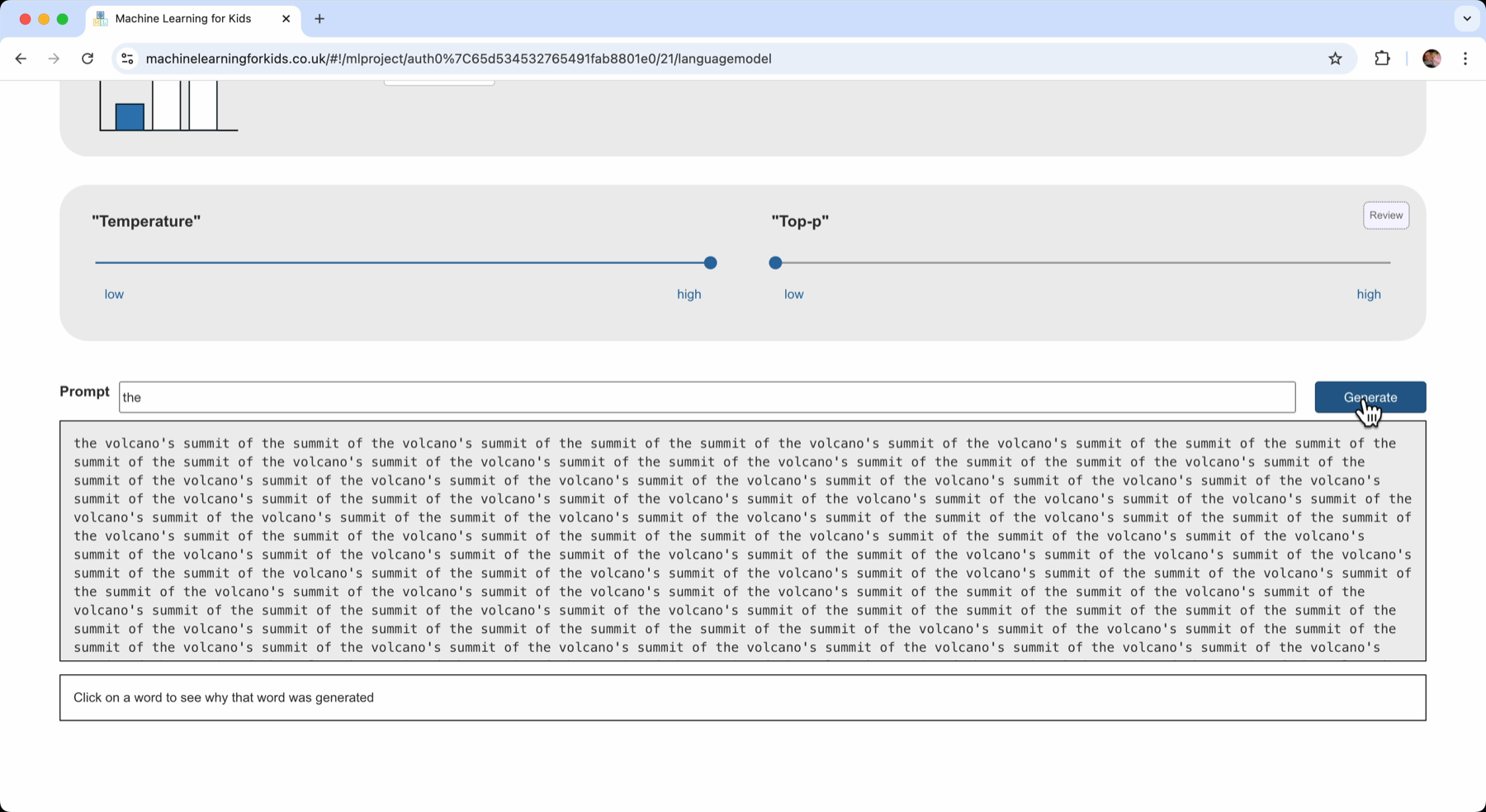
It’s less random. But by reducing the list of candidates so much, there is only one choice for the word to come next, and it ends up going in a loop!
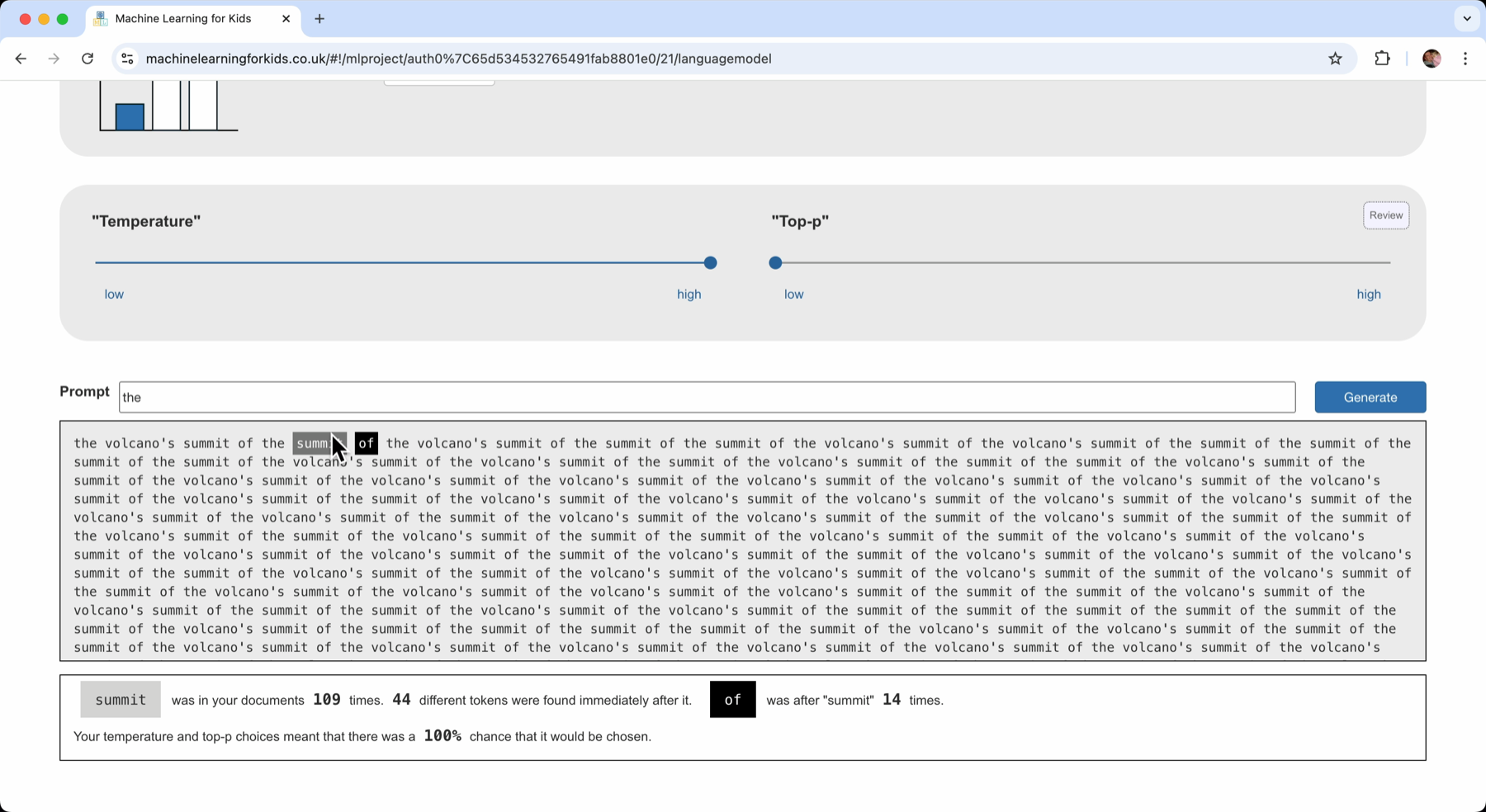
I’d reduced Top-P too far.
Increasing it a little and clicking “Generate” again resulted in text that was a bit better, but still repetitive.
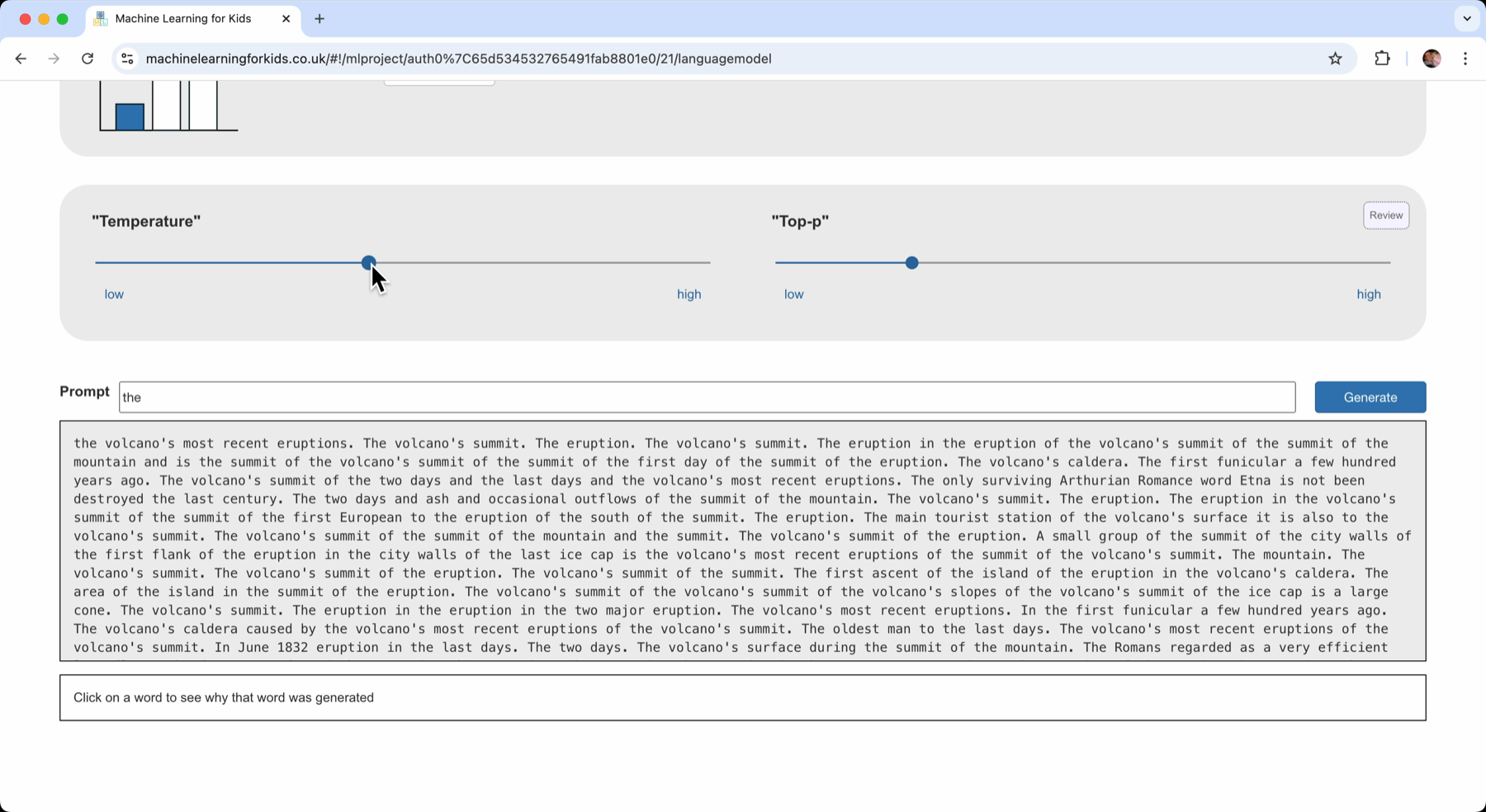
The more I increase Top-P, the more creative and varied the text can be.
And I can experiment with the temperature in the same way – adjusting the slider and then clicking “Generate” to see the impact of how often it picks less common next words.
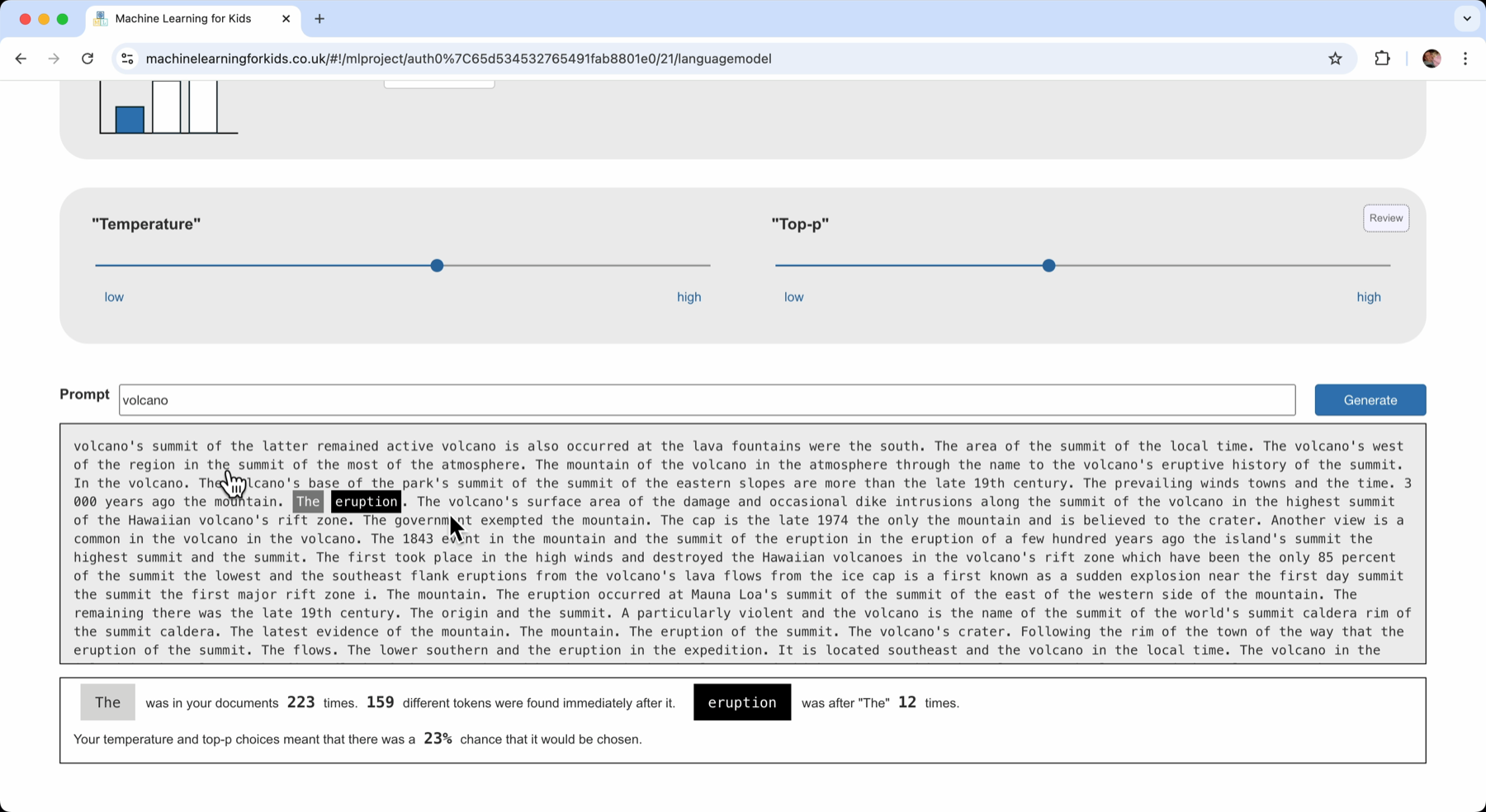
None of the experimenting resulted in a good paragraph being generated. This brings me back to the “context window” idea. By only looking at one word when choosing the next word, it’s difficult to make an informed decision about which word to pick – modifying temperature and Top-P won’t help with that.
Increasing the “context window”
youtu.be/Duw83OYcBik – jump to 19:03
I increased the “context window” so that this time the computer counted every two-word sequence in the documents that I collected. The most common pair of words was “the volcano” – which was found 68 times.
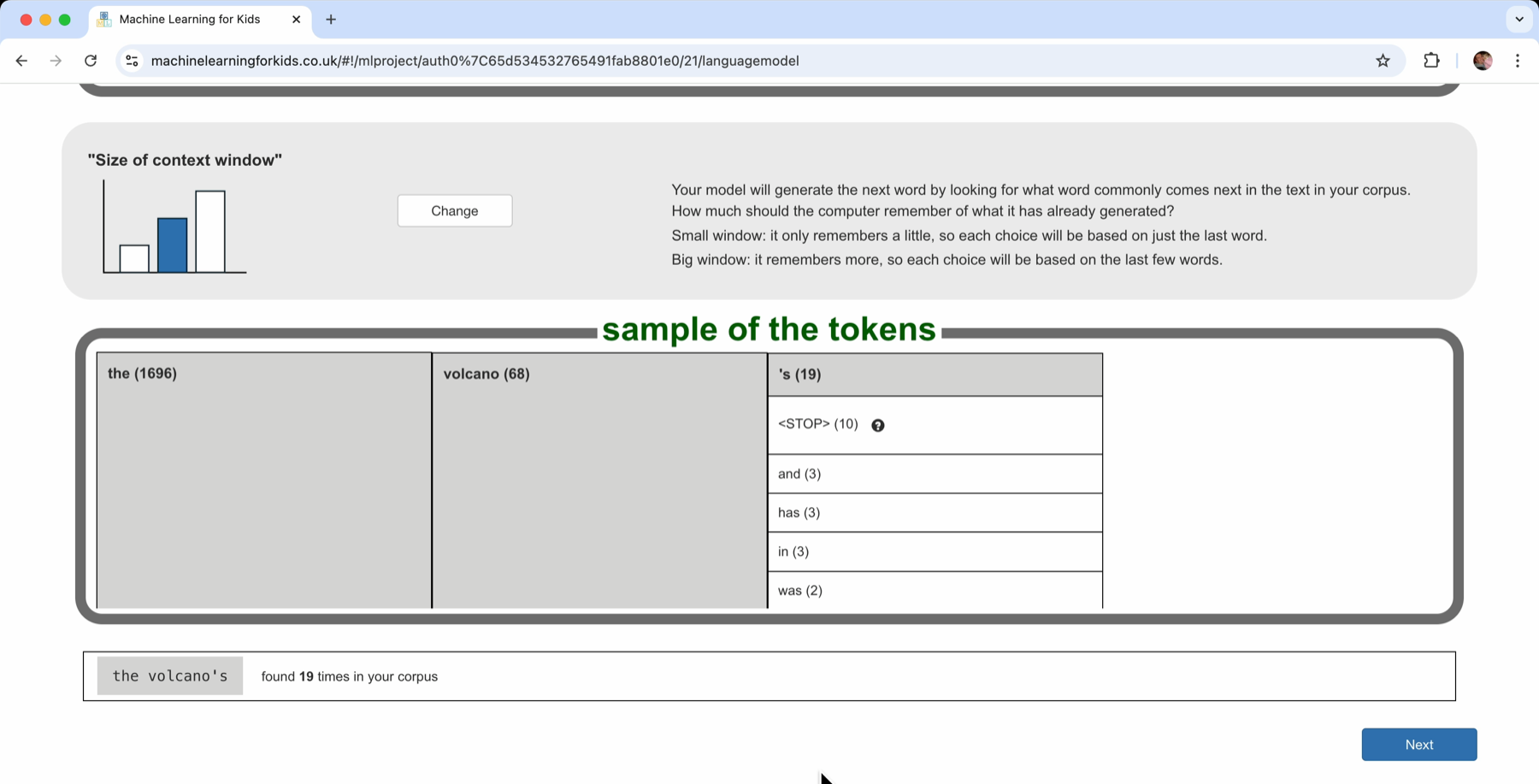
Of all of those 68 times, what came next? What was the word after “the volcano”?
- 19 times it was “’s” (a token isn’t always just a word – sometimes a token will be a bit of a word) : “the volcano’s” was found 19 times in my documents
- 10 times “the volcano” was the end of a sentence
- 3 times the next word was “and” – “the volcano and” shows up 3 times in all of my documents
And so on.
What I’ve got now is a list of the possible options to choose from for what word could come next after every two-word sequence.
Again, I use temperature and Top-P to control how that choice is made.
youtu.be/Duw83OYcBik – jump to 20:50
Clicking on “Generate” shows the impact.
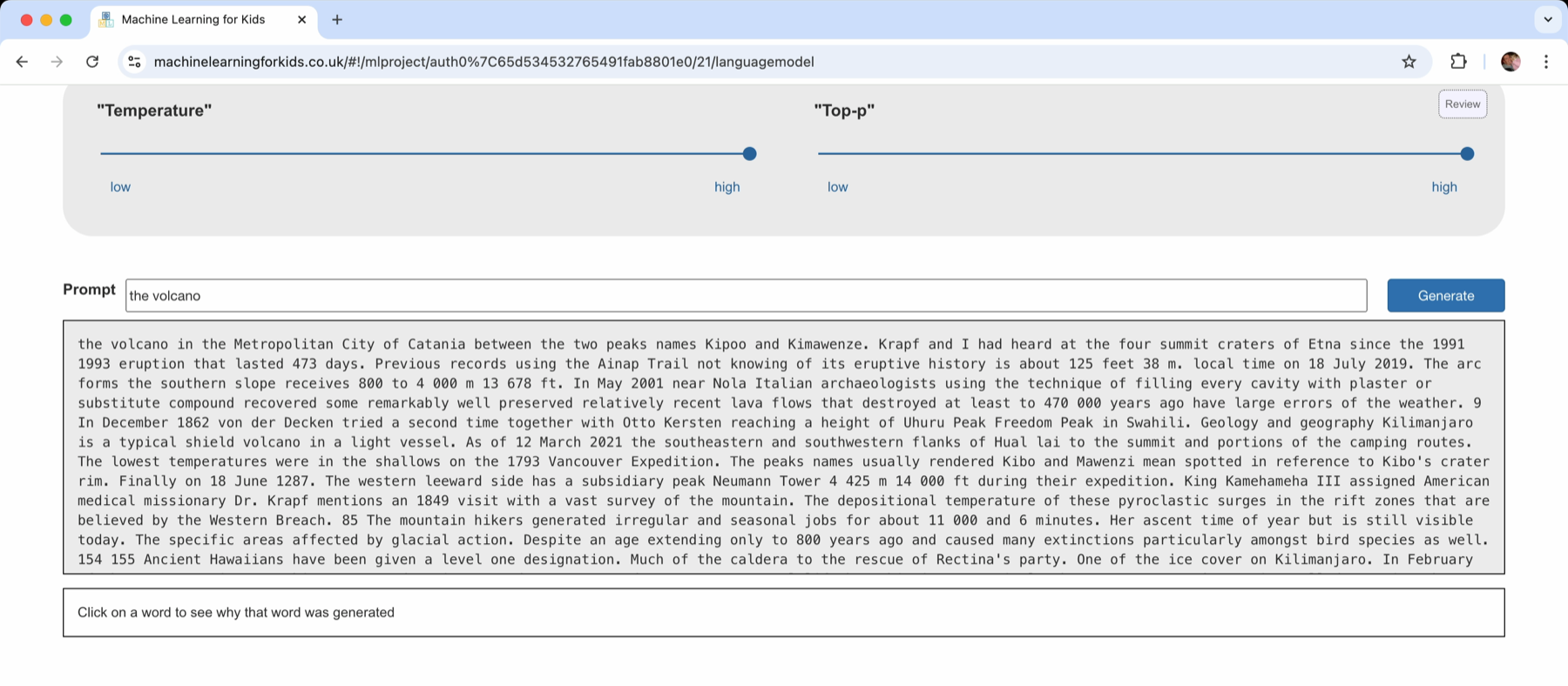
This looks more like text. It’s still not sensible, but the increased context is helping.
Clicking on any word in the generated text shows how it was chosen.
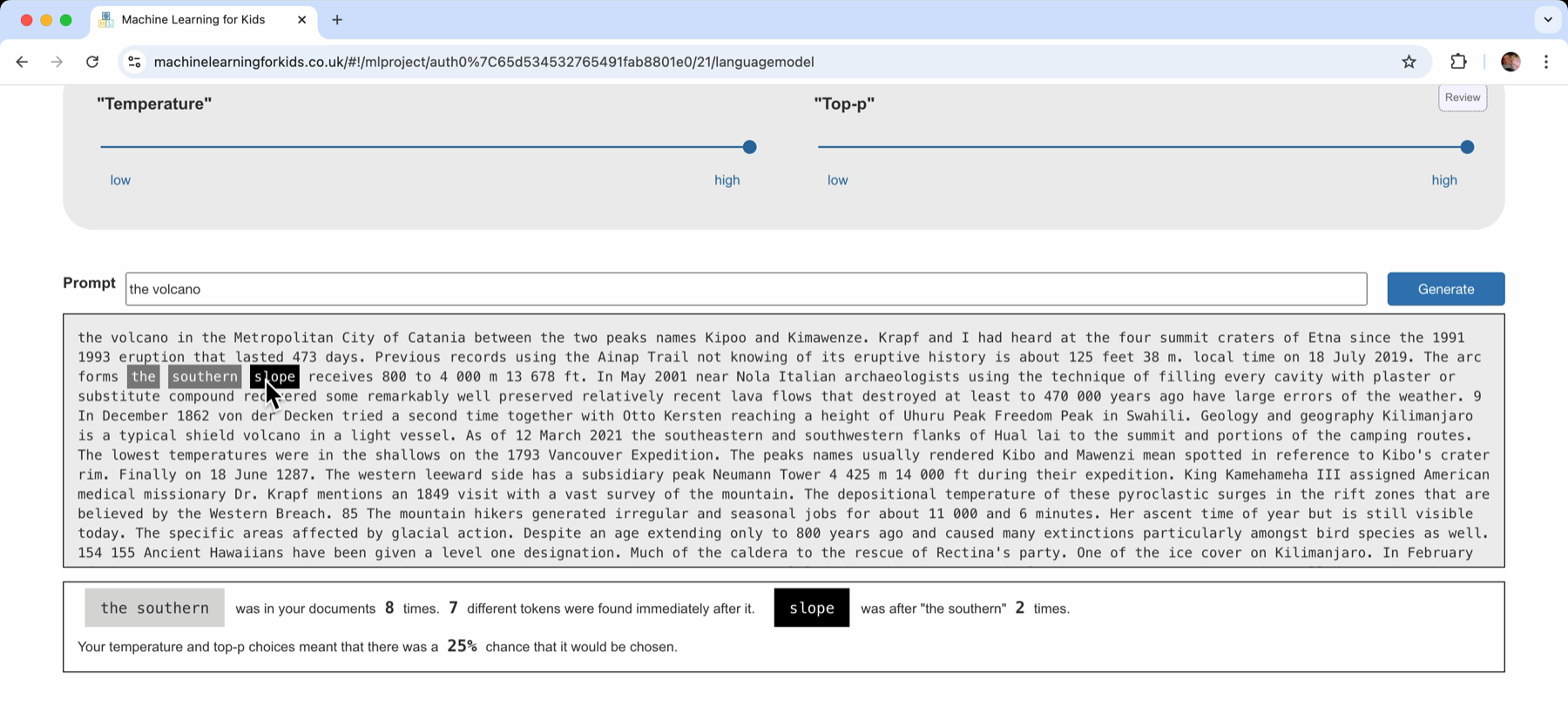
Clicking on a word towards the end of a long sentence shows that only the two words immediately before it were used as an input for choosing that word.
For example, I found:
Previous records using the Ainap Trail not knowing of its eruptive history is about 125 feet 38 m. local time on 18 July 2019.
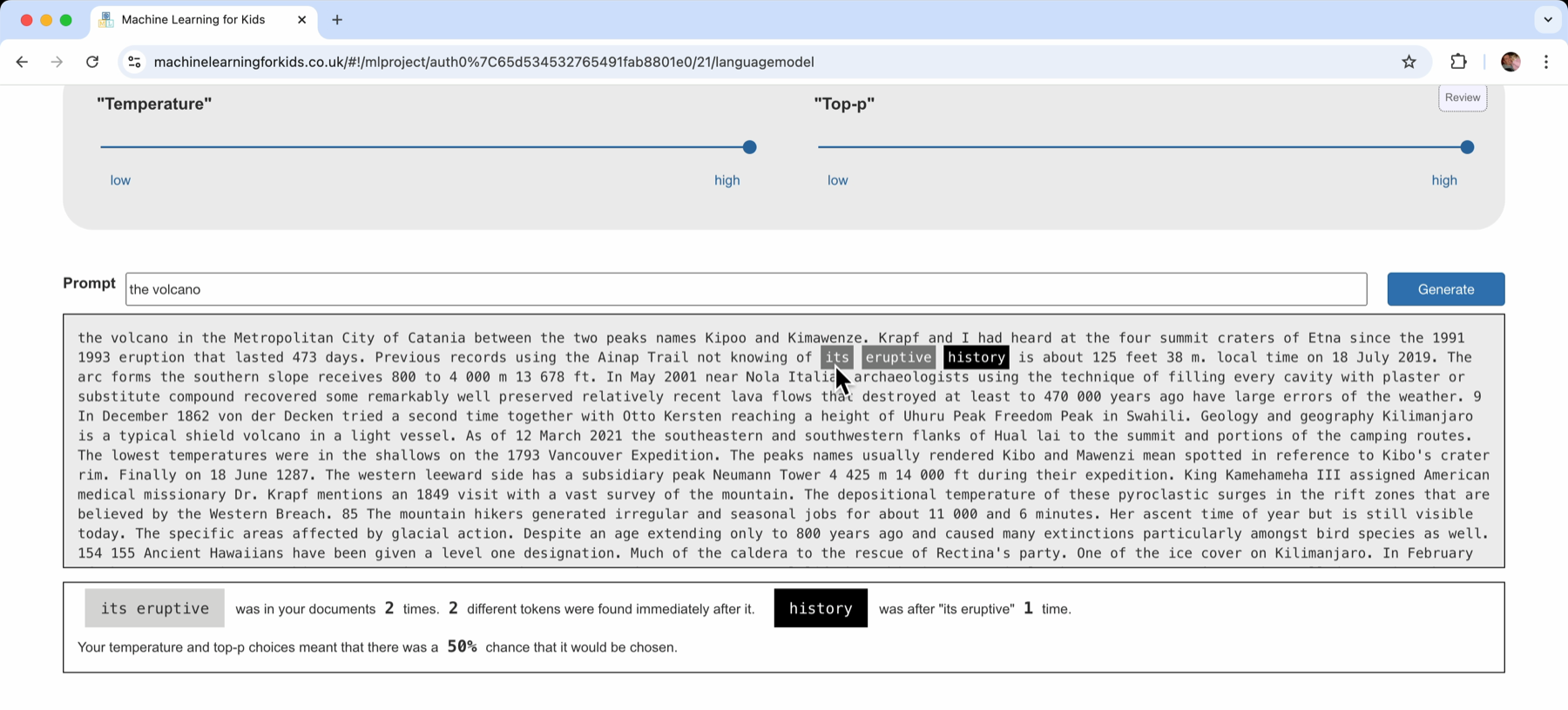
“history” was chosen because it followed “its eruptive”.
The fact that the sentence started with a reference to the Ainap Trail, or talking about previous records, was not a factor.
With such a short “context”, it is difficult for the model to create longer sentences that still make sense.
youtu.be/Duw83OYcBik – jump to 22:33
I can increase the context a little more.
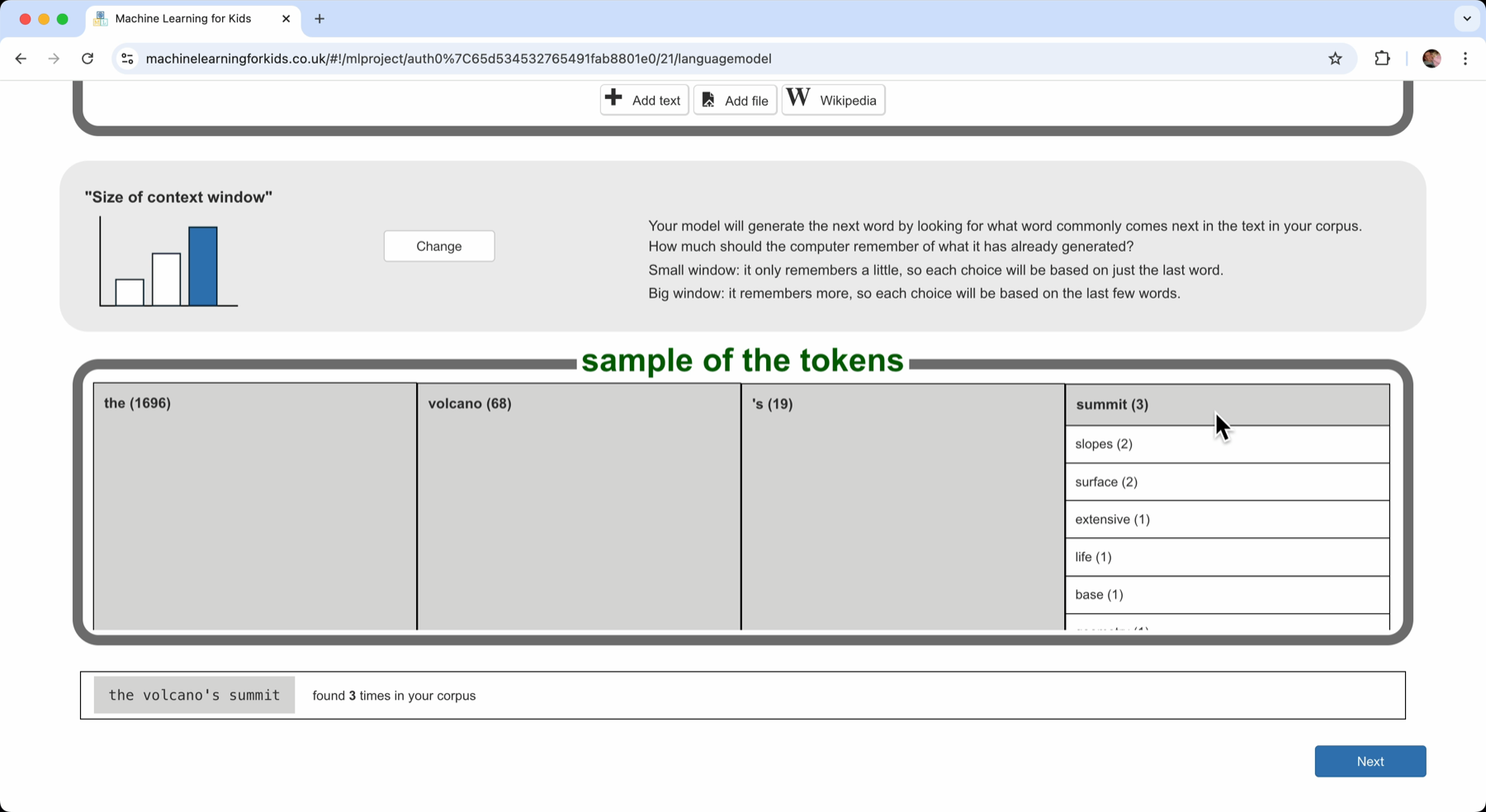
As before, a sample of the tokens is displayed in a table. But the numbers are much smaller now. Compared with the counts before, these numbers are tiny. Each of the four-word sequences shown in this table was found only a few times.
”the volcano’s summit” was found 3 times in my documents
“the volcano’s slopes” was found twice
And many of the other sequences of words were found only once: “the volcano’s base”, “the volcano’s geometry”, and so on.
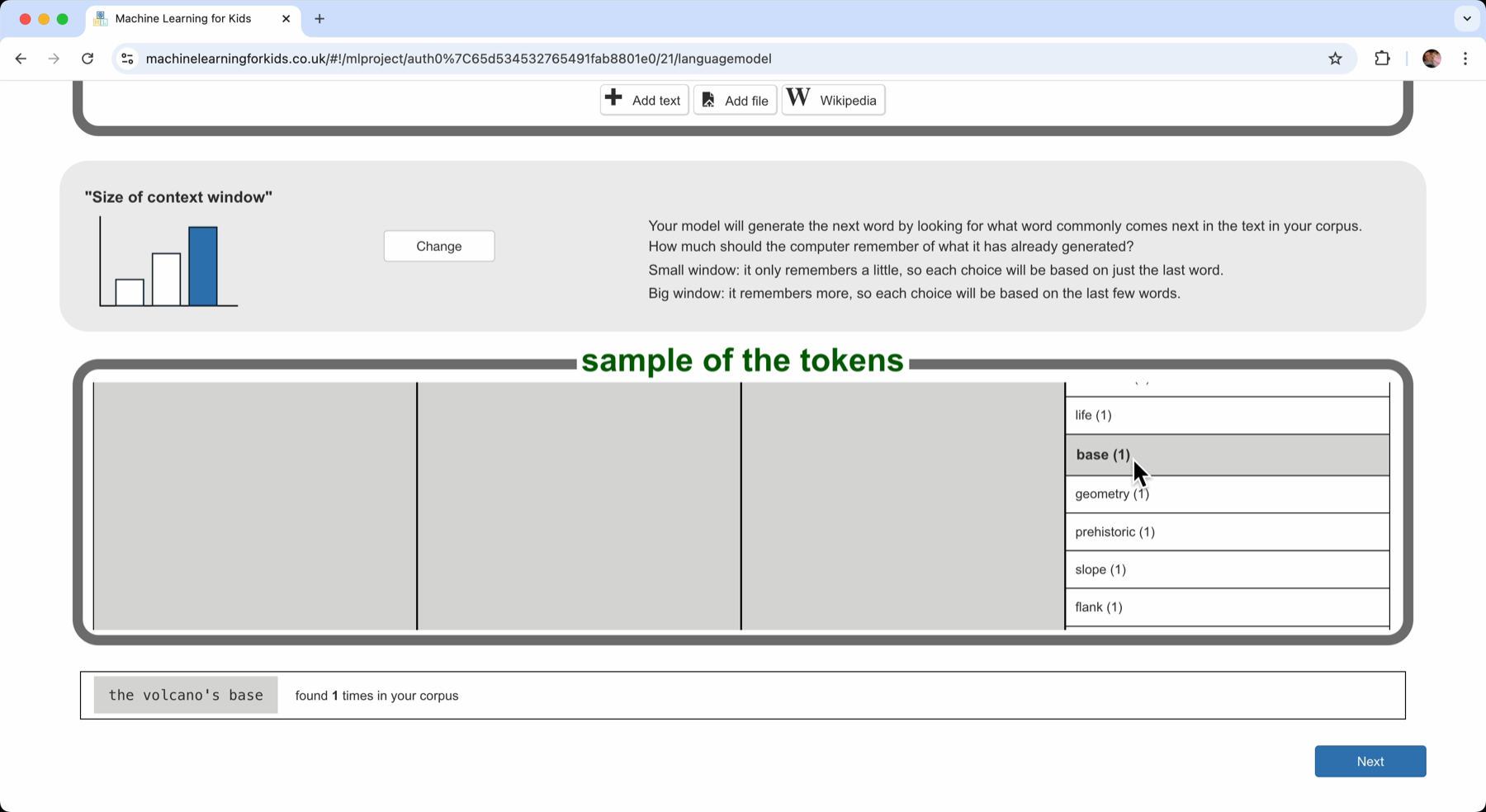
It is hard to find useful patterns in this. The corpus does not have enough documents to find useful patterns with this longer context.
The more we increase the “context window”, the better text the model can generate, but the more and more documents we need to feed it for this to be useful.
youtu.be/Duw83OYcBik – jump to 23:53
Clicking on “Generate” shows the impact of this.
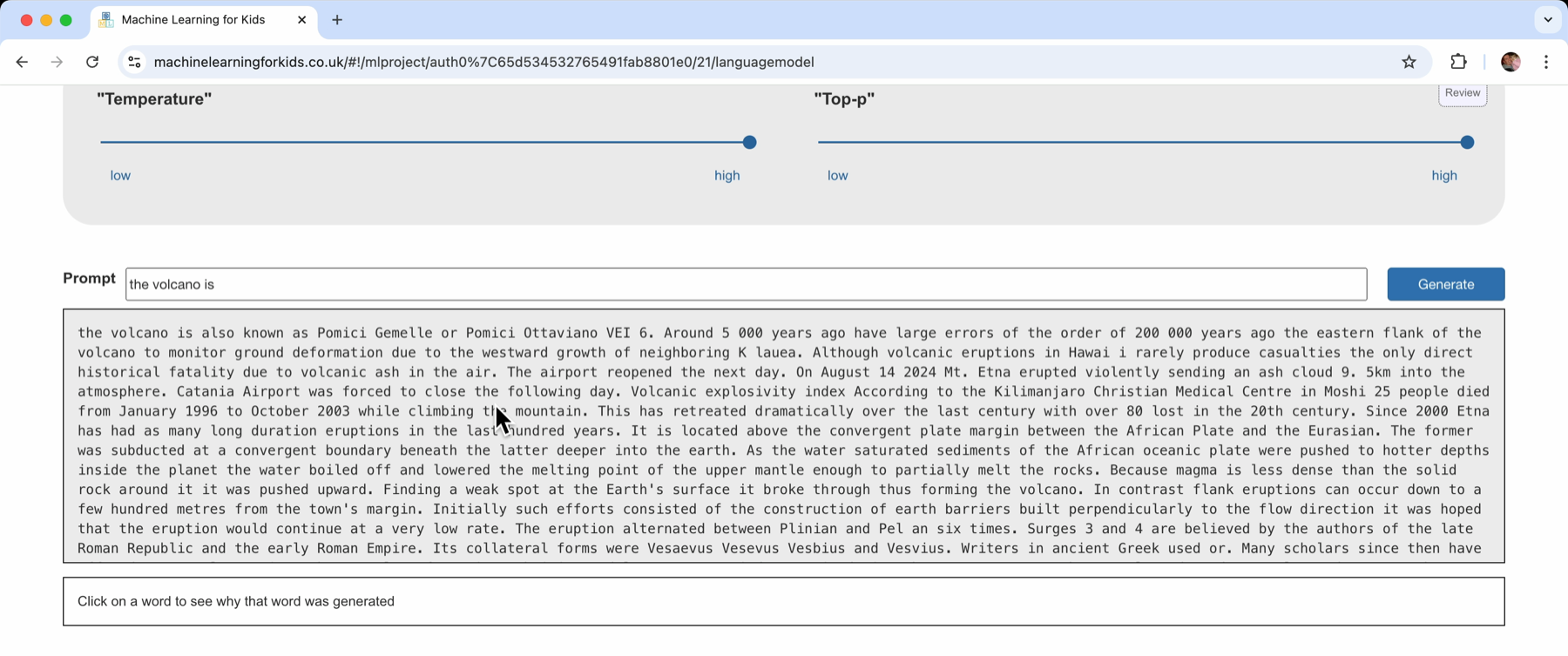
It looks like good, sensible, readable text – but clicking on words in the text shows what happened.
At this point, a lot of this is just reproducing sections from the documents that I collected. There aren’t enough examples of what I’m trying to generate to give me patterns I can use to generate something new.
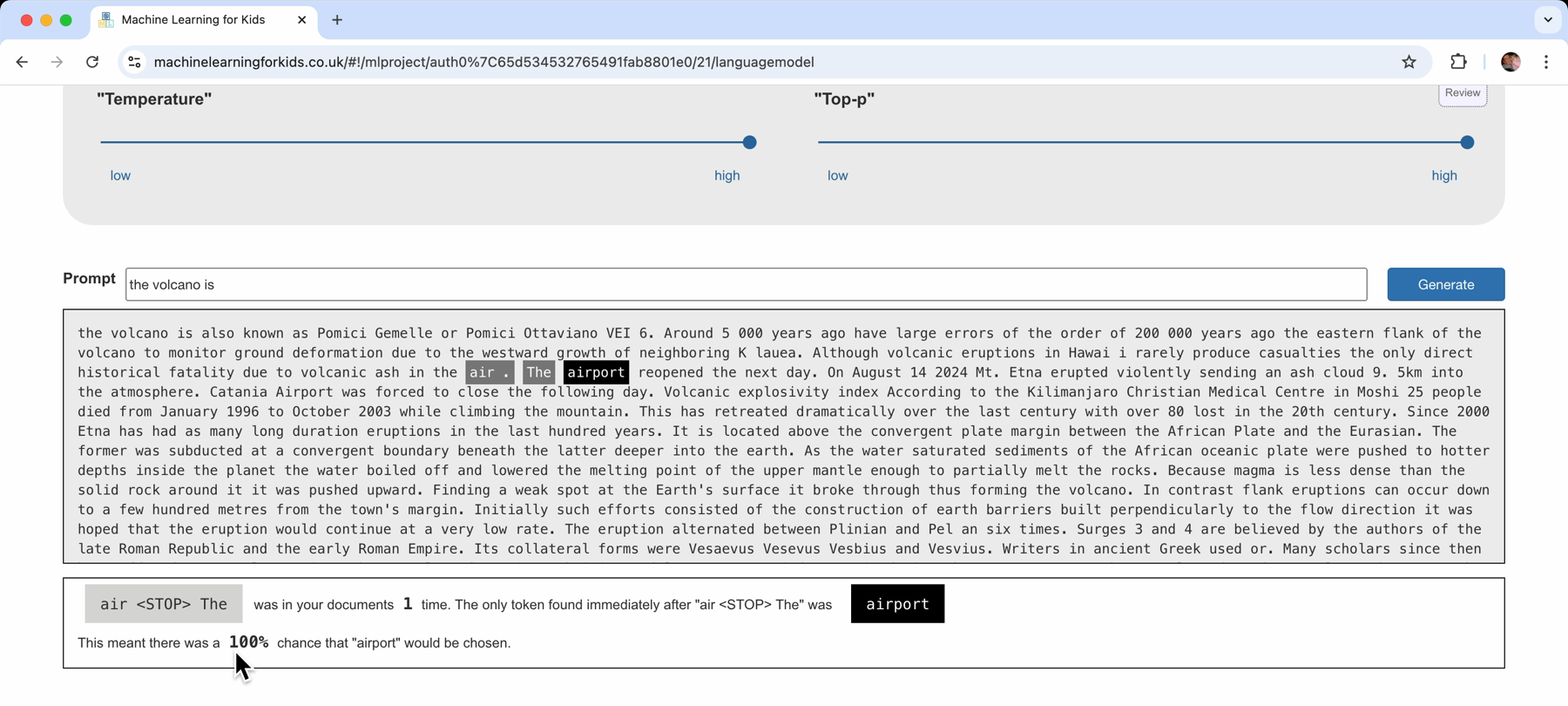
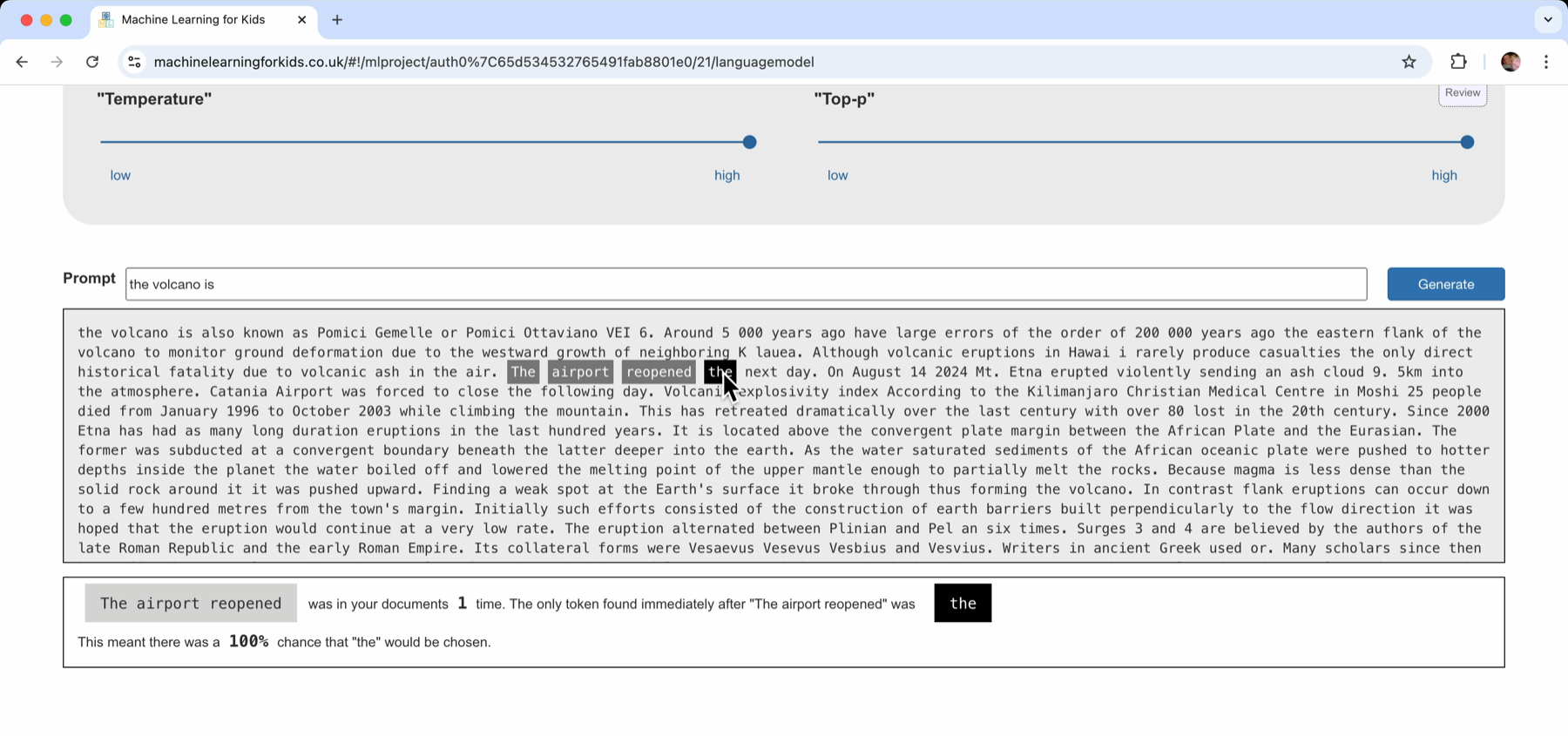
The next step would be to go back and add more documents to the corpus to see if I can help improve that.
Stage 2 : Configuring a small language model
youtu.be/Duw83OYcBik – jump to 26:55
The next stage is to configure a small language model, to see these sorts of principles in action when applied to a language model trained with millions of documents.
Choosing a model architecture
youtu.be/Duw83OYcBik – jump to 27:14
There is a selection of six models to choose from:
- SmolLM2 (Hugging Face) – a 276 MB download
- Qwen 2.5 (Alibaba) – a 289 MB download
- TinyLlama (Singapore Uni. of Technology and Design) – a 625 MB download
- Llama 3.2 (Meta) – a 711 MB download
- Phi 1.5 (Microsoft) – a 806 MB download
- Gemma 2 (Google) – a 1.5 GB download
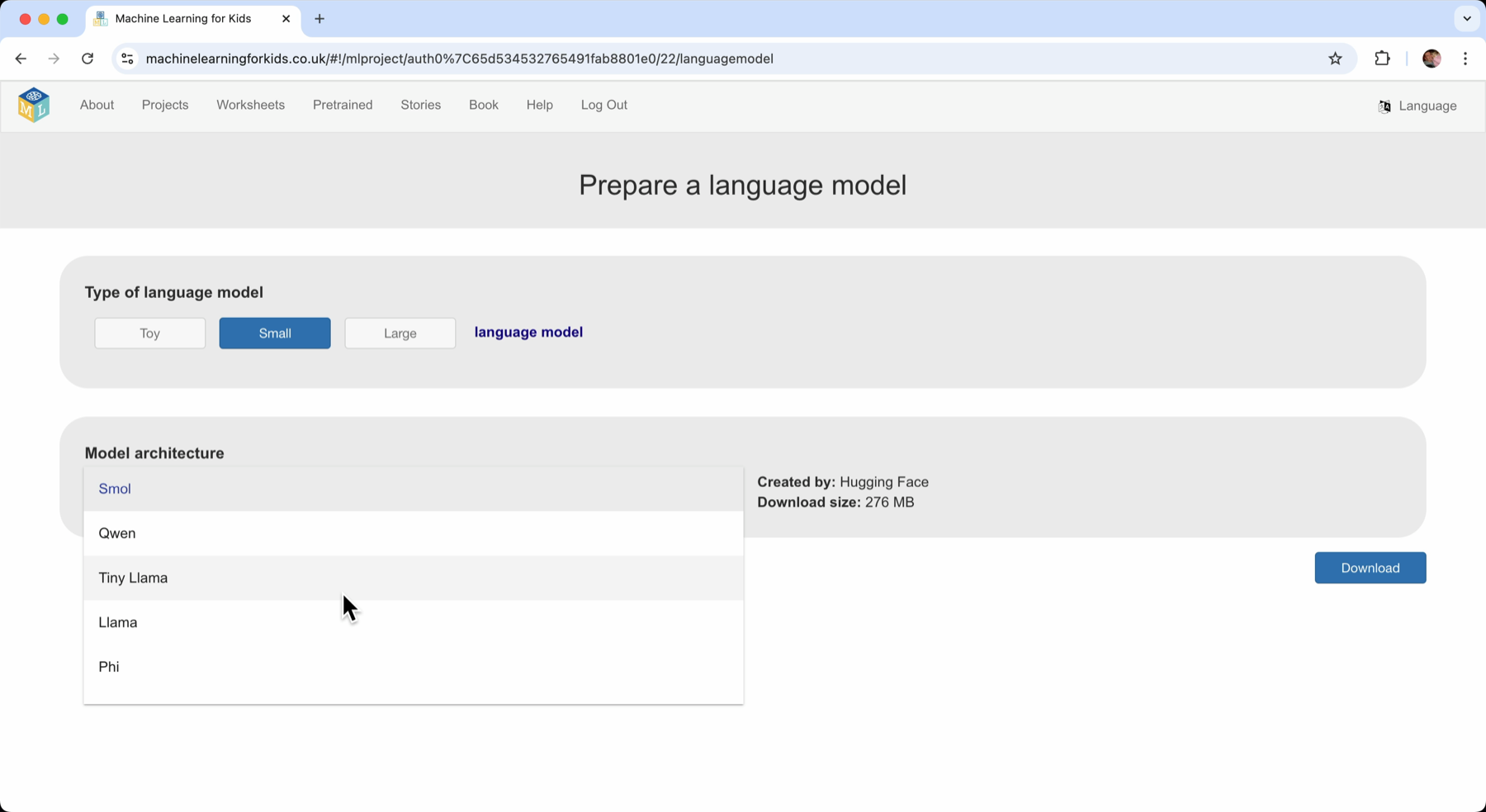
It is super interesting to compare how the different model types perform. Experimenting with putting the same prompts to each model is fun. For students who might have limitations on their network speed or disk space, I also hope it’ll be helpful to have different size options they can choose from.
Choosing a context window
youtu.be/Duw83OYcBik – jump to 28:17
With my toy language model, I had a tiny context window. Each new word it picked for the end of a sentence had no consideration of the words that were at the start of the sentence – and that produced sentences that made no sense.
These models are more complex, and offer much larger context windows.
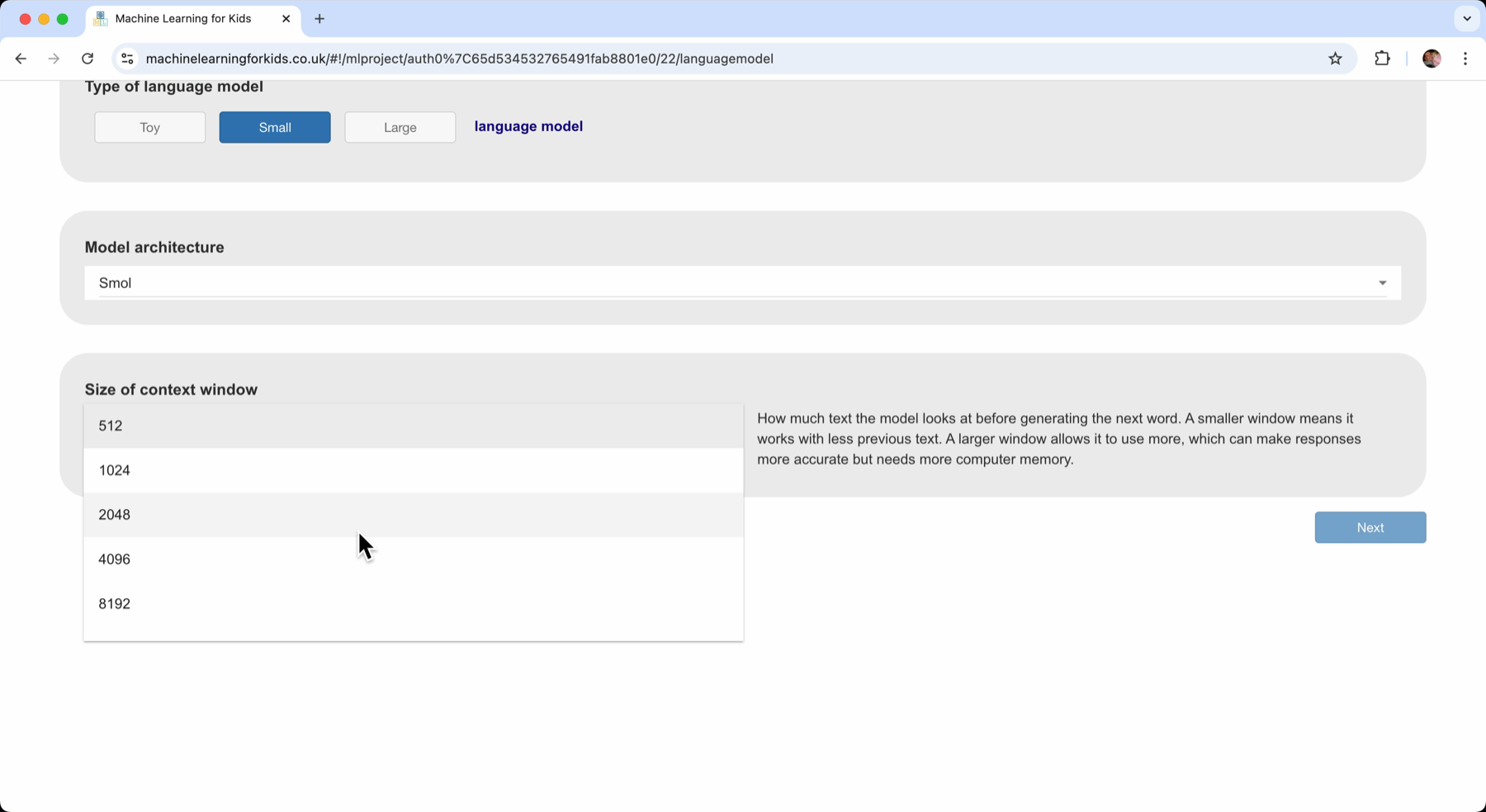
With a big enough context window, it can generate the next word not just based on the words in the current sentence, but based on my question and the last answer the model gave before that.
This makes chat interactions possible – I can ask a follow-up question because all of this is included in the context window.
Temperature and Top-P
youtu.be/Duw83OYcBik – jump to 29:50
Similar to the controls when creating the toy language model, sliders allow experimentation to see how the model behaves as the temperature and Top-P values are adjusted.
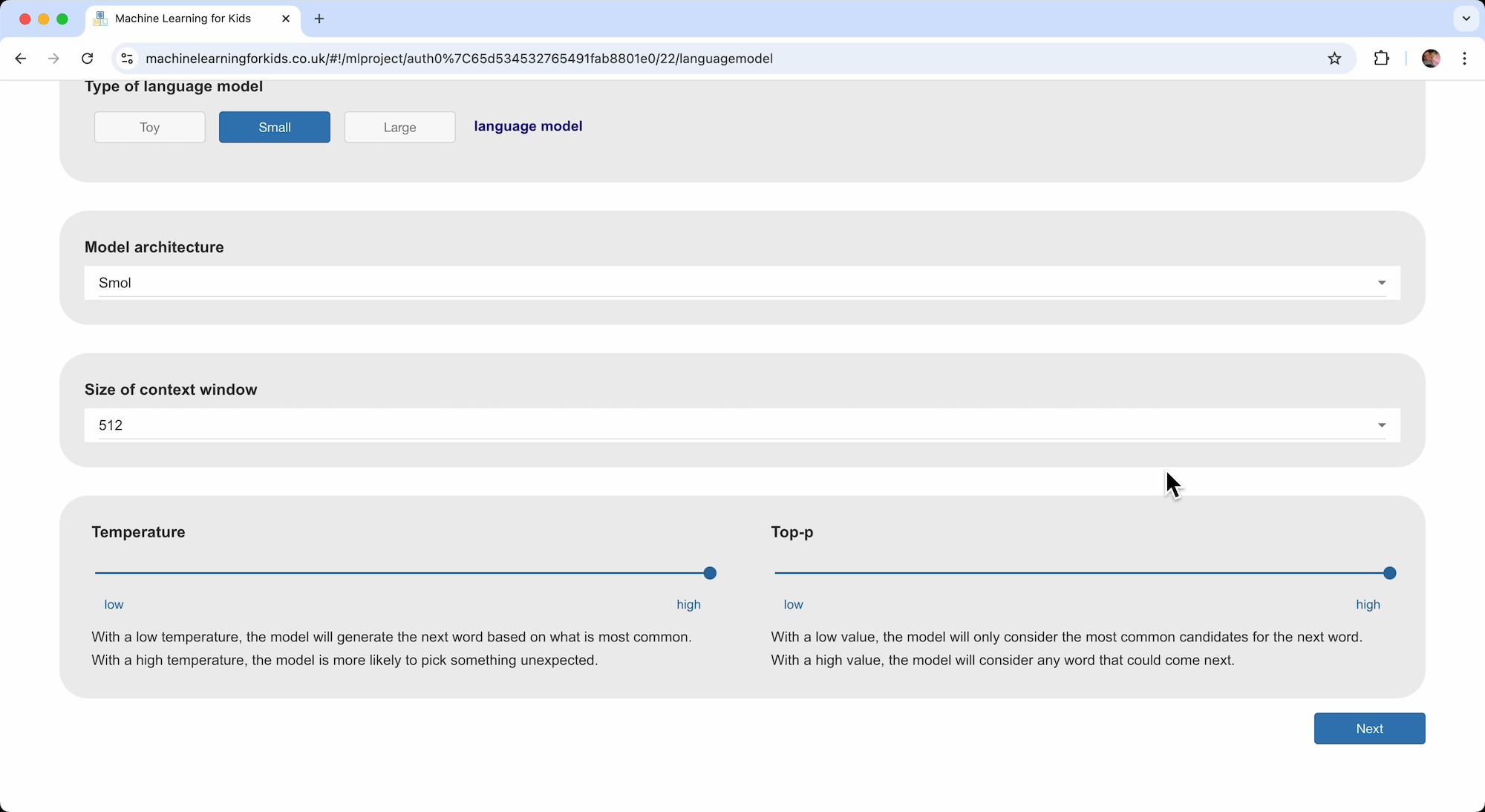
With a low temperature, the model will generate the next word based on what is most common. With a high temperature, the model is more likely to pick something unexpected.
With a low Top-P value, the model will only consider the most common candidates for the next word. With a high value, the model will consider any word that could come next.
Testing
youtu.be/Duw83OYcBik – jump to 30:35
Different types of prompts perform better with different settings.
For example, I can try asking factual or knowledge-based questions with a high temperature and Top-P
This results in creative, but completely inaccurate responses.
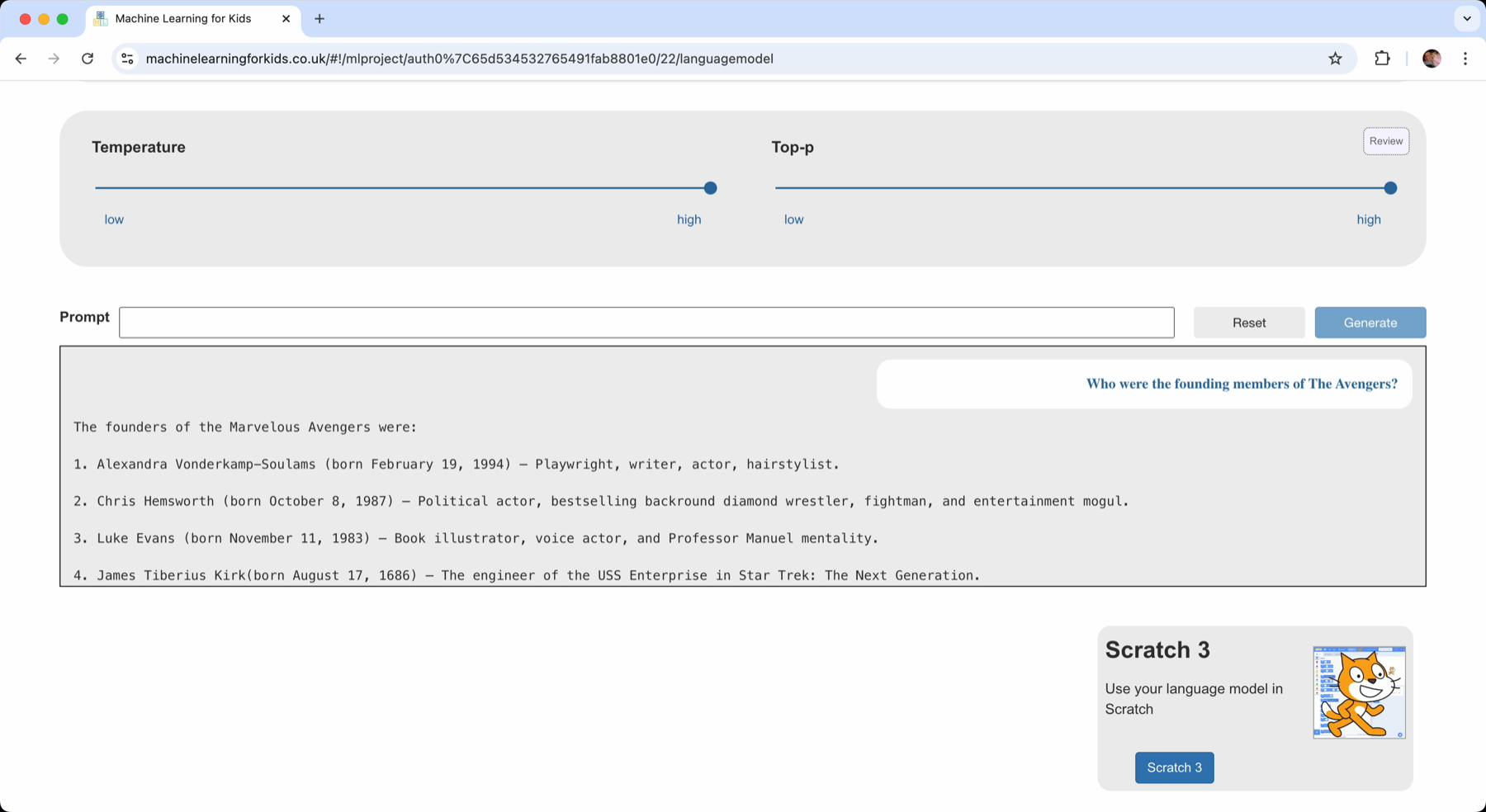
We ask language models to generate new text, but when it generates statements that aren’t true, we call these “hallucinations”. These are a problem when we use language models in the real world.
Temperature controls the randomness in text generation. With a high temperature, I increase the creativity by increasing the chance that less common, less likely words will be chosen.
For factual and knowledge based questions, these probably aren’t the right settings.
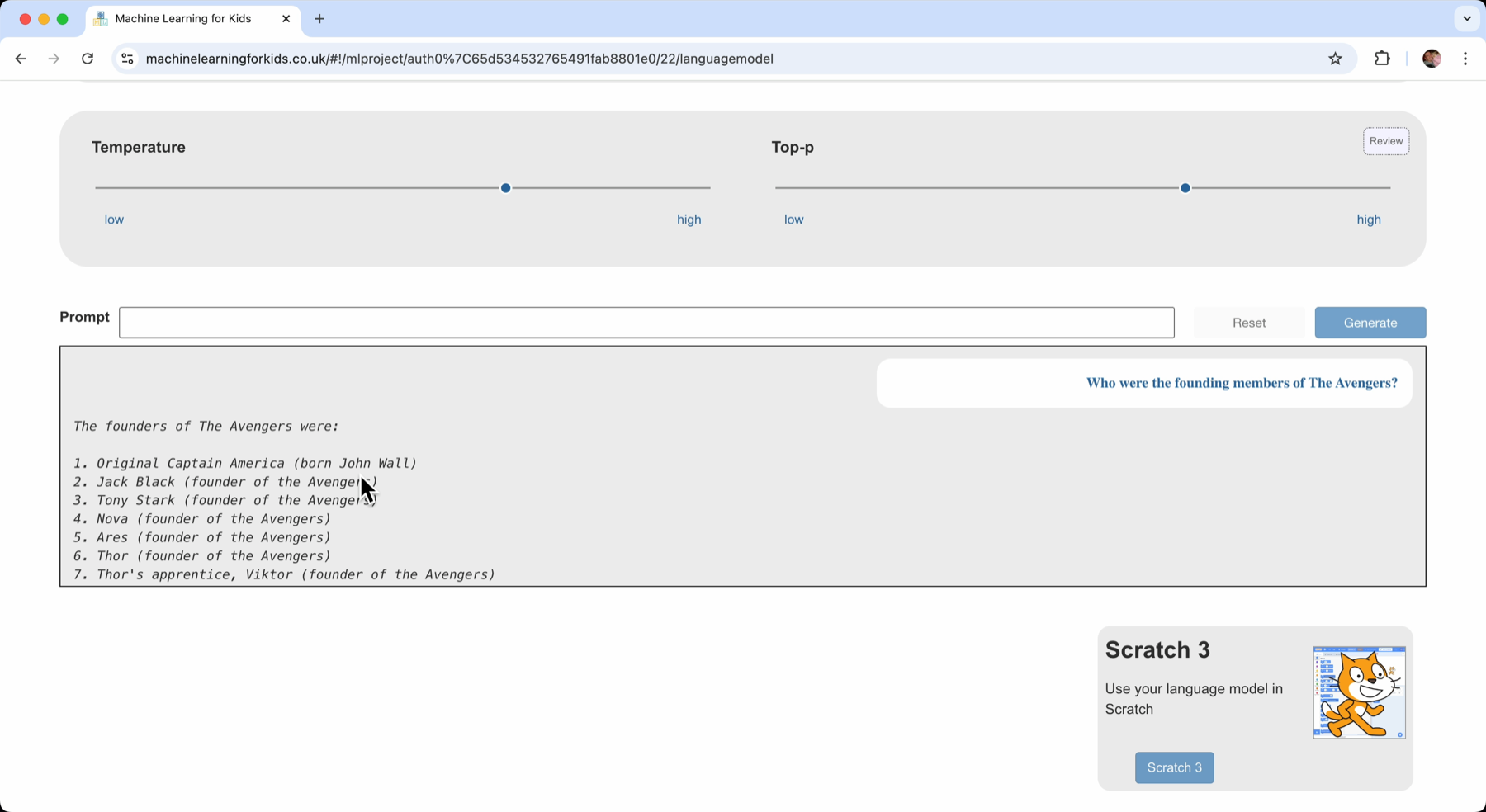
A lower temperature will make the model prioritise the most likely and most probable next words. A lower Top-P will limit the choices to the next words that are most likely and most probable.
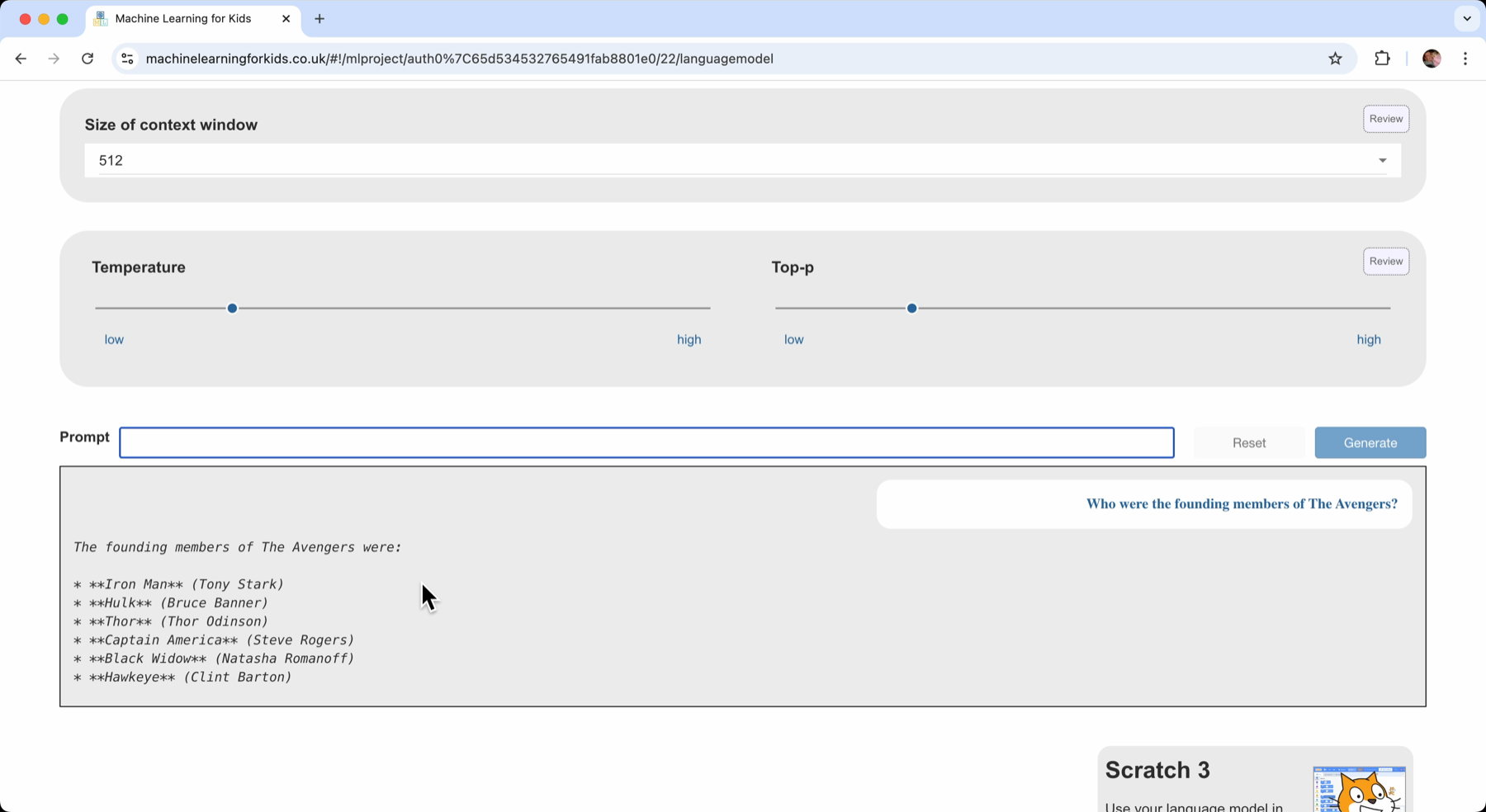
By playing and experimenting with the model, I can see for myself how this helps when asking fact-based or knowledge-based questions.
youtu.be/Duw83OYcBik – jump to 38:35
That isn’t the only use case for language models. You can also give them more creative prompts. To show an example of this, I tried asking the model to tell me a story. But with very low temperature and Top-P values, each time I asked produced a very similar story.
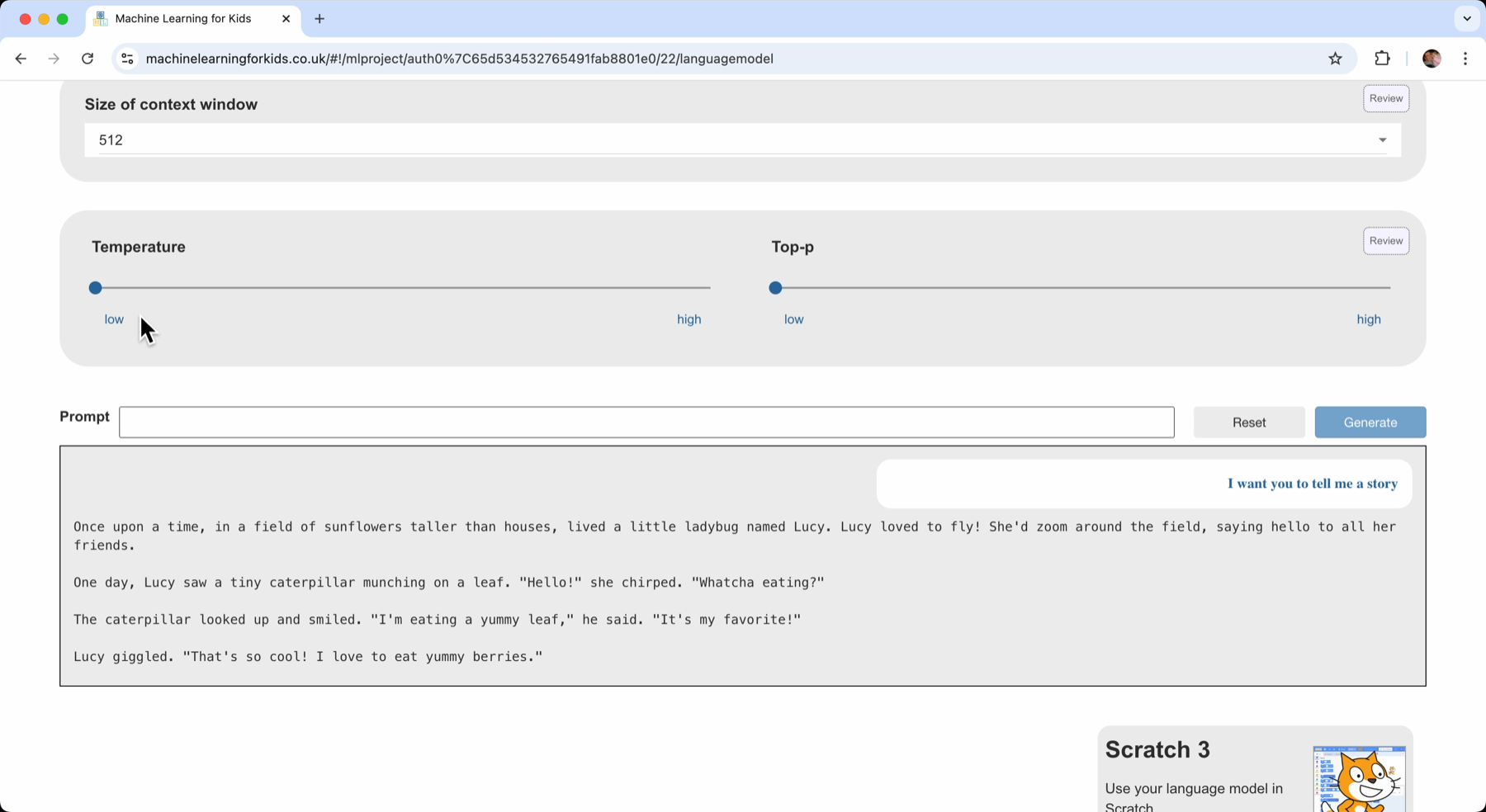
When asking fact-based questions, that is helpful behaviour. I want a similar answer to the same question every time I ask it. But when asking something like “Tell me a story”, randomness or creativity is better.
By increasing the temperature and Top-P values, and asking again for a story, I can see how I get more varied and different stories each time.
youtu.be/Duw83OYcBik – jump to 40:20
Scratch isn’t a good fit for displaying a large amount of text in one go – it would be better to display it in stages. To show how the model could help with that, I tried asking:
I want you to tell me a story, one sentence at a time. When I’m ready for the next sentence, I’ll say “next” – then you should continue the story.
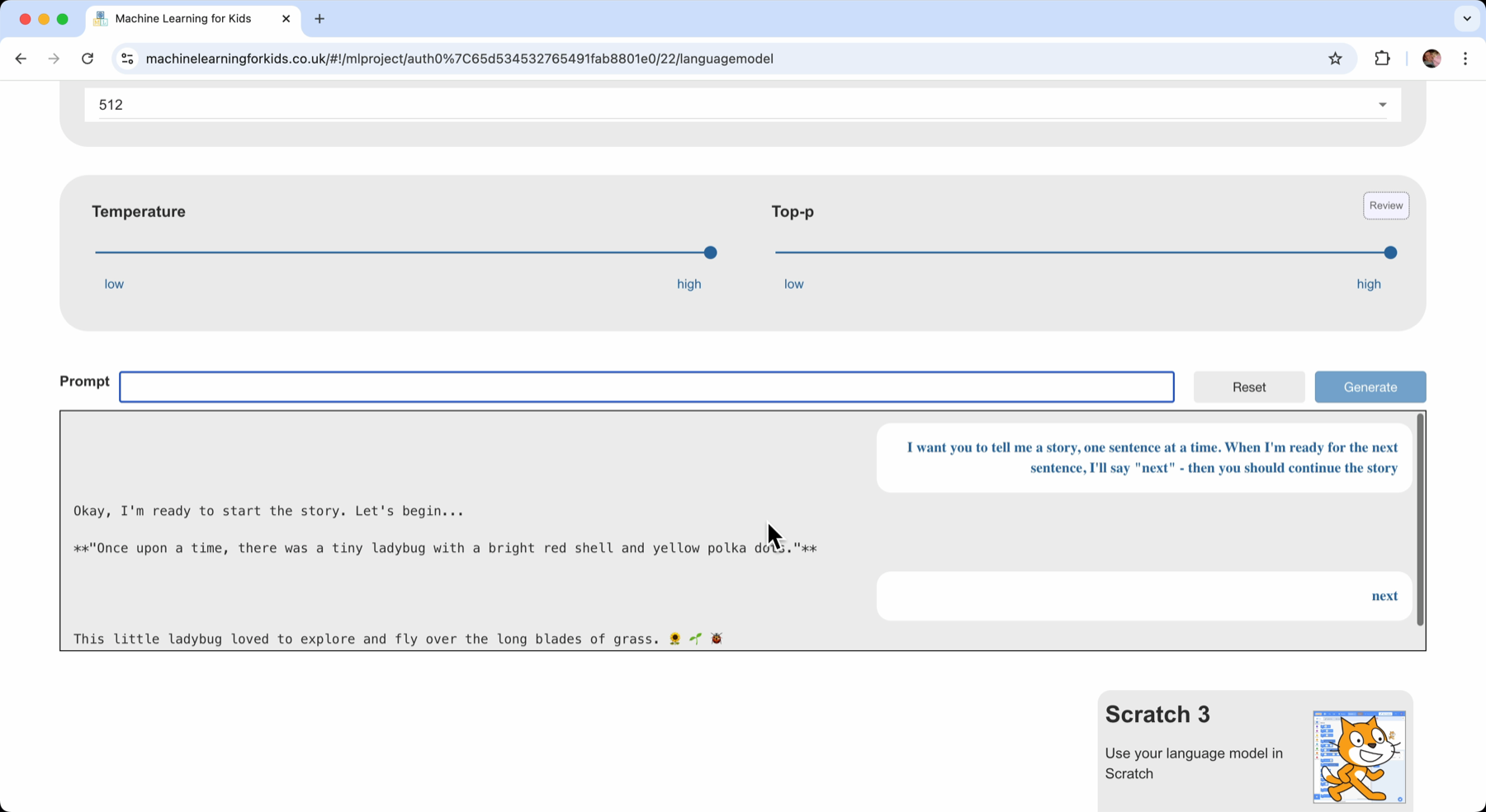
Each time I entered “next”, I got a bit more of the story.
For a while, this worked well. But after a few hundred words, it started to get stuck and generated incoherent sentences.
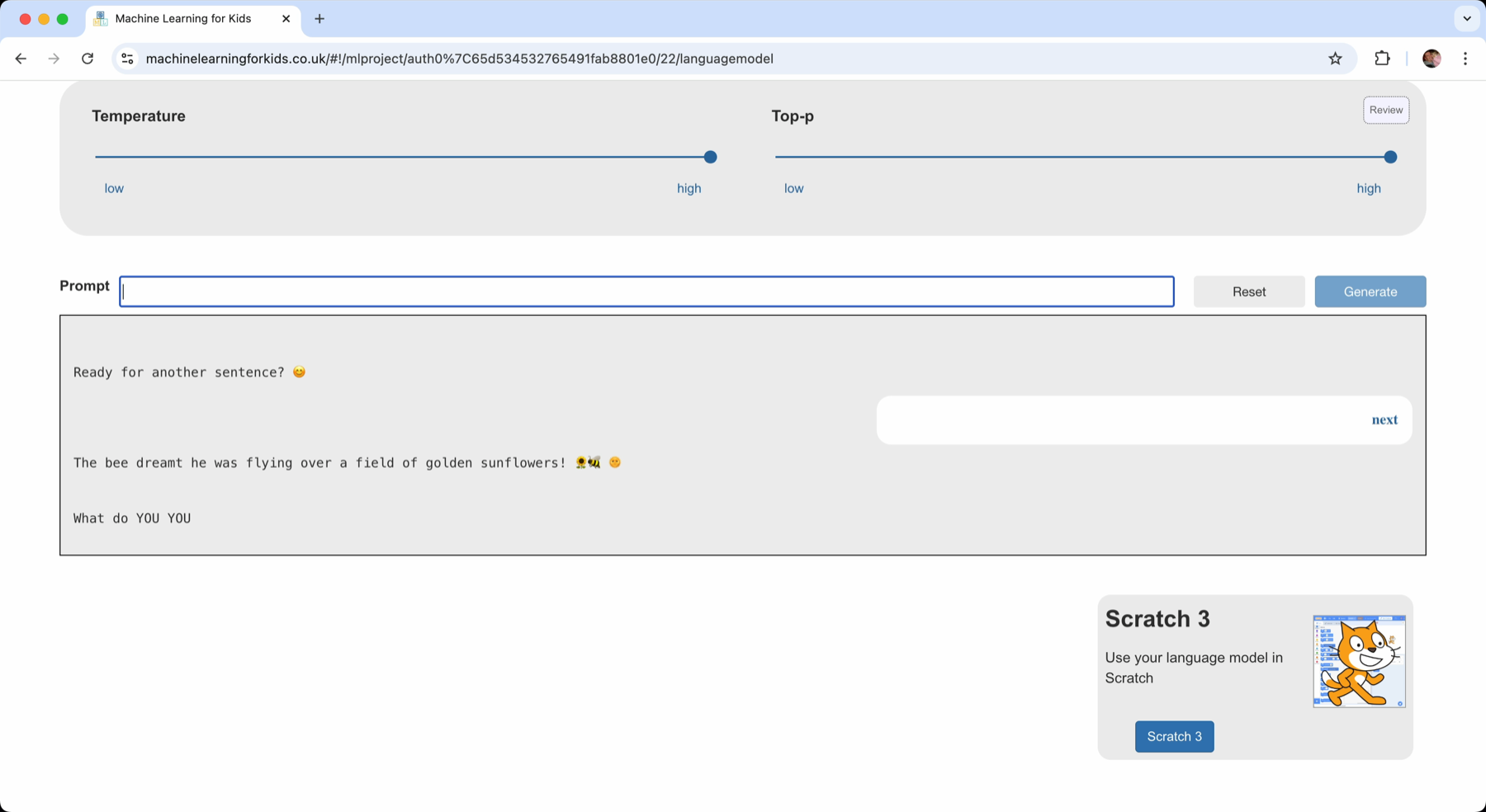
I had filled the 512-token context window I had chosen. This can be seen in the test window: older messages at the top of the chat history are removed when they no longer fit in the context window. The chat window is a visual representation of my current context window.
And in this case, my original prompt had gone. After the model had generated a lot of story text, my original prompt asking for a story no longer fit – so the model no longer had that in the context.
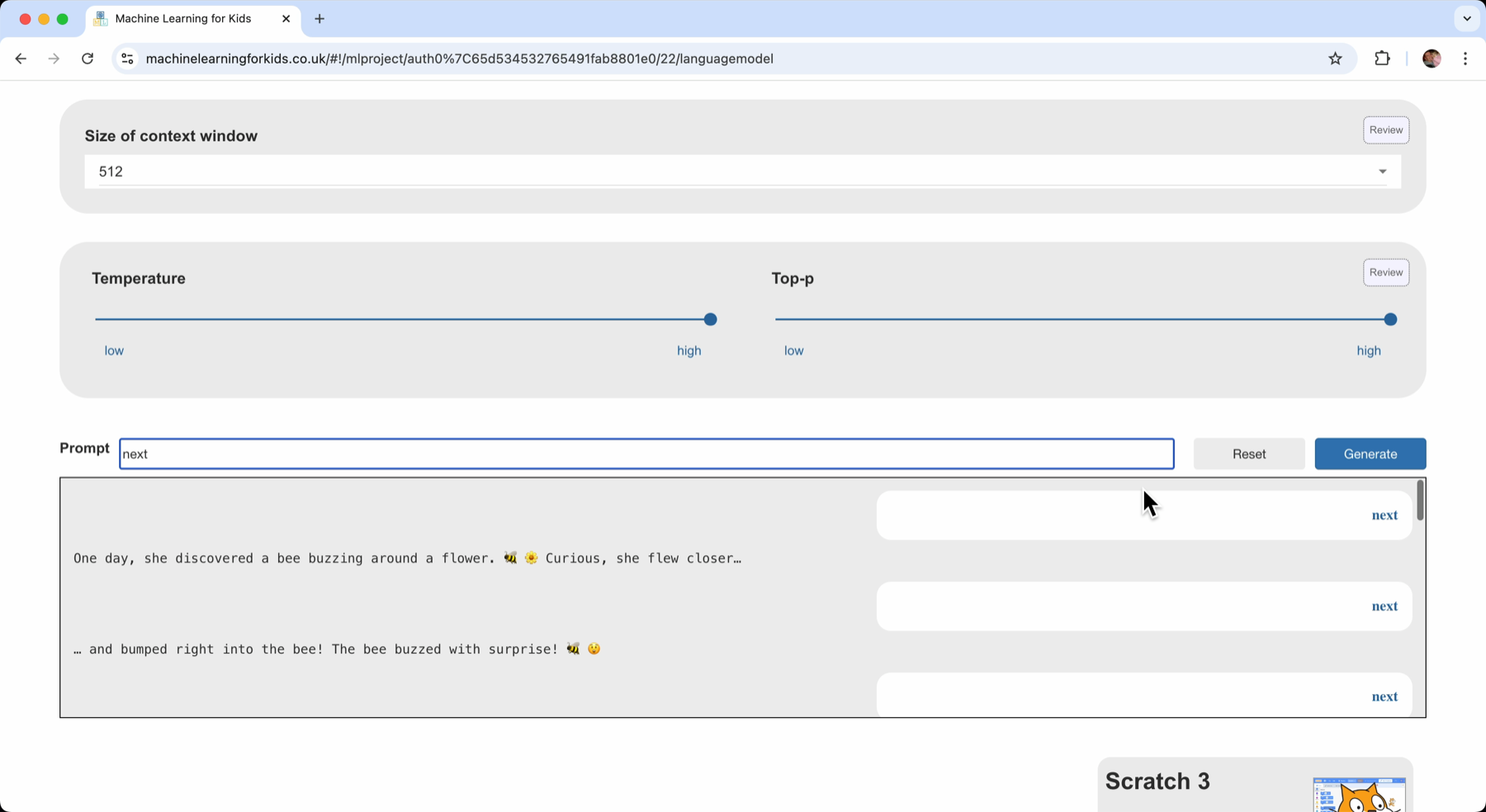
The test page lets me experiment with different context window sizes, so I can see the impact of how the larger window sizes lets the model handle longer and more complex chat interactions.
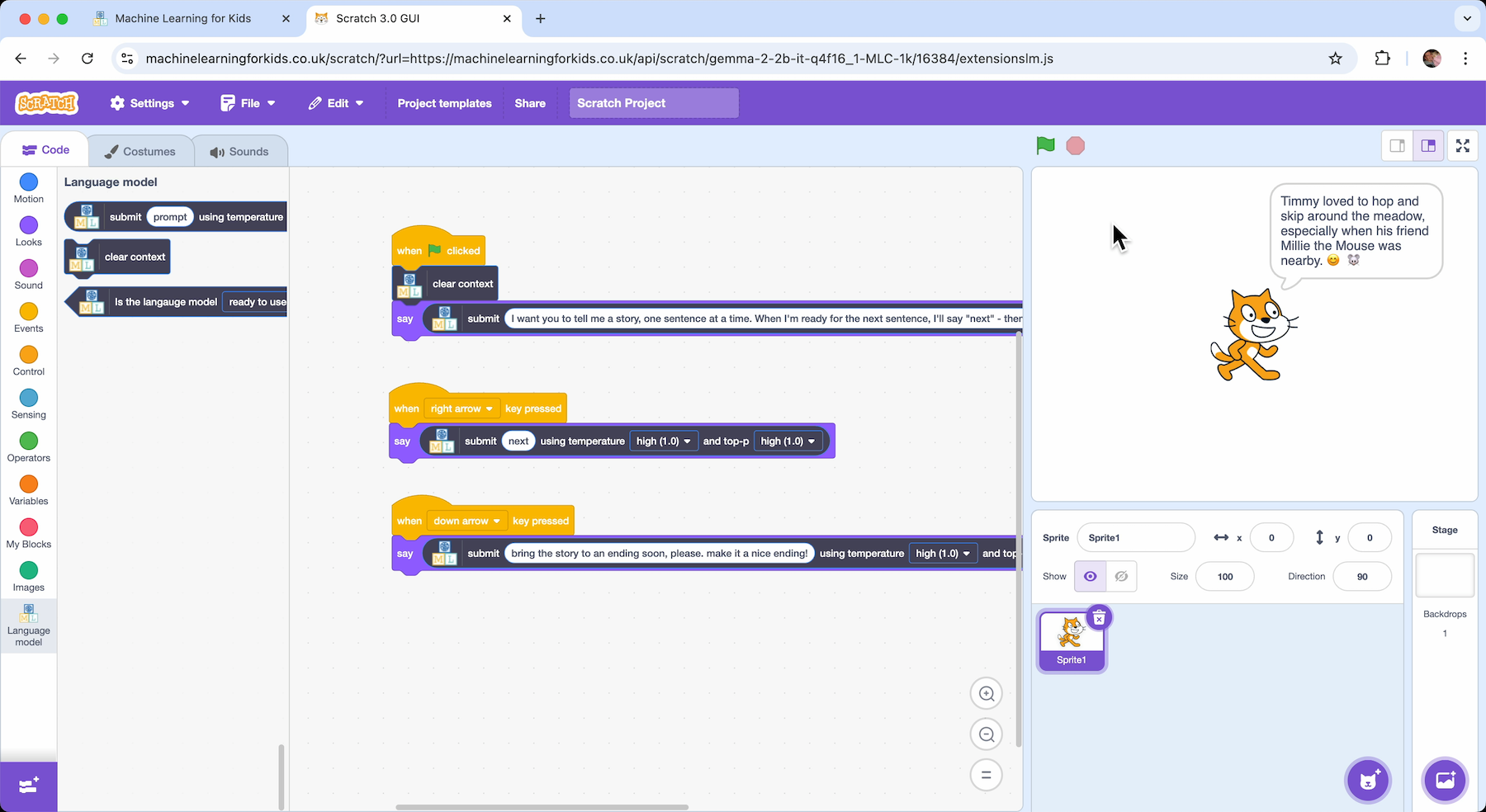
Using the model in Scratch
youtu.be/Duw83OYcBik – jump to 44:08
After increasing the size of the context window, I took this “story teller” idea into Scratch.
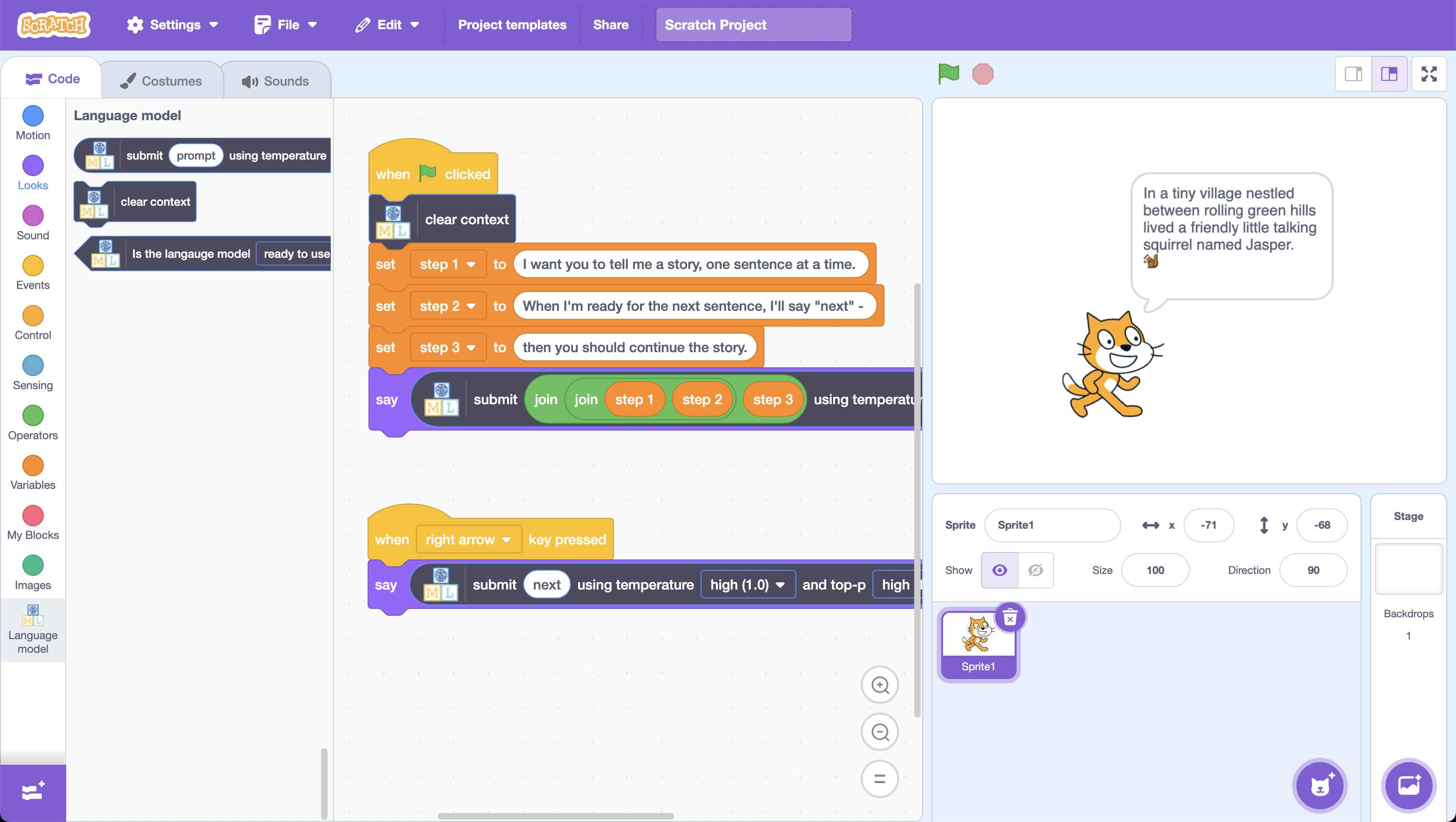
When clicking the Green Flag, it clears the current context and enters the prompt:
I want you to tell me a story, one sentence at a time. When I’m ready for the next sentence, I’ll say “next” – then you should continue the story.
When pressing the right arrow, the “next” prompt is submitted to the model:
next
And to stop the story carrying on too long, when pressing the down arrow, the following prompt is submitted:
Bring the story to an end soon, please. Make it a nice ending!
That is enough to make a simple “story teller” project in Scratch, powered by a language model like Llama or Gemma.
Learning by experimenting
By configuring and testing a small language model, the sorts of principles explained by creating the toy language model are shown in action for real.
These small models aren’t as complex or sophisticated as the large language models available in the cloud. They make mistakes more often. But in a way, I think that’s useful. It’s useful to see that these technologies aren’t infallible. They make mistakes. They hallucinate. They make stuff up. And when they do make stuff up, it’s hard to tell that apart from when it is giving you facts – because in both cases, it’s just generating the next new word, based on patterns of what words have come next in the past.
Tags: machine learning, mlforkids-tech, scratch