I have a lot of digital photos.
An insane amount – something like 40,000 photos that go back over a dozen years since I first got a digital camera at University.
I store them based on the date that they were taken, using a folder structure like this:
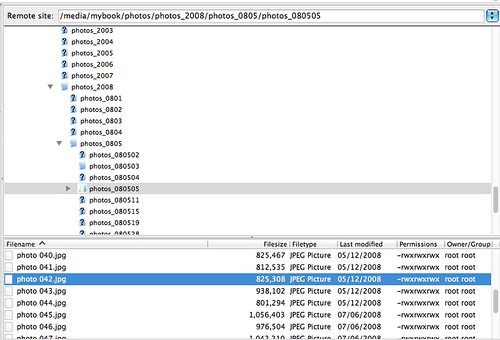
For a while, I used to drop a readme.txt text file into some of the folders saying where the photos were taken or what I was doing. This was partly so that when I look at the photos ten years later I’ve got something to remind me what is going on, but mainly to make it possible for me to search for photos of something when I can’t remember the date it happened.
But in recent years, I’ve been too lazy to keep that up, and rarely ever add a readme file.
I thought that my tweets might be a good alternative. There is a reasonable chance that if I took a photo of something interesting, that I might have tweeted sometime that day about where I am or what I’m doing.
I wanted to populate each of my folders with a day’s photos in it with a tweets.txt text file containing tweets posted on that day.
I signed up for Twitter Backup from Tweetstream back in March (because I tend to sign up to any new website I hear of in case it ends up being useful!) and it’s been downloading my tweets.
Finally, I found a use for tweetstream – they let me download my twitter history (as far back as July 2009, anyway… because I had more than 3,200 tweets when I first signed up with them) as a json file.
With that, it was just a matter of hacking a little bit of Python to grab the tweets and copy them into the folders with my photos.
#######################################
# IMPORTS
#######################################
# lets us parse the twitter data
import json
# lets us check for existence of photo folders
import os
# lets us parse tweet timestamps
from datetime import datetime
# lets us persist state between runs of the script
import pickle
#######################################
# CONSTANTS
#######################################
# the root folder for where my photos are stored
photos_root = "/media/mybook/photos/"
# the folder structure for where photos taken on a given date
# are stored, relative to photos_root
filesystem_date_format = "photos_%Y/photos_%y%m/photos_%y%m%d/"
# the name of the file used to store tweets
tweets_file_name = "tweets.txt"
# the time string format used in the twitter data being parsed
#
# Notice that I'm ignoring the timezone, as the built-in
# datetime library makes parsing it a pain (and I'm being
# lazy).
#
# I can ignore it as I'm in the UK, so this is always "+0000"
# for me anyway. You might need to change this to fit your
# locale.
twitter_date_format = "%a %b %d %H:%M:%S +0000 %Y"
# for getting a time string from a datetime object
short_time_format = "%H:%M:%S"
#######################################
# STATE
#######################################
# last tweet stored - so that the next time we run this script
# with a more recent set of tweets, we don't re-store the same
# older tweets again
# first time we run it, just leave it as 0
most_recent_tweet_id = 0
if os.path.exists('last_tweet_processed.dat'):
with open('last_tweet_processed.dat', 'r') as state_file:
most_recent_tweet_id = pickle.load(state_file)
#######################################
# SCRIPT
#######################################
# open the file containing tweets from my timeline and parse
# it into an array of tweet objects
json_data = open('timeline.json')
timelinedata = json.load(json_data)
json_data.close()
# for each tweet in the array contained in the json file...
# (Note that the tweets are stored in reverse chronological
# order. I prefer chronological order, so I go through the
# array in reverse.)
for tweet in reversed(timelinedata):
# if we've not already looked at this tweet...
# (notice that we're assuming tweets in the data will
# be stored in id order - but this appears to be a
# safe assumption)
if tweet['id'] > most_recent_tweet_id:
# use the time the tweet was created to work out
# the folder where photos on this date will be
# stored
tweetdate = tweet['created_at']
tweettimestamp = datetime.strptime(tweetdate, twitter_date_format)
relative_folder_path = tweettimestamp.strftime(filesystem_date_format)
folder_path = photos_root + relative_folder_path
photos_exist = os.path.exists(folder_path)
# do we have any photos for this date?
if photos_exist:
# get the bits of the tweet that we want to use to
# annotate the photos - the URL for this tweet,
# the time it was sent (we don't need the date as
# the location of the file tells us that), and
# the tweet text itself
tweet_url = "http://twitter.com/" + tweet['user']['screen_name'] + "/status/" + tweet['id_str']
tweet_time = tweettimestamp.strftime(short_time_format)
# some tweets can have unusual characters - ignore them
tweet_text = tweet['text'].encode('ascii','ignore')
# we also get the human-readable description of
# the place that the tweet was sent from, if it
# is available
tweet_place = None
if tweet['place']:
tweet_place = tweet['place']['full_name']
# append the tweet info to a 'tweets.txt' file in
# the photos directory
tweets_file_path = folder_path + tweets_file_name
with open(tweets_file_path, 'a') as tweets_file:
tweets_file.write(tweet_time + "\n" + tweet_text + "\n" + ((tweet_place + "\n") if tweet_place else "") + tweet_url + "\n\n")
# update the ID of the tweet that we have processed
most_recent_tweet_id = tweet['id']
# update the most recent tweet that we processed so that
# we don't duplicate it
with open('last_tweet_processed.dat', 'w') as state_file:
pickle.dump(most_recent_tweet_id, state_file)
And there we go.
With tweetstream doing most of the hard work, I can use my tweets to annotate my photo collection. Neat 🙂
dale@media-hub:/media/mybook/photos/photos_2011/photos_1108/photos_110828$ ls DSC02602.JPG DSC02615.JPG DSC02630.JPG DSC02644.JPG DSC02656.JPG DSC02609.JPG DSC02623.JPG DSC02636.JPG DSC02650.JPG DSC02662.JPG DSC02610.JPG DSC02624.JPG DSC02637.JPG DSC02651.JPG MOV02664.MPG DSC02611.JPG DSC02625.JPG DSC02638.JPG DSC02652.JPG tweets.txt DSC02612.JPG DSC02626.JPG DSC02639.JPG DSC02653.JPG DSC02613.JPG DSC02627.JPG DSC02641.JPG DSC02654.JPG dale@media-hub:/media/mybook/photos/photos_2011/photos_1108/photos_110828$ more tweets.txt 13:37:15 I've had a productive day, digging holes to put children in. :-) http://t.co/4T2Ma16 Christchurch, Dorsetdale@media-hub:/media/mybook/photos/photos_2011/photos_1108/photos_110828$I've had a productive day, digging holes to put children in. :-) http://t.co/4T2Ma16
— Dale Lane (inactive) (@dalelane) August 28, 2011
Rather than storing this sort of information alongside your photos, why not embed it into the EXIF data of the jpg so it always stays alongside it?
And also, why this seemingly manual storage system rather than using one of the many great photo management apps like Picassa, F-Spot, Lightroom, iPhoto, Aperture etc. ?
Hey Dom
Why not use EXIF data instead of txt files? Partly because I don’t have only jpgs here – there are lots of video files too, for example. Partly because I just wanted to keep it simple.
Why manage the folder structure myself? Since 1998, when I started collecting digital photos, I’ve switched photo management app several times. At the moment, I am using Picasa, manually dropping photos into folders that I create, then letting Picasa discover them.
But I don’t imagine that I’ll still be using Picasa in another ten years. (In fact, given the rate that Google are killing off non-core parts of their business, I’m not sure it’ll still be around in ten years!) So I don’t want to get too tied into any photo app’s DB – I like that I can switch apps at any time.
Nice! Aligning different types of data sets along the common dimension of time seems to be a mighty concept, especially in the context of self tracking.
Another nice little idea and script Dale.
I have similar views to you on switching photo management app, I’ve changed a couple of times myself and currently manage my directory (note the proper term here, none of this bloody “folder” Microsoft nonsense) structure manually and simply use Gimp for touch-ups. My directory structure is sorted by year and activity similar to the naming convention I use on my Flickr sets. For example, after going on holiday to Ireland this year all my pictures get stored in 2011/Ireland which makes it easy to see when and where pictures were taken. Using Exif is a decent idea for images which is something I intend to do if I ever move away from Flickr one day i.e. download all my titles/descriptions/geo info/etc from Flickr and store it in Exif data (there are already some scripts that go some way towards doing that for you).
I’ve rambled a bit already but I have one further thought. I liken this sort of problem to my music collection too – that is, I’ve used a few different music apps over the years and hence haven’t managed to keep a database of all my song plays, favourite songs and all that other sort of stuff a modern media player keeps track of. I have, however, got this information store on last.fm and these days I don’t bother to take any notice of my local media database any more than necessary and use info from my central store on the Internet. I wonder if the same could be true for pictures, all we care about is when/where/why for our images so storing that centrally somewhere (Internet or otherwise) would be immensely useful. I hate to say it, but standards can actually be useful.