In this series of posts, I will outline the most common patterns for how artificial intelligence and machine learning are used in event driven architectures.
I’m at a Kafka / Flink conference this week.

This morning, I gave a talk about how AI and ML are used with Kafka topics. I had a lot to say, so I’ll write it up over the next few days:
- the building blocks used in AI/ML Kafka projects (this post)
- how AI / ML is used to augment event stream processing
- how agentic AI is used to respond autonomously to events
- how events can provide real-time context to agents
- how events can be used as a source of training data for models

In this first post, I’ll outline the building blocks available when bringing AI into the event-driven world, and discuss some of the choices that are available for each block.

Naturally, this all starts with a topic – but as this was a talk at a Kafka conference, I didn’t need to explain anything about topics.
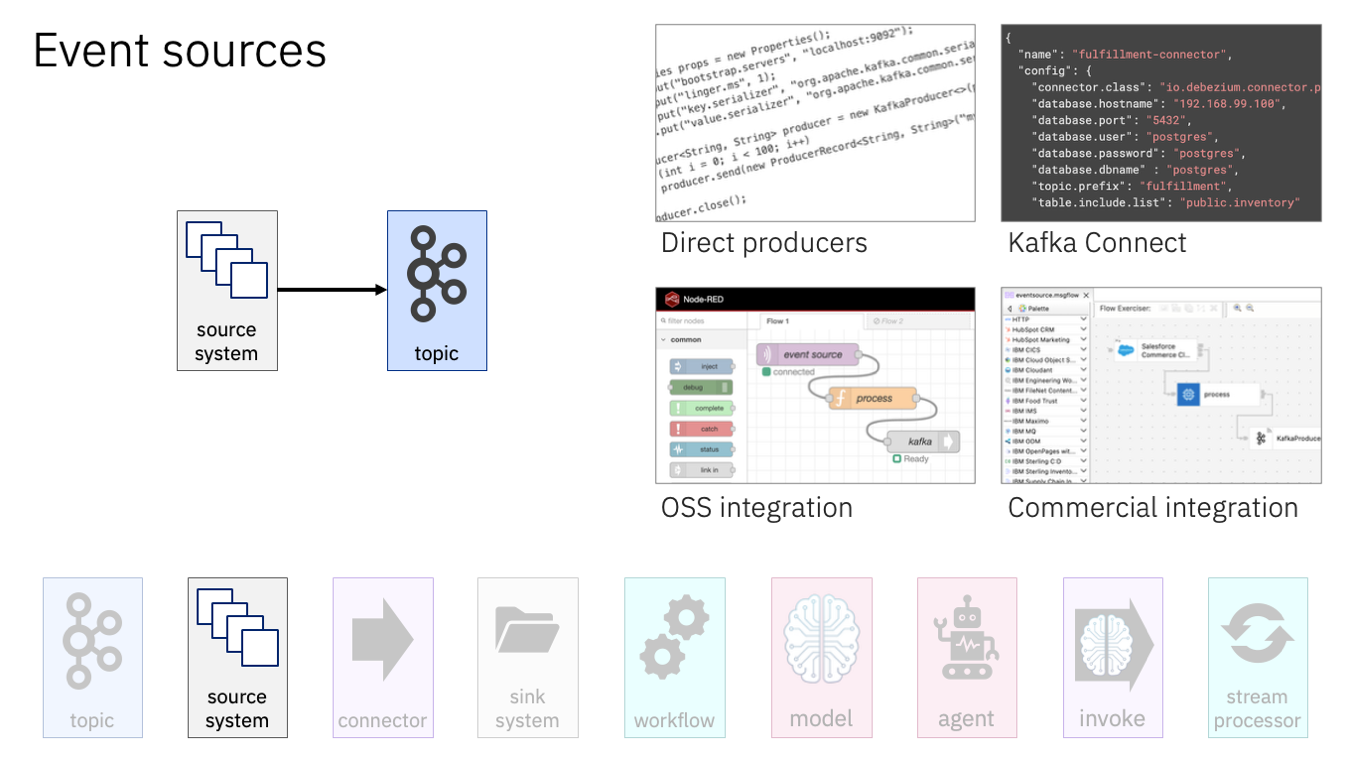
You need a source of events for those topics. There are lots of ways to bring in events from critical business systems, such as:
- writing code using a Kafka client library
- selecting an existing Connector
- using a low-code drag-and-drop integration platform
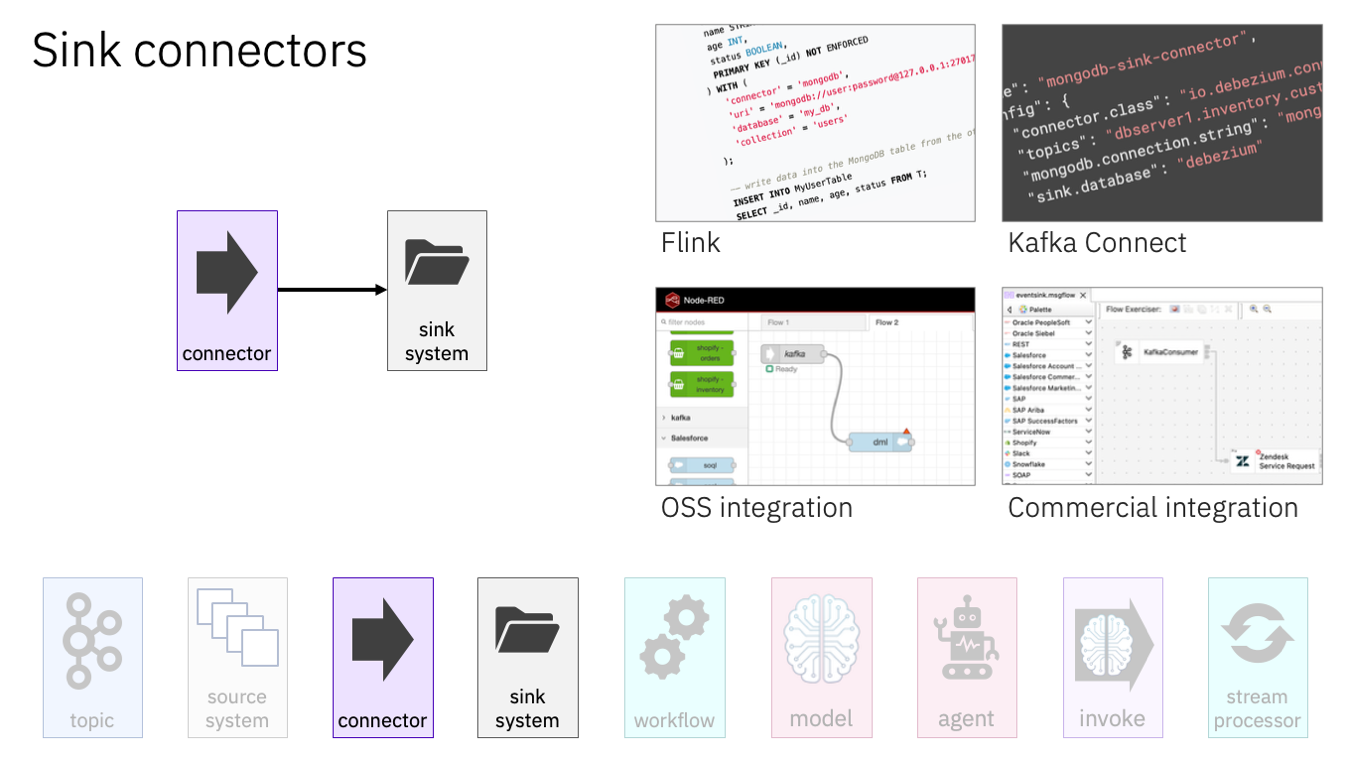
The same is true for sending the results of an AI-enhanced event stream processing to somewhere.
How teams do this is normally determined by how they are doing the processing.
For example, if they’re using Flink, Flink has a range of connectors that make it easy to sink the output into a range of downstream systems.
Or if they’re using an integration platform, those often come with a range of sink connector options.
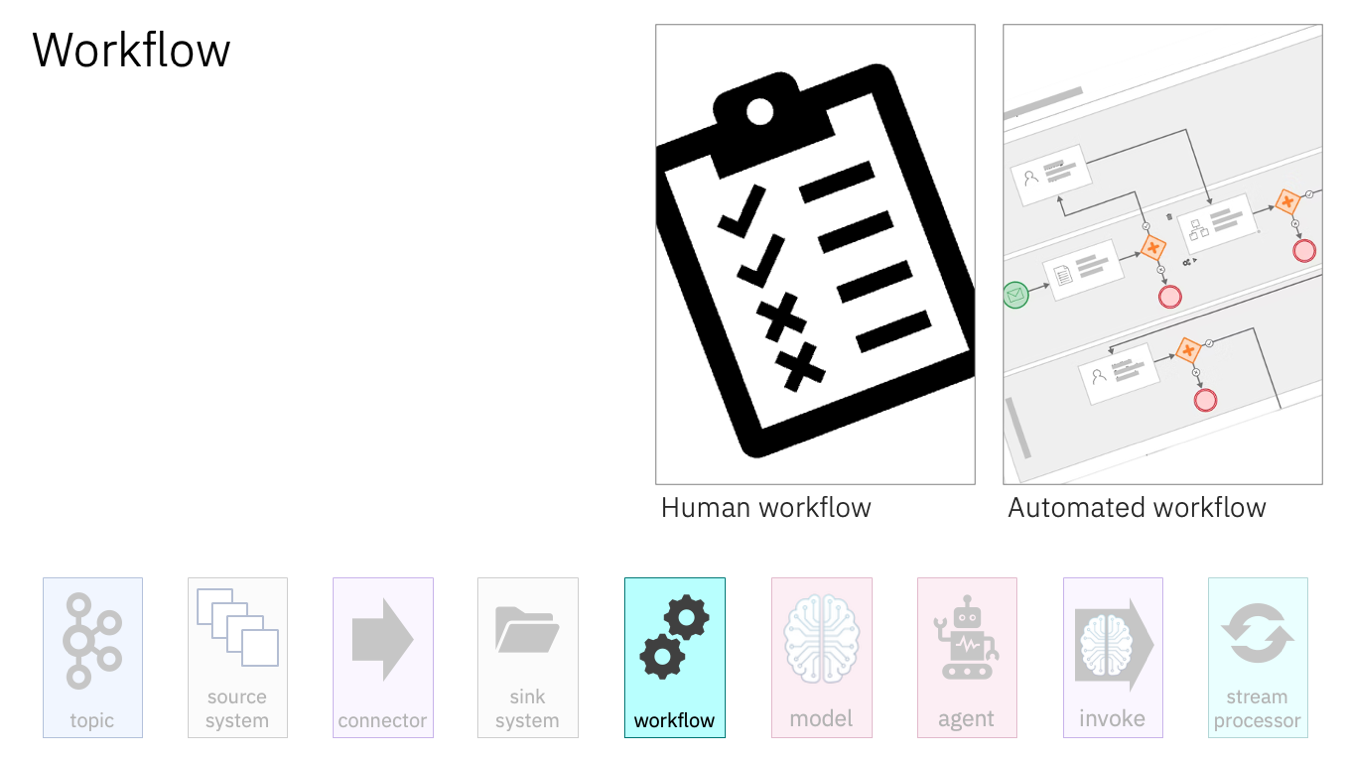
Teams don’t always focus on just storing the event processing output. They want to respond to the insights the AI has helped them spot in the moment – to notify a person to go and do something, or to trigger some automated business process.
Business process management tools like the open source Process Automation Manager have great support for Kafka. Workflows can be triggered by Kafka events.
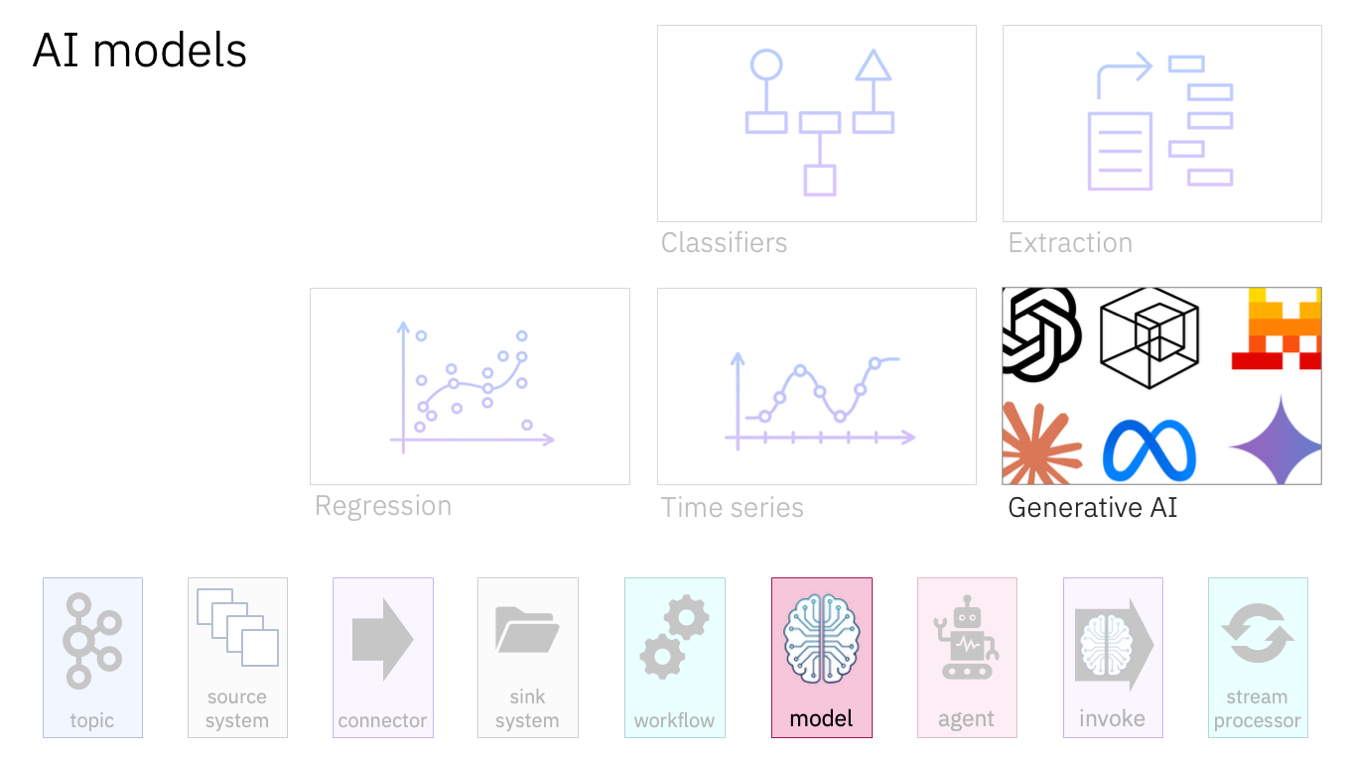
It’s easy to get caught up in the hype of generative AI, and to think that “AI” equals “Generative AI”.
Generative AI models are exciting, and enable some amazing new use cases. But they’re not the only tools in our tool kit.
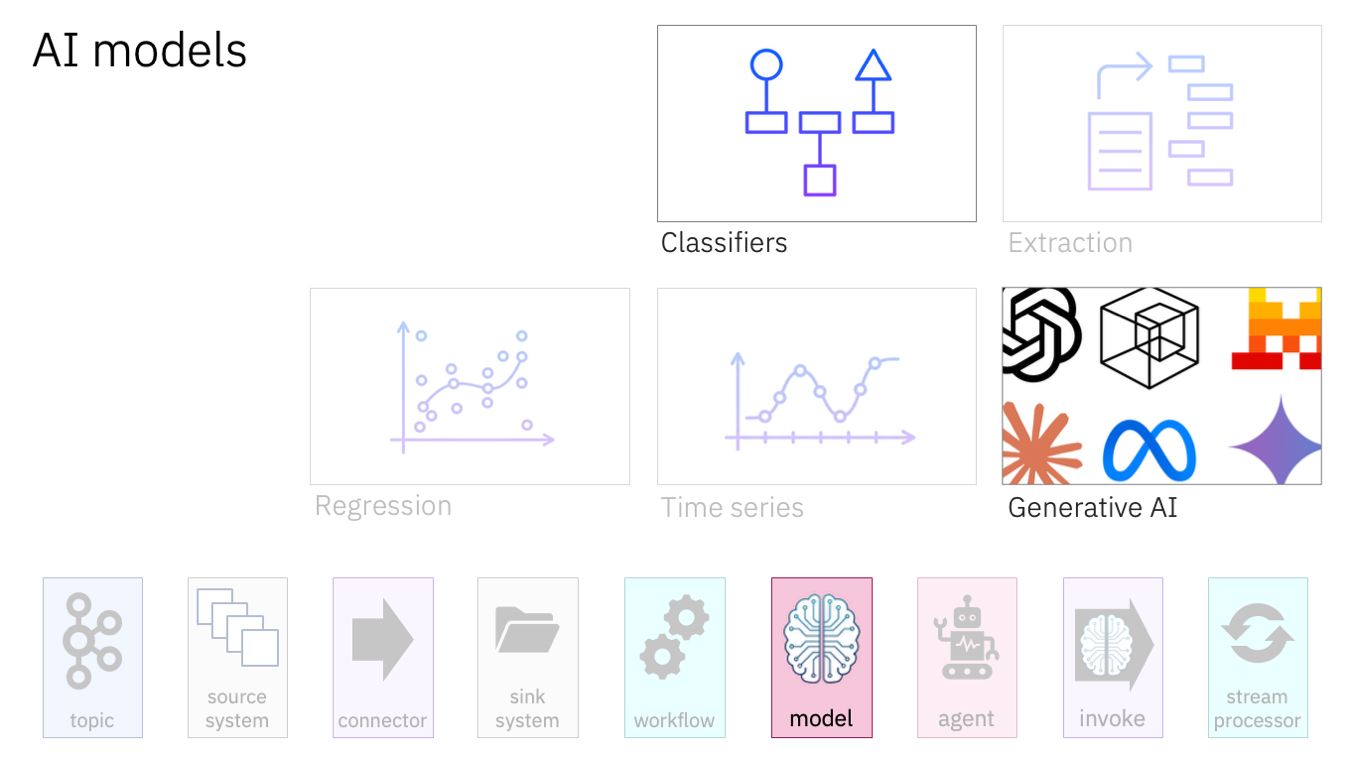
Classifiers can recognise events.
Maybe this sort of event should be processed in one kind of way, and that sort of event should be processed in another way. If the way to recognise what sort of event is which isn’t something that can easily be described in fixed rules, then a classifier can fill that gap.
To use a non-Kafka example, think of the traditional email spam filter – it recognises what to do with new emails as they arrive. Bring those tried and trusted techniques to your Kafka events.
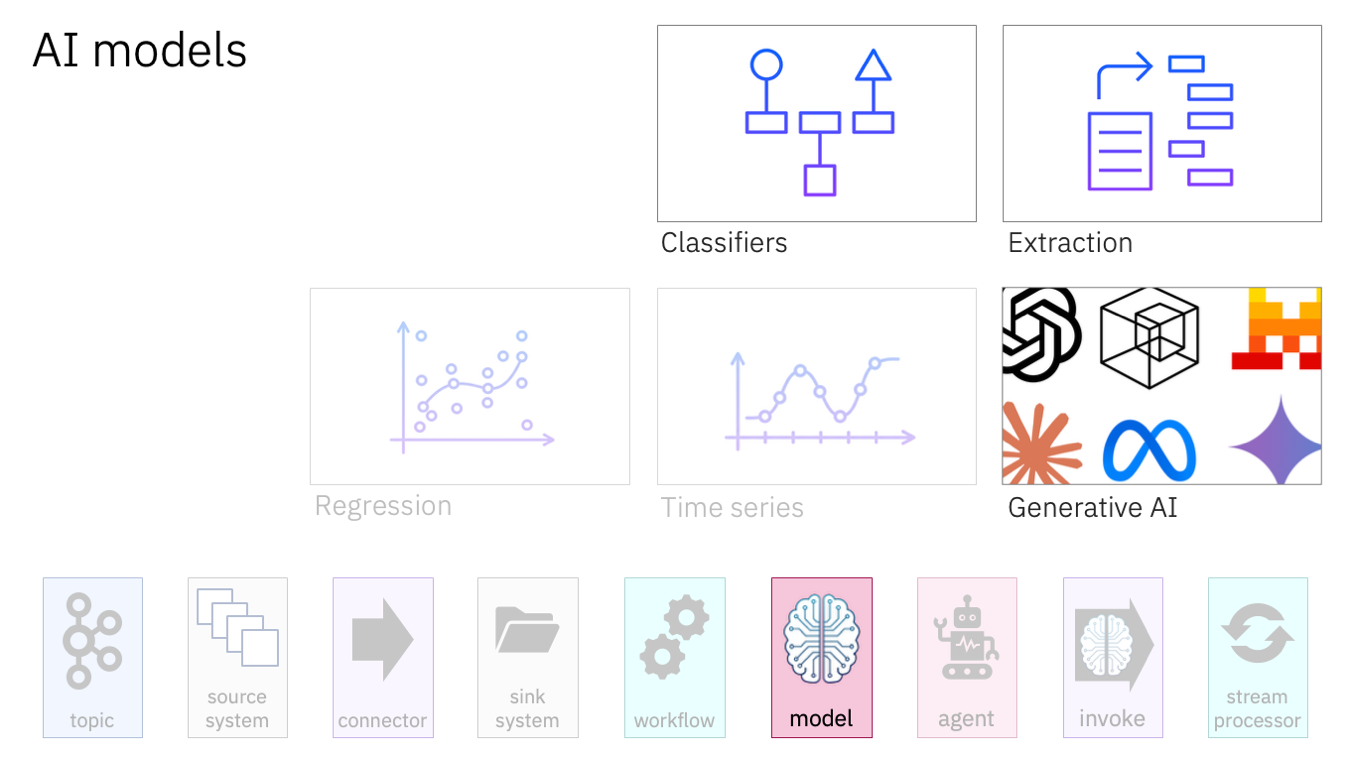
Extraction models pick out the interesting bits from the less structured data in events.
For example, given a sentence like “John Smith bought 12 shares of Acme Corp in October 2025”, an entity extraction model can identify that “John Smith” is a name of a person, “Acme Corp” is the name of an organisation, and “October 2025” is referring to a date.
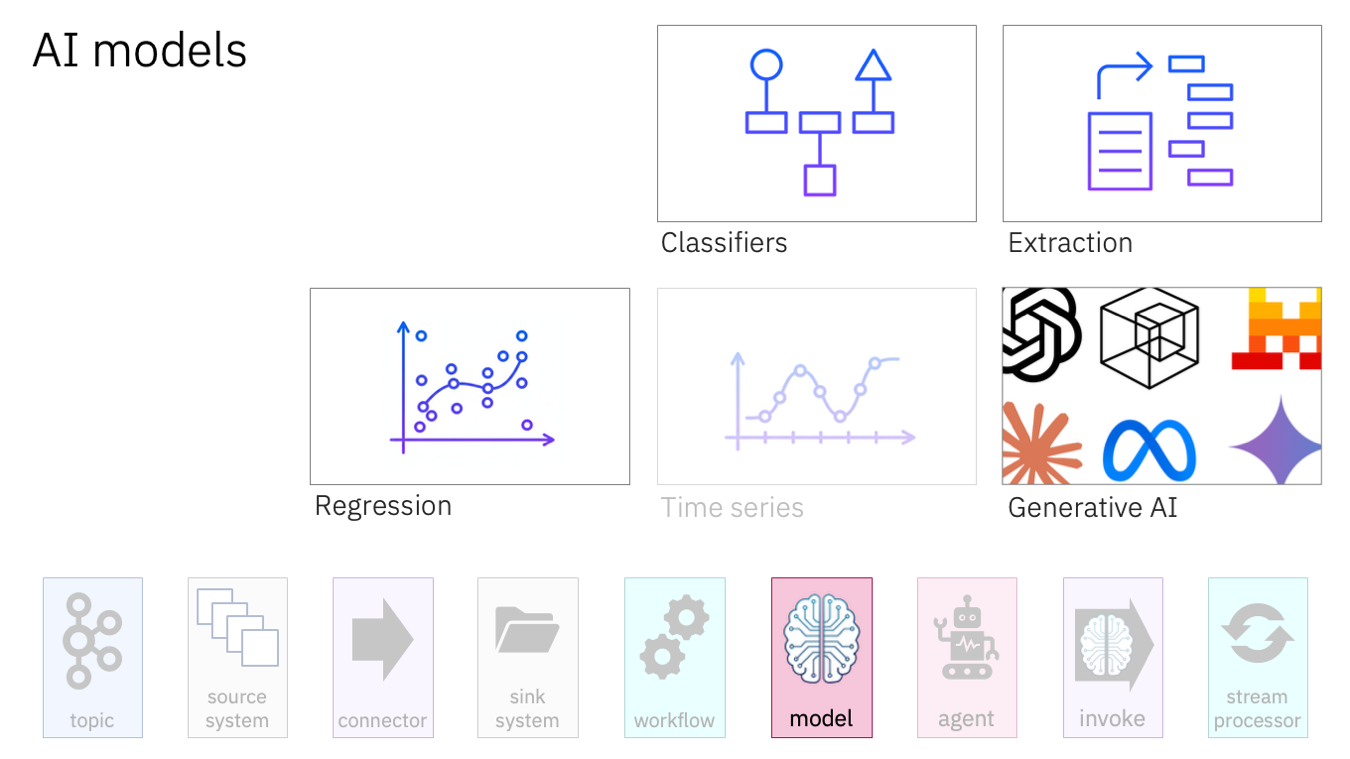
Regression models estimate useful computed values from structured data in Kafka events.
For example, given a variety of values about a house, a regression model can estimate the house price.
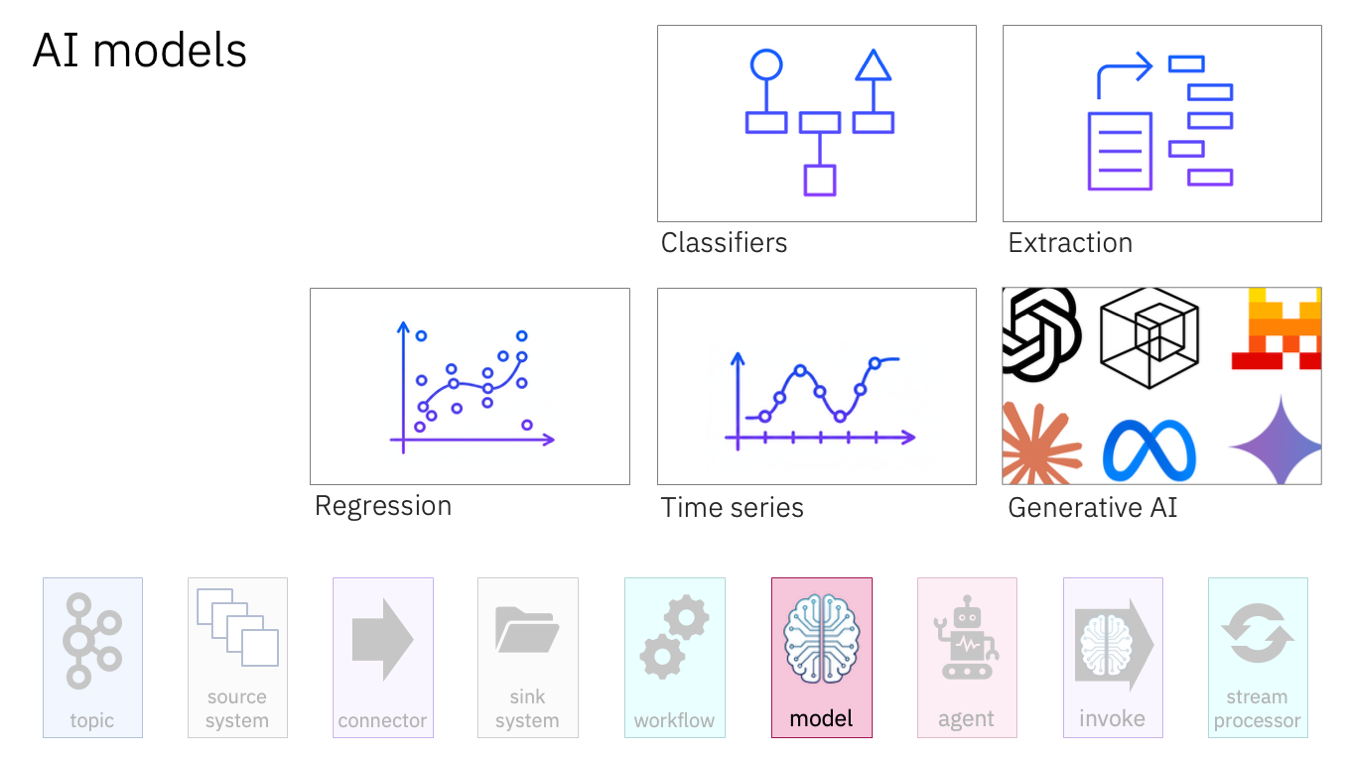
Time series models analyze sequential data (data that is ordered sequentially over time and labelled with timestamps). That makes them perfect for use with Kafka. They can predict future values and identify anomalies.
We have a lot of model types to choose from.

We have options about where we put them, too.
Many models, like a sentiment analysis classifier, have a tiny footprint, so it’s easy to self-host them, embedded in a solution or as a standalone API.
The logo on the slide is from Kubeflow which runs more complex models as just another Kubernetes-native component.
With Ollama, even small generative AI models can be self-hosted in simple containers.
For teams running their EDA in a cloud, they can find AI APIs ready to use without needing to go off-platform.
IBM, AWS, Azure, Google – all come with a range of machine learning models: Generative AI models, all the other types I just went through, and more.
They’re all fronted by REST APIs that are easy to integrate with every event processing platform.
For teams with bespoke requirements, who need a model tailored to their specific business, use case, or data, there are Data platforms. IBM’s Cloud Pak for Data is one example amongst several.
It lets teams load in their own data, makes it easy to create a custom model from it and highlights problems like bias or drift.
And if wanted, it can host the model afterwards.
And for teams who want Generative AI, of course there are also the dedicated Gen AI cloud services too.

Not all AI needs to be agentic, but that is an approach that is getting attention.
New agentic frameworks seem to be appearing every week, with even Flink adding a new option to the mix.

When you want to get started quickly and easily, there are low-code options.
I’m showing the open source LangFlow here, where you drag your pieces (your models, your prompts, tools, data sources, and so on) onto a canvas and plug them together to assemble your agent.

When you want more control, there are libraries to do it through code. I’m showing LangGraph here, which is a Python SDK for building agents.
We’ve helped teams use both of these for their agentic projects.
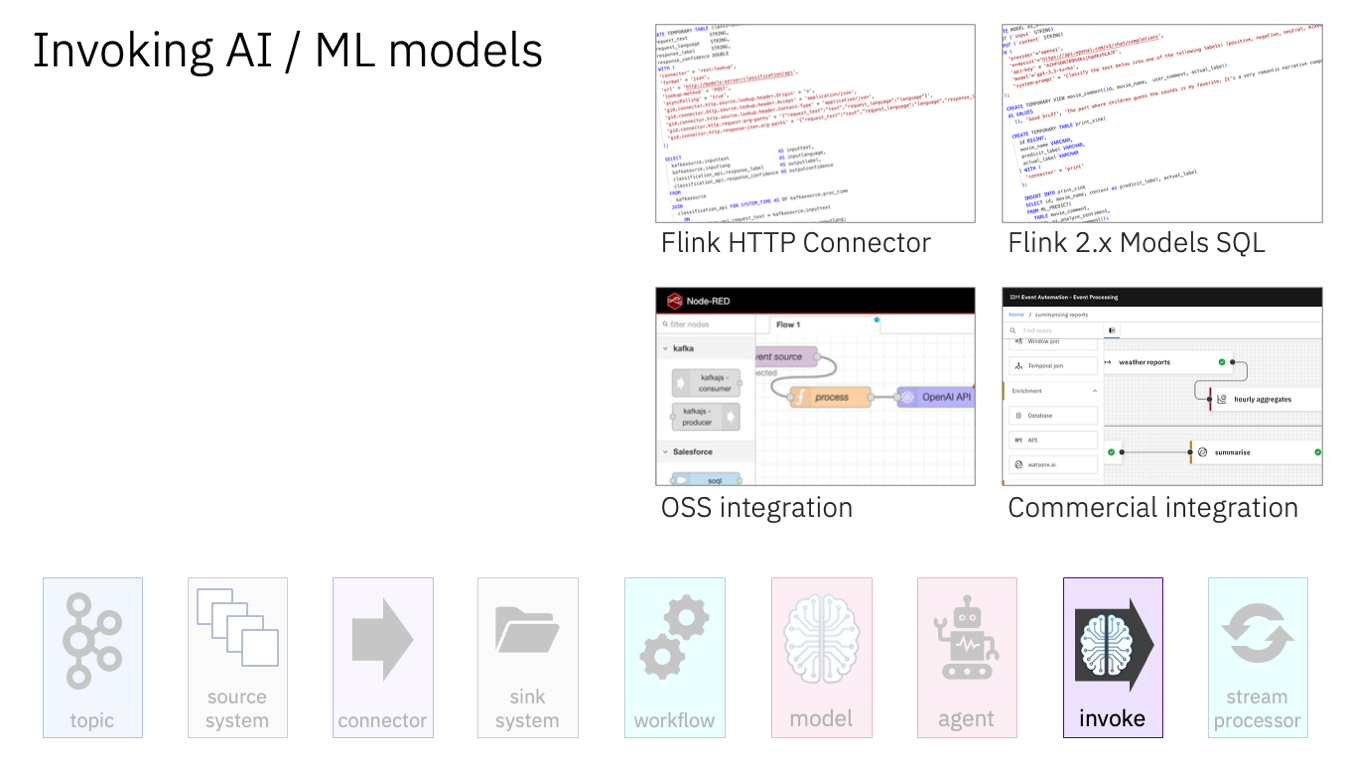
It’s worth touching on how teams bridge the gap between event streams and these AI services.
I mentioned that all of these models offer REST API interfaces, so this makes it very simple. Every programming language or integration platform will support HTTP calls.
Teams writing a Kafka Streams app will use Java libraries to make HTTP calls.
Teams using Flink have an HTTP connector they can use. (This is currently a community connector, but we’re in the process of contributing it upstream into main Flink. Either way, you can use it today).
Teams using the latest 2.x Flink releases could use the dedicated functions added specifically for OpenAI generative AI models, but they also have the HTTP connector for anything else.
Integration platforms invariably let you make HTTP calls, and some have dedicated nodes that simplify the config for well-known AI endpoints.
(I showed examples from the open source Node-RED and IBM’s Event Processing in my screenshots).
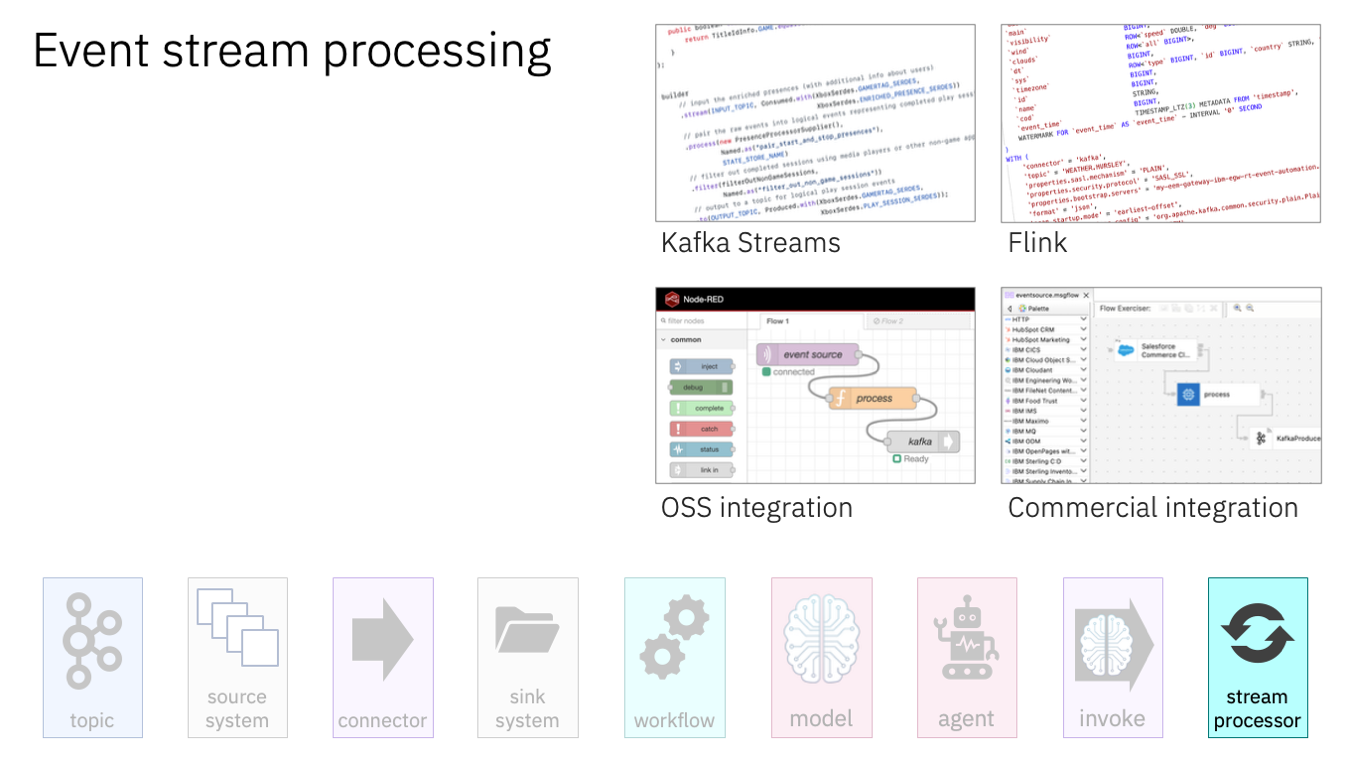
Finally, there’s the decision for how teams implement the processing requirements for their projects.
As I say, because all of them should make it possible to invoke AI APIs, you can use what you are used to and what you have skills with.
I’m showing just a few examples here, with options like Flink and Kafka Streams if you want to go with a code approach, or drag-and-drop low-code integration platforms like webMethods, Event Processing, App Connect, Node-RED and many more.
Event-driven AI projects all use some subset of these building blocks. I’ve shown how there are a range of choices for what you use for each block.
In the next post, I’ll start going through the most common ways to use these building blocks.
Tags: apachekafka, ibmeventstreams, kafka, machine learning