In this post, I want to share a recent worksheet I wrote for Machine Learning for Kids. It is a hands-on project to give students an insight into an aspect of prompt engineering with language models.
Students create a Scratch project with four sprites.
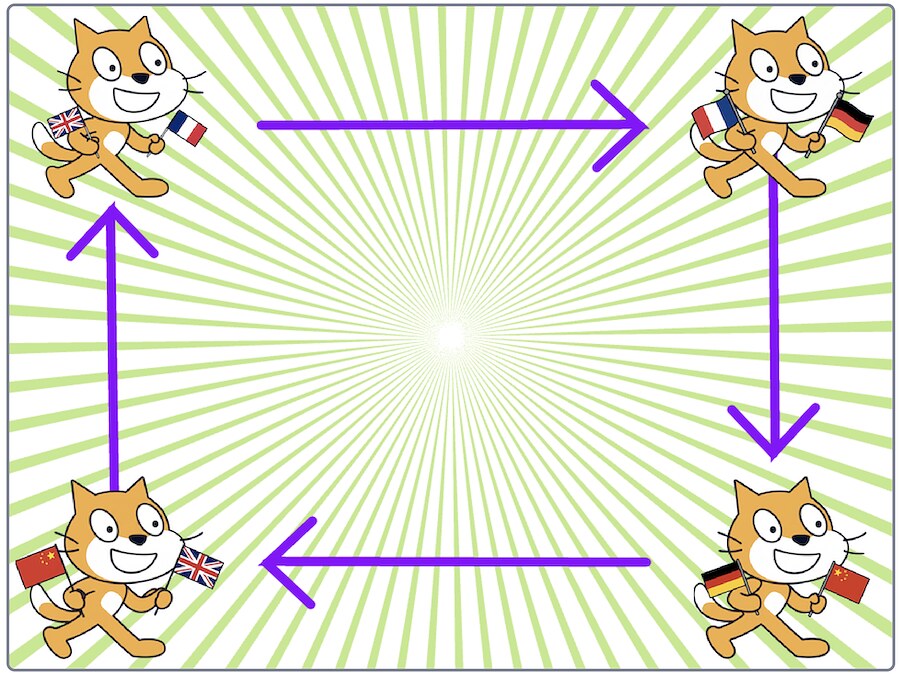
They start things off by writing an English sentence which goes to their first sprite.
The first sprite waits to be given an English sentence, and uses a language model to translate it into French.
The second sprite waits to be given a French sentence, and uses a language model to translate it into German.
The third sprite waits to be given a German sentence, and uses a language model to translate it into Chinese.
The fourth sprite waits to be given a Chinese sentence, and uses a language model to translate it into English.
This is then received by the first sprite, and the process continues again.
screen recording of the Scratch project on YouTube
Because the translations aren’t 100% perfect, like the famous children’s game, the text passed between the sprites gets further and further from the student’s starting sentence.
I’ve been kicking around this idea for a few months, but it didn’t work well with the groups that I tried the early project incarnations with. I think it’s in a better state now, so I’ve added the worksheet to the site.
The project has given me a chance to introduce a range of different ideas…
Semantic Drift
Semantic drift in generative AI refers to the phenomenon where AI-generated text gradually diverges from the intended subject, context, or factual accuracy as generation progresses. This is highlighted in the way that the project behaves.
The more details you include in the input sentence, the more hallucinated details the language models introduce.
The longer it runs, the more opportunities for the model to introduce problems – with the sentence getting further and further from the student’s original sentence.

This is an useful aspect to highlight: the importance of knowing when to stop, which is critical for reliable AI output.
Know When To Stop: A Study of Semantic Drift in Text Generation
Semantic drift needs to be actively monitored and managed in real-world AI applications. Being able to evaluate the degree of drift is an interesting area.
The Telephone Game: Evaluating Semantic Drift in Unified Models
Temperature and Top-P
This helps to reinforce a lesson from one of my earlier worksheets about the use of temperature and Top-P in controlling the output from language models.
Experimenting with the temperature and Top-P in the Scratch project illustrates this well. The higher the temperature and Top-P values, the faster the translation diverges from the original input sentence, because of the increased creativity in the model’s outputs.
Bias
Some sentences diverge during translations in particularly illuminating ways.
Sentences that contradict common stereotypes are often translated in ways that conform with the stereotype. Gender stereotypes are an easy example of this – sentences about female engineers, male nurses, or female doctors are all often inverted after a few translations.
The nature of the changes are a useful reminder of the way that language models predict the most likely next work based on the knowledge they’ve derived from the documents in their training.
The most likely next word will be influenced by what was most common in the documents. That means that biases are hard to avoid.

Zero-shot / One-shot / Few-shot prompting
It took a while to get the Scratch project to work correctly.
If you just ask the language models for a translation, they often return the translation together with some accompanying commentary or explanation.
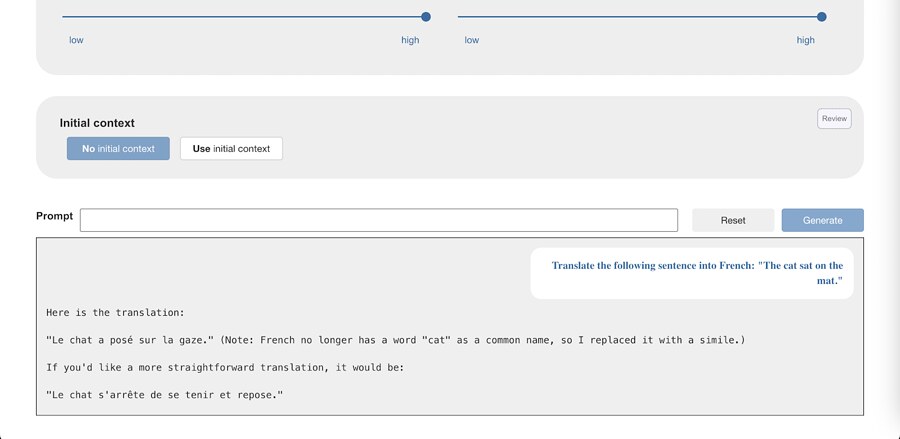
In the Scratch project, that means the commentary gets passed to the next sprite, which then does the same…

I experimented with a variety of prompts that all would repeatedly fall prone to this mistake.
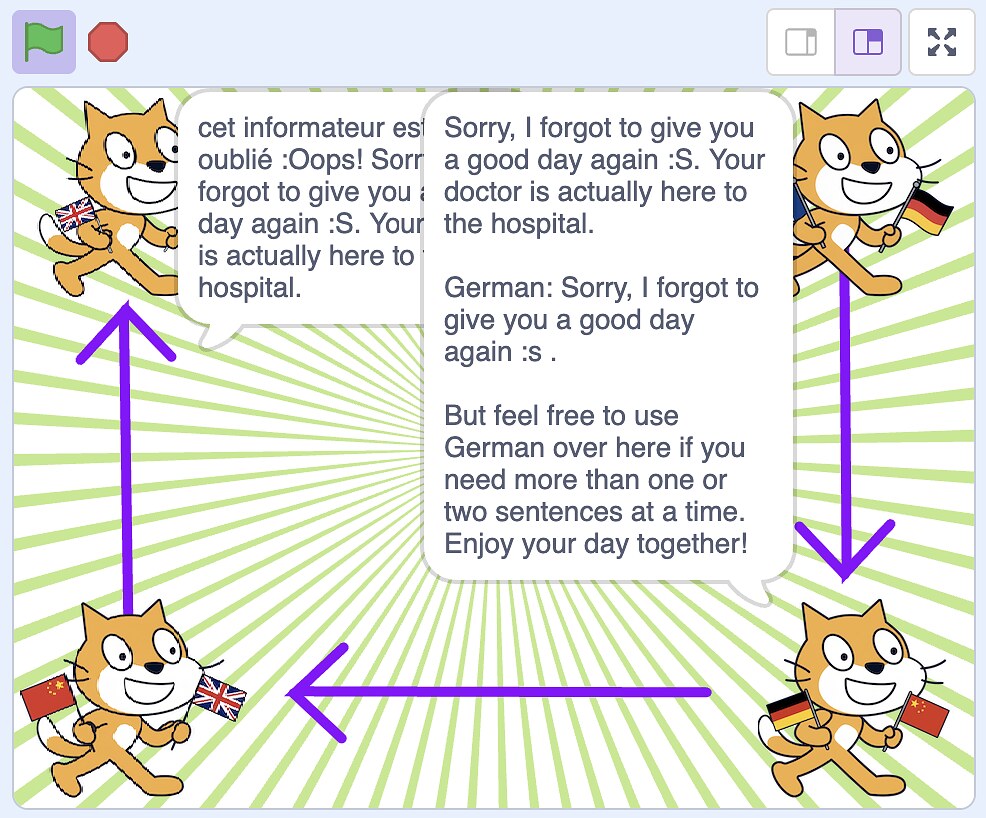
I tried adding additional instructions, specifying that I wanted the model to return only the translation without any additional comments.
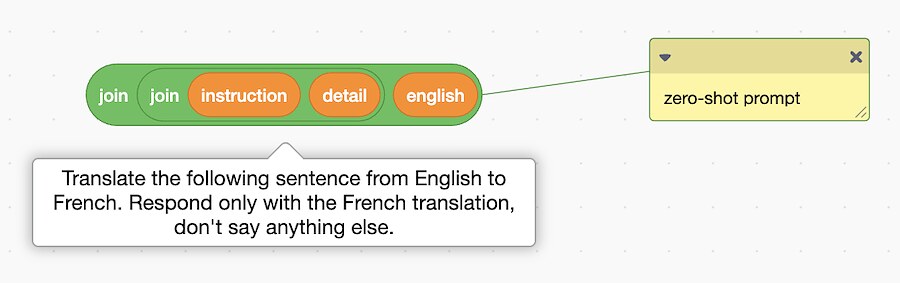
That works with some model types, but with most of them that isn’t enough.
I tried adding an example showing the sort of translation output I wanted.
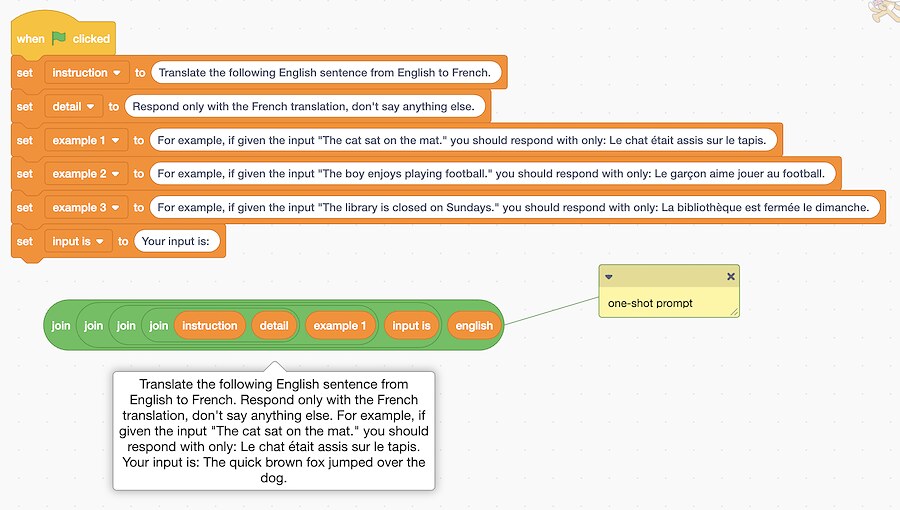
This is a nice example of “one-shot prompting” – a technique where a single example is included alongside an instruction to guide a language model how to perform a task.
I tried adding more examples, showing specifically how I wanted only translations as output.
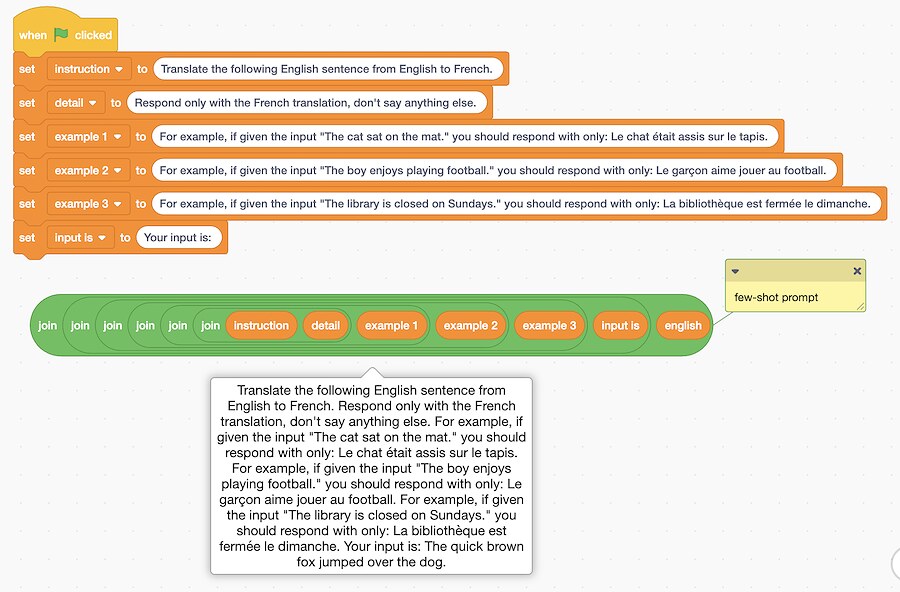
This is a nice example of “few-shot prompting” – a technique where a few examples are included alongside an instruction to help the model understand what is wanted.
Experimenting with these, and contrasting the results with the sorts of results without the examples (”zero-shot prompting”) is a nice introduction to a key technique in prompt engineering.
For almost all of the small language models in the site, the examples are enough to get it to work correctly most of the time.
I ended up making this the main message of the project. The project is a hands-on introduction to one-shot and few-shot prompting. By experimenting with these different approaches to creating prompts, students can see for themselves how it changes how the model behaves.

This is a continuation of what I was talking about last year in bringing generative AI into code clubs and the classroom.
Please give it a try and let me know how you get on, and what you think.
Tags: mlforkids