In this post, I’ll demonstrate how Event Processing can use parameters from an external source (such as a rules engine) in event processing flows.
A simple flow to demonstrate the idea
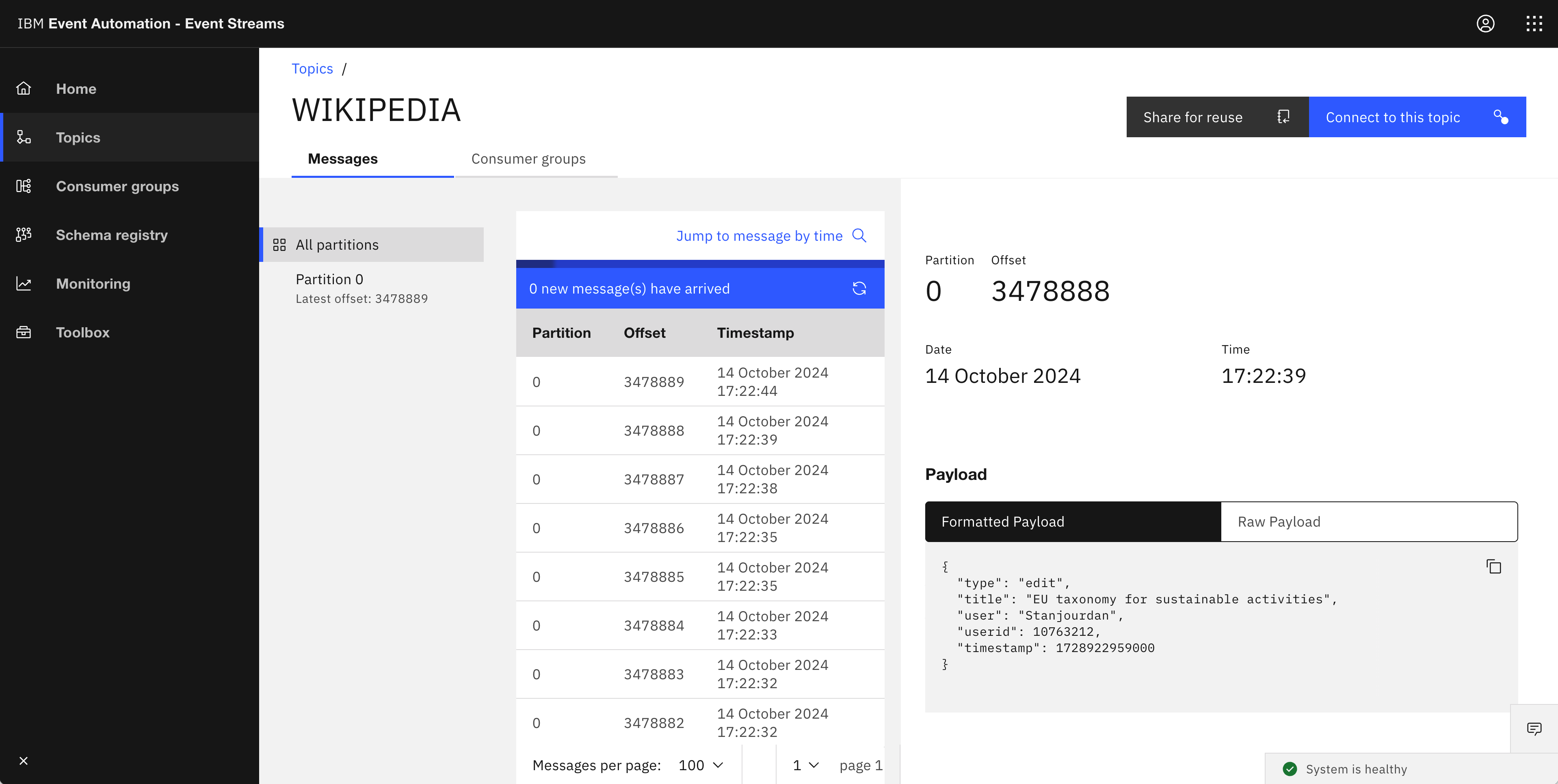
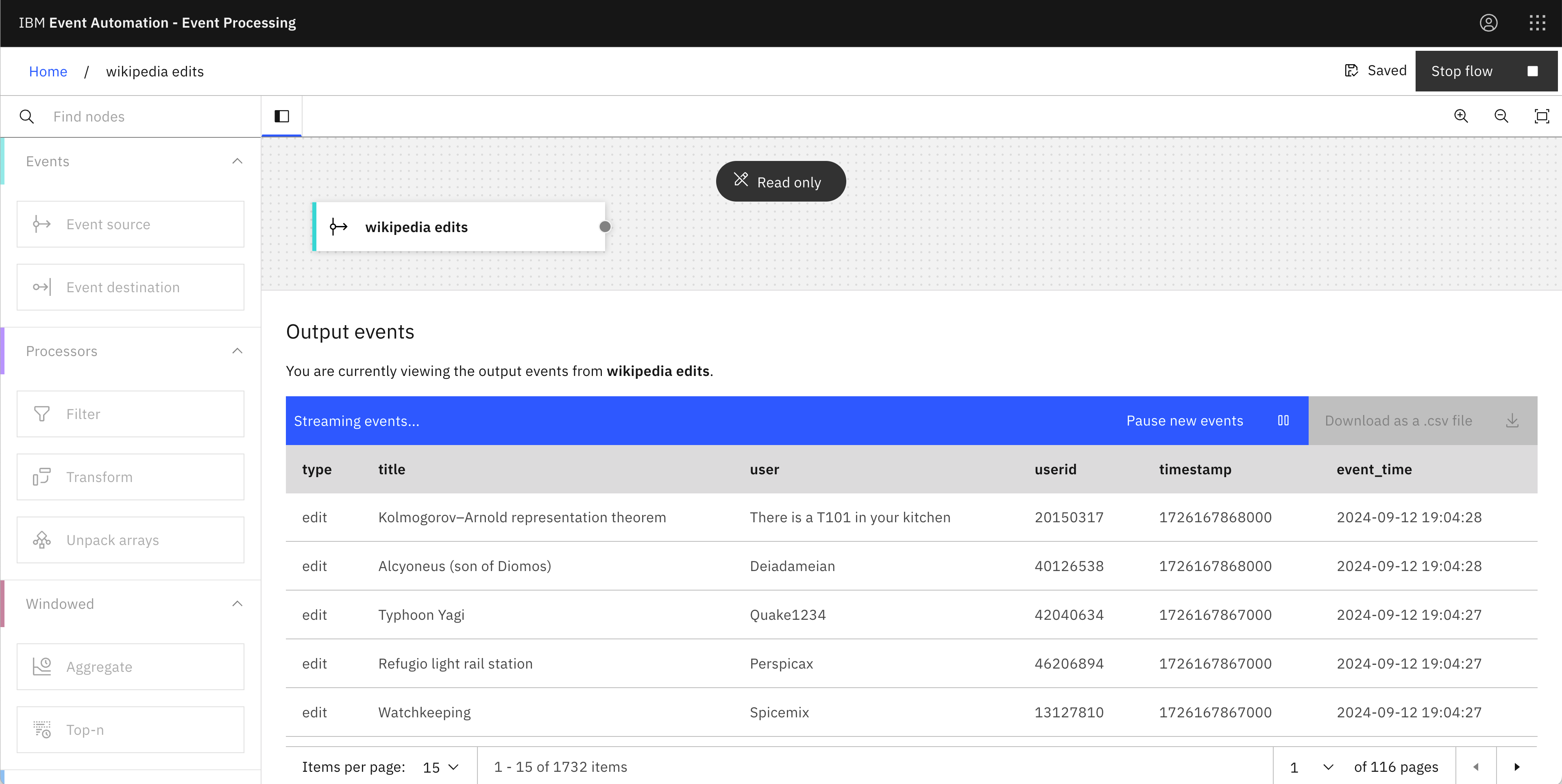
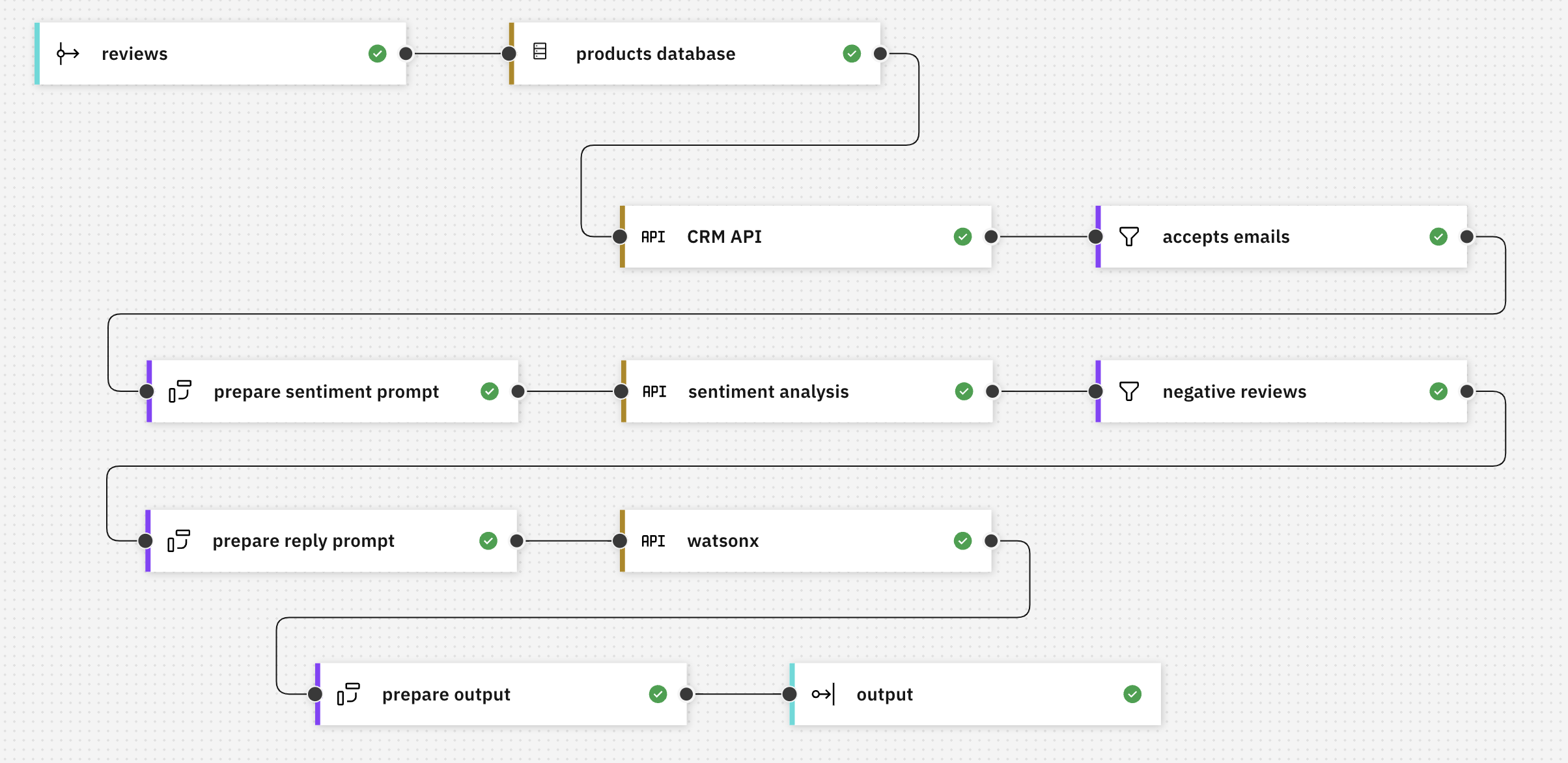
To illustrate the idea, I created a simple demo event processing flow. The flow takes a stream of order events, filters it to keep only orders for high value items, and then modifies the description property in some of the events:
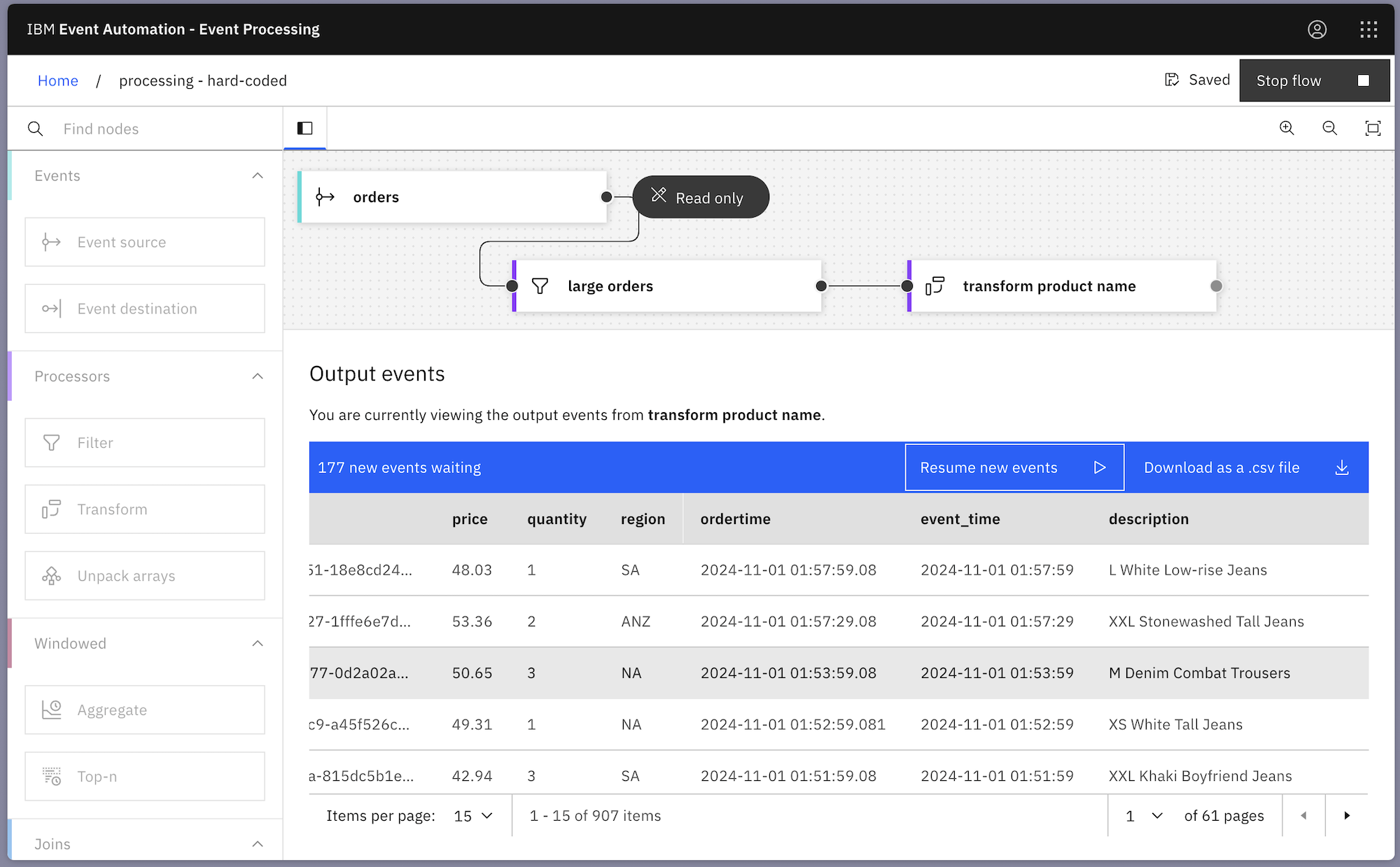
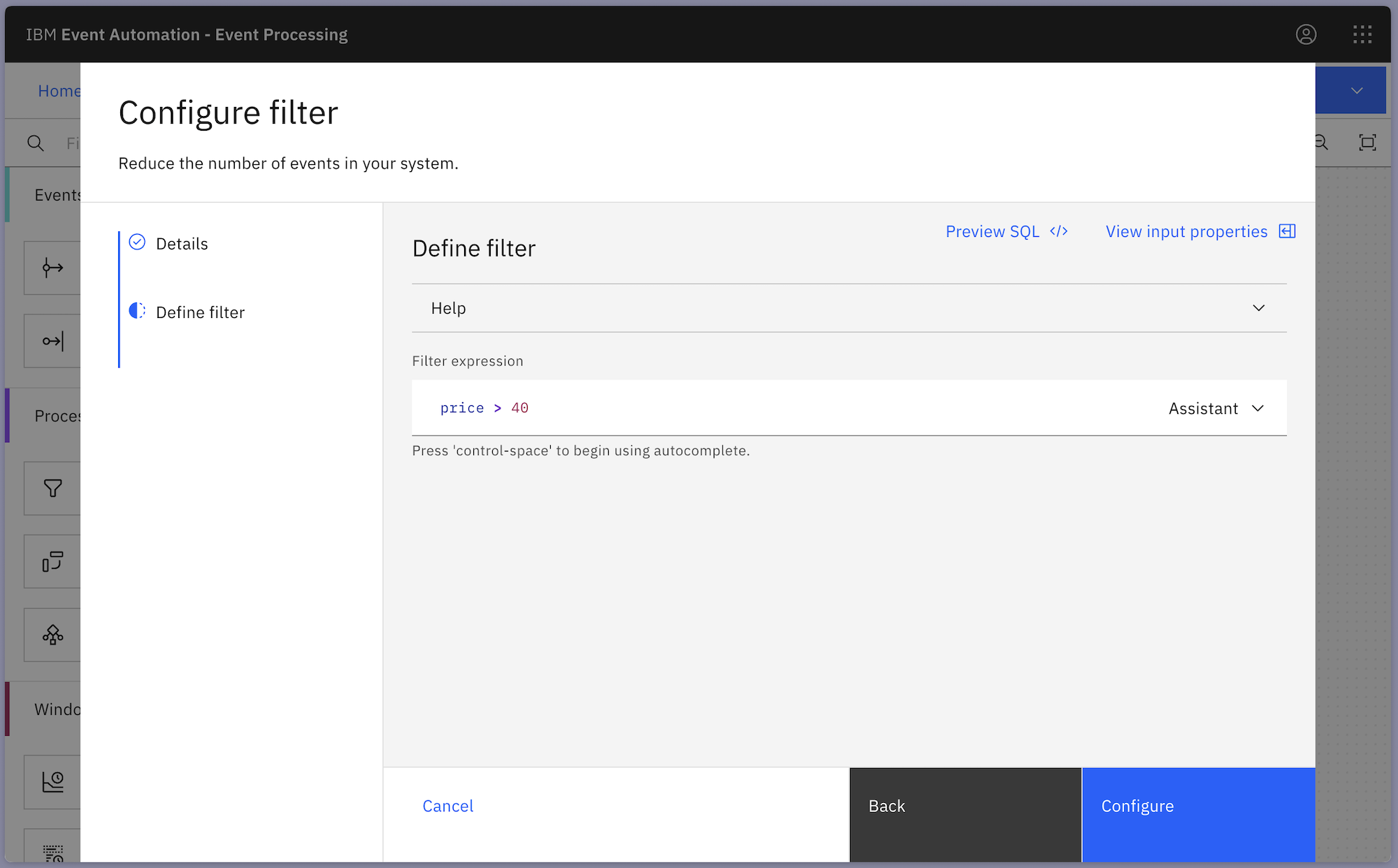
The filter node is comparing the price with “40”, so only order events for items with a value above $40 are kept.
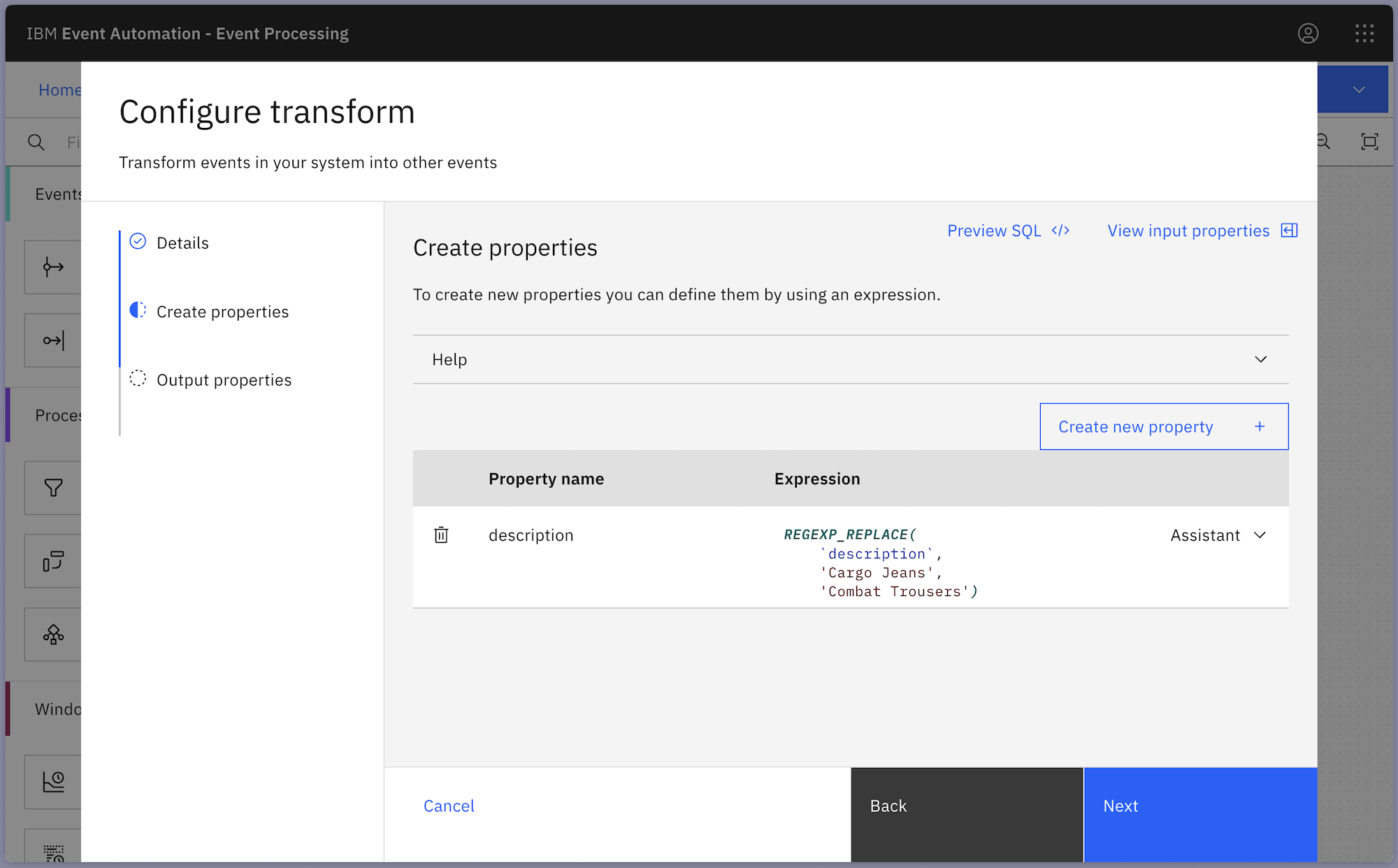
The transform node is modifying the description property of order events – any description that contains the string “Cargo Jeans” is replaced with “Combat Trousers”.
Hard-coded parameters
What if you wanted to modify the threshold for the filter, to change that $40 minimum value for an order to be considered “large”?
Or what if you wanted to modify the transformation, so that different strings would be used in the regular expression replacement?
With the values hard-coded in the flow as shown above, you would need to:
- create a savepoint for the job
- stop the job
- modify the parameters in the job
- resume the job from the savepoint
This is a workable approach, although it does require a little downtime and some administrative effort.
The aim for this post is to highlight an alternative approach.
(more…)
 This week, I’m at
This week, I’m at