In this post, I describe how artificial intelligence and machine learning are used to augment event stream processing.
I gave a talk at a Kafka / Flink conference yesterday about the four main patterns for using AI/ML with events. I had a lot to say, so it is taking me a few days to write up my slides.
- the building blocks used in AI/ML Kafka projects
- how AI / ML is used to augment event stream processing (this post)
- how agentic AI is used to respond autonomously to events
- how events can provide real-time context to agents
- how events can be used as a source of training data for models
The most common pattern for introducing AI into an event driven architecture is to use it to enhance event processing.
As part of event processing, you can have events, collections of events, or changes in events – and any of these can be sent to an AI service. The results can inform the processing or downstream workflows.

The simplest way to do this is to just send individual events (or some of the attributes from individual events) to the AI service.
As I described yesterday, the AI service could be:
- a classifier (to recognise what type of event it is)
- an entity extraction service (to pick out interesting bits from unstructured data in the event)
- a regression model (to estimate a numeric value from the structured event properties)
- a generative AI model (to generate a description or summary of the event properties)
and so on.
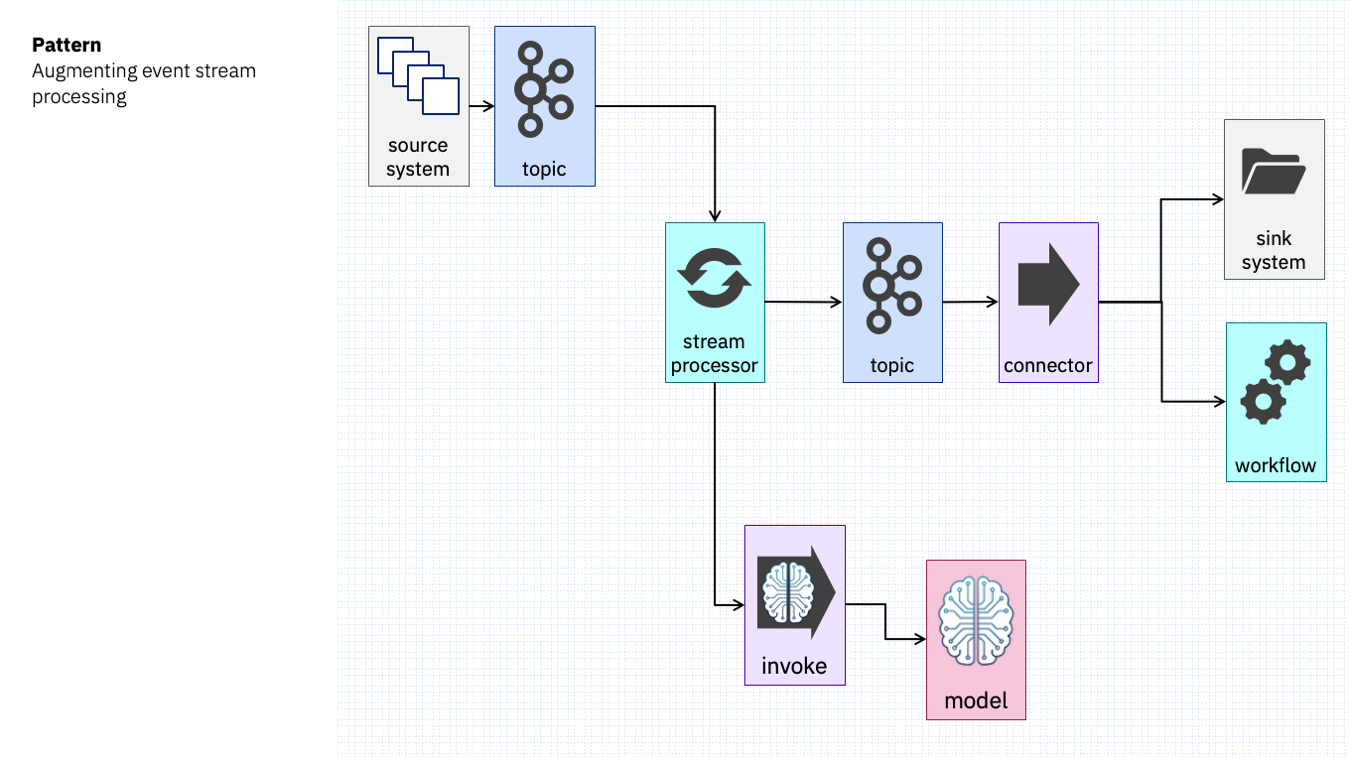
Whatever type of model you use, the pattern looks something like this.
As I described yesterday, your stream processor could be code like Kafka Streams or Flink SQL, or something low-code like an integration platform.
Whatever it is, it receives Kafka events and as part of processing them submits properties from them to an AI service. The results inform the way that events are filtered, routed, or processed.
This is easier to explain with a few examples.

Imagine a logistics system that emits shipping events to a topic – with properties about the item being shipped (size, weight, value, etc.) and what has happened to it (e.g. temperature or humidity changes, or other incidents).
A classifier could take those values and use them to classify the risk level for that item. This could be used to update the record in the shipping system.
The result is a shipping system that has a risk classification that is intelligently updated in real-time in response to events as they occur.
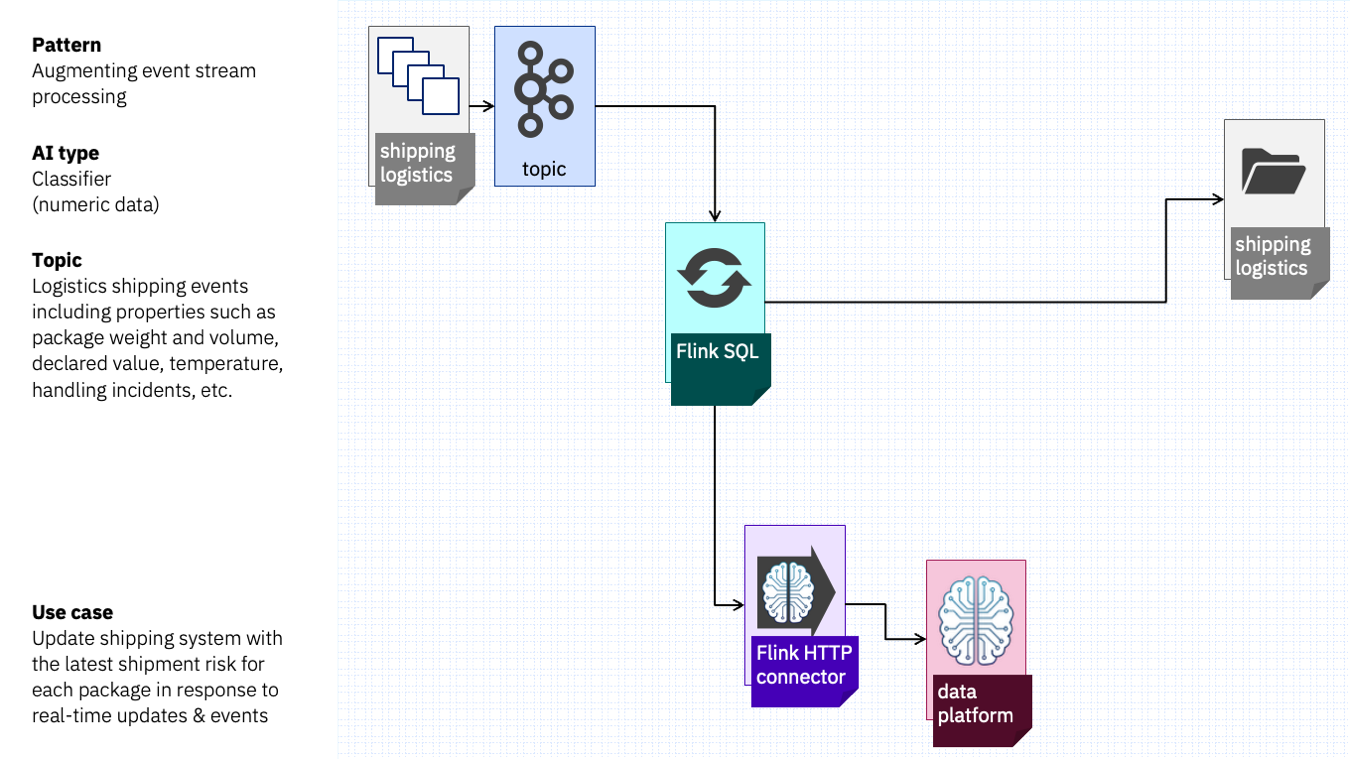
This could look something like this.
The logic for the processing is simple, and could be expressed using Flink SQL.
The shipping company likely has their own risk classifications, so they could use a data platform to train their own custom numeric classification model with their own historical shipping records. A simple classification model can do this effectively with a small number of examples, making this easy to set up.
Flink SQL connectors could sink the enriched shipping info into the logistics system, perhaps using the HTTP connector.
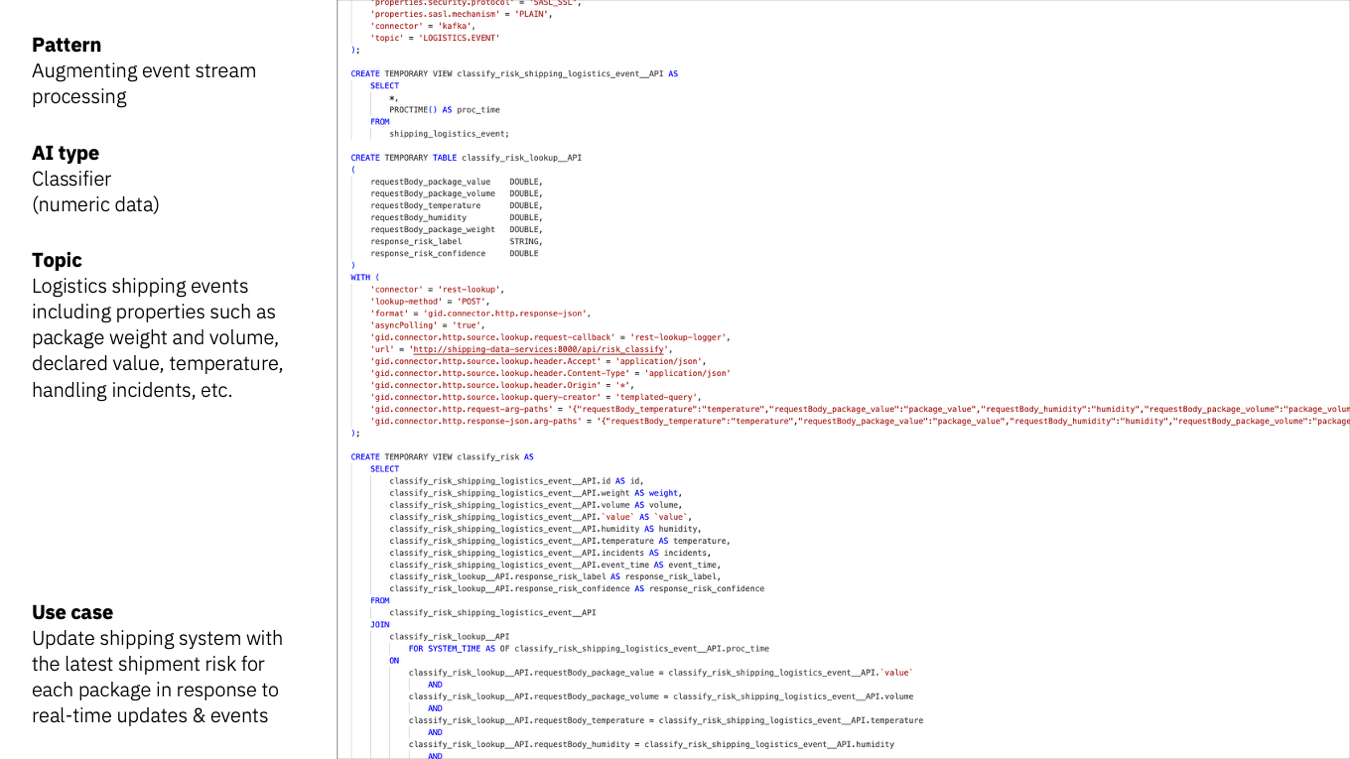
The Flink HTTP connector can invoke the classifier and use the response to enrich the events with the risk classification.
The classifier is just another transformation, another form of enrichment – that we describe in Flink SQL as a lookup join against the model API.
Imagine a company that monitors social media posts that mention their name, so they can proactively respond.
A text classifier could help them to route the comment to the right department, based on the contents of the social media post.
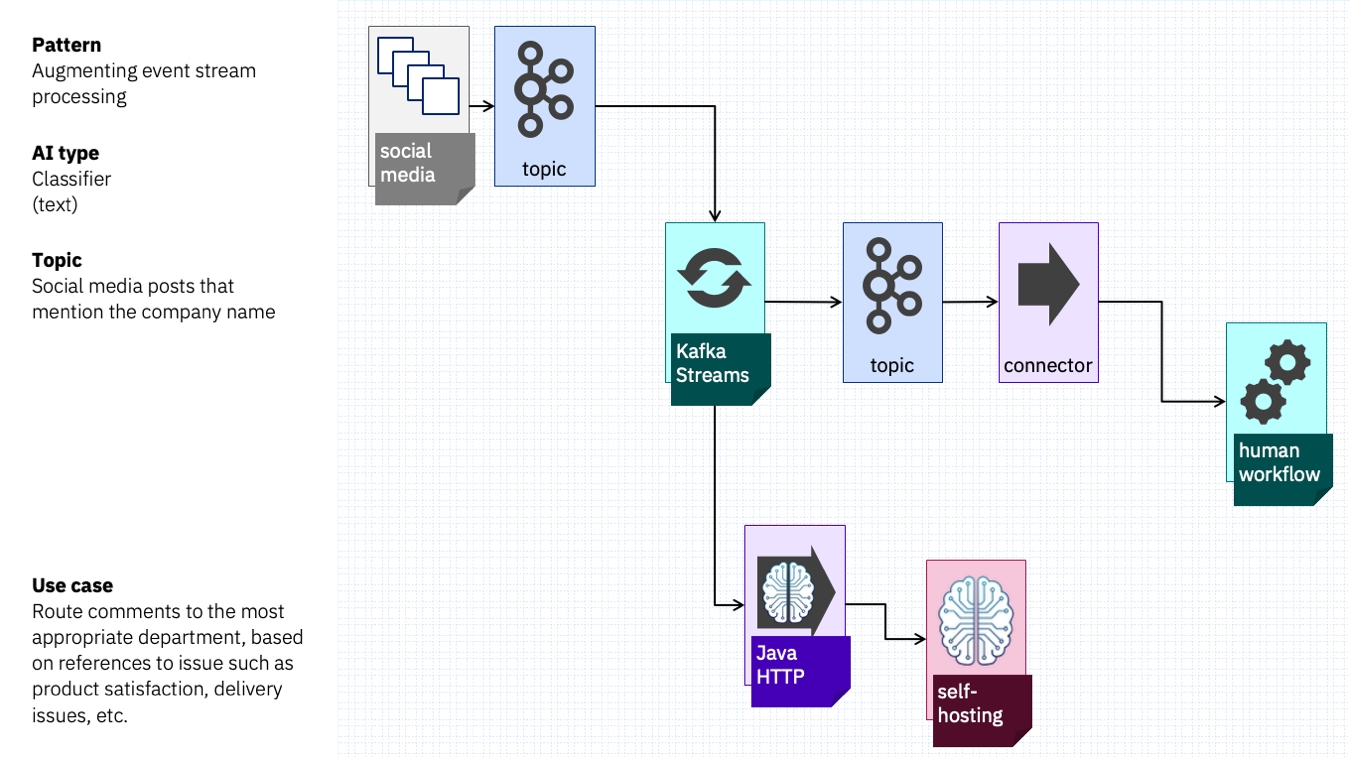
The solution could look something like this.
One way to build it would be to write code – to use Kafka Streams to call a classifier model they trained and run themselves.
Kafka Streams can sink the social media post events (enriched with the department name) to a topic, where it could trigger someone in the right department to respond.

The code needed is simple (it’s just an enrichment stream that invokes an HTTP library) but the properties contributed by the model makes the enriched events more useful and more valuable.
Imagine a recruitment company, with a stream of events for new job vacancy postings.
An entity extraction model can take the text from the job description, and pick out the skills mentioned in it.
Enriching the vacancy event with the key skills could be used to route this new posting to the right recruiter, or to auto-tag the most relevant candidates.
The result is a responsive recruitment system that starts responding to new vacancies as soon as they are submitted.
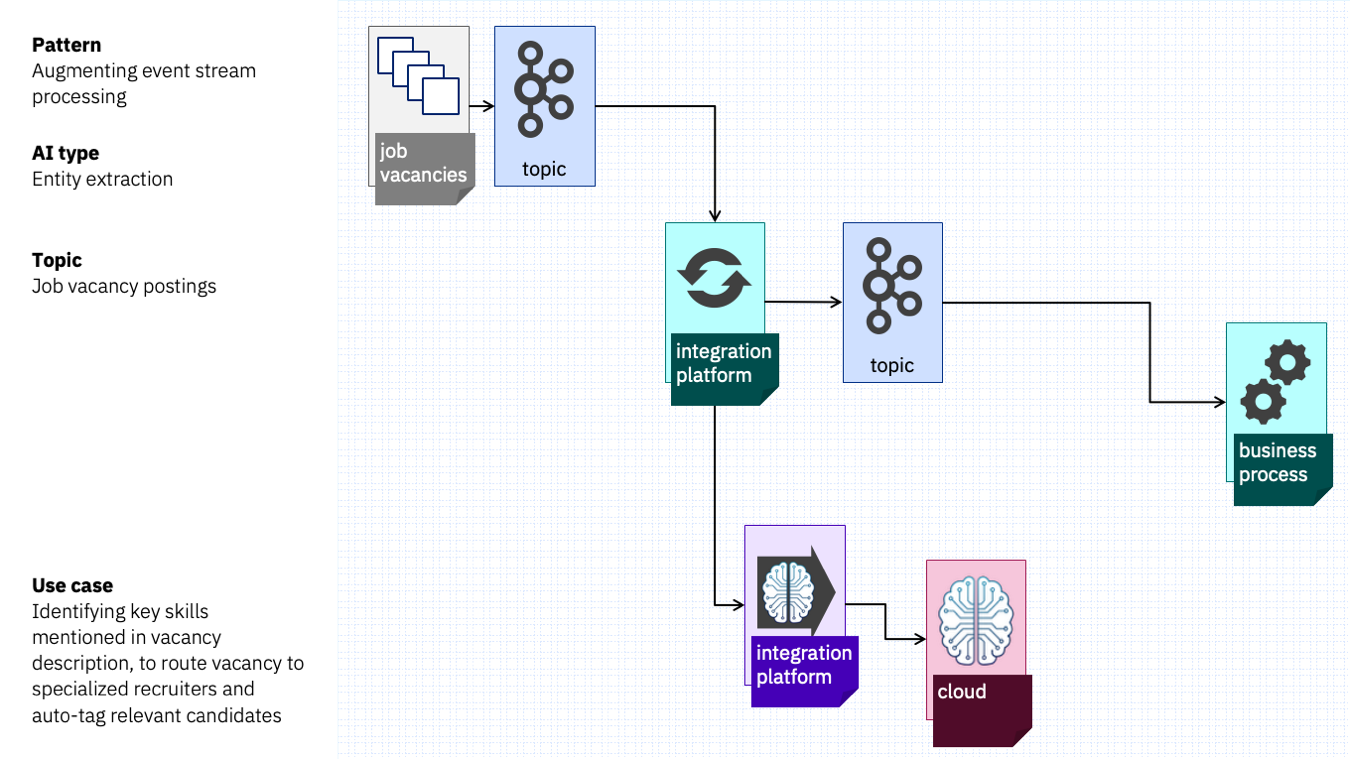
It could look something like this.
This team might prefer to use a low-code integration platform and drag and drop nodes to create the simple event enrichment flow.
They could choose a SaaS-hosted integration platform like webMethods, so they don’t have to run anything on-prem, and use cloud entity extraction APIs to pick out the skills mentioned in the event.
The SaaS integration platform can sink the enriched job vacancy events to a topic that can be used to trigger their business process automation system.

Imagine a customer services team that monitor customer reviews.
They want an event-driven system that will let them respond to concerning trends. They can use a sentiment analysis classifier to recognise the tone in reviews, and aggregate those enriched reviews to see which products are getting the most negative reviews over time.
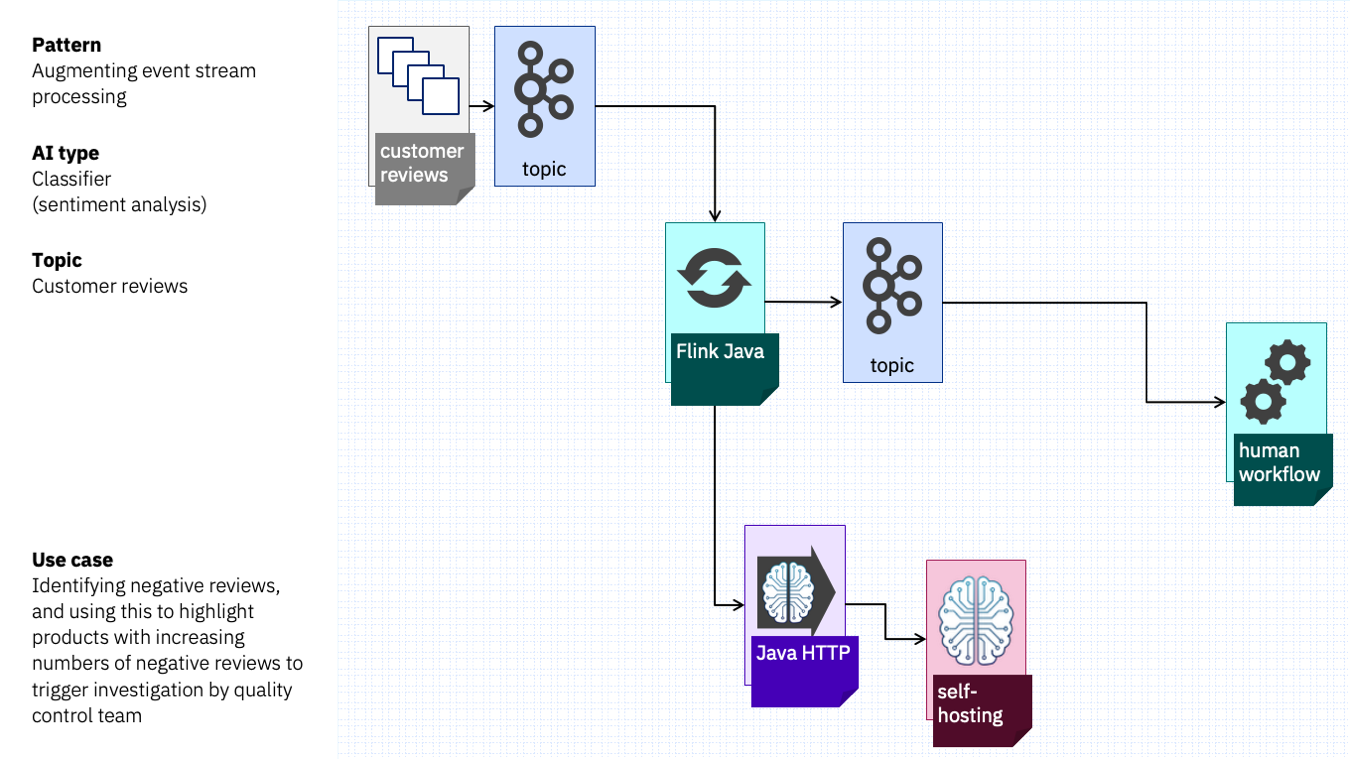
This team might prefer to write code, and choose a Flink Java API.
They can use a Java HTTP library to submit the review text to a simple sentiment analysis model they download from Hugging Face and self-host.

Imagine a financial services company that is monitoring financial news reports.
Maybe they want to keep track of which companies are being mentioned in those reports, and how many times each company is mentioned – and see how this changes over time.
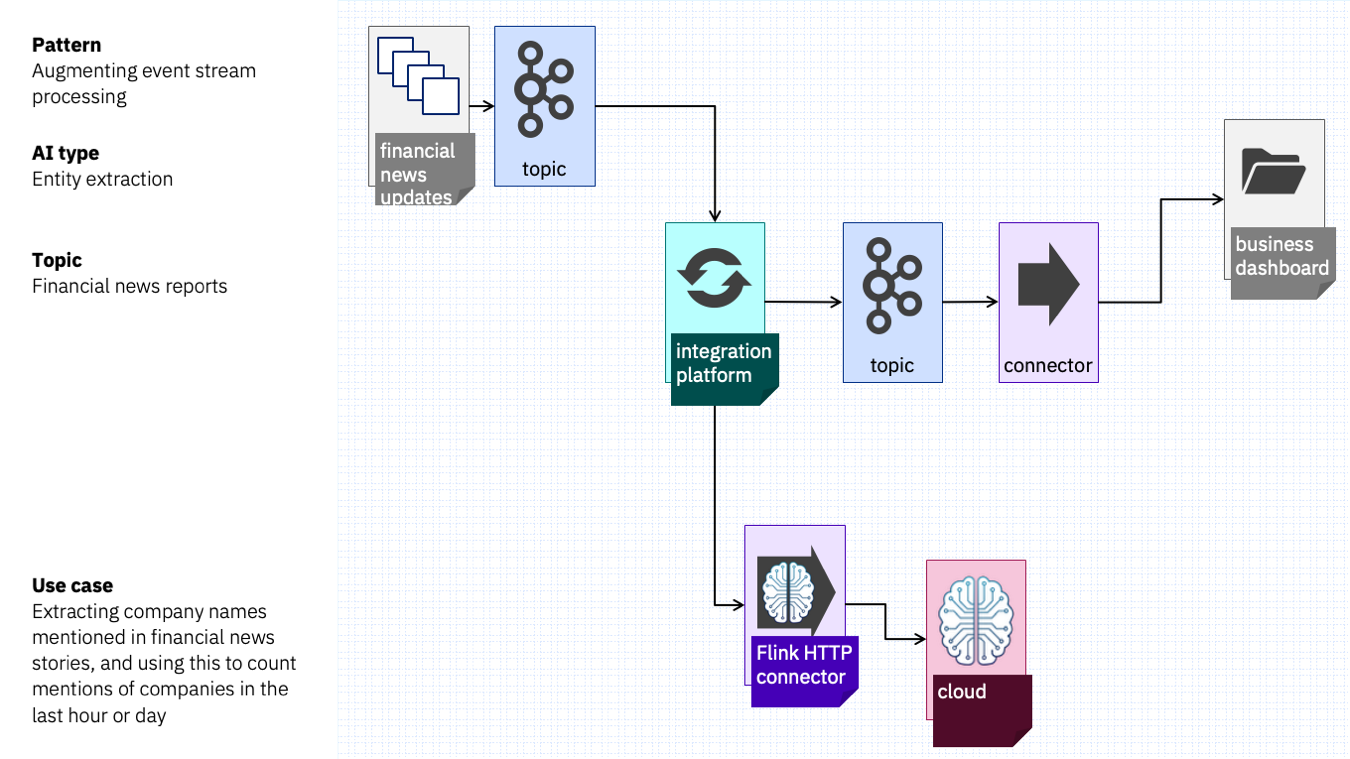
That could look something like this: stream processing sending the text from each news report event to an entity extraction service in the cloud, and getting back a list of company names found in the text.
Those could be aggregated into hourly windows, and used to update a business dashboard each hour with the companies that have been mentioned most frequently.
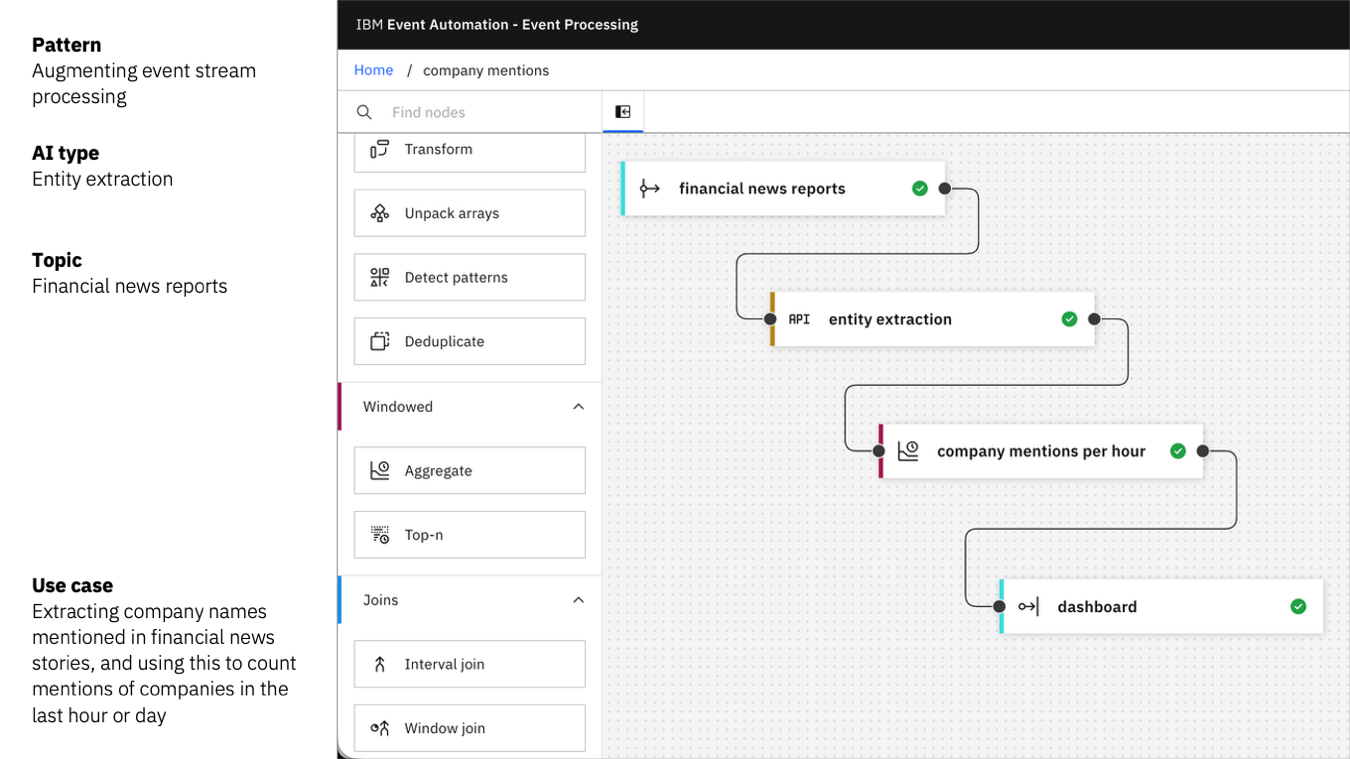
This could be created as a situational application by a business user in a low-code integration platform.
This will pick out company names not by relying on some list of all known companies, but by leveraging the entity extraction API’s ability to recognise when something is a company name from the context in natural language.
Then it uses Flink’s ability for time-based aggregation to keep track of how many times different company names come up each hour.
Imagine a customer complaints department, with a small team that need to respond to issues that customers bring up.
They have an event-driven system, where a workflow platform is driven by events from the complaints board.
By adding generative AI into the mix, they can generate a tailored draft response that is ready for the customer services team member when they receive the new case.
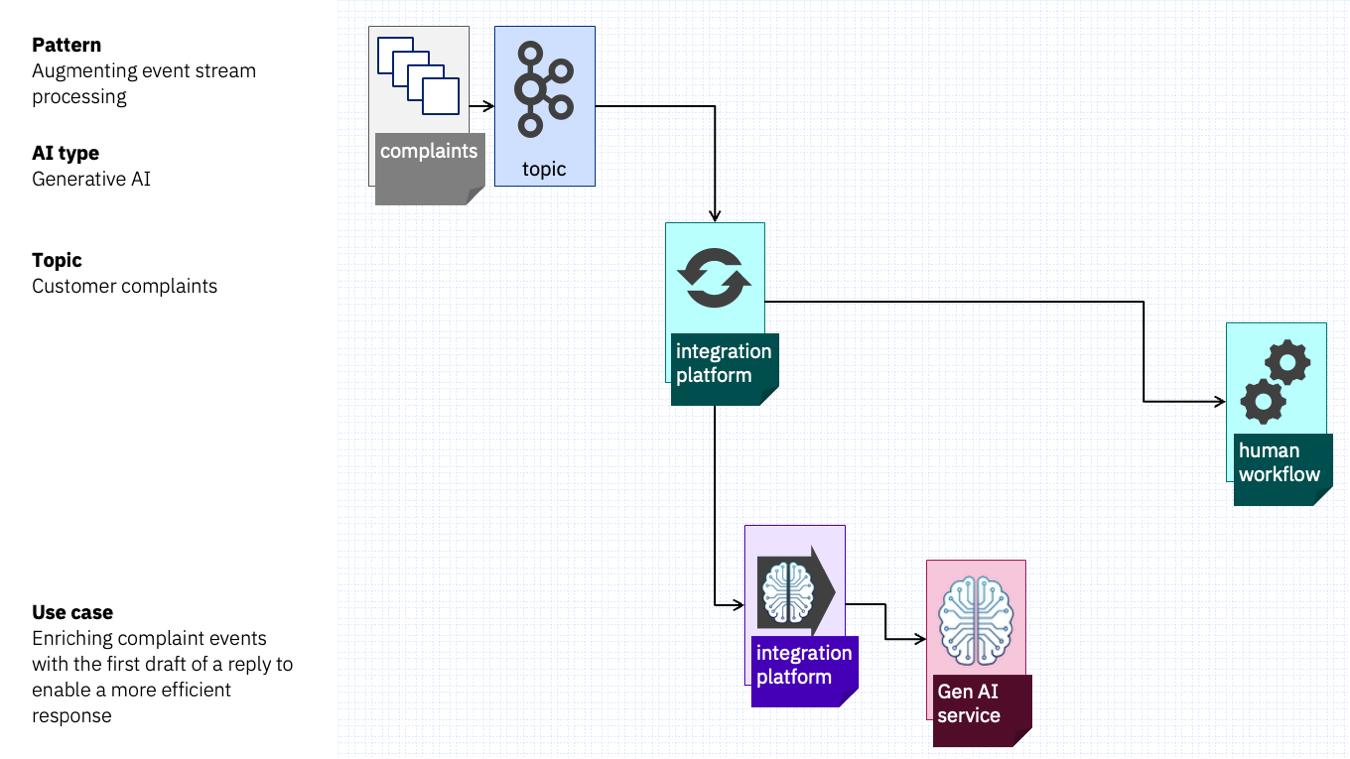
Stream processing receives the complaint events, sends the text with a pre-prepared prompt to a Generative AI cloud service, and uses this to populate the human workflow task.
The result is that when the customer services team member receive a new complaint, they have a draft response ready to go, helping them to respond to the customer with a tailored reply much more quickly.
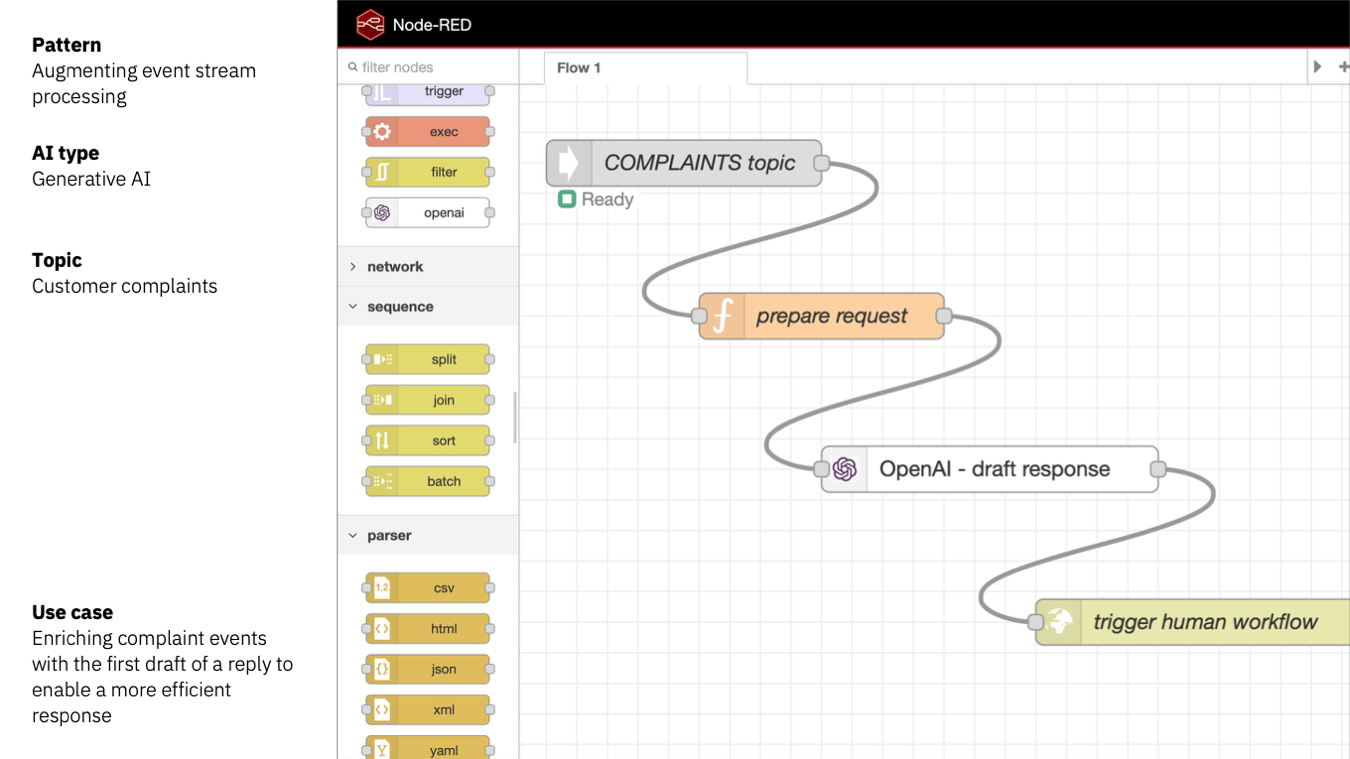
A drag-and-drop integration platform is an easy way to quickly set this up.
This just needs a Kafka consumer node, some simple processing to turn the complaint text into a prompt for an LLM, and a way to sink that into the workflow system.

All of those involved sending individual events to AI services.

A variation of this pattern is to send the results of event stream processing to the AI service. This could be:
- a history of recent changes over time
- a before-and-after comparison of a change since a previous event
- an aggregation or summary of events within a time window
- a correlation of events from multiple streams of events
and so on.
AI services like time series models identify anomalies or predict the most likely next action. Or generative AI can explain and summarise what the events mean.

Imagine a bike hire scheme, that tracks the location of their e-bikes – raw location update events emitted constantly while the bikes are on the move.
Their goal is to generate predictions of how many journeys they can expect to be made over the next few hours, and predict where they are likely to need more e-bikes.
They can also compare those predictions with what happens at the end of each hour, and use that to identify anomalies or unusual behaviour.
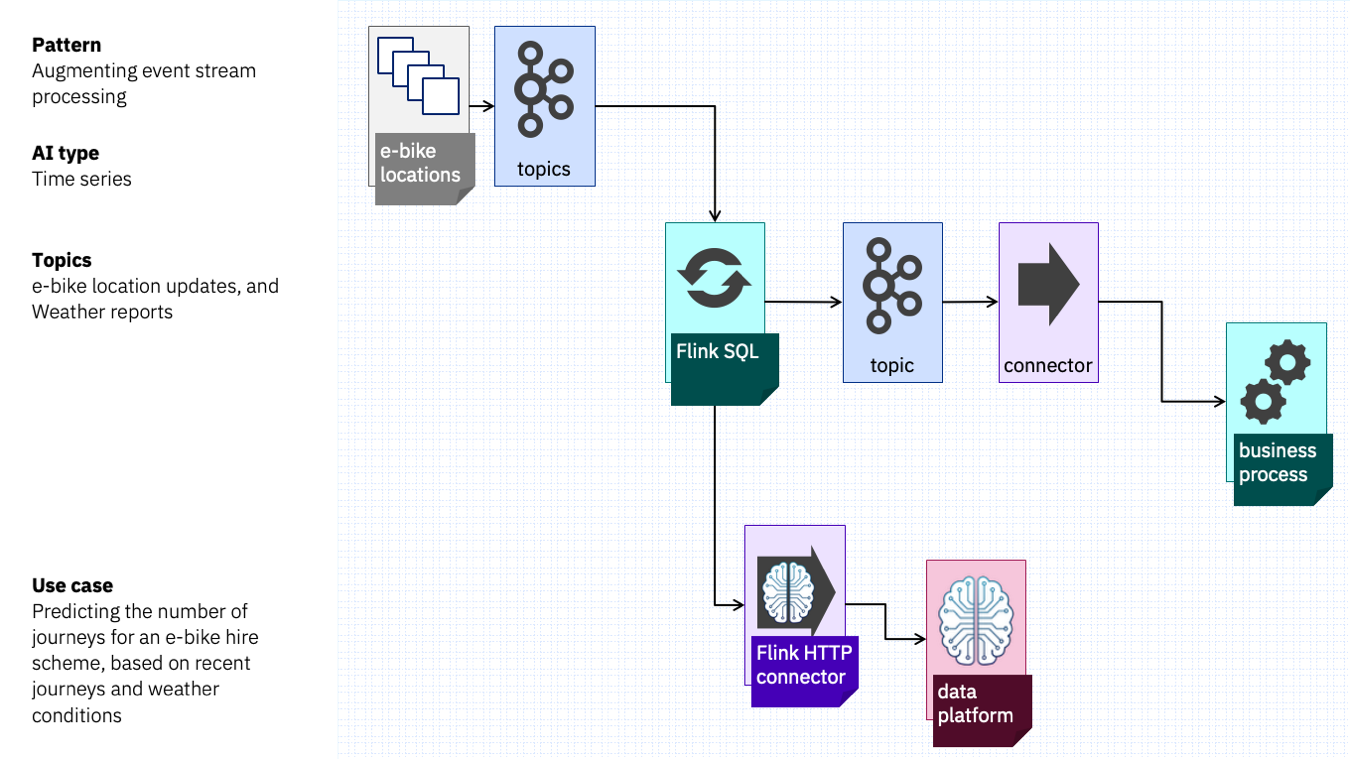
This could look something like this.
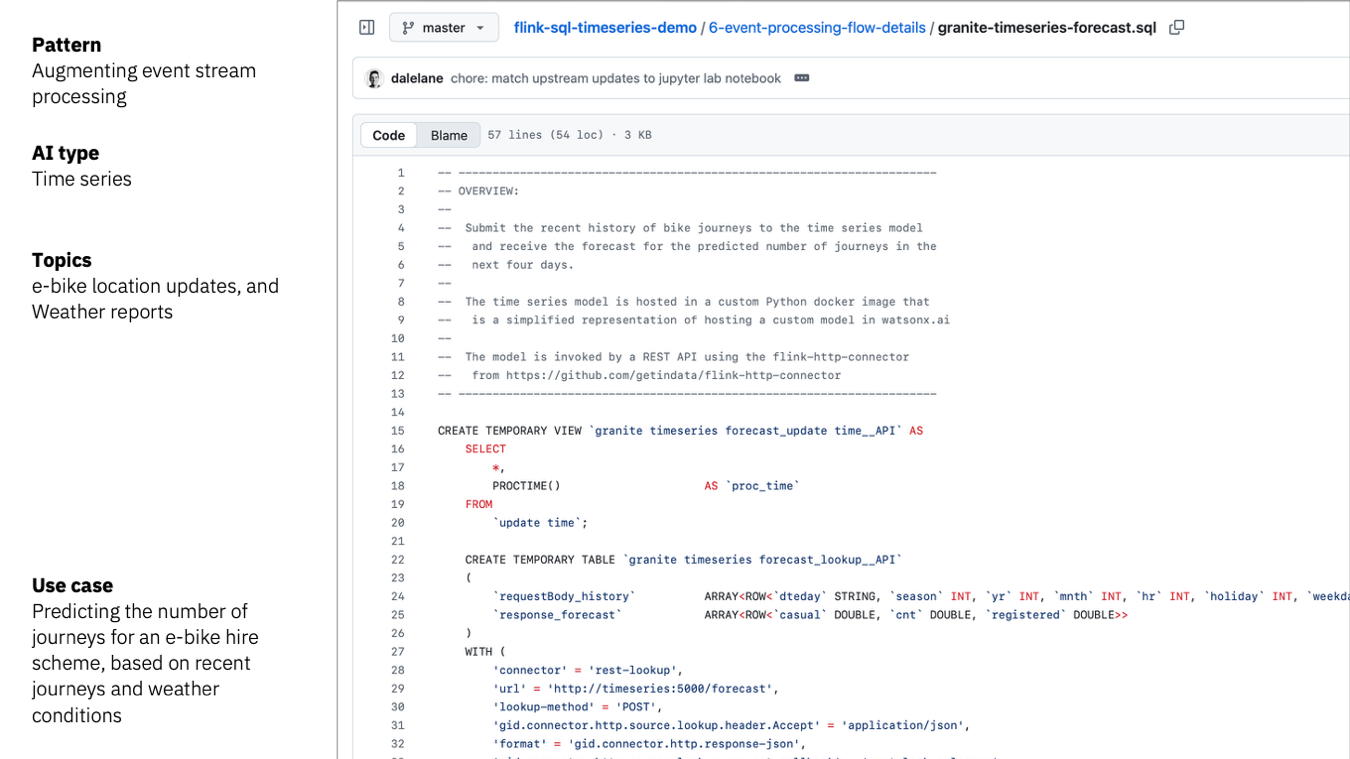
A Flink SQL project aggregates the raw location update events into journeys, correlates those journeys with the weather reports at that time, and submits a time series of recent journey behaviour to a custom time series model.
The output from that model (which is the expected journeys over the next few hours) can be checked against current e-bike availability in each area.
If there are not enough e-bikes in an area to meet the predicted demand this can trigger a business process to move inventory around, or adjust dynamic pricing.
The result is a fleet of e-bikes that is not only tracked for location and battery level, but also journey behaviours that are being intelligently monitored in real-time to make sure that they are always ready to meet future demand.
I built a demo of this a little while ago which you can find on github.
It’s easier than you perhaps expect to get this working. Time series models are an under-used AI type, but models specialized for making predictions against time series data is such a good fit with Kafka events. The ability to make predictions and detect anomalies with events is a powerful tool.
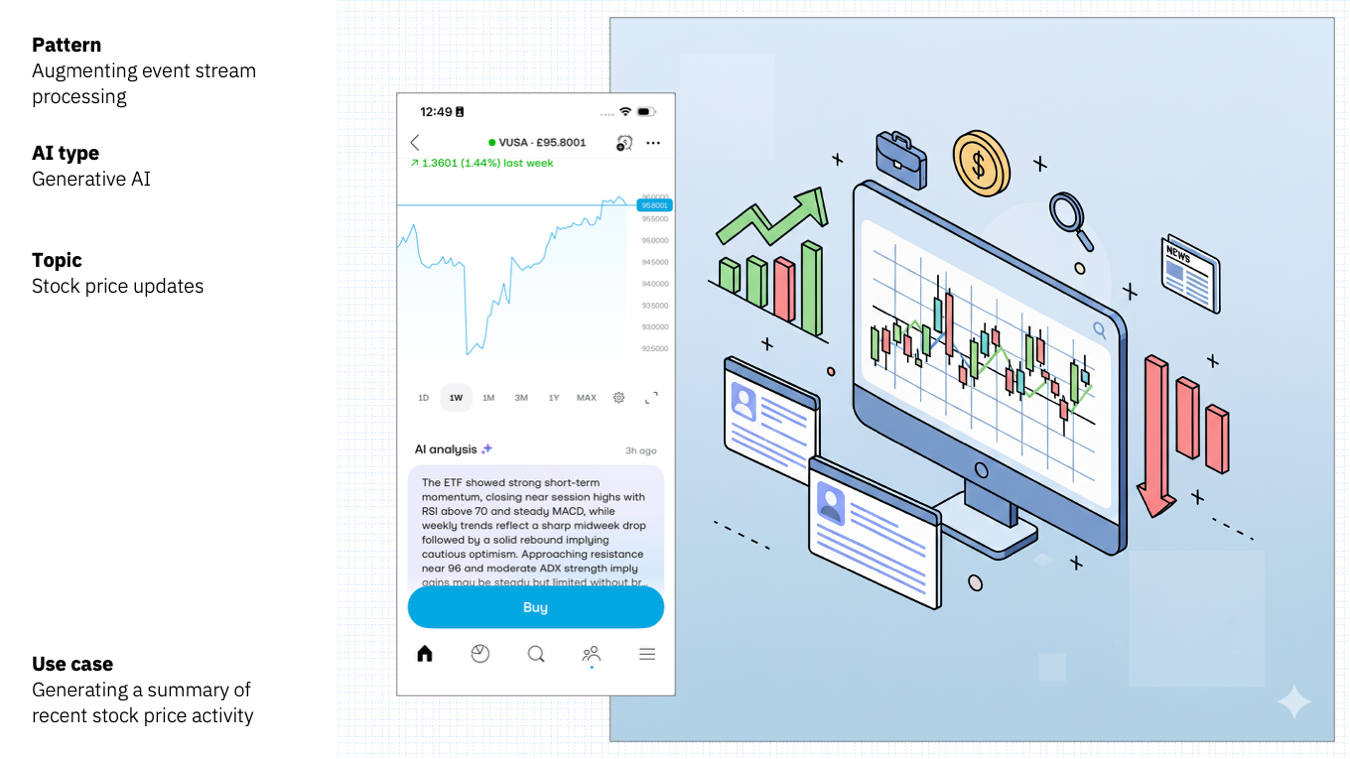
Imagine that you have a topic with stock price updates, with events tracking every stock price change.
Event stream processing can aggregate the price changes over a time window. This can be submitted to a generative AI service that can turn that into a summary with a concise analysis of that stock’s performance.
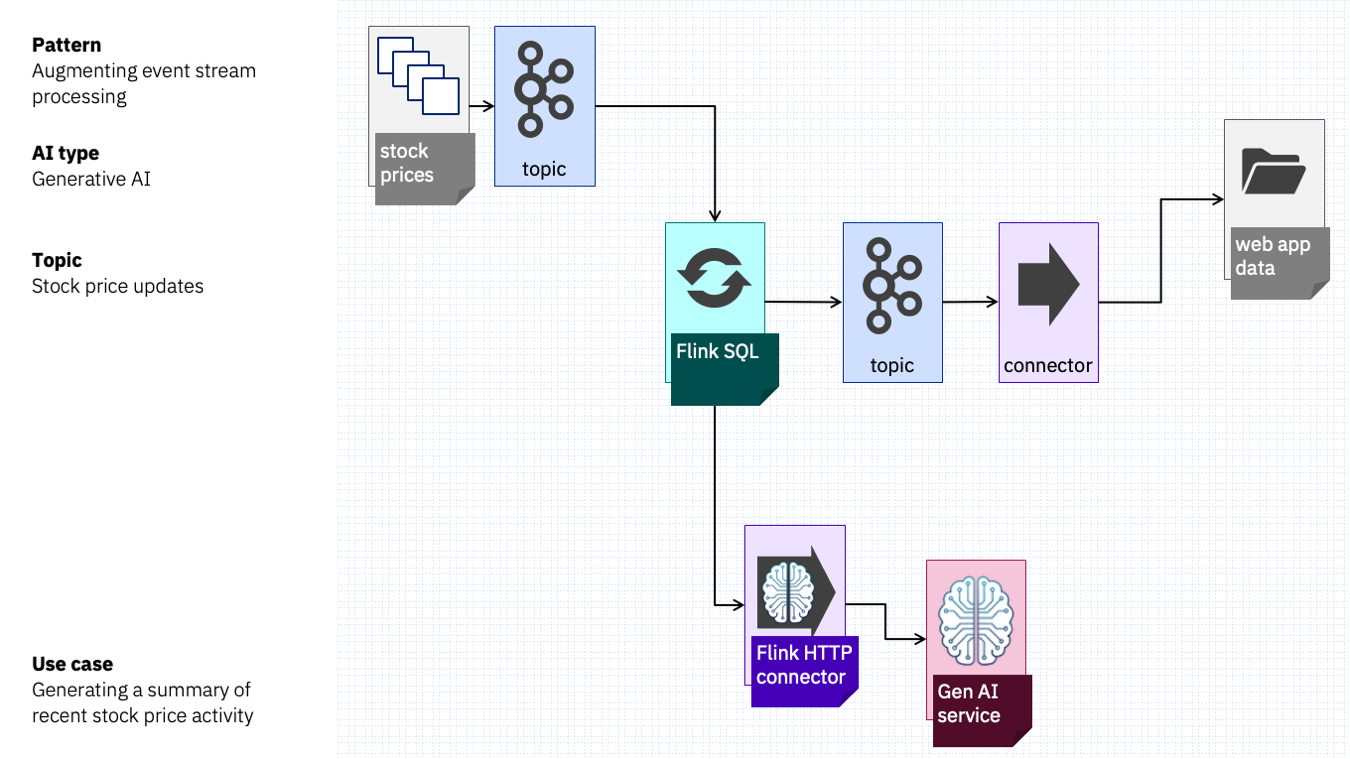
The solution could look something like this. Flink aggregates the stock price events by company, and uses the Flink HTTP connector to submit the changes over each hour to a generative AI service.
Flink produces those hourly summaries for each stock to a topic, and a sink connector pushes them into the system that powers the stock website and app.
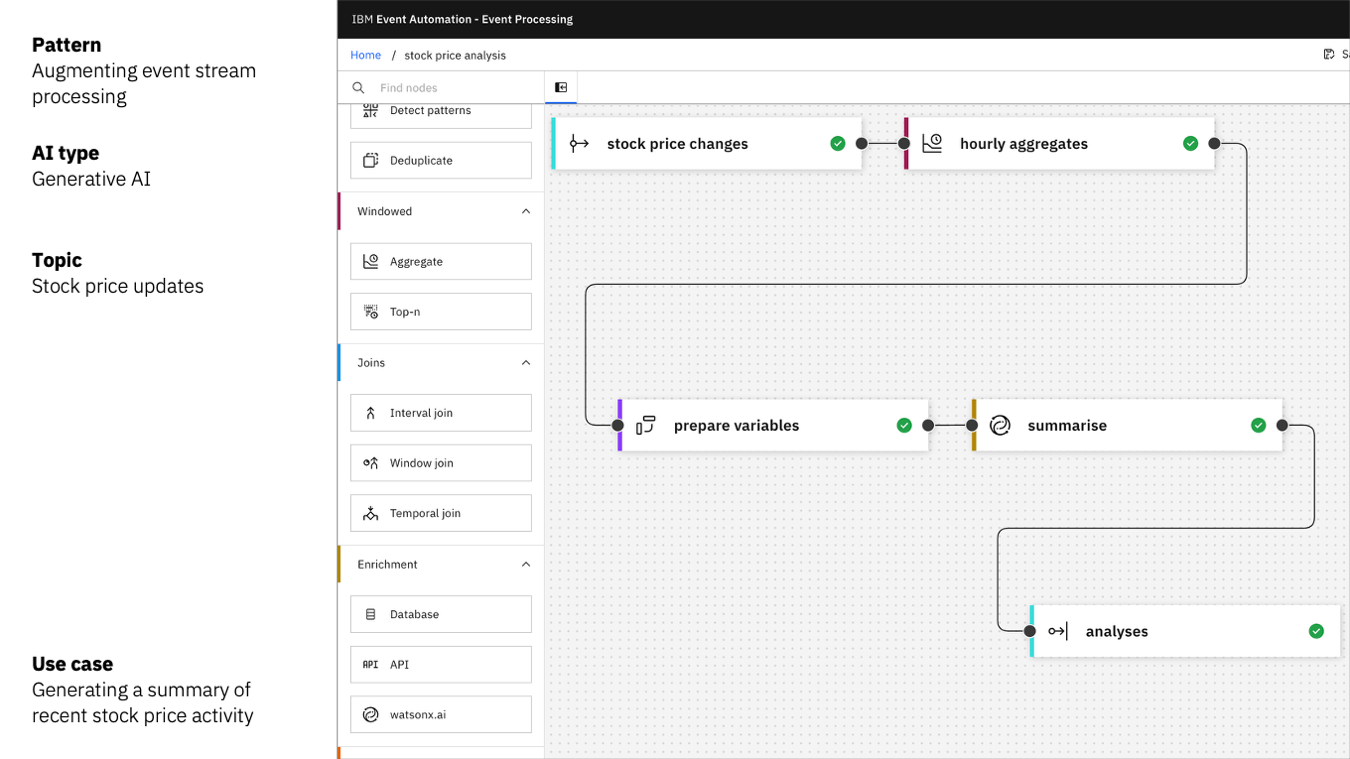
I built a simplified version of this using Flink to do the stateful bit of collecting together changes in events over an hour, and using generative AI to explain those changes.

To sum up, event processing can be enhanced using AI. This can be done by submitting individual events to AI services, or by collecting events from multiple topics or over time windows and submitting the results from that to AI services.
The results help to recognise what the events mean, decide how to process them, enrich them with additional data to inform downstream processes, and much more.
In the next post, I’ll get to the pattern where I start talking about agents.
Tags: apachekafka, kafka, machine learning