In this post, I describe how event stream projections can be used to make agentic AI more effective.
I spoke at a Kafka / Flink conference on Wednesday. I gave a talk about how AI and ML are used with Kafka topics. I had a lot to say, so this is the fourth post I’ve needed to write up my slides (and I’ve still got more to go!).
- the building blocks used in AI/ML Kafka projects
- how AI / ML is used to augment event stream processing
- how agentic AI is used to respond autonomously to events
- how events can provide real-time context to agents (this post)
- how events can be used as a source of training data for models

The talk was a whistlestop tour through the four main patterns for using artificial intelligence and machine learning with event streams.
This pattern was where I talked about using events as a source of context data for agents.

As I’ve written about before, there are multiple ways to maintain a projection of a stream of events, depending on where you want to store the projection and how you need to be able to retrieve (or maybe search and query) them.
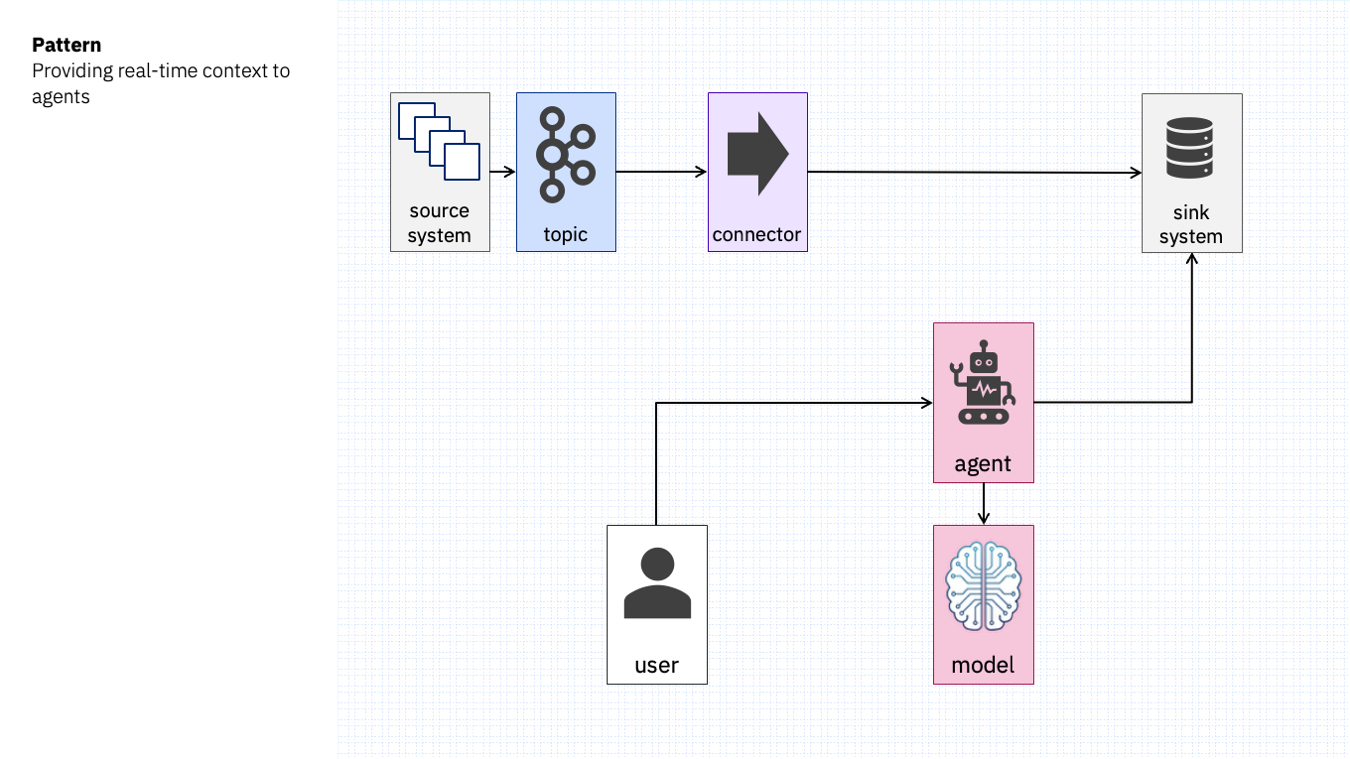
They all look something like this: a connector sinks a stream of events to some cache or persistent store, which stores the current or relevant data.
This store is available as a resource of real-time context for an agent, so when the agent is asked a question, it is able to respond in the context of the latest real-time data.
This is easier to explain with a few examples.

Imagine an agentic assistant, that uses your diary to know when you will be finished in your current appointment, and where you need to be next so it can arrange for a taxi to get you there on time.
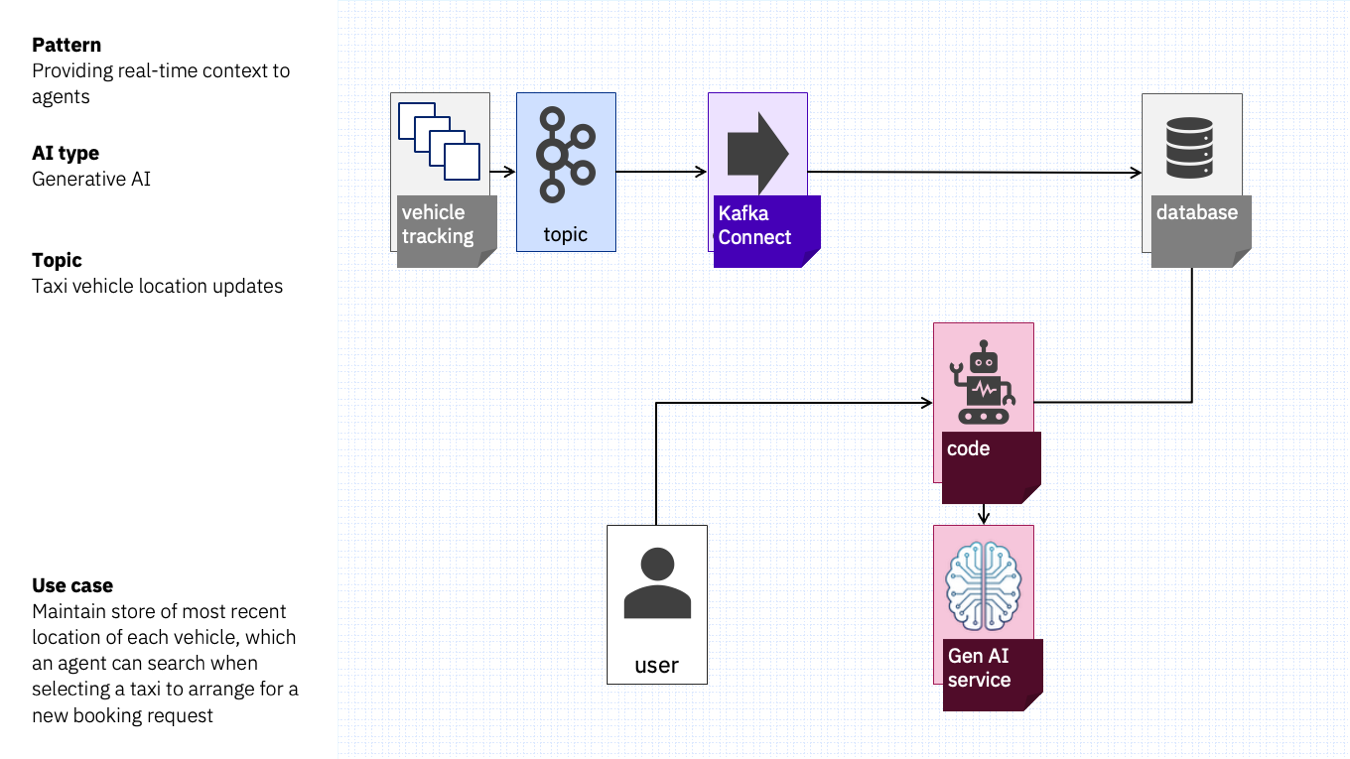
Using a topic of taxi location update events as a source of real-time context would look like this: a database with geo-spatial extensions for searching lets the agent quickly lookup which taxi is currently the closest to the user’s location.

Enabling this can be as simple as running a sink connector that consumes the stream of taxi location events, and upserts the location of each taxi into the database.

If the Kafka events are raw or low-level, it might help to do some form of processing on them first, and then maintain a projection based on the output of the stream processing. This can create a more useful source of real-time context for an agent.
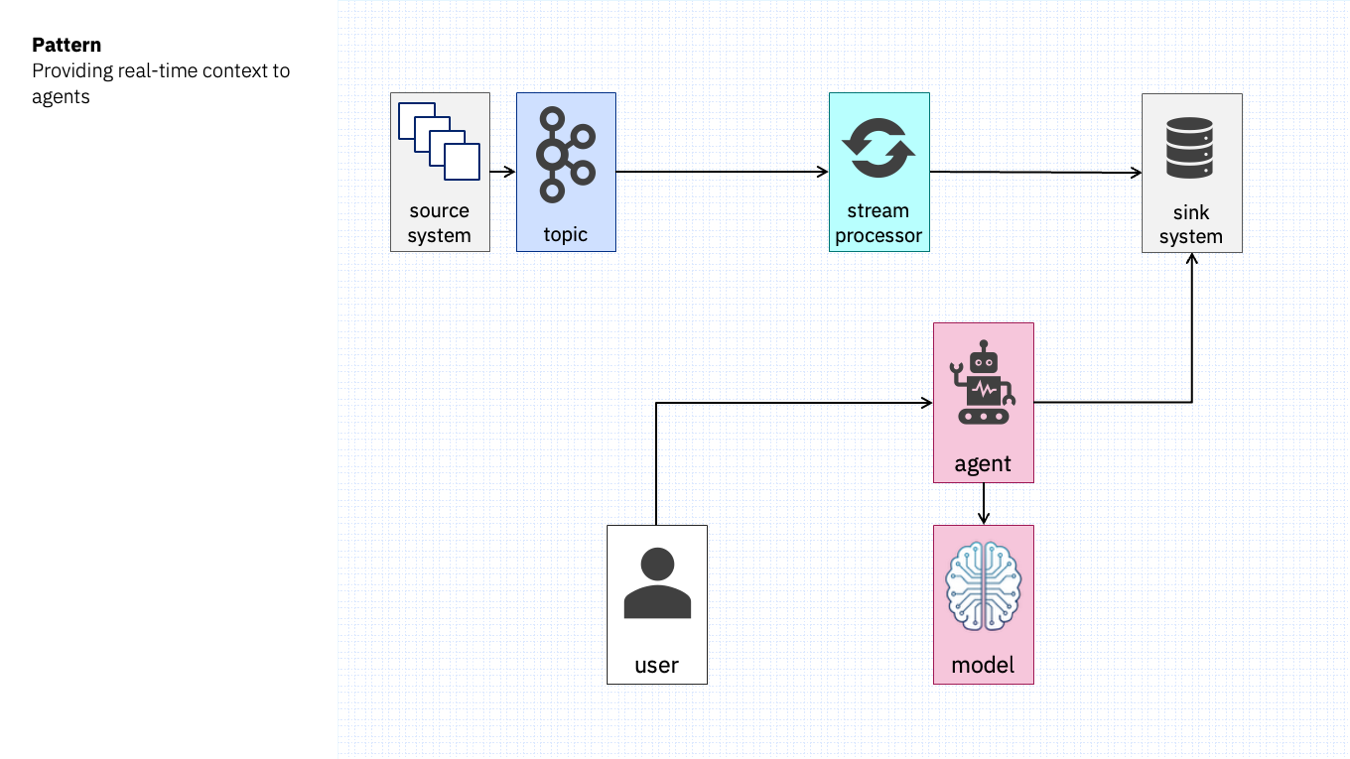
That would look like this: with the results of stream processing being sinked to some cache or persistent store.
As before, this resource is made available to an agent as source of real-time context that it can use when responding to user requests.

Imagine an event-driven online retailer that has topics for things like customer purchases, returns, and their click-tracking and browsing activity.
Event processing can turn that high volume of raw events into a set of useful:
- aggregates (such as how many orders a customer has placed recently)
- patterns (such as sustained interest in an item that the customer didn’t purchase)
- correlations (such as an order that is quickly cancelled or returned)
and so on.
Maintaining projections of these insights from the event processing is a useful source of context that an agent could use to generate appropriate and relevant responses to customer chat interactions.
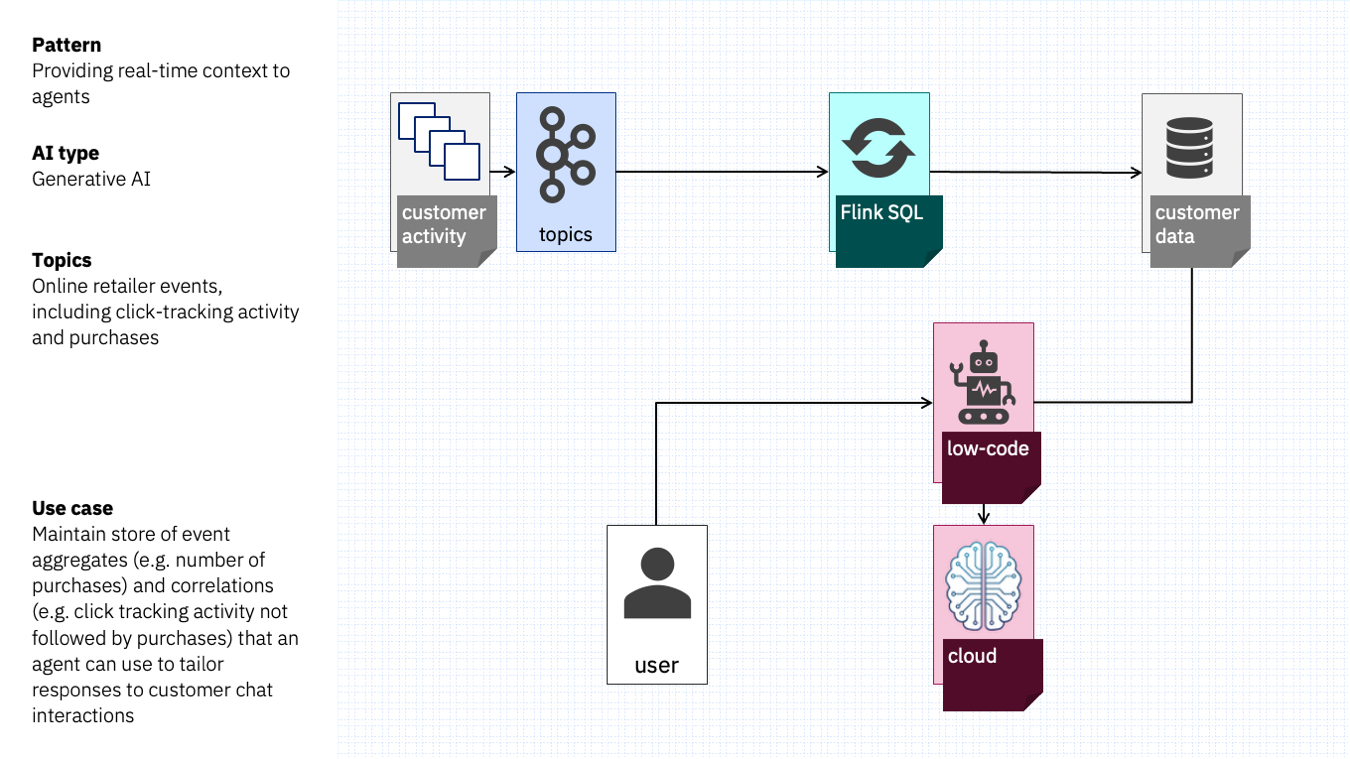
Such a solution would look something like this.
Topics from a customer activity system can be processed by a stateful stream processing platform. The different patterns, correlations, and aggregates can all be sinked into a database, and indexed by the customer’s id.
This database can be added as a resource to a customer services agent. When a customer asks the agent a question, the agent is able to search that recent cache of the customer’s activity with the retailer.

The way to think about this is that when you are creating an agent, identify how that could agent do a better job, take more appropriate actions or give more relevant answers if it had access to the records of what has recently happened on your Kafka topics.
Rather than try to have the agent interactively search across multiple streams of events to try and find relevant patterns, which is difficult to do quickly, you can use event stream processing to efficiently maintain a context of recent insights. The output from that can be made available for agents to efficiently search.
In the next post, I’ll cover the last pattern, which is how topics can be used as a source of training data for machine learning models.
Tags: apachekafka, ibmeventstreams, kafka, machine learning