In this post, I describe how event streams can be used as a source of training data for machine learning models.
I spoke at Current last week. I gave a talk about how artificial intelligence and machine learning are most commonly used with Kafka topics. I had a lot to say, so I didn’t manage to finish writing up my slides – but this post covers the last section of the talk.
It follows:
- the building blocks used in AI/ML Kafka projects
- how AI / ML is used to augment event stream processing
- how agentic AI is used to respond autonomously to events
- how events can provide real-time context to agents
- how events can be used as a source of training data for models (this post)

The talk covered the four main patterns for using AI/ML with events.
This pattern was where I talked about using events as a source of training data for models. This is perhaps the simplest and longest established approach – I’ve been writing about this for years, long pre-dating the current generative AI-inspired interest.

Our Kafka topics hold records of what has happened. By training a model on this historical record, we can create custom models that can recognise when something interesting happens in future.
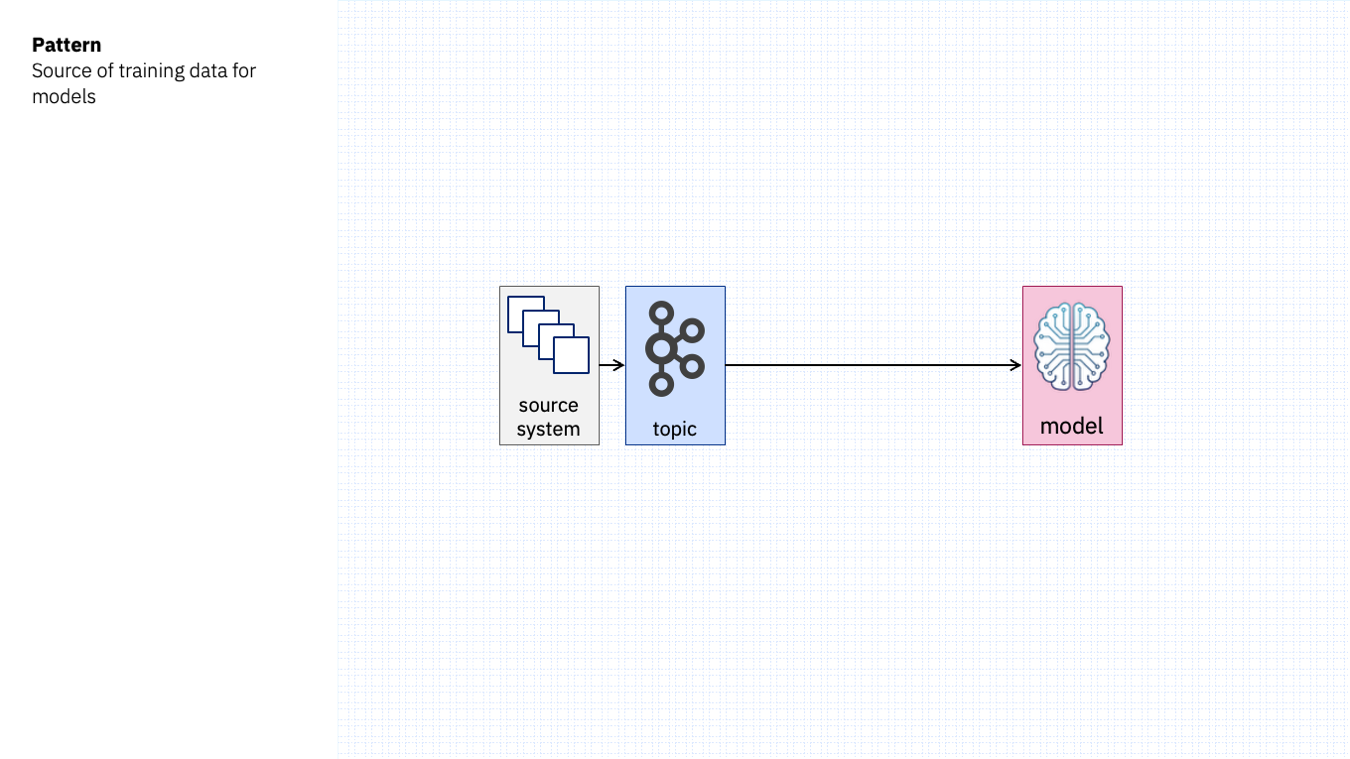
This can be as simple as reading the appropriate topics when creating the machine learning model – replaying the events as often as needed to tune the model.
This is easier to explain with an example.
Imagine a stream of events with resolved customer support issues – events that contain the original customer support issue description and how the issue was resolved.
This would be a great source of training data to create custom machine learning models that learn from those experiences to reduce the time to resolve future issues.
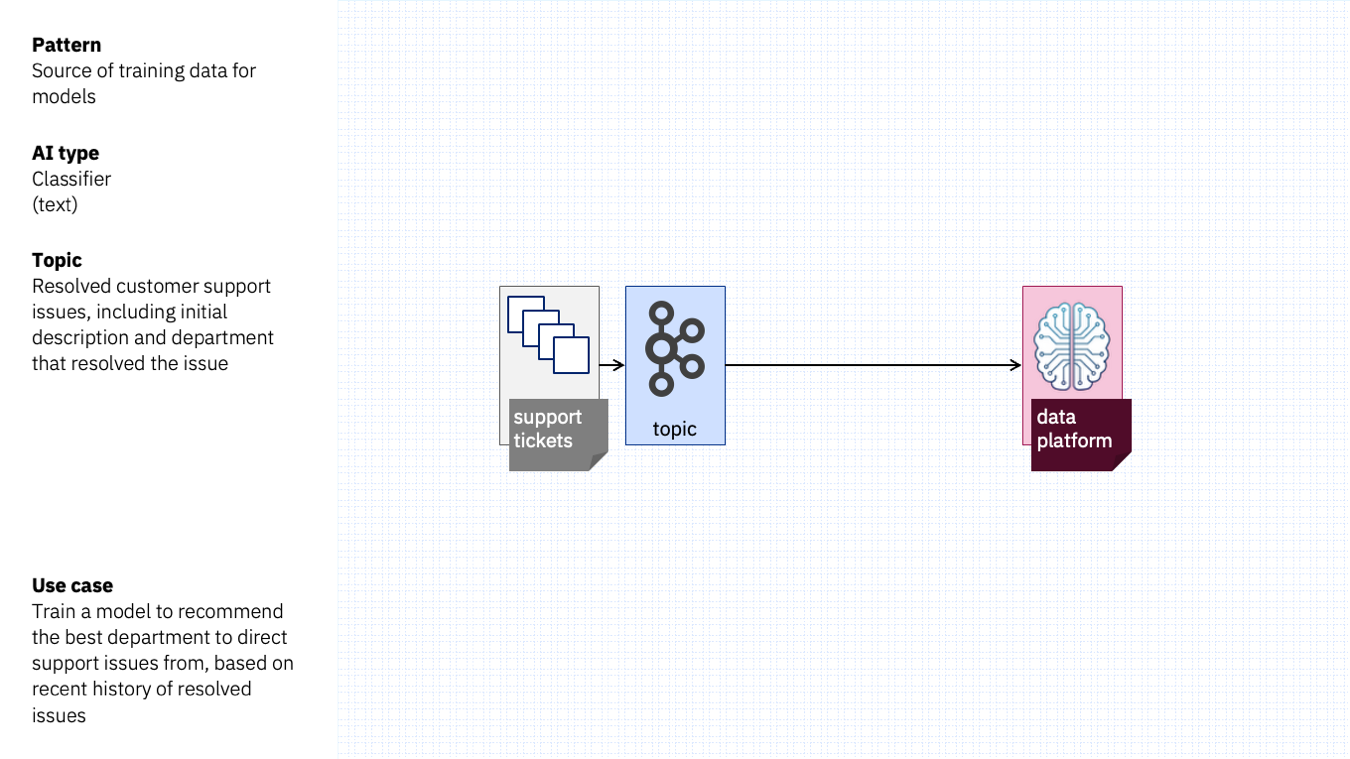
For example, training a text classifier with the name of the department that resolved the issue would be a simple way to create a classifier that can suggest the most appropriate department for new support issues.

This assumes that you have that sort of Kafka topic with a complete set of training data: the record of what happened, together with the label for what you want the model to learn for it.
Often this won’t be the case, but event stream processing can help with this. Event stream processing can correlate across multiple streams of events to turn raw events into usable training data.
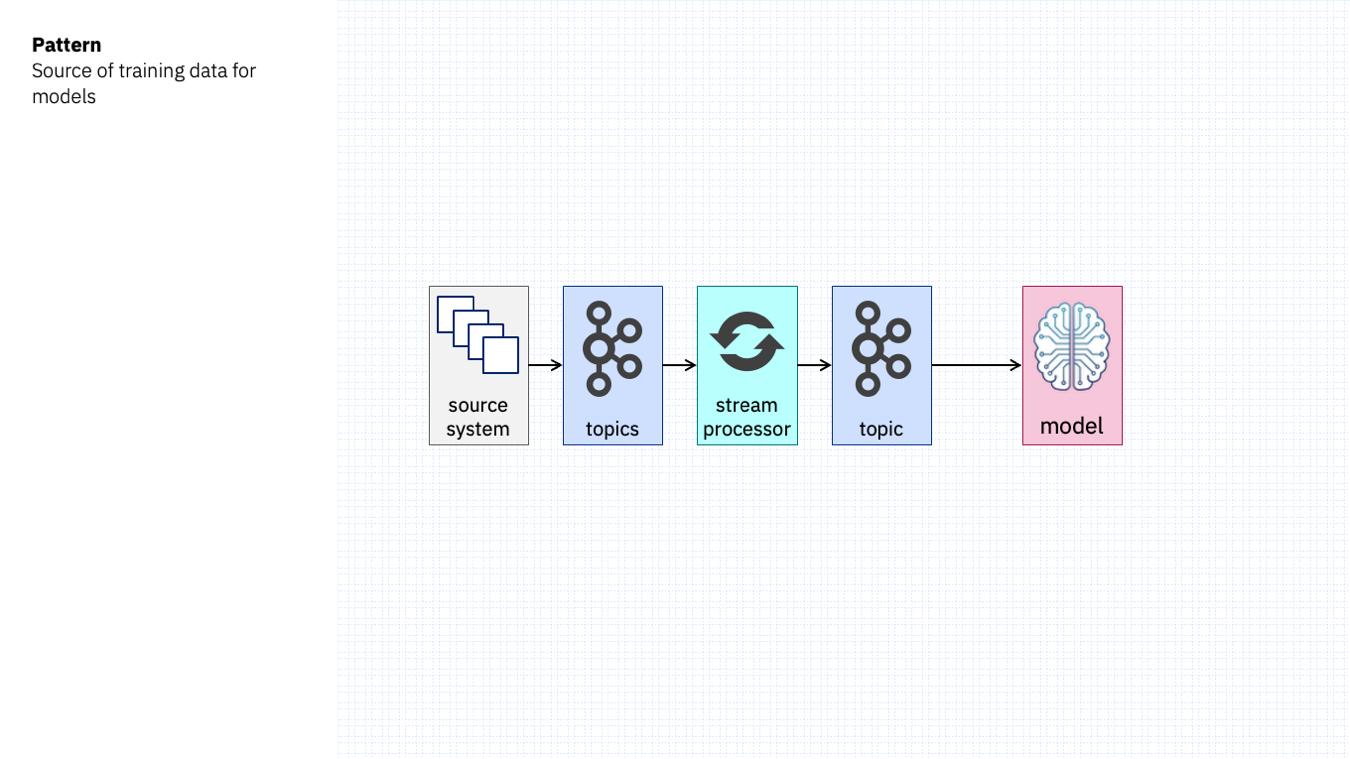
That would look something like this: Event stream processing pre-processing the raw events before using it to train a model.
Sticking with the same use case as before, imagine if this started as two topics:
- one topic with initial customer support issues as they are submitted
- a separate topic that later records how that issue gets resolved
Event stream processing could correlate these two separate streams of events to create a single set of usable training data (the initial support issue and how it was resolved).
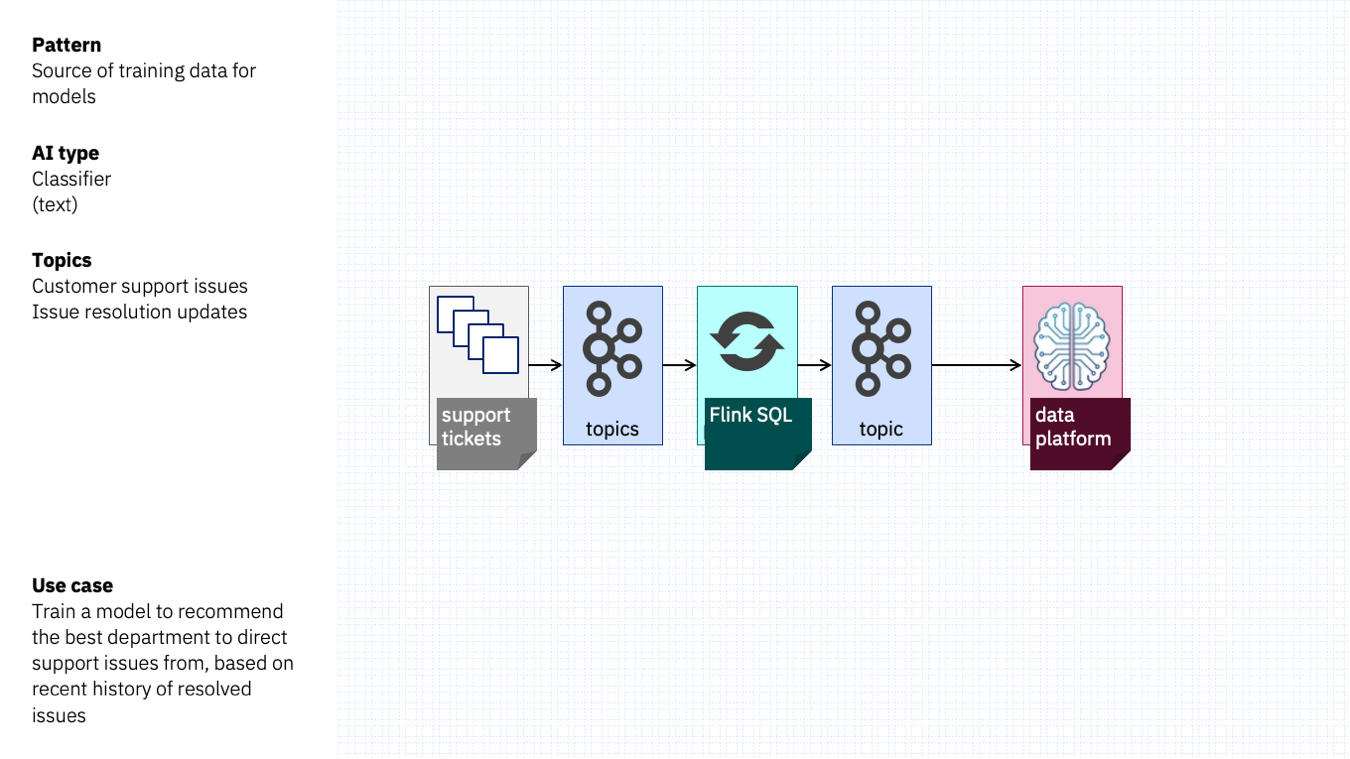
This could be implemented in Flink SQL with a simple interval join. The output from this would be a clean set of labelled training data ready for creating a custom model.
If you use a data platform that supports Kafka topics as an input source, such as Cloud Pak for Data (amongst many others) that is an easy pipeline to get ready.

This pattern doesn’t need to be exclusive from the others.
In the earlier examples I went through, where event processing was enhanced by using custom models to recognise or predict something from new events – these custom models will likely have been trained using historical events from the same topics. This pattern pairs nicely with those earlier use cases.
This was the last of the four patterns that I covered, showing that Kafka topics can be useful in the creation of AI / ML services, not just the usage of them.
Tags: apachekafka, kafka, machine learning