In this post, I describe how event stream projections can be used to make agentic AI more effective.
I spoke at a Kafka / Flink conference on Wednesday. I gave a talk about how AI and ML are used with Kafka topics. I had a lot to say, so this is the fourth post I’ve needed to write up my slides (and I’ve still got more to go!).
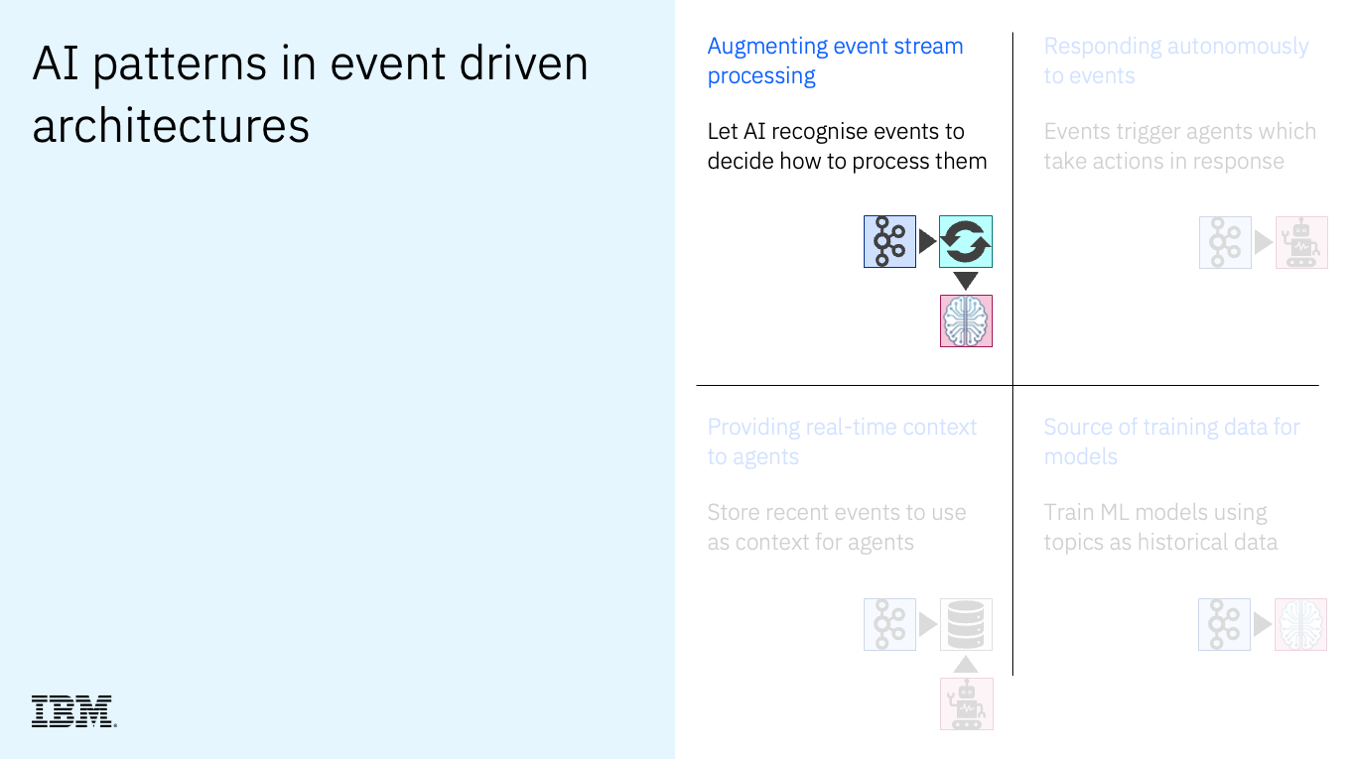
- the building blocks used in AI/ML Kafka projects
- how AI / ML is used to augment event stream processing
- how agentic AI is used to respond autonomously to events
- how events can provide real-time context to agents (this post)
- how events can be used as a source of training data for models

The talk was a whistlestop tour through the four main patterns for using artificial intelligence and machine learning with event streams.
This pattern was where I talked about using events as a source of context data for agents.