In this post, I want to share some changes I’ve been making to how I train models in Machine Learning for Kids.
Improving support for older computers and mobile devices on Machine Learning for Kids
January 16th, 20262025 Year In Review
January 14th, 2026Every site does a “Year In Review” nowadays. I know some people find them a creepy reminder of how much data is collected about us, but I love them. Quantified self plus pretty infographics? How could I say no?
For 2025, I collected some of my favourites:
- Gaming
- Music
- Books
- Podcasts
- Exercise
- Travel
- Social media
- Content creation
- Videos
- Beer
2025 in gaming (Nintendo)
January 13th, 2026Another gaming end of year recap – this time from Nintendo.
I thought I was finished with these 2025 year in reviews, with Spotify Wrapped first out of the gate on 3rd December.
It looks like Nintendo like to do things different – and published theirs on 13th January!
Flink SQL examples with click tracking events
January 12th, 2026In this post, I introduce a few core Flink SQL functions using worked examples of processing a stream of click tracking events from a retail website.
I find that a practical, real-world (ish) example can help to explain how to use Flink SQL in a way that abstract descriptions, such as processing coloured blocks sometimes doesn’t quite achieve.
I’ll use this post to give examples of my most-used Flink SQL functions, in the context of a retail scenario: a stream of events from customers on the website for a clothing retailer.
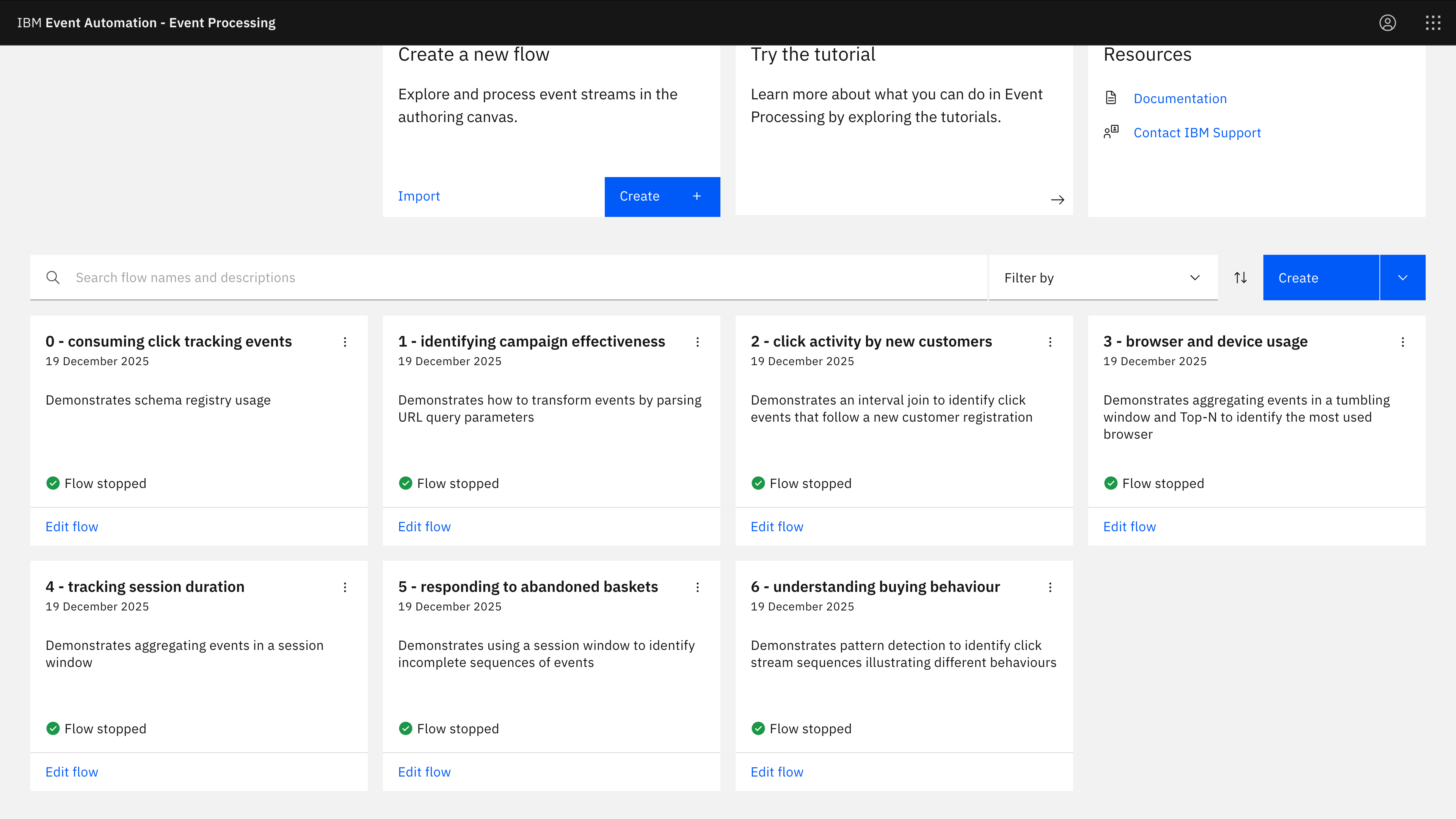
Note: I used Event Processing to create the flows, as the assistants in the canvas helped me create examples quickly. Everything I’ve created is standard Apache Flink SQL, so you don’t need to have Event Processing to try these examples.
- The examples:
- 0 Consuming Avro – bring click tracking events into Flink
- 1 Transforming – deriving new properties
- 2 Joining – correlating with related event streams
- 3 Aggregating (tumble) – counting in a tumble window
- 4 Aggregating (session) – counting in a session window
- 5 Aggregating (session) – collecting in a session window
- Data – the events I’m processing in these examples
- Setup – how to recreate this if you want to try this for yourself
Explaining role prompting in Scratch
January 11th, 2026In this post, I want to share a recent worksheet I wrote for Machine Learning for Kids. It is a hands-on project to give students an insight into an aspect of prompt engineering with language models.
Students create a Scratch project that lets them have a conversation with a small language model. They try to have the same conversation multiple times, and they set up the Scratch project so that adds a short role instruction to the context at the start (e.g. “Answer like a pirate”).
The instruction changes how the model answers, and students have to try and work out from the responses they get from the model which persona has been selected.
screen recording of the Scratch project on YouTube
By repeating the activity several times, they should notice something important: the same language model gives very different answers to the same questions, just because of a small change in the instructions. This observation is the key lesson here.
2025 in music (last.fm)
January 3rd, 2026Spotify has data for most music I choose to listen to – on my computer, my phone, in the car, on smart speakers, etc. So Spotify’s end of year review is more complete.
Last.fm only has data for music I listen on my laptop, but I prefer their end of year reports for the amount of geeky detail they go into!
They have two Year In Review options: a page of graphs, and a more infographic/animation-focused report.
2025 in beers (Untappd)
January 2nd, 2026Untappd is a site for tracking beers that you drink. Their end of year review is called Recappd – this is mine.
2025 in gaming (Backloggd)
January 1st, 2026Backloggd is a site for tracking video game playing. My end-of-year recap is at backloggd.com/u/dalelane/recap which is the best place to look at it, but I’ve made a copy here.