In this post, I want to share the most recent section I’ve added to Machine Learning for Kids: support for generating text and an explanation of some of the ideas behind large language models.
After launching the feature, I recorded a video using it. It turned into a 45 minute end-to-end walkthrough… longer than I planned! A lot of people won’t have time to watch that, so I’ve typed up what I said to share a version that’s easier to skim. It’s not a transcript – I’ve written a shortened version of what I was trying to say in the demo! I’ll include timestamped links as I go if you want to see the full explanation for any particular bit.
The goal was to be able to use language models (the sort of technology behind tools like ChatGPT) in Scratch.
youtu.be/Duw83OYcBik – jump to 00:19
For example, this means I can ask the Scratch cat:
Who were the Tudor Kings of England?
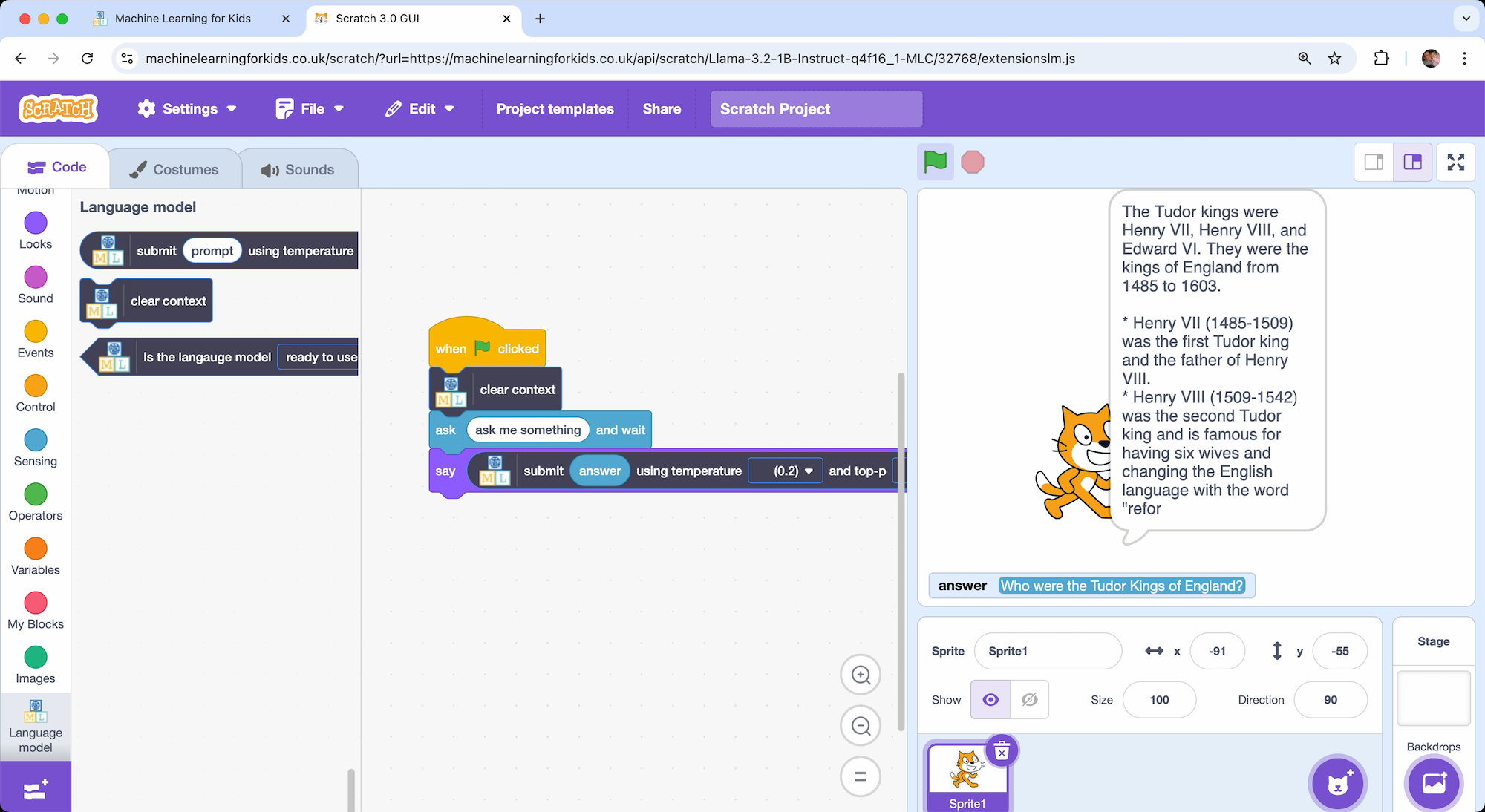
Or I can ask:
Should white chocolate really be called chocolate?
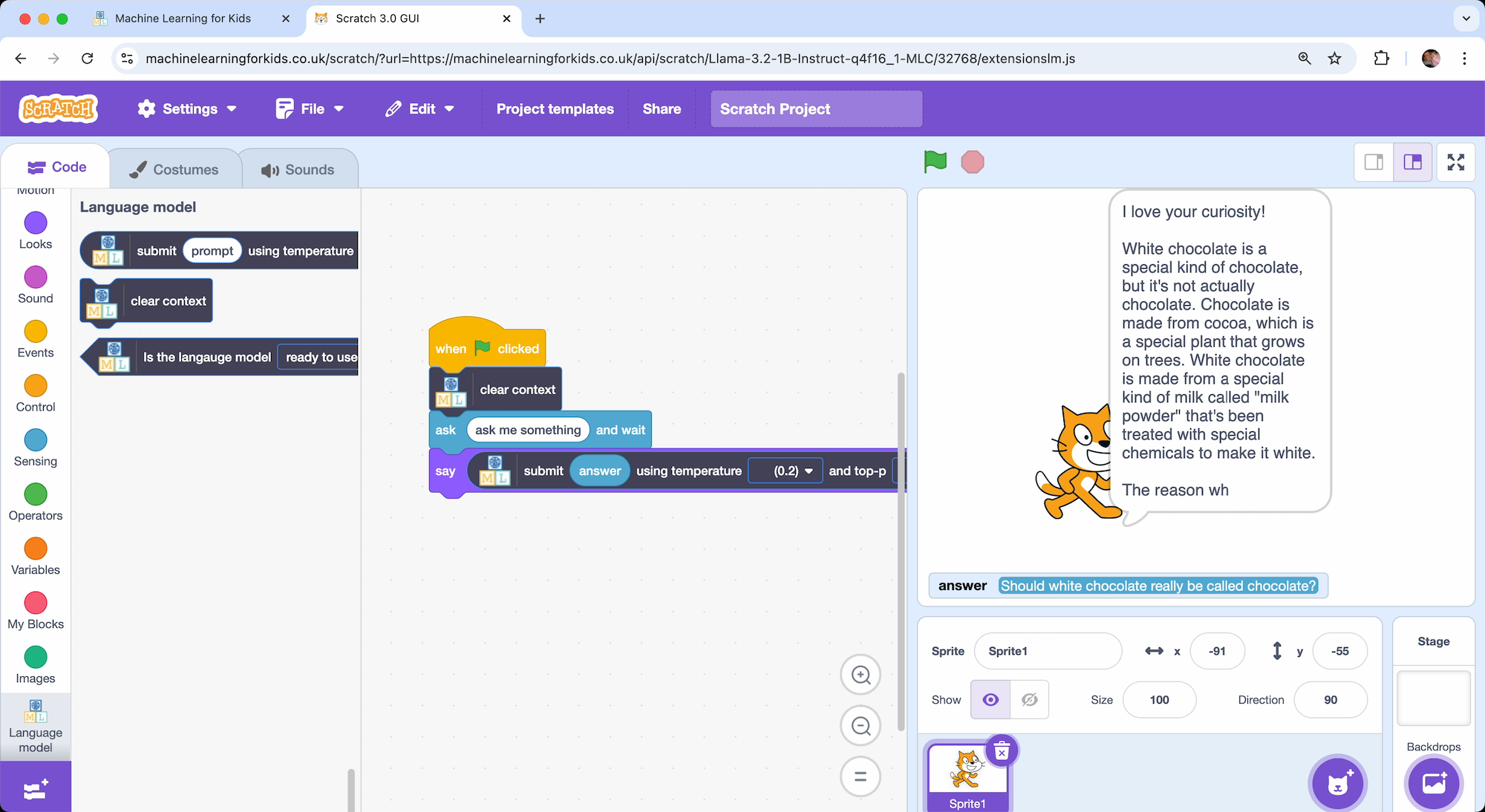
Although that is fun, I think the more interesting bit is the journey for how you get there.